Composable Crystals: Controllable Materials Discovery via Concept Learning
Pith reviewed 2026-06-30 21:50 UTC · model grok-4.3
The pith
Recombining concepts discovered by a VQ-VAE allows controllable generation of novel crystals outside the training distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training a VQ-VAE on crystal data reveals interpretable concepts based on local atomic environments and global symmetry patterns, which generalize across distributions and can be recombined using a composition generator to produce valid, stable, unique, and novel crystals beyond the training set.
What carries the argument
The vector-quantized variational autoencoder that discovers a shared set of reusable crystal concepts serving as building blocks for guided generation.
If this is right
- Controllable exploration of novel crystals rather than unconstrained random sampling.
- Up to 53.2% and 51.7% improvement on the V.S.U.N metric on MP-20 and Alex-MP-20 datasets.
- Particular gains in novelty of generated crystals.
- Concepts exhibit interpretability from local and global patterns and generalize to different crystal distributions.
Where Pith is reading between the lines
- The iterative refinement of the composition generator using the model's own high-quality samples could create a feedback loop for continuous improvement in generation quality.
- If the concepts are generalizable, the method might reduce reliance on massive training datasets for materials discovery tasks.
- The shared concepts could enable transfer between different crystal datasets without full retraining.
Load-bearing premise
The learned concepts from the VQ-VAE can be recombined into valid and stable crystals that do not require additional post-processing or retraining to achieve the claimed controllability.
What would settle it
A test where many concept-recombined crystals turn out to be invalid or unstable, or where the novelty gains disappear when compared to an improved base model without concepts.
Figures
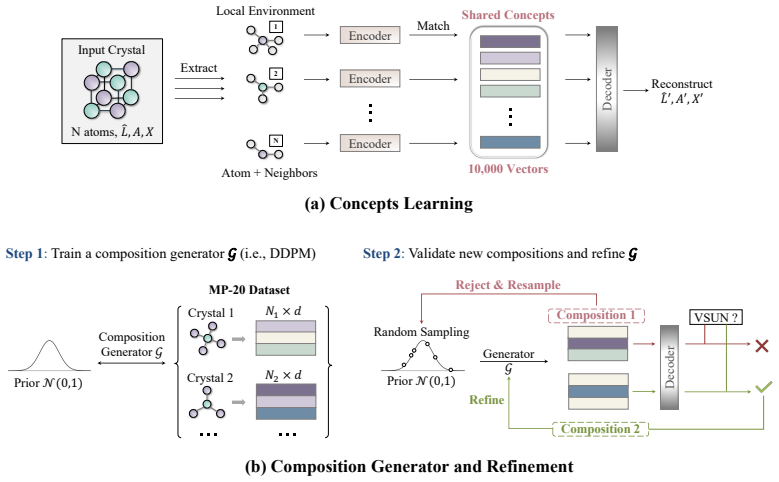


