Recognition: unknown
Reducing cross-sample prediction churn in scientific machine learning
Pith reviewed 2026-05-14 19:11 UTC · model grok-4.3
The pith
K-bootstrap bagging cuts cross-sample prediction churn 40-54% at no accuracy cost in chemistry benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
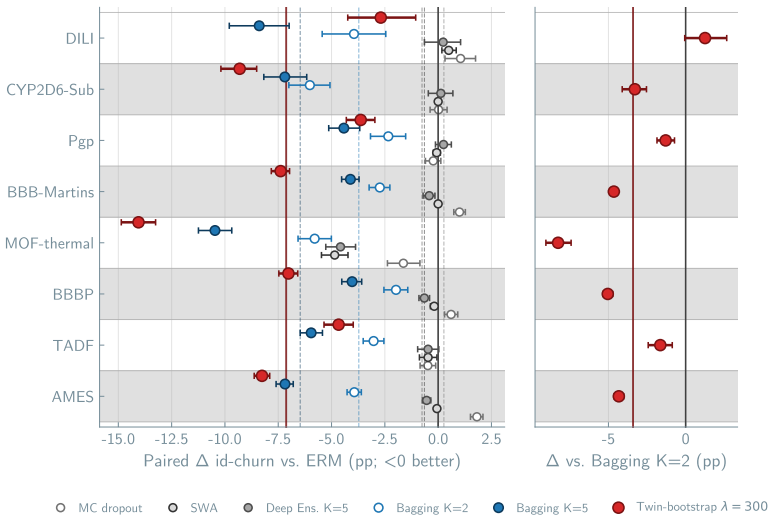
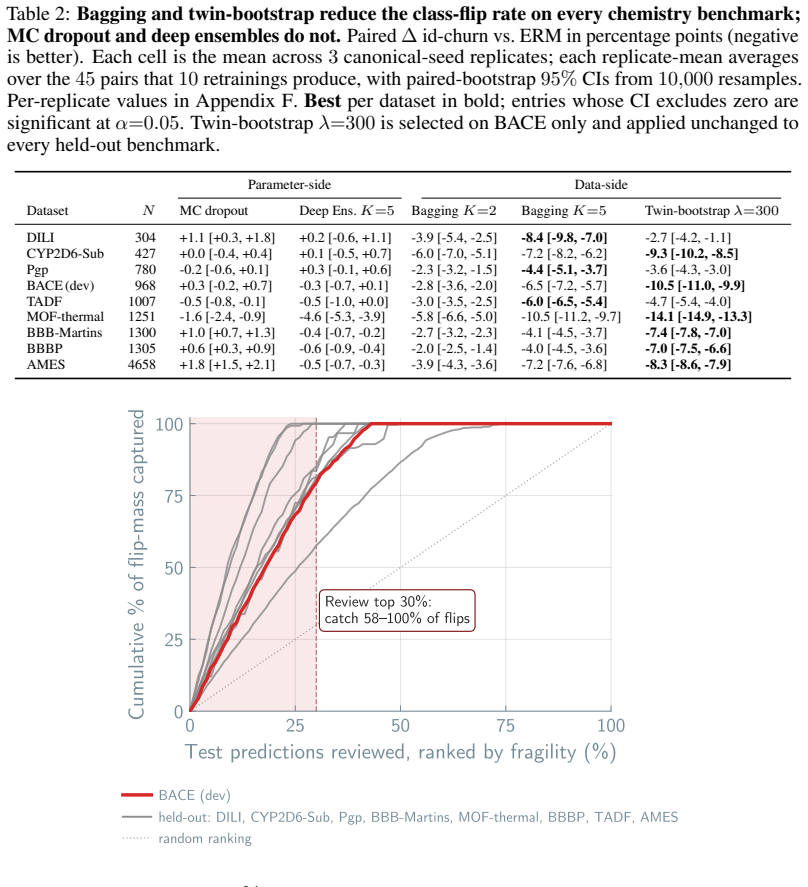
Two classifiers trained on independent bootstraps of the same training set agree on aggregate accuracy to within 1.3-4.2 percentage points but disagree on the class label of 8.0-21.8% of test molecules. K-bootstrap bagging cuts this churn rate 40-54% on every dataset at no accuracy cost at K-times ERM compute. Twin-bootstrap, two networks trained jointly on independent bootstraps with a symmetric KL consistency loss, reduces churn a further median 45% beyond bagging-K=2 at matched 2-times compute.
What carries the argument
Twin-bootstrap training: two networks trained jointly on independent bootstraps with a symmetric KL consistency loss between their output distributions.
If this is right
- Cross-sample prediction churn should be reported as a separate column in scientific-ML benchmark tables.
- Parameter-side uncertainty techniques leave churn unchanged while data-side bagging reduces it.
- Twin-bootstrap delivers extra churn reduction at fixed 2-times compute compared with ordinary bagging.
- Churn reduction comes at linear extra compute for bagging but requires no accuracy trade-off.
