Recognition: 2 theorem links
· Lean TheoremWhat if Tomorrow is the World Cup Final? Counterfactual Time Series Forecasting with Textual Conditions
Pith reviewed 2026-05-15 02:08 UTC · model grok-4.3
The pith
A text-attribution mechanism allows counterfactual time series forecasting by separating mutable and immutable factors in textual conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the task of counterfactual time series forecasting with textual conditions. We present a novel text-attribution mechanism that distinguishes mutable from immutable factors, thereby improving forecast accuracy under sophisticated and stochastic textual conditions. We propose a comprehensive evaluation framework that encompasses both factual and counterfactual settings, even in the absence of ground truth time series.
What carries the argument
The text-attribution mechanism that distinguishes mutable from immutable factors in textual conditions.
If this is right
- Forecasts can adapt to complex future events described in natural language text.
- Accuracy improves when distinguishing factors that affect the series from those that do not.
- Evaluation is possible without ground-truth data for hypothetical scenarios.
- Generalization to real-world complexities beyond simple structured conditions is achieved.
Where Pith is reading between the lines
- If the mechanism works, it could extend to other domains like economic indicators influenced by news events.
- Testable extensions include applying it to datasets with known interventions to verify the mutable/immutable split.
- Neighbouring problems in causal inference for time series might benefit from similar text-based conditioning.
Load-bearing premise
Textual conditions can be reliably decomposed into mutable and immutable factors using the proposed attribution mechanism.
What would settle it
Applying the model to a past event with counterfactual text matching the actual occurrence and verifying if the generated forecast closely matches the observed time series data.
Figures









read the original abstract
Time series forecasting has become increasingly critical in real-world scenarios, where future sequences are influenced not only by historical patterns but also by forthcoming events. In this context, forecasting must dynamically adapt to complex and stochastic future conditions, which introduces fundamental challenges in both forecasting and evaluation. Traditional methods typically rely on historical data or factual future conditions, while overlooking counterfactual scenarios. Furthermore, many existing approaches are restricted to simple structured conditions, limiting their ability to generalize to the real-world complexities. To address these gaps, we introduce the task of counterfactual time series forecasting with textual conditions, enabling more flexible and condition-aware forecasting. We propose a comprehensive evaluation framework that encompasses both factual and counterfactual settings, even in the absence of ground truth time series. Additionally, we present a novel text-attribution mechanism that distinguishes mutable from immutable factors, thereby improving forecast accuracy under sophisticated and stochastic textual conditions. The project page is at https://seqml.github.io/TADiff/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of counterfactual time series forecasting conditioned on textual descriptions of future events. It proposes a text-attribution mechanism to distinguish mutable from immutable factors within those conditions and presents an evaluation framework that assesses both factual and counterfactual performance even when no ground-truth counterfactual time series are available.
Significance. If the attribution mechanism reliably decomposes factors and the evaluation proxies are shown to track actual counterfactual fidelity, the work could meaningfully extend time series forecasting to handle complex, unstructured future conditions such as event descriptions, with applications in domains like sports, economics, and logistics.
major comments (2)
- [Abstract and Evaluation Framework] Abstract and Evaluation Framework: the claim that the framework 'encompasses both factual and counterfactual settings, even in the absence of ground truth time series' is load-bearing for all reported accuracy gains, yet no derivation or ablation is supplied showing that the chosen proxies (consistency with factual baselines or synthetic perturbations) correlate with true counterfactual outcomes; without this, performance improvements may be artifacts of the proxy rather than evidence of better attribution.
- [Text-attribution mechanism] Text-attribution mechanism: the assertion that the mechanism 'distinguishes mutable from immutable factors' and thereby improves accuracy under stochastic textual conditions is presented without an explicit decomposition procedure, loss term, or validation that the separation is not circular (i.e., defined from the same data used for forecasting); this directly affects the central performance claim.
minor comments (2)
- [Abstract] The project page URL is given but no link to code or data is mentioned in the abstract; adding a reproducibility statement would strengthen the submission.
- [Notation] Notation for mutable/immutable factors should be defined once and used consistently; currently the distinction appears only descriptively.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional rigor will strengthen the presentation of the evaluation framework and the text-attribution mechanism. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation Framework] Abstract and Evaluation Framework: the claim that the framework 'encompasses both factual and counterfactual settings, even in the absence of ground truth time series' is load-bearing for all reported accuracy gains, yet no derivation or ablation is supplied showing that the chosen proxies (consistency with factual baselines or synthetic perturbations) correlate with true counterfactual outcomes; without this, performance improvements may be artifacts of the proxy rather than evidence of better attribution.
