Bounded-Rationality, Hedging, and Generalization
Pith reviewed 2026-05-19 15:51 UTC · model grok-4.3
pith:QI6J2BFV Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{QI6J2BFV}
Prints a linked pith:QI6J2BFV badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Generalization is a testable hedging property of a learner's response law to training samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
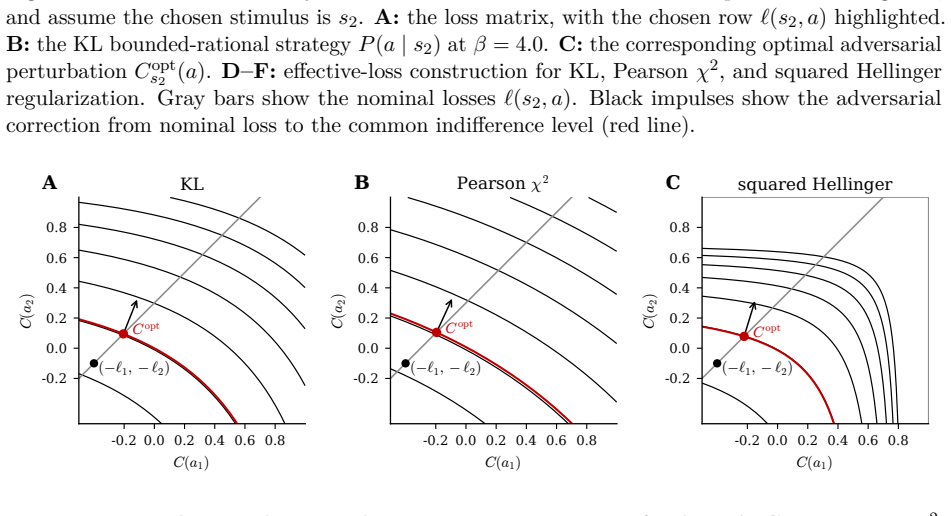
The learner's population loss equals its empirical loss plus the distortion caused by the particular training sample. The amount of distortion the learner can tolerate is given by a hedge that is recoverable from its black-box responses. When the response law is induced by an f-divergence regularizer, this hedge and the associated tradeoff curves live inside the regularizer's own information geometry, with the familiar KL case recovering the usual mutual-information bounds.
What carries the argument
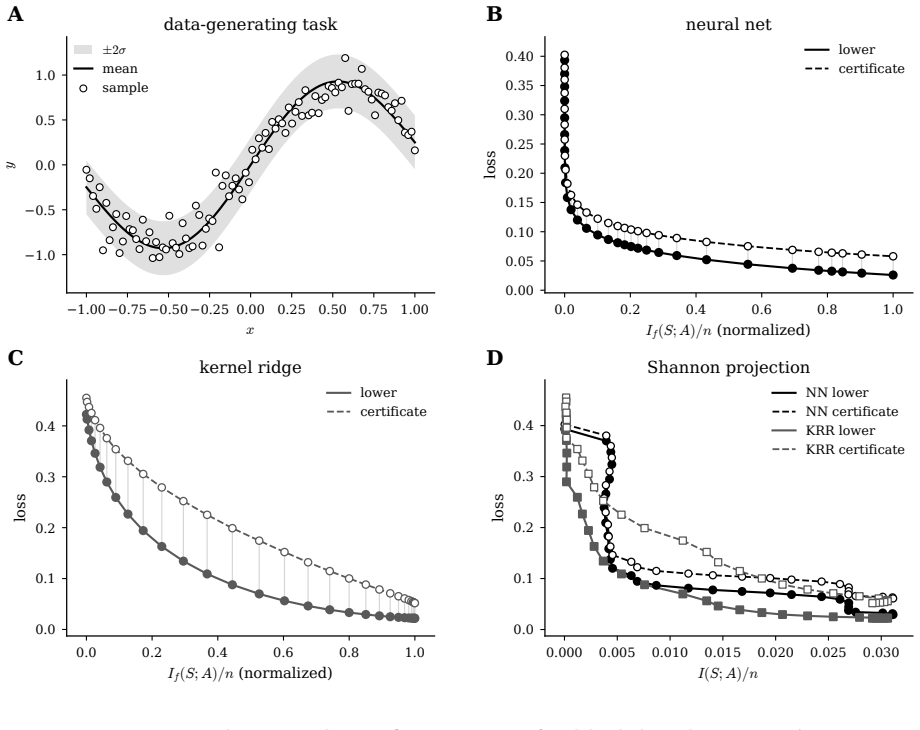
The induced channel from samples to outputs, when shaped by an f-divergence regularizer, which supplies both the lower loss-dependence tradeoff curve and the upper generalization certificate curve.
