Recognition: 2 theorem links
· Lean TheoremExemplar Partitioning for Mechanistic Interpretability
Pith reviewed 2026-05-15 01:30 UTC · model grok-4.3
The pith
Exemplar Partitioning constructs feature dictionaries for language model activations by clustering around observed exemplars, achieving near-SAE performance at much lower computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
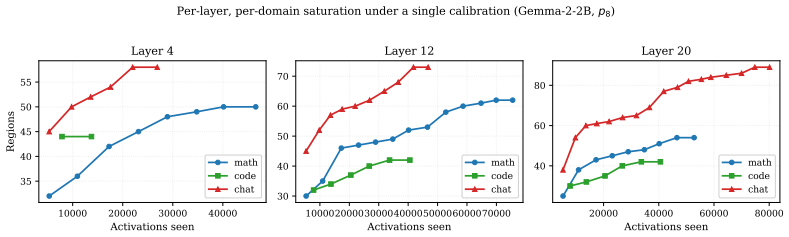
Exemplar Partitioning partitions the space of model activations into regions each centered on an observed exemplar activation, where membership is determined by proximity within a chosen distance threshold. Each such region functions as an interpretable feature that can be used for both analysis and causal intervention by ablating or steering along the exemplar direction. Because the anchors are real data points rather than optimized parameters, dictionaries constructed this way remain comparable across layers, models, and training stages, and the total number of features emerges naturally from the data geometry.
What carries the argument
Voronoi partition of activation space defined by leader-clustering around observed exemplars within a distance threshold, with each exemplar serving as the region center, membership test, and intervention vector.
Load-bearing premise
The Voronoi regions around single observed exemplars capture features that are both causally relevant to model behavior and understandable by humans.
What would settle it
A controlled intervention where ablating the exemplar of a predicted region does not change the model's output on tasks associated with that region, or where the regions show no correlation with human-labeled concepts.
Figures



read the original abstract
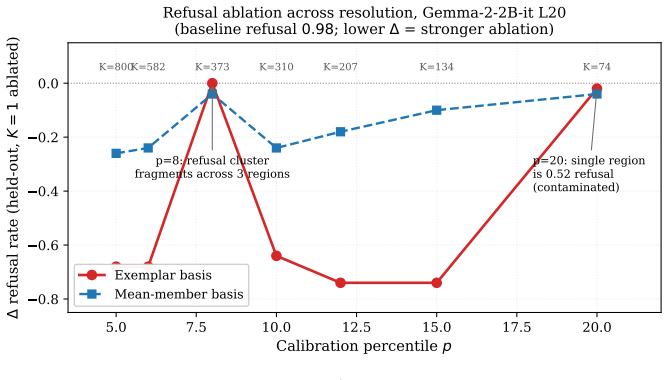
We introduce Exemplar Partitioning (EP), an unsupervised method for constructing interpretable feature dictionaries from large language model activations with $\sim 10^{3}\times$ fewer tokens than comparable sparse autoencoders (SAEs). An EP dictionary is a Voronoi partition of activation space, built by leader-clustering streamed activations within a distance threshold. Each region is anchored by an observed exemplar that serves as both its membership criterion and intervention direction; dictionary size is not prespecified, but determined by the activation geometry at that threshold. Because exemplars are observed rather than learned, dictionaries built from the same data stream are directly comparable across layers, models, and training checkpoints. We characterise EP as an interpretability object via targeted demonstrations of properties newly accessible through this construction, plus one head-to-head benchmark. In Gemma-2-2B, EP dictionary regions are interpretable and support causal interventions: refusal in instruction-tuned Gemma concentrates in a region whose exemplar ablation can collapse held-out refusal. Cross-checkpoint matching between base and instruction-tuned dictionaries separates the directions preserved through finetuning from those introduced by it. EP regions and Gemma Scope SAE features decompose activation space differently but agree on a shared core: $\sim 20\%$ of EP regions match an SAE feature at $F_{1} > 0.5$, and EP one-hot probes retain $\sim 97\%$ of raw-activation probe accuracy at $\ell_{0} = 1$. Nearest-exemplar distance provides a free out-of-distribution signal at inference. On AxBench latent concept detection at Gemma-2-2B-it L20, EP at $p_{1}$ reaches mean AUROC $0.881$, $+0.126$ over the canonical GemmaScope SAE leaderboard entry and within $0.030$ of SAE-A's $0.911$, at $\sim 10^{3}\times$ less build compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Exemplar Partitioning (EP), an unsupervised method that constructs feature dictionaries from LLM activations by leader-clustering streamed activations into Voronoi regions anchored at observed exemplars using a single distance threshold. It claims these regions are interpretable, support causal interventions (e.g., exemplar ablation collapsing refusal in Gemma-2-2B-it), enable direct cross-checkpoint and cross-model comparisons, exhibit ~20% overlap with GemmaScope SAE features at F1>0.5, retain ~97% of raw-activation probe accuracy at l0=1, and achieve mean AUROC 0.881 on AxBench latent concept detection at Gemma-2-2B-it L20 (p1), outperforming the canonical SAE baseline by +0.126 at ~10^3× lower build compute.