Where Pith is reading between the lines
- Churn may serve as a practical diagnostic for whether a model has extracted stable decision boundaries from limited scientific data.
- The same data-resampling logic could be tested on regression or multi-task scientific problems to check if churn behaves similarly.
- If churn remains after these interventions, it may point to inherent limits in the information contained in the training distribution itself.
Load-bearing premise
The churn reductions measured on the nine chemistry classification benchmarks will continue to hold for other tasks and data distributions.
What would settle it
Applying K-bootstrap bagging or twin-bootstrap to a non-chemistry classification task and measuring no reduction in label disagreement across independent retrainings.
Figures




read the original abstract
Scientific machine learning reports predictive performance. It does not report whether the same prediction would survive a different draw of training data. Across $9$ chemistry benchmarks, two classifiers trained on independent bootstraps of the same training set agree on aggregate accuracy to within $1.3\text{--}4.2$ percentage points but disagree on the class label of $8.0\text{--}21.8\%$ of test molecules. We call this gap \emph{cross-sample prediction churn}. The standard parameter-side techniques (deep ensembles, MC dropout, stochastic weight averaging) do not reduce this gap; two data-side methods do. The first is $K$-bootstrap bagging, which cuts the rate $40\text{--}54\%$ on every dataset at no accuracy cost ($K{\times}$-ERM compute). The second is \emph{twin-bootstrap}, our proposal: two networks trained jointly on independent bootstraps with a sym-KL consistency loss between their predictions, which at matched $2{\times}$-ERM compute reduces churn a further median $45\%$ beyond bagging-$K{=}2$. Cross-sample prediction churn deserves a column alongside predictive performance in scientific-ML benchmark reports, because without it the parameter-side and data-side methods are indistinguishable on the metric they actually differ on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces cross-sample prediction churn as the disagreement rate on test predictions between classifiers trained on independent bootstraps of the same training set. On nine chemistry benchmarks it shows that parameter-side methods (ensembles, MC dropout, SWA) leave churn largely unchanged while K-bootstrap bagging reduces churn 40–54 % at no accuracy cost and twin-bootstrap (joint training on two bootstraps plus symmetric-KL consistency loss) yields a further median 45 % reduction at matched 2×-ERM compute; the authors argue that churn should be reported alongside accuracy.
Significance. If the quantitative claims hold, the work is significant because it isolates a distinct failure mode—sensitivity to training-set resampling—that is invisible to standard accuracy or uncertainty metrics yet directly relevant to scientific reproducibility. The consistent empirical pattern across nine benchmarks and the proposal of two simple, compute-matched remedies constitute a concrete, falsifiable contribution that could be adopted as a standard reporting practice.
major comments (1)
- [§4] §4 (results tables): the central quantitative claims—40–54 % churn reduction for K-bootstrap and median 45 % further reduction for twin-bootstrap—are reported as point estimates or ranges across the nine datasets with no standard deviations, confidence intervals, or repeated independent trials (different bootstrap seeds and optimization seeds). Because both resampling and SGD are stochastic, it is impossible to determine whether the observed differences exceed run-to-run variability; the same tables also present accuracy gaps (1.3–4.2 pp) without variance, undermining the “no accuracy cost” claim.
minor comments (2)
- [Abstract] Abstract: the accuracy comparison is stated as “1.3–4.2 percentage points” without clarifying whether this is a range, mean, or median; adding a brief parenthetical on variance would improve clarity.
- [§3.2] §3.2: the hyper-parameter governing the sym-KL loss weight is introduced but no ablation or sensitivity plot is provided; a short supplementary table showing churn and accuracy versus this weight on one or two datasets would strengthen the method description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of our quantitative results. We address the major comment below.
read point-by-point responses
-
Referee: [§4] §4 (results tables): the central quantitative claims—40–54 % churn reduction for K-bootstrap and median 45 % further reduction for twin-bootstrap—are reported as point estimates or ranges across the nine datasets with no standard deviations, confidence intervals, or repeated independent trials (different bootstrap seeds and optimization seeds). Because both resampling and SGD are stochastic, it is impossible to determine whether the observed differences exceed run-to-run variability; the same tables also present accuracy gaps (1.3–4.2 pp) without variance, undermining the “no accuracy cost” claim.
Authors: We agree that reporting variability is necessary to substantiate the claims given the stochasticity of bootstrapping and SGD. In the revised manuscript we will rerun all experiments across multiple independent trials (distinct bootstrap seeds and optimization seeds), and update the §4 tables to report means ± standard deviations for the churn-reduction percentages and for the accuracy values. This will allow direct assessment of whether the 40–54 % and median-45 % reductions exceed run-to-run variability and whether the accuracy gaps (1.3–4.2 pp) remain negligible within the observed variance. revision: yes
Circularity Check
No circularity: empirical measurements on external benchmarks
full rationale
The paper defines cross-sample prediction churn as an observable disagreement rate between models trained on independent bootstraps and then reports measured reductions (40-54% for K-bootstrap, median 45% further for twin-bootstrap) from direct experiments on nine held-out chemistry classification benchmarks. These are point estimates from test-set comparisons, not quantities derived from the same data via fitting or self-referential equations. No load-bearing step reduces by construction to its inputs, no uniqueness theorem is invoked, and no ansatz is smuggled via self-citation. The central claims remain falsifiable against the reported benchmarks and do not collapse into re-labeling of fitted parameters.