If this is right
- If the recovered hedge exceeds the distortion observed from the training sample, the learner generalizes.
- Different choices of f-divergence produce different geometries and therefore different certificates for the same observed behavior.
- The lower and upper curves can be extracted without access to the learner's internal parameters.
- KL regularization recovers the standard information-theoretic generalization bounds as a special case.
Where Pith is reading between the lines
- This framing suggests that generalization performance could be improved by explicitly designing the response law to have favorable hedging properties.
- It opens the possibility of transferring hedging certificates across different training regimes by matching the observed response curves.
- Practical verification would require efficient methods to query a deployed model with modified loss functions.
Load-bearing premise
The learner's mapping from training samples to outputs can be represented by an f-divergence regularizer whose geometry yields recoverable hedging curves.
What would settle it
Extract the hedge by querying the learner on scaled training losses and local perturbations; if on new data the actual population-minus-empirical loss exceeds this hedge, the claim is false.
Figures







read the original abstract
A learner does not only fit data; it also determines how strongly the training sample may shape its output and how much distortion it can hedge. We study this relation as a bounded-rational decision problem whose primitive object is the induced channel from samples to outputs. The learner's response law determines which changes in this channel are cheap or costly, and therefore induces both a lower tradeoff curve between training loss and sample dependence and a matched upper certificate curve. When the response law is represented by an $f$-divergence regularizer, these curves live in the regularizer's native information geometry, with KL as the special case corresponding to Shannon mutual information. We show how the hedge and the two curves can be recovered from black-box behavior by observing responses to scaled losses and local loss perturbations. In learning, population loss is empirical loss plus the distortion induced by the particular training sample. The recovered hedge gives a practical certificate when it covers that distortion. Thus generalization is treated as a testable hedging property of the learner's own response law.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames generalization in learning as a bounded-rationality hedging problem. The learner's response law, when represented by an f-divergence regularizer, induces a lower tradeoff curve between training loss and sample dependence, and a matched upper certificate curve in the regularizer's information geometry. These quantities, including the hedge, can be recovered from black-box observations of the learner's responses to scaled losses and local perturbations. The recovered hedge serves as a certificate for the distortion induced by the training sample in the population loss, treating generalization as a testable property of the response law. KL divergence corresponds to Shannon mutual information as a special case.
Significance. If the central claims hold, particularly the unique recoverability of the hedge and curves from black-box behavior and their ability to certify generalization, this work could offer a novel decision-theoretic perspective on generalization that unifies information geometry with learning theory. It provides a way to test hedging properties directly from observable learner behavior rather than relying on traditional complexity measures.
major comments (2)
- The recoverability of the hedge and curves from responses to scaled losses and local perturbations is central to the practical certificate claim, but the abstract provides no explicit inversion map or identifiability conditions. If different f-divergences produce observationally equivalent responses under the tested scalings and perturbations, the recovered regularizer and its geometry would be ambiguous, undermining the certificate for sample-induced distortion.
- The statement that 'the recovered hedge gives a practical certificate when it covers that distortion' requires a demonstration that the upper curve indeed upper-bounds the population loss minus empirical loss due to the sample; without this derivation or a concrete example, it is unclear whether the certificate is non-vacuous or independent of the choice of regularizer.
minor comments (2)
- The notation for the 'response law' and 'induced channel' could be clarified with a formal definition early in the paper to aid readability.
- Consider adding a reference to prior work on f-divergences in regularization or information geometry to contextualize the contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our work. We address each major comment in turn below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: The recoverability of the hedge and curves from responses to scaled losses and local perturbations is central to the practical certificate claim, but the abstract provides no explicit inversion map or identifiability conditions. If different f-divergences produce observationally equivalent responses under the tested scalings and perturbations, the recovered regularizer and its geometry would be ambiguous, undermining the certificate for sample-induced distortion.