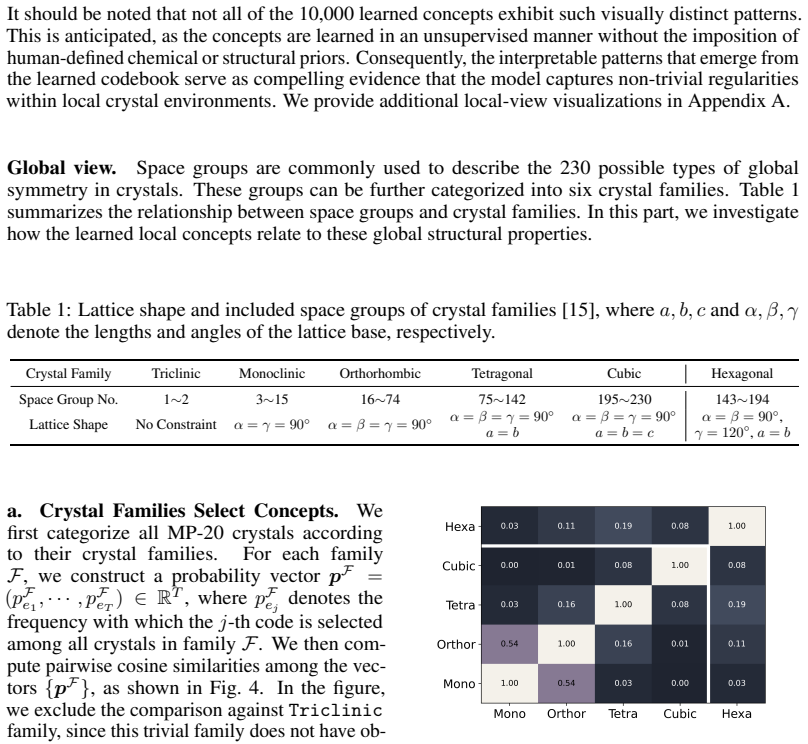

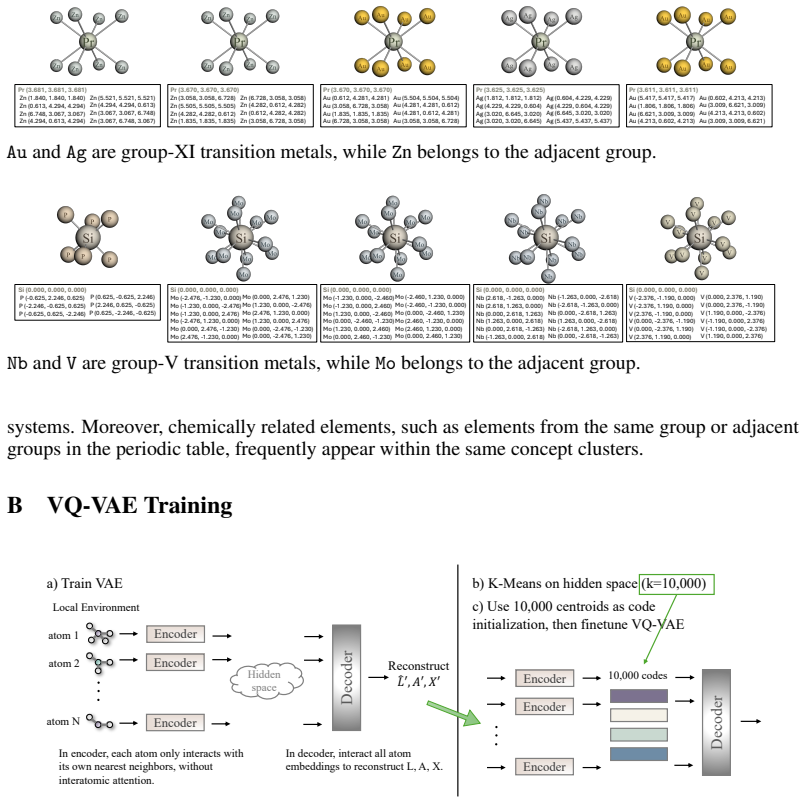
read the original abstract
De novo crystal generation, a central task in materials discovery, aims to generate crystals that are simultaneously valid, stable, unique, and novel. Existing methods mainly rely on black-box stochastic sampling, providing limited control over how generated structures move beyond the observed distribution. In this paper, we introduce a concept-based compositional framework for crystal generation. We train a vector-quantized variational autoencoder to automatically discover a shared set of reusable crystal concepts, which serve as building blocks for guided generation. These learned concepts naturally exhibit interpretability from both local atomic environments and global symmetry patterns, and generalize to crystals from different distributions. By recombining such concepts, our framework enables controllable exploration of novel crystals beyond the training distribution, rather than relying solely on unconstrained random sampling. To further improve composition efficiency, we introduce a composition generator and iteratively refine it using high-quality samples generated by the model itself. The resulting concept compositions are then used to condition downstream crystal generation. Numerical experiments on MP-20 and Alex-MP-20 show that compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a concept-based framework for de novo crystal generation. A VQ-VAE is trained to discover reusable, interpretable concepts from crystal structures that generalize across distributions. These concepts are recombined via a composition generator that is iteratively refined on self-generated high-quality samples; the resulting compositions condition a downstream generator. Experiments on MP-20 and Alex-MP-20 report that concept compositing improves a base model by up to 53.2% and 51.7% on the V.S.U.N. metric, with largest gains in novelty, enabling controllable exploration beyond the training distribution.
