Continual Learning of Domain-Invariant Representations
Pith reviewed 2026-05-20 21:12 UTC · model grok-4.3
The pith
Continual learning methods that combine replay with sequential invariance alignment learn and preserve domain-invariant representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
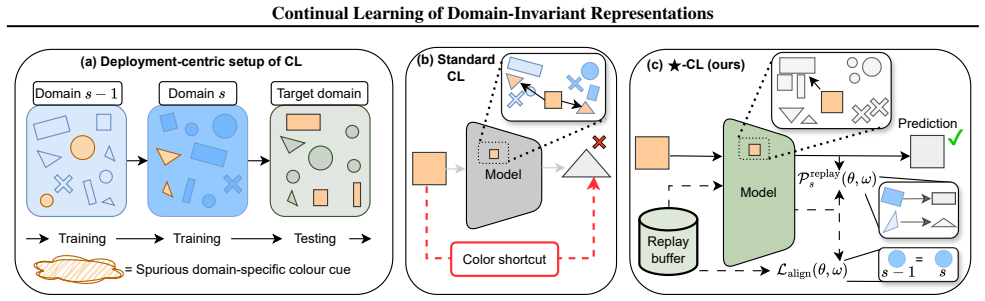
A broad class of continual learning methods can sequentially learn representations that capture invariant structures across domains by combining replay-based training with tailored sequential invariance alignment; these invariants are motivated by the idea that they preserve underlying causal mechanisms and thereby reduce overfitting to domain-specific shortcuts, yielding improved generalization to unseen target domains after deployment.
What carries the argument
Replay-based training paired with a tailored sequential invariance alignment that learns and preserves invariant structures over successive domains.
If this is right
- The methods outperform existing continual learning baselines on generalization to unseen target domains.
- Naive sequential extensions of existing domain-invariant representation learning techniques yield only limited benefits.
- The approach applies across vision, medicine, manufacturing, and ecology tasks.
- It mitigates shortcut learning by focusing on structures that are stable across domains.
Where Pith is reading between the lines
- The same replay-plus-alignment pattern could be tested in settings where domain order is not fixed in advance.
- It suggests that explicitly protecting causal mechanisms during continual updates may improve robustness when environments change gradually.
- The deployment-oriented evaluation protocol could be applied to other continual learning problems that currently measure only in-domain accuracy.
Load-bearing premise
Invariant structures across domains often preserve the underlying causal mechanisms and thereby reduce overfitting to domain-specific cues.
What would settle it
A controlled experiment on a dataset in which domain shifts do not preserve causal mechanisms and the proposed methods fail to outperform standard replay baselines on unseen target domains.
Figures









read the original abstract
Continual learning (CL) aims to train models sequentially over multiple domains without forgetting previously learned knowledge. However, existing CL methods optimize for in-domain performance and are therefore prone to learning spurious, domain-specific cues (``shortcut learning''), which limits generalization to unseen domains after deployment. In this paper, we address this limitation through continual learning of domain-invariant representation. We introduce a broad class of CL methods that sequentially learn representations capturing invariant structures across domains. Our methods are motivated by the observation that such invariant structures often preserve the underlying causal mechanisms, which can reduce the risk of overfitting to domain-specific cues and thus offer better out-of-domain generalization. Our proposed CL methods combine replay-based training with a tailored sequential invariance alignment to learn -- and preserve -- invariant structures over time. We evaluate our methods under a deployment-oriented protocol that measures performance on unseen target domains. Across six benchmark and real-world datasets spanning vision, medicine, manufacturing, and ecology, our methods consistently outperform existing CL baselines in terms of generalization to unseen target domains. As an ablation, we further show that na\"ive extensions of sequential training with existing domain-invariant representation learning (DIRL) methods provide only limited benefits. To the best of our knowledge, this is the first work to develop domain-invariant representation methods for CL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a class of continual learning (CL) methods that combine replay-based training with sequential invariance alignment to learn and preserve domain-invariant representations over time. Motivated by the idea that such invariants often capture causal mechanisms and reduce shortcut learning, the methods are evaluated under a deployment-oriented protocol measuring generalization to unseen target domains. Across six benchmark and real-world datasets in vision, medicine, manufacturing, and ecology, the proposed methods are reported to consistently outperform existing CL baselines; an ablation shows that naive sequential extensions of prior domain-invariant representation learning (DIRL) methods yield only limited gains. This is positioned as the first work developing DIRL methods specifically for CL.
Significance. If the empirical claims hold under fuller scrutiny, the work is significant for bridging continual learning with domain-invariant representation techniques, shifting focus from in-domain retention to out-of-domain robustness in sequential settings. The deployment-oriented evaluation protocol is a positive step toward practical relevance in applications with evolving domains.
major comments (2)
- [Motivation / Abstract] The central motivation (abstract and likely §1) states that invariant structures 'often preserve the underlying causal mechanisms' to explain reduced overfitting and better OOD generalization, yet the experiments report only aggregate performance gains on target domains without any verification step, such as measuring representation alignment against known causal factors or comparing against non-causal invariant baselines. This assumption is load-bearing for interpreting why the sequential alignment helps beyond standard regularization.