Authors: The full manuscript derives the inversion map explicitly in Section 3.2 via the convex dual of the f-divergence and the observed response function; identifiability follows from strict convexity of f together with the assumption that local perturbations span a neighborhood of the tangent space (Proposition 2). Different f-divergences are distinguishable under these scalings precisely because their induced response laws differ in the second-order curvature terms. We agree the abstract is insufficiently precise on this point and will revise it to state the inversion procedure and the strict-convexity identifiability condition. revision: yes
-
Referee: The statement that 'the recovered hedge gives a practical certificate when it covers that distortion' requires a demonstration that the upper curve indeed upper-bounds the population loss minus empirical loss due to the sample; without this derivation or a concrete example, it is unclear whether the certificate is non-vacuous or independent of the choice of regularizer.
Authors: Theorem 4 establishes the upper-bound property directly from the variational representation of the f-divergence: the certificate curve is the minimal value of the regularized population loss consistent with the observed hedge, which by construction dominates the sample-induced distortion term. The bound is tight for the recovered regularizer and therefore non-vacuous by definition; independence from an arbitrary choice follows because the regularizer itself is recovered from data. We will add a short numerical example (KL and exponential cases) in the revised version to illustrate the numerical gap between the certificate and the realized distortion. revision: partial
Circularity Check
No significant circularity; derivation presented as independent recovery method
full rationale
The abstract frames generalization as a hedging property induced by the learner's response law under an f-divergence regularizer, with curves recovered from black-box observations of scaled losses and perturbations. No equation or step is shown that defines the hedge or curves directly in terms of the recovered quantities themselves, nor does any load-bearing claim reduce to a self-citation or fitted input renamed as prediction. The recovery procedure is asserted as a contribution rather than presupposed by construction, leaving the central claims with independent content relative to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The learner's response law determines which changes in the induced channel from samples to outputs are cheap or costly.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
When the response law is represented by an f-divergence regularizer, these curves live in the regularizer’s native information geometry, with KL as the special case corresponding to Shannon mutual information. ... the hedge and the two curves can be recovered from black-box behavior by observing responses to scaled losses and local loss perturbations.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the certificate value Ladv_f := sup ... = L + (1/β)If(S;A)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David A. McAllester. Some PAC-Bayesian Theorems.Machine Learning, 37(3):355–363, 1999
work page 1999
-
[2]
Institute of Mathematical Statistics, 2007
Olivier Catoni.PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning. Institute of Mathematical Statistics, 2007
work page 2007
-
[3]
Information-Theoretic Analysis of Generalization Capability of Learning Algorithms
Aolin Xu and Maxim Raginsky. Information-Theoretic Analysis of Generalization Capability of Learning Algorithms. InAdvances in Neural Information Processing Systems 30, pages 2524–2533, 2017
work page 2017
-
[4]
Reasoning About Generalization via Conditional Mutual Information
Thomas Steinke and Lydia Zakynthinou. Reasoning About Generalization via Conditional Mutual Information. InProceedings of the Thirty Third Conference on Learning Theory, pages 3437–3452, 2020
work page 2020
-
[5]
Fredrik Hellström, Giuseppe Durisi, Benjamin Guedj, and Maxim Raginsky. General- ization Bounds: Perspectives from Information Theory and PAC-Bayes.arXiv preprint arXiv:2309.04381, 2024