Significance. If the central claims hold without hidden selection effects, the work would offer a concrete advance over black-box sampling methods by providing interpretable, reusable building blocks and explicit controllability. The VQ-VAE concept discovery and reported generalization to out-of-distribution crystals are potentially valuable contributions to materials informatics.
major comments (2)
- [Abstract / Methods (composition generator)] Abstract (and the description of the composition generator): the iterative refinement step that uses 'high-quality samples generated by the model itself' to train the composition generator is load-bearing for the controllability claim. It is unclear whether any validity/stability/quality filter is applied during this self-supervised loop; if so, the reported V.S.U.N. gains (53.2% / 51.7%) cannot be attributed solely to recombination of the learned VQ-VAE concepts and the weakest assumption (generalizability without post-hoc mechanisms) is not yet supported.
- [Abstract / Experiments] Abstract: the claim that 'compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty' requires an ablation that isolates the effect of concept recombination from any curation performed during iterative refinement. Without such a controlled comparison, the numerical results do not yet establish that the framework enables exploration 'rather than relying solely on unconstrained random sampling.'
minor comments (1)
- [Abstract] The V.S.U.N. metric is referenced without an explicit definition or citation in the provided abstract; a clear statement of its components and how novelty is measured would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and commit to revisions that improve clarity and strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract / Methods (composition generator)] Abstract (and the description of the composition generator): the iterative refinement step that uses 'high-quality samples generated by the model itself' to train the composition generator is load-bearing for the controllability claim. It is unclear whether any validity/stability/quality filter is applied during this self-supervised loop; if so, the reported V.S.U.N. gains (53.2% / 51.7%) cannot be attributed solely to recombination of the learned VQ-VAE concepts and the weakest assumption (generalizability without post-hoc mechanisms) is not yet supported.
Authors: We agree that the description of the iterative refinement requires greater precision. The manuscript currently states only that the composition generator is refined on 'high-quality samples generated by the model itself,' without enumerating the exact selection criteria. In the revised version we will expand the Methods section to specify the precise validity, stability, and quality thresholds (if any) applied during self-supervised iteration, thereby clarifying whether post-hoc mechanisms beyond concept recombination are involved. revision: yes
-
Referee: [Abstract / Experiments] Abstract: the claim that 'compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty' requires an ablation that isolates the effect of concept recombination from any curation performed during iterative refinement. Without such a controlled comparison, the numerical results do not yet establish that the framework enables exploration 'rather than relying solely on unconstrained random sampling.'
Authors: We acknowledge the value of an explicit ablation that separates the contribution of concept recombination from any curation effects of the iterative loop. We will add this controlled comparison in the revised manuscript, reporting V.S.U.N. metrics for (i) the base generator, (ii) the composition generator without iterative refinement, and (iii) the full pipeline, thereby isolating the impact of learned-concept recombination. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, parameter-fitting steps, or self-referential reductions where a claimed prediction or result is equivalent to its inputs by construction. The iterative refinement of the composition generator is described at a high level without exhibiting a specific loop that forces outputs from inputs (e.g., no fitted parameter renamed as prediction). No self-citations, uniqueness theorems, or ansatzes are quoted. The framework's claims rest on empirical numerical experiments rather than a closed definitional chain, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J Ballard, Joshua Bambrick, et al. Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
2024
-
[2]
Specformer: Spectral graph neural networks meet transformers.arXiv preprint arXiv:2303.01028, 2023
Deyu Bo, Chuan Shi, Lele Wang, and Renjie Liao. Specformer: Spectral graph neural networks meet transformers.arXiv preprint arXiv:2303.01028, 2023
-
[3]
Space group informed transformer for crystalline materials generation, 2024.URL https://arxiv
Zhendong Cao, Xiaoshan Luo, Jian Lv, and Lei Wang. Space group informed transformer for crystalline materials generation, 2024.URL https://arxiv. org/abs/2403.15734, 11
-
[4]
Space group equivariant crystal diffusion.arXiv preprint arXiv:2505.10994, 2025
Rees Chang, Angela Pak, Alex Guerra, Ni Zhan, Nick Richardson, Elif Ertekin, and Ryan P Adams. Space group equivariant crystal diffusion.arXiv preprint arXiv:2505.10994, 2025
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
The faiss library
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre- Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library. 2024
2024
-
[7]
A generalization of transformer networks to graphs
Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs. arXiv preprint arXiv:2012.09699, 2020
-
[8]
Alex M. Ganose, Hrushikesh Sahasrabuddhe, Mark Asta, Kevin Beck, Tathagata Biswas, Alexan- der Bonkowski, Joana Bustamante, Xin Chen, Yuan Chiang, Daryl Chrzan, Jacob Clary, Orion Cohen, Christina Ertural, Max Gallant, Janine George, Sophie Gerits, Rhys Goodall, Rishabh Guha, Geoffroy Hautier, Matthew Horton, Aaron Kaplan, Ryan Kingsbury, Matthew Kuner, B...
