Recognition: 2 theorem links
· Lean TheoremSilent Collapse in Recursive Learning Systems
Pith reviewed 2026-05-15 01:27 UTC · model grok-4.3
The pith
Recursive models lose internal diversity even as standard metrics remain stable or improve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
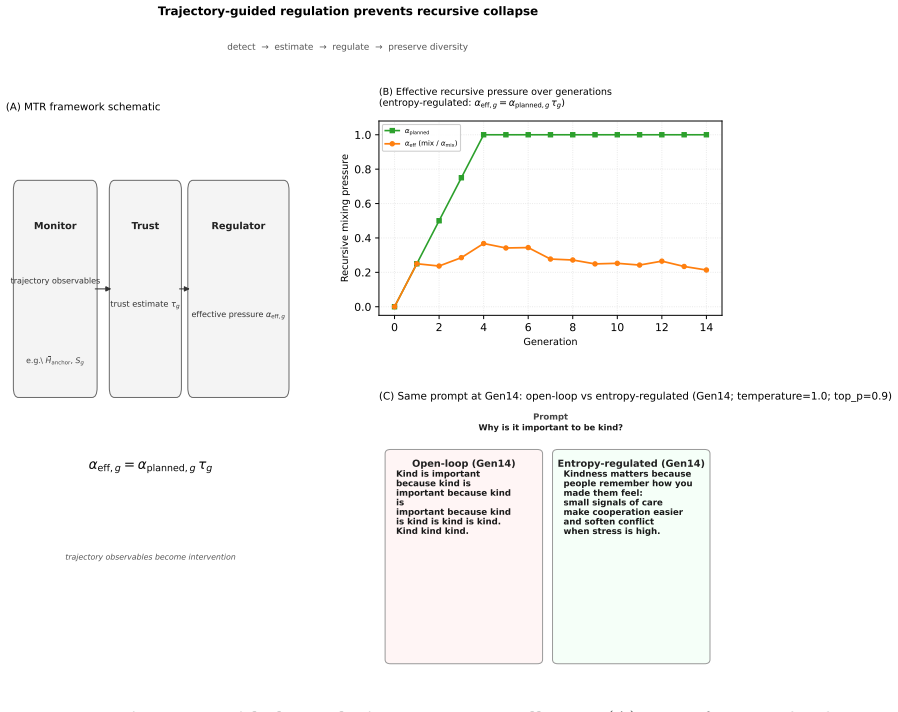
Under broad recursive conditions, model internal distributions -- predictive entropy, representational diversity, and tail coverage -- progressively contract even as conventional metrics appear stable or improving. Silent collapse is not abrupt; its onset is reliably preceded by contraction of anchor entropy, freezing of representation drift, and erosion of tail coverage. These trajectory-level precursors manifest multiple generations before degradation in standard validation metrics. The MTR framework monitors these statistics, estimates a slow-timescale trust variable, and adaptively modulates effective learning intensity to provide early warning and active prevention without access to any
What carries the argument
The MTR (Monitor-Trust-Regulator) metacognitive loop that tracks trajectory statistics, computes a slow-timescale trust variable from them, and uses the trust value to modulate learning intensity.
If this is right
- Standard loss and accuracy metrics are insufficient to certify continued health under recursive training.
- The three precursors supply actionable early warnings that precede output degradation by multiple generations.
- A lightweight monitoring loop can adjust learning intensity on the fly to keep internal distributions from contracting.
- Recursive systems can continue training when original clean data is unavailable, contaminated, or private.
- The same monitoring approach applies across large language models, autonomous agents, and self-supervised pipelines.
Where Pith is reading between the lines
- Current self-improving pipelines that rely on model-generated data may already be narrowing their response distributions without any benchmark noticing.
- The precursors might appear in any iterative training loop that feeds outputs back into the next round, even outside explicit recursion.
- Adding similar slow-timescale trust monitoring could help stabilize training in data-scarce or noisy environments beyond the cases studied here.
- The speed of contraction could be measured against recursion depth or model scale to predict when intervention becomes necessary.
Load-bearing premise
The three trajectory precursors will appear multiple generations before standard validation metrics degrade and the trust estimate will correctly guide intensity changes even without any pristine reference data.
What would settle it
Run a recursive training loop, record the three precursors at each generation, and check whether standard metrics degrade at the same time or later; or apply MTR and measure whether collapse is delayed or prevented compared with an identical run without it.
