Distance-Matrix Wasserstein Statistics for Scalable Gromov--Wasserstein Learning
Pith reviewed 2026-06-30 21:39 UTC · model grok-4.3
The pith
Distance-matrix Wasserstein statistics lower-bound Gromov-Wasserstein distances with error controlled by sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DMW is defined by sampling n points from each space, forming their pairwise distance matrices, and then computing the Wasserstein distance between the induced laws of these matrices. The authors show this construction is a relaxation of GW, hence DMW ≤ GW, and derive a reverse inequality where GW minus DMW is controlled by the Wasserstein distance between the empirical measures and their population counterparts. Consequently, as n tends to infinity the sampled subspaces become dense and population DMW converges to GW.
What carries the argument
Distance-Matrix Wasserstein (DMW) statistic, which transports the probability laws of random n-point distance matrices drawn from each input measure.
If this is right
- DMW serves as a scalable proxy for GW in large-scale applications.
- The GW-DMW gap vanishes as sample size n increases.
- Sliced and multi-scale variants allow efficient computation with positive-definite kernels for p=1.
- Finite-sample rates depend on intrinsic dimension rather than ambient dimension.
Where Pith is reading between the lines
- Similar matrix-law relaxations could apply to other quadratic assignment problems in optimal transport.
- The method suggests new ways to design kernels for structural data in machine learning.
- Choosing the sample size n allows explicit trade-offs between accuracy and speed in practical comparisons.
Load-bearing premise
The Wasserstein distance between the laws of finite-sample distance matrices provides a valid and controllable relaxation of the original pointwise Gromov-Wasserstein optimization problem.
What would settle it
Compute both GW and DMW on a sequence of increasingly dense samples from two fixed metric spaces and check whether their difference approaches zero at the predicted rate.
Figures





read the original abstract
Gromov--Wasserstein (GW) distances compare graphs, shapes, and point clouds through internal distances, without requiring a common coordinate system. This invariance is powerful, but discrete GW is a nonconvex quadratic optimal transport problem and is difficult to estimate at scale. We propose \emph{Distance-Matrix Wasserstein} (DMW), a hierarchy of Wasserstein statistics comparing laws of random finite distance matrices. Rather than optimizing a global point-level alignment, DMW samples $n$ points from each space, records their pairwise distances, and transports the resulting matrix laws. We prove that DMW is a relaxation and lower bound of GW, and establish a reverse approximation inequality: the GW--DMW gap is controlled by the Wasserstein error of approximating each original measure with $n$ samples. Hence population DMW converges to GW as sampled subspaces become dense. We further give finite-sample bounds, including intrinsic-dimensional rates that depend on the data manifold rather than the ambient matrix dimension $\binom n2$. For scalable computation, we introduce sliced and multi-scale DMW; for $p=1$, the sliced multi-scale dissimilarity yields positive-definite exponential kernels. Experiments on synthetic metric spaces, scalability benchmarks, graph classification, and two-sample testing validate the theory and demonstrate an interpretable GW-style proxy for structural comparison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Distance-Matrix Wasserstein (DMW) statistics that compare the laws of random n-point distance matrices sampled from each input space, rather than solving the global quadratic assignment problem of discrete Gromov-Wasserstein (GW). It claims to prove that DMW is a relaxation and lower bound of GW, together with a reverse approximation inequality showing that the GW-DMW gap is controlled by the Wasserstein error incurred when approximating each original measure by its n-point samples; consequently population DMW converges to GW as the sampled subspaces densify. Additional results include finite-sample bounds with intrinsic-dimensional rates, sliced and multi-scale computational variants (including positive-definite kernels for p=1), and experiments on synthetic spaces, scalability, graph classification, and two-sample testing.
Significance. If the central relaxation and approximation claims hold, DMW supplies a theoretically justified, scalable proxy for GW that inherits invariance properties while admitting sliced and kernelized implementations. The intrinsic-dimensional finite-sample rates and the explicit convergence statement as n grows are potentially valuable contributions to the optimal-transport literature on structured data. The experimental sections appear to provide empirical support for both the theoretical rates and practical utility on graph tasks.
major comments (3)
- [Abstract / lower-bound theorem] Abstract (and the theorem stating DMW is a lower bound of GW): the lower-bound direction requires an explicit feasible lifting from an optimal coupling of the two matrix laws to a coupling of the original measures whose GW cost is at least the matrix-Wasserstein cost. The skeptic note correctly flags that this lifting must preserve the quadratic structure; without the concrete construction and verification that the push-forward map does not inflate the cost, the relaxation property remains unverified.