2025
-
[9]
N Gruver, A Sriram, A Madotto, AG Wilson, CL Zitnick, and Z Ulissi. Fine-tuned language models generate stable inorganic materials as text, arxiv, 2024.arXiv preprint arXiv:2402.04379, 10
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Commentary: The materials project: A materials genome approach to accelerating materials innovation.APL materials, 1(1), 2013
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, et al. Commentary: The materials project: A materials genome approach to accelerating materials innovation.APL materials, 1(1), 2013
2013
-
[14]
Crystal structure prediction by joint equivariant diffusion.Advances in Neural Information Processing Systems, 36:17464–17497, 2023
Rui Jiao, Wenbing Huang, Peijia Lin, Jiaqi Han, Pin Chen, Yutong Lu, and Yang Liu. Crystal structure prediction by joint equivariant diffusion.Advances in Neural Information Processing Systems, 36:17464–17497, 2023
2023
-
[15]
Space group constrained crystal generation.arXiv preprint arXiv:2402.03992, 2024
Rui Jiao, Wenbing Huang, Yu Liu, Deli Zhao, and Yang Liu. Space group constrained crystal generation.arXiv preprint arXiv:2402.03992, 2024. 11
-
[16]
Chaitanya K Joshi, Xiang Fu, Yi-Lun Liao, Vahe Gharakhanyan, Benjamin Kurt Miller, Anuroop Sriram, and Zachary W Ulissi. All-atom diffusion transformers: Unified generative modelling of molecules and materials.arXiv preprint arXiv:2503.03965, 2025
-
[17]
Llm meets diffusion: A hybrid framework for crystal material generation
Subhojyoti Khastagir, Kishalay Das, Pawan Goyal, Seung-Cheol Lee, Satadeep Bhattacharjee, and Niloy Ganguly. Llm meets diffusion: A hybrid framework for crystal material generation. arXiv preprint arXiv:2510.23040, 2025
-
[18]
Kresse and J
G. Kresse and J. Furthmüller. Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set.Phys. Rev. B, 54:11169–11186, Oct 1996
1996
-
[19]
Kresse and D
G. Kresse and D. Joubert. From ultrasoft pseudopotentials to the projector augmented-wave method.Phys. Rev. B, 59:1758–1775, Jan 1999
1999
-
[20]
Daniel Levy, Siba Smarak Panigrahi, Sékou-Oumar Kaba, Qiang Zhu, Kin Long Kelvin Lee, Mikhail Galkin, Santiago Miret, and Siamak Ravanbakhsh. Symmcd: Symmetry-preserving crystal generation with diffusion models.arXiv preprint arXiv:2502.03638, 2025
-
[21]
Flowmm: Generating materials with riemannian flow matching
Benjamin Kurt Miller, Ricky TQ Chen, Anuroop Sriram, and Brandon M Wood. Flowmm: Generating materials with riemannian flow matching. InForty-first International Conference on Machine Learning, 2024
2024
-
[22]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[24]
Python materials genomics (pymatgen): A robust, open-source python library for materials analysis.Computational Materials Science, 68:314–319, 2013
Shyue Ping Ong, William Davidson Richards, Anubhav Jain, Geoffroy Hautier, Michael Kocher, Shreyas Cholia, Dan Gunter, Vincent L Chevrier, Kristin A Persson, and Gerbrand Ceder. Python materials genomics (pymatgen): A robust, open-source python library for materials analysis.Computational Materials Science, 68:314–319, 2013
2013
-
[25]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[26]
Perdew, Kieron Burke, and Matthias Ernzerhof
John P. Perdew, Kieron Burke, and Matthias Ernzerhof. Generalized gradient approximation made simple.Phys. Rev. Lett., 77:3865–3868, Oct 1996
1996
-
[27]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[28]
Improving machine-learning models in materials science through large datasets.Materials Today Physics, 48:101560, 2024
Jonathan Schmidt, Tiago FT Cerqueira, Aldo H Romero, Antoine Loew, Fabian Jäger, Hai-Chen Wang, Silvana Botti, and Miguel AL Marques. Improving machine-learning models in materials science through large datasets.Materials Today Physics, 48:101560, 2024
2024
-
[29]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[30]
Flowllm: Flow matching for material generation with large language models as base distributions.Advances in Neural Information Processing Systems, 37:46025–46046, 2024