Axiom & Free-Parameter Ledger
free parameters (1)
- sym-KL loss weight
axioms (1)
- domain assumption Bootstrap samples are valid proxies for independent draws from the same underlying distribution
Reference graph
Works this paper leans on
-
[1]
On the reproducibility of neural network predictions.arXiv preprint arXiv: 2102.03349,
Srinadh Bhojanapalli, Kimberly Wilber, Andreas Veit, Ankit Singh Rawat, Seungyeon Kim, Aditya Menon, and Sanjiv Kumar. On the reproducibility of neural network predictions.arXiv preprint arXiv: 2102.03349,
-
[2]
Selective ensembles for consistent predictions
Emily Black, Klas Leino, and Matt Fredrikson. Selective ensembles for consistent predictions. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25- 29,
2022
-
[3]
ISSN 1573-0565. doi: 10.1007/bf00058655. URLhttp://dx.doi.org/10.1007/BF00058655. Leo Breiman. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical Science, 16(3), August
-
[4]
ISSN 0883-4237. doi: 10.1214/ss/1009213726. URL http://dx.doi.org/10.1214/ss/1009213726. Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta: Large-scale self- supervised pretraining for molecular property prediction.arXiv preprint arXiv: 2010.09885,
-
[5]
Curran Associates Inc. ISBN 9781510838819. Alexander D’Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yian Ma, Cory McLean, Diana Mincu, Akinori Mitani, An...
-
[6]
doi: 10.1038/s41597-023-02897-3
ISSN 2052-4463. doi: 10.1038/s41597-023-02897-3. URL http://dx.doi.org/ 10.1038/s41597-023-02897-3. Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf H. Roohani, J. Leskovec, Connor W. Coley, Cao Xiao, Jimeng Sun, and M. Zitnik. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development.NeurIPS Datasets and Benchmarks,
-
[7]
Clever materials: When models identify good materials for the wrong reasons
Kevin Maik Jablonka. Clever materials: When models identify good materials for the wrong reasons. arXiv preprint arXiv: 2602.17730,
-
[8]
Churn reduction via distillation
Heinrich Jiang, Harikrishna Narasimhan, Dara Bahri, Andrew Cotter, and Afshin Rostamizadeh. Churn reduction via distillation. InThe Tenth International Conference on Learning Rep- resentations, ICLR 2022, Virtual Event, April 25-29,
2022
-
[9]
Charles T
URL https://openreview.net/forum?id= Bkg6RiCqY7. Charles T. Marx, Flávio P. Calmon, and Berk Ustun. Predictive multiplicity in classification. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Proceedings of Machine Learning Research, pages 6765–6774. PMLR,
2020
-
[10]
doi: 10.1038/s41467-020-17755-8
ISSN 2041-1723. doi: 10.1038/s41467-020-17755-8. URL http://dx.doi.org/10.1038/ s41467-020-17755-8. Aditya Nandy, Gianmarco Terrones, Naveen Arunachalam, Chenru Duan, David W. Kastner, and Heather J. Kulik. Mofsimplify, machine learning models with extracted stability data of three thousand metal–organic frameworks.Scientific Data, 9(1), March
-
[11]
doi: 10.1038/s41597-022-01181-0
ISSN 2052-4463. doi: 10.1038/s41597-022-01181-0. URLhttp://dx.doi.org/10.1038/s41597-022-01181-0. Richard D. Riley and Gary S. Collins. Stability of clinical prediction models developed using statistical or machine learning methods.Biometrical Journal, 65(8),
-
[12]
ISSN 1521-4036. doi: 10.1002/bimj.202200302. URLhttp://dx.doi.org/10.1002/bimj.202200302. Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning. Chemical Science, 9(2):513–530,
-
[13]
ISSN 2041-6539. doi: 10.1039/c7sc02664a. URL http://dx.doi.org/10.1039/C7SC02664A. Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
-
[14]
Top-10% recall
freezes λ=300 on BACE and applies it to every other dataset. Does per-dataset tuning win on the metric the paper reports (cross-sample churn between independent retrainings)? We test this with a Bayesian optimisation that minimises the argmax disagreement between two independent twin-bootstrap ensembles on a held-out validation fold, subject to an accurac...
2018
-
[15]
Test models
on RDKit-derived atom-and-bond graphs of BACE: 3 GINConv layers, hidden dimension 128, mean-pool readout, 50 epochs. All ten train-seeds and the canonical-data-seed protocol are unchanged. Table 15 reports per-method id-accuracy, class-flip rate, and sym-KL with95% paired-bootstrap CIs, plus paired∆vs. ERM on the same45seed-pairs. Table 15:GIN on BACE: ba...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.