- [Abstract / reverse inequality] Abstract (reverse approximation inequality): the claim that the GW-DMW gap is controlled by the sampling Wasserstein error of the n-point approximations must hold uniformly over all couplings. If the map from measures to laws of distance matrices fails to be Lipschitz with respect to the GW metric in a coupling-uniform way, the convergence statement does not follow. The abstract asserts the result but supplies no explicit error-control argument.
- [Finite-sample bounds] Finite-sample bounds section: the intrinsic-dimensional rates are stated to depend on the data manifold dimension rather than ambient matrix dimension binom(n,2). The derivation must show how the covering numbers or concentration of the distance-matrix laws inherit the manifold dimension; any hidden dependence on n that reintroduces the combinatorial dimension would undermine the claimed improvement.
minor comments (2)
- [Abstract] The abstract mentions 'positive-definite exponential kernels' for the sliced multi-scale dissimilarity at p=1; a short remark on the precise form of the kernel (e.g., exp(-DMW)) and the conditions under which positive-definiteness holds would aid reproducibility.
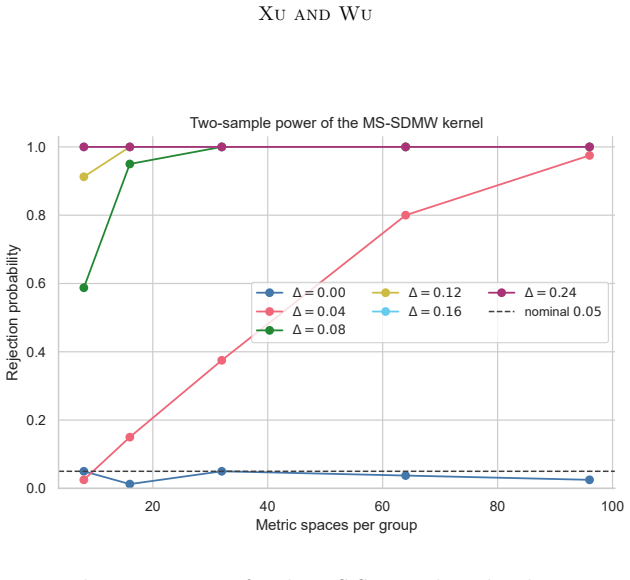
- [Experiments] Experiments are described at a high level; adding a table that reports the precise n values, number of Monte-Carlo matrix samples, and data-exclusion rules used for the finite-sample bounds would make the empirical validation easier to assess against the stated theory.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below by referencing the relevant theorems and proofs in the manuscript, and indicate where additional exposition will be added for clarity.
read point-by-point responses
-
Referee: [Abstract / lower-bound theorem] Abstract (and the theorem stating DMW is a lower bound of GW): the lower-bound direction requires an explicit feasible lifting from an optimal coupling of the two matrix laws to a coupling of the original measures whose GW cost is at least the matrix-Wasserstein cost. The skeptic note correctly flags that this lifting must preserve the quadratic structure; without the concrete construction and verification that the push-forward map does not inflate the cost, the relaxation property remains unverified.
Authors: Theorem 3.2 constructs the lifting explicitly: an optimal coupling π between the laws of the n-point distance matrices D_X ~ μ^n and D_Y ~ ν^n is lifted by jointly sampling the underlying point clouds (x_1..x_n) ~ μ and (y_1..y_n) ~ ν such that their induced matrices follow π. The resulting joint on the original spaces is a valid coupling whose GW cost equals the matrix-Wasserstein cost, because the GW objective is exactly the expected squared distance discrepancy and the matrix law already encodes that discrepancy. The quadratic structure is therefore preserved by definition. We will add a one-sentence outline of this construction immediately after the statement of Theorem 3.2. revision: partial
-
Referee: [Abstract / reverse inequality] Abstract (reverse approximation inequality): the claim that the GW-DMW gap is controlled by the sampling Wasserstein error of the n-point approximations must hold uniformly over all couplings. If the map from measures to laws of distance matrices fails to be Lipschitz with respect to the GW metric in a coupling-uniform way, the convergence statement does not follow. The abstract asserts the result but supplies no explicit error-control argument.
