Recognition: 2 theorem links
· Lean TheoremSupport Before Frequency in Discrete Diffusion
Pith reviewed 2026-05-15 05:45 UTC · model grok-4.3
The pith
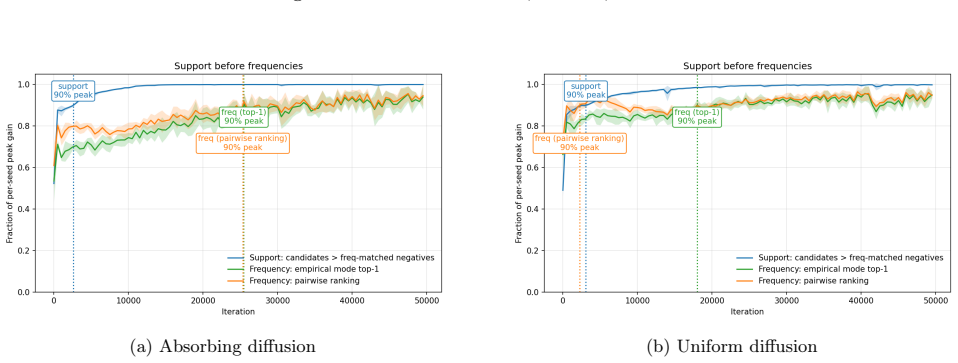
Discrete diffusion models learn data support before frequencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For uniform and absorbing diffusion, we prove that in the small-noise regime of the final denoising steps, each single-token reverse edit decomposes into a leading scale, determined by whether it moves toward the data support, and a finer coefficient, determining relative probabilities within the same scale. Thus, recovering validity structure only requires learning the correct order of magnitude of reverse probabilities, whereas recovering data frequencies requires coefficient-level estimation. The separation is mechanism-dependent: uniform diffusion exhibits a trichotomy into validity-improving, validity-preserving, and validity-worsening edits, while absorbing diffusion places its leading
What carries the argument
The decomposition of each reverse edit into a leading support scale and a finer frequency coefficient in the small-noise limit of the reverse process.
If this is right
- Support localization emerges earlier than within-support frequency ranking.
- Uniform diffusion induces a trichotomy of validity-improving, preserving, and worsening edits.
- Absorbing diffusion concentrates leading mass on validity-improving moves.
- Recovering the data support requires only order-of-magnitude accuracy rather than precise probability estimates.
- These predictions are supported by experiments on masked language diffusion models and synthetic regular-language tasks.
Where Pith is reading between the lines
- This ordering implies that partial training checkpoints may already produce mostly valid samples even if their likelihood estimates remain inaccurate.
- Designers of discrete generative models could prioritize loss terms that accelerate support recovery before refining frequencies.
- Analogous scale separations might exist in other noising processes if their reverse steps admit similar asymptotic decompositions.
- The finding suggests monitoring support metrics separately from likelihood during training to detect when validity is achieved.
Load-bearing premise
The decomposition into leading scale and finer coefficient holds in the small-noise regime of the final denoising steps.
What would settle it
Training a discrete diffusion model until it accurately predicts frequencies within the support but still assigns significant probability to invalid sequences would contradict the claimed hierarchy.
Figures


















read the original abstract
Discrete diffusion models are increasingly competitive for language modeling, yet it remains unclear how their denoising objectives organize learning. Although these objectives target the full data distribution, we show that the exact reverse process induces a hierarchy between coarse support information and finer frequency information. For uniform and absorbing (a.k.a. masking) diffusion, we prove that, in the small-noise regime of the final denoising steps, each single-token reverse edit decomposes into a leading scale, determined by whether it moves toward the data support (e.g., grammatically valid sentences), and a finer coefficient, determining relative probabilities within the same scale. Thus, recovering validity structure only requires learning the correct order of magnitude of reverse probabilities, whereas recovering data frequencies requires coefficient-level estimation. The separation is mechanism-dependent: uniform diffusion exhibits a trichotomy into validity-improving, validity-preserving, and validity-worsening edits, while absorbing diffusion places its leading-order mass on validity-improving moves. Experiments on a masked language diffusion model and synthetic regular-language tasks support these predictions: support-localization emerges earlier than within-support frequency ranking, and the contrast between uniform and absorbing diffusion matches the predicted rate separation. Together, our results suggest that discrete diffusion models learn data support before data frequencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that discrete diffusion models learn data support before frequencies because the exact reverse process for uniform and absorbing diffusion decomposes, in the small-noise regime, into a leading scale term (determining validity/support) and a sub-leading coefficient (determining relative frequencies). Proofs are given for this decomposition, and experiments on synthetic regular-language tasks and masked language models show support localization emerging earlier than frequency ranking.