Authors: We agree that explicit validation of the proxies is necessary to support the central claims. Section 4 of the manuscript describes the evaluation framework, including factual consistency checks against observed baselines and synthetic perturbations as proxies for counterfactual assessment when ground truth is unavailable. However, a formal derivation linking these proxies to counterfactual fidelity and a dedicated ablation study are indeed absent. In the revised manuscript we will add (i) a derivation showing how the proxies follow from standard counterfactual identification assumptions and (ii) an ablation on synthetic datasets where ground-truth counterfactual trajectories can be generated, demonstrating that improvements in the proxy metrics track improvements in actual counterfactual accuracy. This revision will be marked as a new subsection in the evaluation framework. revision: yes
-
Referee: Text-attribution mechanism: the assertion that the mechanism 'distinguishes mutable from immutable factors' and thereby improves accuracy under stochastic textual conditions is presented without an explicit decomposition procedure, loss term, or validation that the separation is not circular (i.e., defined from the same data used for forecasting); this directly affects the central performance claim.
Authors: We acknowledge that the description of the text-attribution mechanism in Section 3 requires greater precision. The mechanism employs an attribution module that processes textual condition embeddings through a cross-attention layer to produce per-factor masks, with a dedicated attribution loss that encourages separation between mutable and immutable components. Nevertheless, the step-by-step decomposition algorithm, the exact mathematical form of the attribution loss, and an explicit check against circularity (i.e., that the separation is not derived solely from the forecasting objective) were not provided. In the revision we will insert (i) a detailed algorithmic procedure for the decomposition, (ii) the full loss formulation, and (iii) a controlled experiment that trains the attribution module on textual conditions alone and verifies that the resulting mutable/immutable partition improves downstream forecasting only when the attribution loss is active, thereby demonstrating non-circularity. revision: yes
Circularity Check
No significant circularity; new task definition and mechanism are self-contained proposals
full rationale
The paper defines a new task of counterfactual time series forecasting with textual conditions and introduces a text-attribution mechanism to separate mutable and immutable factors. No equations, derivations, or fitted parameters are shown that reduce the claimed accuracy improvements or evaluation framework to inputs defined from the same data by construction. The evaluation is explicitly framed as operating without ground-truth counterfactual series, presented as a methodological contribution rather than a statistical prediction forced by prior fits. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way that collapses the central claims back to the paper's own inputs. The derivation chain remains independent as a task formulation and proxy-based evaluation design.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
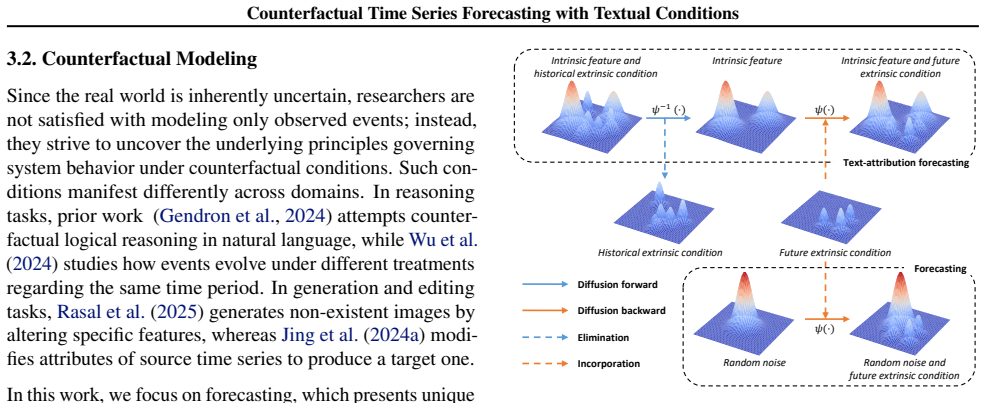
TADIFF first attributes historical sequences to intrinsic features ... via condition-aware diffusion forward process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Modeling long-and short-term temporal patterns with deep neural networks , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[5]
Automated contrastive learning strategy search for time series , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
-
[6]
Proceedings of the Web Conference 2021 , pages=
Network of tensor time series , author=. Proceedings of the Web Conference 2021 , pages=
work page 2021
-
[7]
arXiv preprint arXiv:2302.04355 , year=
MedDiff: Generating electronic health records using accelerated denoising diffusion model , author=. arXiv preprint arXiv:2302.04355 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Contiformer: Continuous-time transformer for irregular time series modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2310.18688 , year=
Clairvoyance: A pipeline toolkit for medical time series , author=. arXiv preprint arXiv:2310.18688 , year=
-
[10]
arXiv preprint arXiv:2402.06656 , year=
Diffsformer: A diffusion transformer on stock factor augmentation , author=. arXiv preprint arXiv:2402.06656 , year=
-
[11]
arXiv preprint arXiv:2210.02186 , year=
Timesnet: Temporal 2d-variation modeling for general time series analysis , author=. arXiv preprint arXiv:2210.02186 , year=
-
[12]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[13]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[14]
The eleventh international conference on learning representations , year=
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting , author=. The eleventh international conference on learning representations , year=
-
[15]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
itransformer: Inverted transformers are effective for time series forecasting , author=. arXiv preprint arXiv:2310.06625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
A time series is worth 64 words: Long-term forecasting with transformers , author=. arXiv preprint arXiv:2211.14730 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv preprint arXiv:2403.01742 , year=
