Recognition: 2 theorem links
· Lean TheoremWhen Are Two Networks the Same? Tensor Similarity for Mechanistic Interpretability
Pith reviewed 2026-05-15 03:13 UTC · model grok-4.3
The pith
Tensor similarity is a weight-based metric that algebraically determines when two neural networks implement the same computation by ignoring irrelevant symmetries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
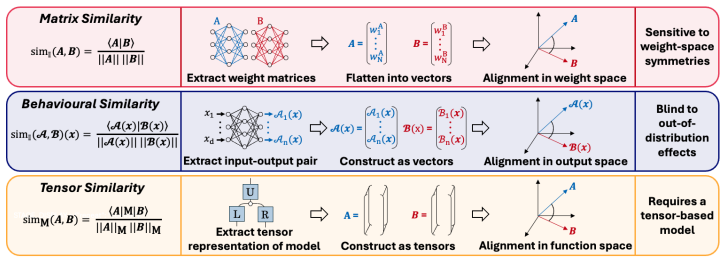
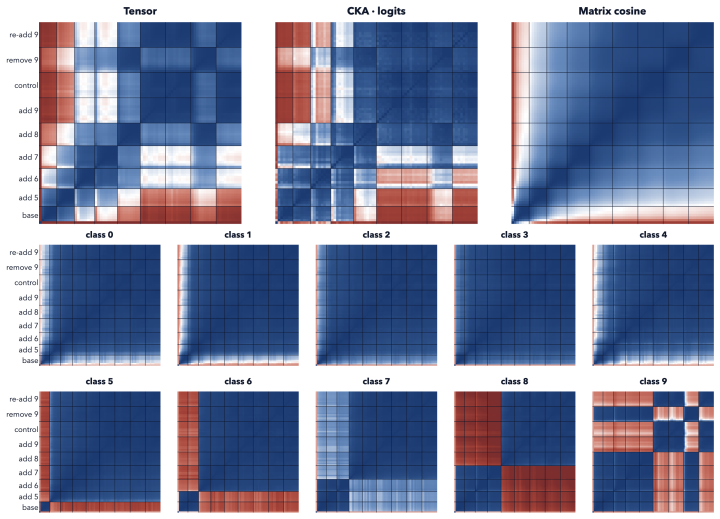
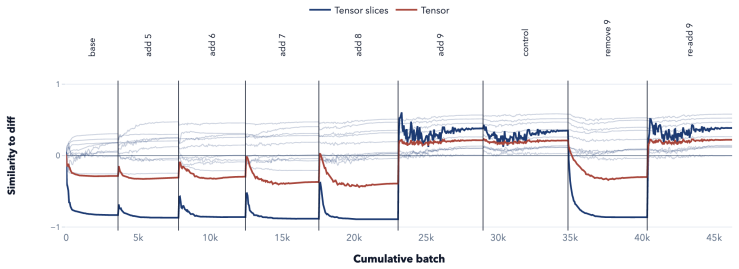
Tensor similarity is introduced as a weight-based metric for tensor-based models that remains invariant to basis changes and other symmetries. It captures global functional equivalence, including cross-layer mechanisms, through an efficient recursive algorithm. The metric tracks functional training dynamics such as grokking and backdoor insertion with higher fidelity than existing measures, reducing the task of measuring similarity and verifying faithfulness to a solved algebraic problem.
What carries the argument
Tensor similarity metric computed by a recursive algorithm that matches tensors while respecting weight-space symmetries to detect functional equivalence.
If this is right
- Tensor similarity tracks grokking and backdoor insertion during training with higher fidelity than behavior-based or parameter-based alternatives.
- Verifying that two model parts implement the same mechanism becomes an algebraic calculation rather than an empirical approximation.
- Cross-layer mechanisms are incorporated directly into the similarity computation.
- The measure remains unchanged under weight-space symmetries that leave the implemented function intact.
Where Pith is reading between the lines
- If the algebraic check holds, it could support automated circuit extraction by confirming when a candidate circuit matches a known reference.
- The approach might extend to comparing checkpoints across training runs to detect when specific computations emerge or disappear.
- It opens a route to exact equivalence checks between models trained on different random seeds or architectures that realize the same mapping.
Load-bearing premise
The recursive algorithm identifies every instance of functional equivalence in tensor-based models without missing non-linear interactions or symmetries beyond weight-space basis changes.
What would settle it
Finding two networks that produce identical outputs for every input yet receive a low tensor similarity score, or two networks with high tensor similarity that implement demonstrably different functions.