-
[6]
Pedro A. Ortega and Daniel A. Braun. Thermodynamics as a Theory of Decision-Making with Information-Processing Costs.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 469(2153):20120683, 2013
work page 2013
-
[7]
Information-Theoretic Bounded Rationality
Pedro A. Ortega, Daniel A. Braun, Justin S. Dyer, Kee-Eung Kim, and Naftali Tishby. Information-Theoretic Bounded Rationality.arXiv preprint arXiv:1512.06789, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Markov Processes and the H-Theorem.Journal of the Physical Society of Japan, 18(3):328–331, 1963
Tadao Morimoto. Markov Processes and the H-Theorem.Journal of the Physical Society of Japan, 18(3):328–331, 1963
work page 1963
-
[9]
Syed M. Ali and Samuel D. Silvey. A General Class of Coefficients of Divergence of One Distribution from Another.Journal of the Royal Statistical Society: Series B, 28(1):131–142, 1966
work page 1966
-
[10]
Imre Csiszár. Information-Type Measures of Difference of Probability Distributions and Indirect Observations.Studia Scientiarum Mathematicarum Hungarica, 2:299–318, 1967. 21
work page 1967
-
[11]
Igor Vajda. On the f-Divergence and Singular Statistical Experiments.Studia Scientiarum Mathematicarum Hungarica, 3:167–174, 1968
work page 1968
-
[12]
Claude E. Shannon. Coding Theorems for a Discrete Source with a Fidelity Criterion.IRE National Convention Record, 7(4):142–163, 1959
work page 1959
-
[13]
Toby Berger.Rate Distortion Theory: A Mathematical Basis for Data Compression. Prentice- Hall, 1971
work page 1971
-
[14]
Aharon Ben-Tal and Marc Teboulle. Rate Distortion Theory with Generalized Information Measures via Convex Programming Duality.IEEE Transactions on Information Theory, 32(5): 630–641, 1986
work page 1986
-
[15]
Pedro A. Ortega and Daniel D. Lee. An Adversarial Interpretation of Information-Theoretic Bounded Rationality. InProceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, pages 2117–2124, 2014
work page 2014
-
[16]
Pedro A. Ortega and Alan A. Stocker. Human Decision-Making under Limited Time. In Advances in Neural Information Processing Systems 29, pages 2145–2153, 2016
work page 2016
-
[17]
Andrew Caplin and Mark Dean. Revealed Preference, Rational Inattention, and Costly Information Acquisition.American Economic Review, 105(7):2183–2203, 2015
work page 2015
-
[18]
Daniel A. Braun and Pedro A. Ortega. Information-Theoretic Bounded Rationality and epsilon-Optimality.Entropy, 16(8):4662–4676, 2014
work page 2014
-
[19]
Tyrrell Rockafellar.Convex Analysis
R. Tyrrell Rockafellar.Convex Analysis. Princeton University Press, 1970
work page 1970
-
[20]
Aharon Ben-Tal and Marc Teboulle. Penalty Functions and Duality in Stochastic Programming viaϕ-Divergence Functionals.Mathematics of Operations Research, 12(2):224–240, 1987
work page 1987
-
[21]
Friedrich Liese and Igor Vajda. On Divergences and Informations in Statistics and Information Theory.IEEE Transactions on Information Theory, 52(10):4394–4412, 2006
work page 2006
-
[22]
Imre Csiszár. A Class of Measures of Informativity of Observation Channels.Periodica Mathematica Hungarica, 2(1–4):191–213, 1972
work page 1972
-
[23]
Jacob Ziv and Moshe Zakai. On Functionals Satisfying a Data-Processing Theorem.IEEE Transactions on Information Theory, 19(3):275–283, 1973
work page 1973
-
[24]
Imre Csiszár. Generalized Cutoff Rates and Rényi’s Information Measures.IEEE Transactions on Information Theory, 41(1):26–34, 1995
work page 1995
-
[25]
On Csiszár’s f-Divergences and Informativities.Entropy, 20(2): 105, 2018
Igal Sason and Sergio Verdú. On Csiszár’s f-Divergences and Informativities.Entropy, 20(2): 105, 2018
work page 2018
-
[26]
On Conjugate Convex Functions.Canadian Journal of Mathematics, 1:73–77, 1949
Werner Fenchel. On Conjugate Convex Functions.Canadian Journal of Mathematics, 1:73–77, 1949
work page 1949
-
[27]
On General Minimax Theorems.Pacific Journal of Mathematics, 8(1):171–176, 1958
Maurice Sion. On General Minimax Theorems.Pacific Journal of Mathematics, 8(1):171–176, 1958
work page 1958
-
[28]