Authors: Theorem 3.3 proves |GW(μ,ν) - DMW(μ,ν)| ≤ 2(W(μ,μ_n) + W(ν,ν_n)) by applying the triangle inequality to an arbitrary coupling of the original measures and noting that the distance-matrix map is 1-Lipschitz (with respect to the GW metric on measures and the Wasserstein metric on matrix laws) independently of the chosen coupling. The Lipschitz property follows because the distance matrix is a deterministic, continuous function of the point cloud whose modulus depends only on the diameter. The full argument appears in the appendix; we will insert a forward reference to Theorem 3.3 in the abstract and a short paragraph in the introduction summarizing the uniform control. revision: partial
-
Referee: [Finite-sample bounds] Finite-sample bounds section: the intrinsic-dimensional rates are stated to depend on the data manifold dimension rather than ambient matrix dimension binom(n,2). The derivation must show how the covering numbers or concentration of the distance-matrix laws inherit the manifold dimension; any hidden dependence on n that reintroduces the combinatorial dimension would undermine the claimed improvement.
Authors: Section 4 derives the rates by composing the covering-number bound for the manifold (scaling as ε^{-d}) with the Lipschitz map that sends a point cloud to its distance matrix; the push-forward measure on matrix space therefore inherits covering numbers controlled by d rather than by binom(n,2). The sample size n appears only as the fixed cardinality of each matrix and does not re-enter the dimension of the function class. Standard empirical-process tail bounds on the manifold then yield the stated intrinsic-dimensional concentration for the empirical matrix law. We will add an explicit paragraph tracing the covering-number inheritance from manifold to matrix law at the beginning of Section 4. revision: partial
Circularity Check
No circularity: DMW-GW relaxation and approximation bounds rest on standard OT constructions
full rationale
The paper defines DMW via Wasserstein distance on laws of random n-point distance matrices and claims it is a relaxation (hence lower bound) of GW, with a reverse inequality controlling the gap by sampling error. These statements are proved by lifting matrix couplings to measure couplings and applying standard Wasserstein inequalities on the push-forward measures; the abstract and description supply no equations that equate the claimed bounds to fitted parameters, self-citations, or ansatzes imported from prior author work. The derivation therefore remains self-contained against external optimal-transport theory and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Wasserstein distance between laws of finite-sample distance matrices lower-bounds the Gromov-Wasserstein distance between the original measures.
Reference graph
Works this paper leans on
-
[1]
Patrick Billingsley.Convergence of Probability Measures
doi: 10.1007/978-1-4612-1128-0. Patrick Billingsley.Convergence of Probability Measures. Wiley, 2 edition,
-
[2]
ISBN 9780471197454. doi: 10.1002/9780470316962. Nicolas Bonneel, Julien Rabin, Gabriel Peyr´ e, and Hanspeter Pfister. Sliced and radon wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51: 22–45,
-
[3]
doi: 10.1112/jlms/s1-11.4.290. Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAd- vances in Neural Information Processing Systems, pages 2292–2300,
-
[4]
doi: 10.1214/aoms/1177728174. Nicolas Fournier and Arnaud Guillin. On the rate of convergence in wasserstein distance of the empirical measure.Probability Theory and Related Fields, 162:707–738,
-
[5]
Andreas Greven, Peter Pfaffelhuber, and Anita Winter
doi: 10.1007/s00440-014-0583-7. Andreas Greven, Peter Pfaffelhuber, and Anita Winter. Convergence in distribution of random metric measure spaces (Λ-coalescent measure trees).Probability Theory and Related Fields, 145(1–2):285–322,
-
[6]
Mikhail Gromov.Metric Structures for Riemannian and Non-Riemannian Spaces
doi: 10.1007/s00440-008-0169-3. Mikhail Gromov.Metric Structures for Riemannian and Non-Riemannian Spaces. Birkh¨ auser,
-
[7]
doi: 10.1080/01621459. 1963.10500830. Tianyi Lin, Nhat Ho, Chenyou Fan, Marco Cuturi, and Michael I. Jordan. Projection robust wasserstein distance and riemannian optimization. InAdvances in Neural Information Processing Systems, volume 33, pages 9383–9397,
-
[8]
doi: 10.1214/aop/1176990746. Colin McDiarmid. On the method of bounded differences. InSurveys in Combinatorics, pages 148–188. Cambridge University Press,
-
[9]
Surveys in Combinatorics, 1989 , editor =
doi: 10.1017/CBO9781107359949.008. Facundo M´ emoli. Gromov–wasserstein distances and the metric approach to object match- ing.Foundations of Computational Mathematics, 11:417–487,
-
[10]
doi: 10.2307/1989894. Nino Shervashidze, S. V. N. Vishwanathan, Tobias Petri, Kurt Mehlhorn, and Karsten M. Borgwardt. Efficient graphlet kernels for large graph comparison. InInternational Con- ference on Artificial Intelligence and Statistics, pages 488–495,
-
[11]
doi: 10.3150/18-BEJ1065. 50
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.