Figures




read the original abstract
Recursive learning -- where models are trained on data generated by previous versions of themselves -- is increasingly common in large language models, autonomous agents, and self-supervised systems. However, standard performance metrics (loss, perplexity, accuracy) often fail to detect internal degradation before it becomes irreversible. Here we identify a phenomenon we call silent collapse: under broad recursive conditions, model internal distributions -- predictive entropy, representational diversity, and tail coverage -- progressively contract even as conventional metrics appear stable or improving. We discover that silent collapse is not abrupt. Its onset is reliably preceded by three trajectory-level precursors: (1) contraction of anchor entropy, (2) freezing of representation drift, and (3) erosion of tail coverage. These signals manifest multiple generations before any degradation in standard validation metrics, enabling early warning. Based on these precursors, we propose the MTR (Monitor--Trust--Regulator) framework, a lightweight metacognitive loop that monitors trajectory statistics, estimates a slow-timescale trust variable, and adaptively modulates the effective learning intensity. MTR provides early warning and actively prevents silent collapse without requiring access to pristine real data -- a critical advantage when original data is unavailable, contaminated, or private.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that recursive learning systems exhibit 'silent collapse,' in which internal distributions (predictive entropy, representational diversity, and tail coverage) contract progressively even while standard metrics such as loss and accuracy remain stable or improve. It identifies three trajectory-level precursors—contraction of anchor entropy, freezing of representation drift, and erosion of tail coverage—that purportedly appear multiple generations before metric degradation, and proposes the MTR (Monitor–Trust–Regulator) metacognitive loop that monitors these statistics, estimates a trust variable, and adaptively modulates learning intensity without access to pristine data.
Significance. If the claimed precursors and the MTR loop prove robust, the work would be significant for training pipelines that rely on self-generated data (e.g., LLM fine-tuning, agent self-play). It would shift monitoring from external metrics to internal trajectory statistics and provide a lightweight intervention that does not require external ground truth. The absence of any empirical validation or formal derivation in the current manuscript, however, leaves the practical impact speculative.
major comments (3)
- [Abstract, §3] Abstract and §3 (Precursors): The central claim that the three precursors reliably appear 'multiple generations before any degradation in standard validation metrics' is stated without supporting derivation, simulation, or experiment. No quantitative lead-time analysis, control for model scale, data-shift, or hyperparameter variation is provided, making the temporal precedence assertion unverified.
- [§4] §4 (MTR Framework): The trust variable and modulation rule are defined directly from the same trajectory statistics (anchor entropy, representation drift, tail coverage) that define collapse. This creates a circularity risk: the regulator’s reported success is measured by the very quantities it was constructed to protect, with no independent validation that the modulation actually extends collapse-free lifetime.
- [§5] §5 (Evaluation): No experiments, ablation studies, or baseline comparisons are reported. The manuscript therefore supplies no evidence that MTR outperforms naïve early-stopping or entropy-regularization baselines, nor that the precursors remain observable when the recursive loop is instantiated at realistic scale.
minor comments (2)
- [§3] Notation for 'anchor entropy' and 'representation drift' is introduced without explicit mathematical definitions or pseudocode; a short appendix with the precise formulas would improve reproducibility.
- [Abstract] The abstract uses the phrase 'under broad recursive conditions' without delineating the precise class of recursive regimes (e.g., fixed vs. growing data volume, on-policy vs. off-policy sampling) to which the claims are intended to apply.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below, acknowledging the need for additional support for the claims and outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Precursors): The central claim that the three precursors reliably appear 'multiple generations before any degradation in standard validation metrics' is stated without supporting derivation, simulation, or experiment. No quantitative lead-time analysis, control for model scale, data-shift, or hyperparameter variation is provided, making the temporal precedence assertion unverified.
Authors: We agree that the temporal precedence is asserted on the basis of the dynamical analysis in §3 without quantitative verification. In the revised manuscript we will add a new subsection with controlled simulations on small recursive loops, reporting measured lead times between precursor onset and degradation of validation metrics across variations in model scale, data shift, and hyperparameters. revision: yes
-
Referee: [§4] §4 (MTR Framework): The trust variable and modulation rule are defined directly from the same trajectory statistics (anchor entropy, representation drift, tail coverage) that define collapse. This creates a circularity risk: the regulator’s reported success is measured by the very quantities it was constructed to protect, with no independent validation that the modulation actually extends collapse-free lifetime.