Figures






read the original abstract
Mechanistic interpretability aims to break models into meaningful parts; verifying that two such parts implement the same computation is a prerequisite. Existing similarity measures evaluate either empirical behaviour, leaving them blind to out-of-distribution mechanisms, or basis-dependent parameters, meaning they disregard weight-space symmetries. To address these issues for the class of tensor-based models, we introduce a weight-based metric, tensor similarity, that is invariant to such symmetries. This metric captures global functional equivalence and accounts for cross-layer mechanisms using an efficient recursive algorithm. Empirically, tensor similarity tracks functional training dynamics, such as grokking and backdoor insertion, with higher fidelity than existing metrics. This reduces measuring similarity and verifying faithfulness into a solved algebraic problem rather than one of empirical approximation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces tensor similarity, a weight-based metric for tensor-based neural networks that is invariant to basis changes and other weight-space symmetries. It uses an efficient recursive algorithm to capture global functional equivalence, including cross-layer mechanisms, and claims this reduces similarity measurement and faithfulness verification to an algebraic problem. Empirically, the metric tracks training dynamics such as grokking and backdoor insertion with higher fidelity than existing metrics.
Significance. If the recursive algorithm is shown to correctly compute exact functional equivalence invariant to relevant symmetries and without omissions from non-linearities, the work would provide a principled algebraic alternative to empirical similarity measures in mechanistic interpretability, potentially improving reliability in verifying that model components implement equivalent computations.
major comments (2)
- [Abstract] Abstract: The central claim that the recursive algorithm computes global functional equivalence for tensor models (including cross-layer mechanisms) without missing non-linear interactions rests on unshown correctness; no formal proof, derivation details, or exhaustive case analysis is referenced, with validation limited to correlation with training dynamics rather than direct equivalence checks.
- [Abstract] Abstract: The assertion of higher fidelity than existing metrics on training dynamics (grokking, backdoor insertion) lacks any error analysis, validation setup, or quantitative comparison details, leaving the empirical support for the algebraic reduction unassessable.
Simulated Author's Rebuttal
We thank the referee for their review and valuable feedback on our work. Below we provide point-by-point responses to the major comments, indicating where revisions will be made to address the concerns raised.
read point-by-point responses
-
Referee: The central claim that the recursive algorithm computes global functional equivalence for tensor models (including cross-layer mechanisms) without missing non-linear interactions rests on unshown correctness; no formal proof, derivation details, or exhaustive case analysis is referenced, with validation limited to correlation with training dynamics rather than direct equivalence checks.
Authors: We agree that the manuscript would be strengthened by including a formal proof or detailed derivation of the recursive algorithm. In the revised version, we will add this in an appendix, providing a step-by-step derivation based on the tensor contraction rules and symmetry groups. We will also include an exhaustive case analysis for linear and common non-linear layers to demonstrate no omissions in cross-layer mechanisms. Additionally, we will supplement the empirical results with direct equivalence tests on controlled examples. revision: yes
-
Referee: The assertion of higher fidelity than existing metrics on training dynamics (grokking, backdoor insertion) lacks any error analysis, validation setup, or quantitative comparison details, leaving the empirical support for the algebraic reduction unassessable.
Authors: We acknowledge the need for more rigorous empirical validation details. The revised manuscript will include a comprehensive description of the experimental setup, including model architectures, training procedures, the specific existing metrics used for comparison, and quantitative results with error analysis from multiple seeds. This will allow for a clear assessment of the higher fidelity claims. revision: yes
Circularity Check
Tensor similarity defined as independent algebraic metric with no circular reductions to inputs or self-citations
full rationale
The paper introduces tensor similarity as a weight-based metric invariant to symmetries, using an efficient recursive algorithm to capture global functional equivalence for tensor models. The abstract presents this directly as an algebraic construction that addresses limitations of empirical or basis-dependent measures, without any equations or steps that reduce by construction to fitted parameters, self-referential predictions, or load-bearing self-citations. No self-definitional loops, uniqueness theorems imported from prior author work, or renaming of known results appear in the derivation chain. The central claim remains an original proposal whose correctness is tested empirically on dynamics like grokking, keeping the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural network computations are fully represented by tensor weights up to basis symmetries.
- domain assumption A recursive algorithm can efficiently match cross-layer mechanisms without loss of equivalence information.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tensor similarity uses ... symmetrisation ... polarisation isomorphism ... Gaussian metric Λ=E_{x∼N(0,I)} ⊗^{2n}x ... sim_{P_n}(A,B)=1 ⇔ ∃λ>0 : A=λB
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gram-based recursion ... tree graph ... local tensors
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba
URL https://transformer-circuits.pub/ 2025/attribution-graphs/methods.html. David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6541–6549,
work page 2025
-
[2]
Network Dissection: Quantifying Interpretability of Deep Visual Representations
URL https://arxiv. org/abs/1704.05796. Nora Belrose, Quintin Pope, Lucia Quirke, Alex Mallen, and Xiaoli Fern. Neural networks learn statistics of increasing complexity,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
9 Nadav Cohen and Amnon Shashua
URLhttps://arxiv.org/abs/2402.04362. 9 Nadav Cohen and Amnon Shashua. Convolutional Rectifier Networks as Generalized Tensor Decom- positions,
-
[4]
Convolutional Rectifier Networks as Generalized Tensor Decompositions
URLhttps://arxiv.org/abs/1603.00162v2. Nadav Cohen, Or Sharir, and Amnon Shashua. On the Expressive Power of Deep Learning: A Tensor Analysis,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
On the Expressive Power of Deep Learning: A Tensor Analysis
URLhttps://arxiv.org/abs/1509.05009v3. Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga- Alonso. Towards automated circuit discovery for mechanistic interpretability. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
org/posts/baJyjpktzmcmRfosq/ stitching-saes-of-different-sizes
URLhttps://arxiv.org/abs/2304.14997. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models,
-
[7]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
URL https://arxiv.org/ abs/2309.08600. Alexander D’Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yian Ma, Cory McLean, Diana Mincu, Akinori Mitani, Andrea...