Anuroop Sriram, Benjamin K Miller, Ricky T Chen, and Brandon M Wood. Flowllm: Flow matching for material generation with large language models as base distributions.Advances in Neural Information Processing Systems, 37:46025–46046, 2024
2024
-
[31]
Yuan Sui, Yanming Zhang, Yi Liao, Yu Gu, Guohua Tang, Zhongqian Sun, Wei Yang, and Bryan Hooi. What-if analysis of large language models: Explore the game world using proactive thinking.arXiv preprint arXiv:2509.04791, 2025
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[34]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[35]
Conceptmix: A compositional image generation benchmark with controllable difficulty.Advances in Neural Information Processing Systems, 37:86004–86047, 2024
Xindi Wu, Dingli Yu, Yangsibo Huang, Olga Russakovsky, and Sanjeev Arora. Conceptmix: A compositional image generation benchmark with controllable difficulty.Advances in Neural Information Processing Systems, 37:86004–86047, 2024
2024
-
[36]
Tian Xie, Xiang Fu, Octavian-Eugen Ganea, Regina Barzilay, and Tommi Jaakkola. Crys- tal diffusion variational autoencoder for periodic material generation.arXiv preprint arXiv:2110.06197, 2021
-
[37]
Yujie Xing, Xiao Wang, Yibo Li, Hai Huang, and Chuan Shi. Less is more: on the over- globalizing problem in graph transformers.arXiv preprint arXiv:2405.01102, 2024
-
[38]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. InInternational conference on machine learning, pages 10524–10533. PMLR, 2020
2020
-
[39]
Geometric latent diffusion models for 3d molecule generation
Minkai Xu, Alexander S Powers, Ron O Dror, Stefano Ermon, and Jure Leskovec. Geometric latent diffusion models for 3d molecule generation. InInternational Conference on Machine Learning, pages 38592–38610. PMLR, 2023
2023
-
[40]
MatterSim: A Deep Learning Atomistic Model Across Elements, Temperatures and Pressures
Han Yang, Chenxi Hu, Yichi Zhou, Xixian Liu, Yu Shi, Jielan Li, Guanzhi Li, Zekun Chen, Shuizhou Chen, Claudio Zeni, et al. Mattersim: A deep learning atomistic model across elements, temperatures and pressures.arXiv preprint arXiv:2405.04967, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Dingli Yu, Simran Kaur, Arushi Gupta, Jonah Brown-Cohen, Anirudh Goyal, and Sanjeev Arora. Skill-mix: A flexible and expandable family of evaluations for ai models.arXiv preprint arXiv:2310.17567, 2023
-
[42]
Mattergen: a generative model for inorganic materials design.arXiv preprint arXiv:2312.03687, 2023
Claudio Zeni, Robert Pinsler, Daniel Zügner, Andrew Fowler, Matthew Horton, Xiang Fu, Sasha Shysheya, Jonathan Crabbé, Lixin Sun, Jake Smith, et al. Mattergen: a generative model for inorganic materials design.arXiv preprint arXiv:2312.03687, 2023
-
[43]
Can large language models improve the adversarial robustness of graph neural networks? InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Zhongjian Zhang, Xiao Wang, Huichi Zhou, Yue Yu, Mengmei Zhang, Cheng Yang, and Chuan Shi. Can large language models improve the adversarial robustness of graph neural networks? InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2008–2019, 2025
2008
-
[44]
Graph-GRPO: Training Graph Flow Models with Reinforcement Learning
Baoheng Zhu, Deyu Bo, Delvin Ce Zhang, and Xiao Wang. Graph-grpo: Training graph flow models with reinforcement learning.arXiv preprint arXiv:2603.10395, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Local structure order parameters and site fingerprints for quantification of coordination environment and crystal structure similarity.RSC advances, 10(10):6063–6081, 2020
Nils ER Zimmermann and Anubhav Jain. Local structure order parameters and site fingerprints for quantification of coordination environment and crystal structure similarity.RSC advances, 10(10):6063–6081, 2020. 13 A Visualizing More Local Patterns encoded in Concepts In Section 4, we visualize the top-5 local atomic environments associated with two learned...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.