Diffusion-ts: Interpretable diffusion for general time series generation , author=. arXiv preprint arXiv:2403.01742 , year=
-
[18]
Transactions on Machine Learning Research , issn=
Chronos: Learning the Language of Time Series , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[19]
Forty-first International Conference on Machine Learning , year=
Unified Training of Universal Time Series Forecasting Transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
arXiv preprint arXiv:2406.01638 , year=
Timecma: Towards llm-empowered time series forecasting via cross-modality alignment , author=. arXiv preprint arXiv:2406.01638 , year=
-
[21]
arXiv preprint arXiv:2310.01728 , year=
Time-llm: Time series forecasting by reprogramming large language models , author=. arXiv preprint arXiv:2310.01728 , year=
-
[22]
arXiv preprint arXiv:2406.08627 , year=
Time-mmd: A new multi-domain multimodal dataset for time series analysis , author=. arXiv preprint arXiv:2406.08627 , year=
-
[23]
From News to Forecast: Integrating Event Analysis in
Xinlei Wang and Maike Feng and Jing Qiu and Jinjin Gu and Junhua Zhao , booktitle=. From News to Forecast: Integrating Event Analysis in. 2024 , url=
work page 2024
-
[24]
arXiv preprint arXiv:2405.13522 , year=
Intervention-Aware Forecasting: Breaking Historical Limits from a System Perspective , author=. arXiv preprint arXiv:2405.13522 , year=
-
[25]
arXiv preprint arXiv:2502.04395 , year=
Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting , author=. arXiv preprint arXiv:2502.04395 , year=
-
[26]
arXiv preprint arXiv:2507.21830 , year=
DualSG: A Dual-Stream Explicit Semantic-Guided Multivariate Time Series Forecasting Framework , author=. arXiv preprint arXiv:2507.21830 , year=
-
[27]
IEEE Signal Processing Letters , year=
FTMixer: Frequency and Time Domain Representations Fusion for Time Series Forecasting , author=. IEEE Signal Processing Letters , year=
-
[28]
arXiv preprint arXiv:2410.06392 , year=
Counterfactual causal inference in natural language with large language models , author=. arXiv preprint arXiv:2410.06392 , year=
-
[29]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Counterfactual generative models for time-varying treatments , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[30]
arXiv preprint arXiv:2506.07883 , year=
Diffusion Counterfactual Generation with Semantic Abduction , author=. arXiv preprint arXiv:2506.07883 , year=
-
[31]
Advances in Neural Information Processing Systems , year=
Towards Editing Time Series , author=. Advances in Neural Information Processing Systems , year=
-
[32]
International conference on machine learning , pages=
Causal transformer for estimating counterfactual outcomes , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[33]
arXiv preprint arXiv:2508.13355 , year=
Counterfactual Probabilistic Diffusion with Expert Models , author=. arXiv preprint arXiv:2508.13355 , year=
-
[34]
International Conference on Machine Learning , pages=
Self-interpretable time series prediction with counterfactual explanations , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[35]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[36]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
International Conference on Machine Learning , year=
VerbalTS: Generating Time Series from Texts , author=. International Conference on Machine Learning , year=
-
[38]
arXiv preprint arXiv:2504.19669 , year=
Multimodal Conditioned Diffusive Time Series Forecasting , author=. arXiv preprint arXiv:2504.19669 , year=
-
[39]
Haoyi Zhou and Shanghang Zhang and Jieqi Peng and Shuai Zhang and Jianxin Li and Hui Xiong and Wancai Zhang , title =. The Thirty-Fifth
- [40]
-
[41]
Sundial: A Family of Highly Capable Time Series Foundation Models
Sundial: A Family of Highly Capable Time Series Foundation Models , author=. arXiv preprint arXiv:2502.00816 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2403.02682 , year=
Time weaver: A conditional time series generation model , author=. arXiv preprint arXiv:2403.02682 , year=
- [43]
-
[44]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[45]
European conference on computer vision , pages=
Long-clip: Unlocking the long-text capability of clip , author=. European conference on computer vision , pages=. 2024 , organization=
work page 2024
-
[46]
Time series feature extraction on basis of scalable hypothesis tests (tsfresh--a python package) , author=. Neurocomputing , volume=. 2018 , publisher=
work page 2018
-
[47]
The early mathematical manuscripts of Leibniz , author=. 2012 , publisher=
work page 2012
-
[48]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[49]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Forty-second International Conference on Machine Learning , year=
Context is Key: A Benchmark for Forecasting with Essential Textual Information , author=. Forty-second International Conference on Machine Learning , year=
-
[51]
arXiv preprint arXiv:2508.09904 , year=
Beyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs , author=. arXiv preprint arXiv:2508.09904 , year=
-
[52]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning , author=. arXiv preprint arXiv:2506.15799 , year=
-
[53]
arXiv preprint arXiv:2603.04767 , year=
ConTSG-Bench: A Unified Benchmark for Conditional Time Series Generation , author=. arXiv preprint arXiv:2603.04767 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.