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
URLhttps://arxiv.org/abs/1612.08083. Li Deng. The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Magazine, 29(6):141–142,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2504.02667. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kapl...
-
[11]
https://transformer-circuits.pub/2021/framework/index.html. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling,
work page 2021
-
[12]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
URL https://arxiv.org/abs/ 2101.00027. Johnnie Gray. quimb: a python library for quantum information and many-body calculations.Journal of Open Source Software, 3(29):819,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov
doi: 10.21105/joss.00819. Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms,
-
[14]
URL https://arxiv.org/abs/2402.02364. Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viégas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V). InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine L...
-
[15]
URL https://arxiv.org/abs/1711.11279. 10 Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Similarity of Neural Network Representations Revisited
URLhttps://arxiv.org/abs/1905.00414. Nikolaus Kriegeskorte, Marieke Mur, and Peter Bandettini. Representational similarity analysis — connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[17]
URLhttps://doi.org/10.3389/neuro.06.004.2008
doi: 10.3389/neuro.06.004.2008. URLhttps://doi.org/10.3389/neuro.06.004.2008. Yoav Levine, Or Sharir, Nadav Cohen, and Amnon Shashua. Quantum Entanglement in Deep Learning Architectures.Phys. Rev. Lett., 122(6):065301,
-
[18]
doi: 10.1103/PhysRevLett.122. 065301. URLhttps://link.aps.org/doi/10.1103/PhysRevLett.122.065301. Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. In International Conference on Learning Representations, 2025a. URL http...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevlett.122
-
[19]
Maxime Méloux, Silviu Maniu, François Portet, and Maxime Peyrard
URLhttp://arxiv.org/abs/2503.01588. Maxime Méloux, Silviu Maniu, François Portet, and Maxime Peyrard. Everything, everywhere, all at once: Is mechanistic interpretability identifiable?,
-
[20]
Progress measures for grokking via mechanistic interpretability
URLhttps://arxiv.org/abs/2301.05217. Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learn- ing and Unsupervised Feature Learning 2011,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
URL https://arxiv. org/abs/2407.12034. Chris Olah. A toy model of mechanistic (un)faithfulness.Transformer Circuits Thread,
-
[22]
URL https://transformer-circuits.pub/2025/faithfulness-toy-model/index.html. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal ...
work page 2025
-
[23]
URL https://transformer-circuits.pub/2022/ in-context-learning-and-induction-heads/index.html. Michael T. Pearce, Thomas Dooms, Alice Rigg, José M. Oramas, and Lee Sharkey. Bilinear MLPs enable weight-based mechanistic interpretability. InInternational Conference on Learning Representations,
work page 2022
-
[24]
and Dooms, Thomas and Rigg, Alice and Oramas, Jose M
URLhttps://arxiv.org/abs/2410.08417. Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. InAdvances in Neural Information Processing Systems,
-
[25]
URLhttps://arxiv.org/abs/1706.05806. 11 Lyle Ramshaw. Blossoms are polar forms.Computer Aided Geometric Design, 6(4):323–358,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
doi: 10.1016/0167-8396(89)90032-0
ISSN 0167-8396. doi: 10.1016/0167-8396(89)90032-0. URL https://www.sciencedirect. com/science/article/pii/0167839689900320. Logan Riggs. Tensor-transformer variants are surprisingly performant. Less- Wrong,
-
[27]
URL http://arxiv. org/abs/2305.03452. Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, Stella Biderman, Adria Garriga-Alonso, Arthur Conmy, Neel Nanda, Jessica Rumbelow, Martin Wattenberg, Nandi Schoots, Joseph Miller, Eric J. Michaud, Stephen Ca...
-
[28]
URL https://arxiv.org/abs/2002. 05202. George Wang, Jesse Hoogland, Stan van Wingerden, Zach Furman, and Daniel Murfet. Differentiation and specialization of attention heads via the refined local learning coefficient,
work page 2002
-
[29]
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang
URL https: //arxiv.org/abs/2410.02984. Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling.arXiv preprint arXiv:2302.03169,
-
[30]
parameterised by L(i) A ,R (i) A ∈R ri×Hi−1, D(i) A ∈ RHi×ri (and likewise for B), the Gram step (10) reduces to matrix operations alone. Initialise G(0) =1 d+1 and, for eachi∈[L], compute four matrix products, (LL)(i) :=L (i) A G(i−1) L(i) B T ,(RR) (i) :=R (i) A G(i−1) R(i) B T , (LR)(i) :=L (i) A G(i−1) R(i) B T ,(RL) (i) :=R (i) A G(i−1) L(i) B T ,(12...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.