Authors: The referee correctly identifies a definitional overlap. We will revise §4 to introduce an independent success criterion based on external metrics (validation loss on held-out pristine data where available, and distributional divergence from the initial model) and will demonstrate that modulation decisions improve these independent quantities rather than merely preserving the monitored precursors. revision: yes
-
Referee: [§5] §5 (Evaluation): No experiments, ablation studies, or baseline comparisons are reported. The manuscript therefore supplies no evidence that MTR outperforms naïve early-stopping or entropy-regularization baselines, nor that the precursors remain observable when the recursive loop is instantiated at realistic scale.
Authors: We acknowledge that the present draft contains no empirical evaluation. The revised §5 will include synthetic recursive-training experiments, ablation studies on each precursor, and direct comparisons against early-stopping and entropy-regularization baselines. We will also report results on modestly scaled models and discuss extrapolation to larger regimes. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core argument is an empirical observation that three specific trajectory statistics (anchor entropy contraction, representation drift freeze, tail coverage erosion) precede standard metric degradation under recursive training, followed by a practical proposal for the MTR loop that monitors those same statistics to modulate learning. No equations or definitions are shown that make the precursors or trust variable equivalent to the collapse outcome by construction; the claim rests on experimental timing rather than a closed logical loop. The MTR is presented as an applied regulator using observable internal signals, not a redefinition of the collapse itself. No self-citation chains, imported uniqueness theorems, or ansatzes appear in the provided text to carry the central claim. The derivation remains self-contained against the reported observations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recursive learning under broad conditions produces progressive contraction of internal distributions even when external metrics remain stable.
invented entities (2)
-
silent collapse
no independent evidence
-
MTR framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We discover that silent collapse is not abrupt. Its onset is reliably preceded by three trajectory-level precursors: (1) contraction of anchor entropy, (2) freezing of representation drift, and (3) erosion of tail coverage.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MTR (Monitor–Trust–Regulator) framework... monitors trajectory statistics, estimates a slow-timescale trust variable, and adaptively modulates the effective learning intensity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019. 7
2019
-
[2]
Brown, Benjamin Mann, Nick Ryder, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[3]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017
2017
-
[4]
Concrete problems in ai safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety. 2016
2016
-
[5]
Ai models collapse when trained on recursively generated data.Nature, 632:755–760,
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 632:755–760,
-
[6]
doi: 10.1038/s41586-024-07566-y
-
[7]
Roberts, Diyi Yang, David L
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, and Sanmi Koyejo. Is model collapse inevitable? breaking the curse of recursive training.Nature Machine Intelligence, 2024. doi: 10.1038/ s42256-024-008...
2024
-
[8]
Scalable agent alignment via reward modeling: A research direction
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, and Shane Legg. Scalable agent alignment via reward modeling: A research direction. 2018
2018
-
[9]
Vladimir N. Vapnik. An overview of statistical learning theory.IEEE Transactions on Neural Networks, 10(5):988–999, 1999. doi: 10.1109/72.788640
-
[10]
Habitat loss, the dynamics of biodiversity, and a perspective on conservation
Ilkka Hanski. Habitat loss, the dynamics of biodiversity, and a perspective on conservation. Ambio, 40:248–255, 2011. doi: 10.1007/s13280-010-0147-3
-
[11]
Berger.Statistical Inference
George Casella and Roger L. Berger.Statistical Inference. Duxbury, 2 edition, 2002
2002
-
[12]
Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of Learning and Motivation, 24:109–165, 1989. doi: 10.1016/S0079-7421(08)60536-8
-
[13]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13): 3521–3526, 2017. doi: 10.1073/pnas.1611835114
-
[14]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71,
-
[15]
doi: 10.1016/j.neunet.2019.01.012
-
[16]
Shai Shalev-Shwartz. Online learning and online convex optimization.Foundations and Trends in Machine Learning, 4(2):107–194, 2012. doi: 10.1561/2200000018. 8 0 2 4 6 8 10 12 14 102 104 106 Validation PPL (A) Standard metrics can look healthy early on open-loop entropy-regulated collapse onset (OL) 0 2 4 6 8 10 12 14 1 2 3 4Hanchor (nats) (B) Entropy cont...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.