Significance. If the link from the exact reverse decomposition to optimization dynamics is established, the result offers a principled explanation for the learning order in discrete diffusion, which is increasingly used in language modeling. The rigorous proofs for the uniform and absorbing cases and the supporting synthetic experiments are strengths that make the work potentially impactful for understanding and improving diffusion-based generative models.
major comments (2)
- [§3] The proof shows that the exact reverse transitions factor into leading support term and finer frequency coefficient, but the claim that models therefore learn support before frequencies requires an additional argument that gradient-based optimization prioritizes the leading term; no analysis of the loss landscape or SGD trajectory is provided to support this step.
- [§5] The experiments demonstrate the predicted ordering on regular languages and masked LMs, but do not include controls or ablations to isolate whether the ordering arises from the scale-coefficient decomposition rather than data statistics, masking schedule, or architecture biases.
minor comments (1)
- [Abstract] The definition of the 'small-noise regime' could be made more precise, e.g., by specifying the noise level or number of final steps explicitly.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments. The work aims to provide a mechanistic explanation for why discrete diffusion models recover support structure before frequencies. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] The proof shows that the exact reverse transitions factor into leading support term and finer frequency coefficient, but the claim that models therefore learn support before frequencies requires an additional argument that gradient-based optimization prioritizes the leading term; no analysis of the loss landscape or SGD trajectory is provided to support this step.
Authors: We agree that an explicit analysis of the loss landscape or SGD trajectory would provide a tighter link. The manuscript's argument rests on the fact that, in the small-noise regime, the leading scale term dominates the reverse probability by a full order of magnitude while the coefficient is sub-leading; any gradient-based optimizer will therefore incur a substantially larger penalty for mis-ordering the scale than for mis-estimating the coefficient. This scale separation supplies a heuristic reason why support is recovered first. We will add a short discussion subsection in §3 that spells out this heuristic, its assumptions, and its limitations, without claiming a full dynamical analysis. revision: partial
-
Referee: [§5] The experiments demonstrate the predicted ordering on regular languages and masked LMs, but do not include controls or ablations to isolate whether the ordering arises from the scale-coefficient decomposition rather than data statistics, masking schedule, or architecture biases.
Authors: The synthetic regular-language tasks are constructed with fully known, controllable data statistics, and the direct comparison between uniform and absorbing diffusion (which induce different predicted rate separations) is intended to isolate the effect of the decomposition from architecture or schedule. The masked-LM experiments use a standard transformer backbone. We nevertheless agree that additional ablations would make the isolation more convincing. In the revision we will add (i) results with a shuffled-frequency baseline that preserves support but randomizes within-support probabilities, (ii) sweeps over masking schedules, and (iii) a brief comparison against a non-diffusion autoregressive baseline on the same synthetic tasks. revision: yes
Circularity Check
Derivation from exact reverse-process equations is self-contained
full rationale
The paper derives the claimed hierarchy directly from the exact reverse transition probabilities in the small-noise regime, decomposing each edit into a leading validity term and sub-leading coefficient via the diffusion process definitions. This is a mathematical property of the target distribution for uniform and absorbing cases, with no reduction to fitted parameters, no self-citation load-bearing the central claim, and no ansatz smuggled in. Experiments are presented as supporting evidence rather than the derivation itself. The core result is therefore independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption small-noise regime of the final denoising steps
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorems 2.1 and 2.2: small-noise expansions q_{t-1|t}(y|x) ~ σ^{Δd} · p_data(projD(candidate))/p_data(projD(current))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Thompson, A. C. , title =. Proceedings of the American Mathematical Society , volume =. 1963 , doi =
work page 1963
-
[2]
Advances in Neural Information Processing Systems , volume=
A continuous time framework for discrete denoising models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