Significance. If the results hold, EP provides a computationally lightweight alternative to SAEs for mechanistic interpretability, with the key advantage of observed exemplars enabling parameter-free, directly comparable dictionaries across layers, models, and checkpoints. The intervention demonstrations and competitive AxBench performance indicate potential for isolating causally relevant directions at scale, which could lower barriers to feature discovery in large models.
major comments (3)
- [§4] §4 (refusal ablation experiments): the central causal claim that ablating a single exemplar collapses held-out refusal assumes the Voronoi cell isolates a mechanistically coherent direction. With a single fixed distance threshold, multiple independently manipulable directions could lie inside the same ball, rendering the intervention effect ambiguous; no analysis of intra-region direction independence or threshold sensitivity is provided to rule this out.
- [AxBench evaluation] AxBench evaluation (results paragraph and any associated table): the reported mean AUROC of 0.881 at p1 is presented without standard deviations across concepts or runs, exact number of test concepts, or explicit data-split details, making it impossible to assess whether the +0.126 margin over the GemmaScope SAE entry is statistically reliable or sensitive to evaluation choices.
- [§5.3] §5.3 (SAE overlap analysis): the ~20% overlap at F1>0.5 is used to argue for a 'shared core,' yet the paper provides no characterization of the non-overlapping EP regions (e.g., whether they capture unique causal features or geometric artifacts), which is load-bearing for the claim that EP and SAEs decompose activation space in complementary but consistent ways.
minor comments (2)
- [Abstract] Abstract: the symbols p1 and p are used in the AUROC claim without definition; readers must reach the methods or results to infer they denote specific threshold or percentile settings.
- [Methods] Methods section: the procedure for selecting or validating the distance threshold is not stated explicitly (fixed global value, per-layer tuning, or data-driven); this affects reproducibility of the reported dictionary sizes and intervention results.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below, acknowledging where additional analysis or reporting is needed, and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4] §4 (refusal ablation experiments): the central causal claim that ablating a single exemplar collapses held-out refusal assumes the Voronoi cell isolates a mechanistically coherent direction. With a single fixed distance threshold, multiple independently manipulable directions could lie inside the same ball, rendering the intervention effect ambiguous; no analysis of intra-region direction independence or threshold sensitivity is provided to rule this out.
Authors: We agree that a single fixed threshold leaves open the possibility that a Voronoi cell contains multiple independent directions, which could make the ablation effect harder to interpret in isolation. The intervention result nevertheless demonstrates a causal link between the observed exemplar region and refusal behavior. In the revised manuscript we will add a threshold-sensitivity analysis (reporting ablation outcomes across a range of distance thresholds) and a within-cell variance analysis (via PCA on activations assigned to the region) to quantify directional coherence. revision: yes
-
Referee: [AxBench evaluation] AxBench evaluation (results paragraph and any associated table): the reported mean AUROC of 0.881 at p1 is presented without standard deviations across concepts or runs, exact number of test concepts, or explicit data-split details, making it impossible to assess whether the +0.126 margin over the GemmaScope SAE entry is statistically reliable or sensitive to evaluation choices.
Authors: We apologize for the incomplete reporting. The evaluation followed the AxBench protocol on the standard test split for the reported layer and model. The revised manuscript will include the standard deviation across concepts, the exact number of test concepts, and explicit data-split and run details so that the statistical reliability of the reported margin can be assessed directly. revision: yes
-
Referee: [§5.3] §5.3 (SAE overlap analysis): the ~20% overlap at F1>0.5 is used to argue for a 'shared core,' yet the paper provides no characterization of the non-overlapping EP regions (e.g., whether they capture unique causal features or geometric artifacts), which is load-bearing for the claim that EP and SAEs decompose activation space in complementary but consistent ways.