Rob Brekelmans, Tim Genewein, Jordi Grau-Moya, Grégoire Delétang, Markus Kunesch, Shane Legg, and Pedro A. Ortega. Your Policy Regularizer Is Secretly an Adversary.Transactions on Machine Learning Research, 2022. 22
work page 2022
-
[29]
A Generalization of the Rate-Distortion Theory and Applications
Moshe Zakai and Jacob Ziv. A Generalization of the Rate-Distortion Theory and Applications. InInformation Theory: New Trends and Open Problems, pages 87–123. Springer, 1975
work page 1975
-
[30]
Richard E. Blahut. Computation of Channel Capacity and Rate-Distortion Functions.IEEE Transactions on Information Theory, 18(4):460–473, 1972
work page 1972
-
[31]
Suguru Arimoto. An Algorithm for Computing the Capacity of Arbitrary Discrete Memoryless Channels.IEEE Transactions on Information Theory, 18(1):14–20, 1972
work page 1972
-
[32]
Training Region-Based Object Detectors with Online Hard Example Mining
Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training Region-Based Object Detectors with Online Hard Example Mining. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 761–769, 2016
work page 2016
-
[33]
Understanding Black-Box Predictions via Influence Functions
Pang Wei Koh and Percy Liang. Understanding Black-Box Predictions via Influence Functions. InProceedings of the 34th International Conference on Machine Learning, pages 1885–1894, 2017
work page 2017
-
[34]
Peyman Mohajerin Esfahani and Daniel Kuhn. Data-Driven Distributionally Robust Optimiza- tion Using the Wasserstein Metric: Performance Guarantees and Tractable Reformulations. Mathematical Programming, 171(1–2):115–166, 2018
work page 2018
-
[35]
John C. Duchi and Hongseok Namkoong. Learning Models with Uniform Performance via Distributionally Robust Optimization.The Annals of Statistics, 49(3):1378–1406, 2021
work page 2021
-
[36]
Pedro A. Ortega and Daniel A. Braun. Information, Utility and Bounded Rationality. In Artificial General Intelligence, pages 269–274, 2011
work page 2011
-
[37]
Christopher A. Sims. Implications of Rational Inattention.Journal of Monetary Economics, 50 (3):665–690, 2003
work page 2003
-
[38]
Filip Matějka and Alisdair McKay. Rational Inattention to Discrete Choices: A New Foundation for the Multinomial Logit Model.American Economic Review, 105(1):272–298, 2015
work page 2015
-
[39]
Saeed Masiha, Amin Gohari, and Mohammad Hossein Yassaee. f-Divergences and Their Applications in Lossy Compression and Bounding Generalization Error.IEEE Transactions on Information Theory, 69(12):7538–7564, 2023
work page 2023
-
[40]
Ronald A. Howard and James E. Matheson. Risk-Sensitive Markov Decision Processes.Man- agement Science, 18(7):356–369, 1972
work page 1972
- [41]
- [42]
-
[43]
Lars Peter Hansen and Thomas J. Sargent. Robust Control and Model Uncertainty.American Economic Review, 91(2):60–66, 2001
work page 2001
-
[44]
Lars Peter Hansen and Thomas J. Sargent.Robustness. Princeton University Press, 2008
work page 2008
-
[45]
A Theory of Regularized Markov Decision Processes
Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A Theory of Regularized Markov Decision Processes. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2160–2169, 2019. 23
work page 2019
-
[46]
Regularized Policies Are Reward Robust
Hisham Husain, Kamil Ciosek, and Ryota Tomioka. Regularized Policies Are Reward Robust. InProceedings of the Twenty-Fourth International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 64–72, 2021
work page 2021
-
[47]
Twice Regularized MDPs and the Equiva- lence between Robustness and Regularization
Esther Derman, Matthieu Geist, and Shie Mannor. Twice Regularized MDPs and the Equiva- lence between Robustness and Regularization. InAdvances in Neural Information Processing Systems 34, pages 22274–22287, 2021
work page 2021
-
[48]
Maximum Entropy RL (Provably) Solves Some Robust RL Problems
Benjamin Eysenbach and Sergey Levine. Maximum Entropy RL (Provably) Solves Some Robust RL Problems. InInternational Conference on Learning Representations, 2022
work page 2022
-
[49]
Erick Delage and Yinyu Ye. Distributionally Robust Optimization Under Moment Uncertainty with Application to Data-Driven Problems.Operations Research, 58(3):595–612, 2010
work page 2010
-
[50]