arXiv preprint arXiv:2503.00307 , year=
Remasking discrete diffusion models with inference-time scaling , author=. arXiv preprint arXiv:2503.00307 , year=
-
[4]
Proceedings of the 42nd International Conference on Machine Learning , series=
The Diffusion Duality , author=. Proceedings of the 42nd International Conference on Machine Learning , series=
-
[5]
The Diffusion Duality, Chapter II:
Deschenaux, Justin and Gulcehre, Caglar and Sahoo, Subham Sekhar , booktitle=. The Diffusion Duality, Chapter II:
-
[6]
International Conference on Learning Representations , year=
Denoising is not the End: Discrete Diffusion Language Models with Self-Correction , author=. International Conference on Learning Representations , year=
-
[7]
Simple guidance mechanisms for discrete diffusion models.arXiv preprint arXiv:2412.10193, 2024
Simple Guidance Mechanisms for Discrete Diffusion Models , author=. arXiv preprint arXiv:2412.10193 , year=
-
[8]
arXiv preprint arXiv:2503.09790 , year=
Constrained Language Generation with Discrete Diffusion Models , author=. arXiv preprint arXiv:2503.09790 , year=
-
[9]
arXiv preprint arXiv:2503.04482 , year=
Generalized Interpolating Discrete Diffusion , author=. arXiv preprint arXiv:2503.04482 , year=
-
[10]
When Scores Learn Geometry: Rate Separations under the Manifold Hypothesis , author=. arXiv preprint arXiv:2509.24912 , year=
-
[11]
arXiv preprint arXiv:2505.17638 , year=
Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training , author=. arXiv preprint arXiv:2505.17638 , year=
-
[12]
Large Language Diffusion Models
Large Language Diffusion Models , author=. arXiv preprint arXiv:2502.09992 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
LLaDA2.1: Speeding Up Text Diffusion via Token Editing , author=. 2026 , eprint=
work page 2026
-
[14]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B , author=. 2025 , eprint=
work page 2025
-
[15]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[16]
Dream 7B: Diffusion Large Language Models
Dream 7B: Diffusion Large Language Models , author=. arXiv preprint arXiv:2508.15487 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song and Zheng Zhang and Cheng Luo and Pengyang Gao and Fan Xia and Hao Luo and Zheng Li and Yuehang Yang and Hongli Yu and Xingwei Qu and Yuwei Fu and Jing Su and Ge Zhang and Wenhao Huang and Mingxuan Wang and Lin Yan and Xiaoying Jia and Jingjing Liu and Wei. Seed Diffusion:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.02193 , eprintt...
work page internal anchor Pith review doi:10.48550/arxiv.2508.02193 2025
-
[18]
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
work page 2025
-
[19]
arXiv preprint arXiv:2510.15020 , year=
The Coverage Principle: How Pre-Training Enables Post-Training , author=. arXiv preprint arXiv:2510.15020 , year=
-
[20]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Concrete score matching: Generalized score matching for discrete data , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:2211.16750 , year=
Score-based continuous-time discrete diffusion models , author=. arXiv preprint arXiv:2211.16750 , year=
-
[23]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in neural information processing systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in neural information processing systems , volume=
Simplified and generalized masked diffusion for discrete data , author=. Advances in neural information processing systems , volume=
-
[26]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data , author=. arXiv preprint arXiv:2406.03736 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
A survey on diffusion language models,
A survey on diffusion language models , author=. arXiv preprint arXiv:2508.10875 , year=
-
[29]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Block diffusion: Interpolating between autoregressive and diffusion language models , author=. arXiv preprint arXiv:2503.09573 , year=
work page internal anchor Pith review arXiv
-
[30]
Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding , author=. arXiv preprint arXiv:2505.22618 , year=
-
[31]
arXiv preprint arXiv:2506.00413 , year=
Accelerating diffusion llms via adaptive parallel decoding , author=. arXiv preprint arXiv:2506.00413 , year=
-
[32]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[33]
Gemini Diffusion , year =
-
[34]
Mercury: Ultra-Fast Language Models Based on Diffusion , author=. 2025 , eprint=
work page 2025
-
[35]
Advances in Neural Information Processing Systems , volume=
Discrete flow matching , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Shannon, C. E. , title =. Bell System Technical Journal , volume =. doi:https://doi.org/10.1002/j.1538-7305.1948.tb01338.x , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/j.1538-7305.1948.tb01338.x , year =
-
[37]
Foundations of statistical natural language processing , author=. 1999 , publisher=
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.