Authors: The overlap figure is offered only as evidence of a non-trivial shared component rather than a claim of full equivalence. We acknowledge that a fuller characterization of the non-overlapping EP regions would strengthen the complementarity argument. In revision we will add a short discussion noting that non-overlapping regions may reflect geometric properties particular to exemplar anchoring and that their utility is supported by the competitive AxBench results, while clarifying that we do not claim they are necessarily unique causal features. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents Exemplar Partitioning as a direct unsupervised construction: leader-clustering of streamed activations within a fixed distance threshold yields Voronoi regions anchored at observed exemplars, with dictionary size emerging from the data geometry rather than being preset. Reported metrics (AxBench mean AUROC 0.881 at p1, refusal ablation effects, ~20% SAE overlap, 97% probe retention) are empirical evaluations on benchmark tasks and held-out data, with no equations reducing these quantities to parameters fitted on the evaluation set itself. No load-bearing self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify the central claims; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- distance threshold
axioms (1)
- domain assumption Leader-clustering on streamed activations produces Voronoi regions that align with causally relevant model features
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An EP dictionary is a Voronoi partition of activation space, built by leader-clustering streamed activations within a distance threshold.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EP at p1 reaches mean AUROC 0.881 ... at ~10^3× less build compute.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nature , volume=
Emergence of simple-cell receptive field properties by learning a sparse code for natural images , author=. Nature , volume=
-
[2]
2022 , note=
Toy Models of Superposition , author=. 2022 , note=
2022
-
[3]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[4]
2023 , note=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , note=
2023
-
[5]
2024 , note=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , note=
2024
-
[6]
2024 , eprint=
Scaling and evaluating sparse autoencoders , author=. 2024 , eprint=
2024
-
[7]
2024 , eprint=
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author=. 2024 , eprint=
2024
-
[8]
2024 , eprint=
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2 , author=. 2024 , eprint=
2024
-
[9]
2025 , note=
Karvonen, Adam and Rager, Can and Lin, Johnny and Tigges, Curt and Bloom, Joseph and Chanin, David and Lau, Yeu-Tong and Farrell, Eoin and McDougall, Callum and Ayonrinde, Kola and Till, Demian and Wearden, Matthew and Conmy, Arthur and Marks, Samuel and Nanda, Neel , booktitle=. 2025 , note=
2025
-
[10]
and Potts, Christopher , booktitle=
Wu, Zhengxuan and Arora, Aryaman and Geiger, Atticus and Wang, Zheng and Huang, Jing and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher , booktitle=. 2025 , note=
2025
-
[11]
IEEE Conference on Computer Vision and Pattern Recognition , year=
Network Dissection: Quantifying Interpretability of Deep Visual Representations , author=. IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[12]
International Conference on Machine Learning , year=
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors , author=. International Conference on Machine Learning , year=
-
[13]
International Conference on Machine Learning , year=
Concept Bottleneck Models , author=. International Conference on Machine Learning , year=
-
[14]
Advances in Neural Information Processing Systems , year=
Towards Automatic Concept-based Explanations , author=. Advances in Neural Information Processing Systems , year=
-
[15]
Fel, Thomas and Picard, Agustin and Bethune, Louis and Boissin, Thibaut and Vigouroux, David and Colin, Julien and Cadene, Remi and Serre, Thomas , booktitle=
-
[16]
International Conference on Machine Learning , year=
A Multimodal Automated Interpretability Agent , author=. International Conference on Machine Learning , year=
-
[17]
Clustering Algorithms , author=
-
[18]
IEEE Transactions on Information Theory , volume=
Least Squares Quantization in PCM , author=. IEEE Transactions on Information Theory , volume=
-
[19]
Advances in Neural Information Processing Systems , year=
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems , year=
-
[20]
Distill , year=
Activation Atlas , author=. Distill , year=
-
[21]
International Conference on Learning Representations , year=
Generalization through Memorization: Nearest Neighbor Language Models , author=. International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations Workshop , year=
Understanding intermediate layers using linear classifier probes , author=. International Conference on Learning Representations Workshop , year=
-
[23]
Computational Linguistics , volume=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. Computational Linguistics , volume=
-
[24]
2023 , eprint=
Activation Addition: Steering Language Models Without Optimization , author=. 2023 , eprint=
2023
-
[25]
Annual Meeting of the Association for Computational Linguistics , year=
Steering Llama 2 via Contrastive Activation Addition , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[26]
2023 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2023 , eprint=
2023
-
[27]
Advances in Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Advances in Neural Information Processing Systems , year=
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , author=. Advances in Neural Information Processing Systems , year=
-
[29]
Advances in Neural Information Processing Systems , year=
Energy-based Out-of-distribution Detection , author=. Advances in Neural Information Processing Systems , year=
-
[30]
Entropy , volume=
The Geometry of Concepts: Sparse Autoencoder Feature Structure , author=. Entropy , volume=
-
[31]
2000 , publisher=
Directional Statistics , author=. 2000 , publisher=
2000
-
[32]
and Ghosh, Joydeep and Sra, Suvrit , journal=
Banerjee, Arindam and Dhillon, Inderjit S. and Ghosh, Joydeep and Sra, Suvrit , journal=. Clustering on the Unit Hypersphere using von
-
[33]
International Conference on Machine Learning , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. International Conference on Machine Learning , year=
-
[34]
Interpreting
nostalgebraist , year=. Interpreting
-
[35]
2022 , note=
In-context Learning and Induction Heads , author=. 2022 , note=
2022
-
[36]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in
-
[37]
Advances in Neural Information Processing Systems , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Advances in Neural Information Processing Systems , year=
-
[38]
2023 , eprint=
Attribution Patching Outperforms Automated Circuit Discovery , author=. 2023 , eprint=
2023
-
[39]
arXiv preprint arXiv:2501.16615 , year=
Sparse Autoencoders Trained on the Same Data Learn Different Features , author=. arXiv preprint arXiv:2501.16615 , year=. 2501.16615 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.