Joel Goh and Melvyn Sim. Distributionally Robust Optimization and Its Tractable Approxi- mations.Operations Research, 58(4-part-1):902–917, 2010
work page 2010
-
[51]
Aharon Ben-Tal, Dick den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust Solutions of Optimization Problems Affected by Uncertain Probabilities.Management Science, 59(2):341–357, 2013
work page 2013
- [52]
-
[53]
Distributionally Robust Convex Opti- mization.Operations Research, 62(6):1358–1376, 2014
Wolfram Wiesemann, Daniel Kuhn, and Melvyn Sim. Distributionally Robust Convex Opti- mization.Operations Research, 62(6):1358–1376, 2014
work page 2014
-
[54]
Hamed Rahimian and Sanjay Mehrotra. Frameworks and Results in Distributionally Robust Optimization.Open Journal of Mathematical Optimization, 3:1–85, 2022
work page 2022
-
[55]
Güzin Bayraksan and David K. Love. Data-Driven Stochastic Programming Using Phi- Divergences. InINFORMS TutORials in Operations Research, pages 1–19. 2015
work page 2015
-
[56]
David K. Love and Güzin Bayraksan. Phi-Divergence Constrained Ambiguous Stochastic Programs for Data-Driven Optimization.arXiv preprint arXiv:1603.00900, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[57]
Henry Lam. Robust Sensitivity Analysis for Stochastic Systems.Mathematics of Operations Research, 41(4):1248–1275, 2016
work page 2016
-
[58]
PAC-Bayesian Generalisation Error Bounds for Gaussian Process Classification
Matthias Seeger. PAC-Bayesian Generalisation Error Bounds for Gaussian Process Classification. Journal of Machine Learning Research, 3:233–269, 2002
work page 2002
-
[59]
Gintare Karolina Dziugaite and Daniel M. Roy. Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data. In Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence, 2017
work page 2017
-
[60]
Gintare Karolina Dziugaite and Daniel M. Roy. Data-Dependent PAC-Bayes Priors via Differential Privacy.arXiv preprint arXiv:1802.09583, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Information- Theoretic Analysis of Stability and Bias of Learning Algorithms
Maxim Raginsky, Alexander Rakhlin, Matthew Tsao, Yihong Wu, and Aolin Xu. Information- Theoretic Analysis of Stability and Bias of Learning Algorithms. In2016 IEEE Information Theory Workshop (ITW), pages 26–30, 2016. 24
work page 2016
-
[62]
Yuheng Bu, Shaofeng Zou, and Venugopal V. Veeravalli. Tightening Mutual Information-Based Bounds on Generalization Error.IEEE Journal on Selected Areas in Information Theory, 1(1): 121–130, 2020
work page 2020
-
[63]
Roy, and Gintare Karolina Dziugaite
Mahdi Haghifam, Jeffrey Negrea, Ashish Khisti, Daniel M. Roy, and Gintare Karolina Dziugaite. Sharpened Generalization Bounds Based on Conditional Mutual Information and an Application to Noisy, Iterative Algorithms. InAdvances in Neural Information Processing Systems 33, pages 14177–14188, 2020
work page 2020
-
[64]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization Beyond Overfitting on Small Algorithmic Datasets.arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[65]
Ziming Liu, Eric J. Michaud, and Max Tegmark. Omnigrok: Grokking Beyond Algorithmic Data. InInternational Conference on Learning Representations, 2023
work page 2023
-
[66]
Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling Modern Machine- Learning Practice and the Classical Bias–Variance Trade-Off.Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019
work page 2019
-
[67]
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep Double Descent: Where Bigger Models and More Data Hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003, 2021
work page 2021
-
[68]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic Gradient Descent with Warm Restarts. InInternational Conference on Learning Representations, 2017
work page 2017
-
[69]
Cohen, Simran Kaur, Yuanzhi Li, J
Jeremy M. Cohen, Simran Kaur, Yuanzhi Li, J. Zico Kolter, and Ameet Talwalkar. Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability. InInternational Conference on Learning Representations, 2021. A Mathematical Derivations A.1 Derivation of the Optimal Adversarial Perturbation We seek the perturbationCs(a)that the adversary applies...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.