- [Experiments] §5 (Experiments): The claim of consistent outperformance across six datasets under the deployment-oriented protocol is presented without reported statistical tests, number of random seeds, full baseline specifications, or confirmation that hyperparameter choices were not post-hoc. Given the reader's note on missing experimental details, this undermines verification of the generalization advantage.
minor comments (2)
- [Abstract] The ablation description in the abstract refers to 'naive extensions of sequential training with existing DIRL methods' but does not name the specific DIRL methods or detail how the naive extension was implemented.
- [Method] Notation for 'invariant structures' versus 'domain-invariant representations' should be unified or explicitly distinguished in the method section to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below and indicate the revisions we will incorporate to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Motivation / Abstract] The central motivation (abstract and likely §1) states that invariant structures 'often preserve the underlying causal mechanisms' to explain reduced overfitting and better OOD generalization, yet the experiments report only aggregate performance gains on target domains without any verification step, such as measuring representation alignment against known causal factors or comparing against non-causal invariant baselines. This assumption is load-bearing for interpreting why the sequential alignment helps beyond standard regularization.
Authors: We appreciate the referee highlighting the role of this motivational hypothesis. The phrasing draws from established literature on domain-invariant representations and causal mechanisms but is presented as an intuition rather than an empirically verified claim within this work. Our experiments focus on measuring generalization performance under the deployment-oriented protocol rather than direct causal analysis. We will revise the abstract and introduction to explicitly frame the causal connection as a motivating hypothesis from prior work, clarify the scope of our contributions, and add a short discussion of limitations and future directions for causal verification. We do not plan to add new experiments comparing against non-causal baselines, as that would substantially expand the scope beyond the current focus on continual learning methods. revision: partial
-
Referee: [Experiments] §5 (Experiments): The claim of consistent outperformance across six datasets under the deployment-oriented protocol is presented without reported statistical tests, number of random seeds, full baseline specifications, or confirmation that hyperparameter choices were not post-hoc. Given the reader's note on missing experimental details, this undermines verification of the generalization advantage.
Authors: We agree that additional details are required to support the empirical claims and enable full verification. In the revised manuscript we will: report results over 5 random seeds with mean and standard deviation; include statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) comparing our methods to baselines; provide complete hyperparameter specifications and training details for all baselines; and explicitly describe the hyperparameter selection protocol, confirming that tuning was performed on validation splits without reference to target-domain test performance. These changes will be incorporated into §5 and the supplementary material. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces a new combination of replay-based continual learning with sequential invariance alignment, motivated by the observation that invariant structures often preserve causal mechanisms. This motivation is presented as an empirical assumption rather than a derived result from equations. Performance claims are supported by evaluation on six external benchmark and real-world datasets, with ablations against naive extensions of existing DIRL methods. No load-bearing steps reduce by construction to fitted parameters, self-citations, or imported uniqueness theorems; the central method and generalization results remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Invariant structures often preserve the underlying causal mechanisms
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our proposed CL methods combine replay-based training with a tailored sequential invariance alignment to learn -- and preserve -- invariant structures over time.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We consider multiple notions of domain invariance, namely, (i) risk-based, (ii) gradient-based, and (iii) feature-based—domain invariances.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Invariant risk minimization , author=. arXiv preprint arXiv:1907.02893 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Domain generalization via invariant feature representation , author=. 2013 , organization=
work page 2013
-
[3]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
work page 1989
-
[4]
arXiv preprint arXiv:2009.00329 , year=
Learning explanations that are hard to vary , author=. arXiv preprint arXiv:2009.00329 , year=
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
work page 2024
-
[6]
Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
-
[7]
Advances in Neural Information Processing Systems , volume=
Dark experience for general continual learning: a strong, simple baseline , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Loss decoupling for task-agnostic continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
IEEE Sensors Journal , volume=
Contrastive generative replay method of remaining useful life prediction for rolling bearings , author=. IEEE Sensors Journal , volume=. 2023 , publisher=
work page 2023
-
[10]
European Conference on Computer Vision , pages=
An incremental unified framework for small defect inspection , author=. European Conference on Computer Vision , pages=
-
[11]
Nature Communications , volume=
A clinical deep learning framework for continually learning from cardiac signals across diseases, time, modalities, and institutions , author=. Nature Communications , volume=. 2021 , publisher=
work page 2021
-
[12]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Multi-label continual learning for the medical domain: A novel benchmark , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
work page 2025
-
[13]
Federated continual learning with weighted inter-client transfer , author=. 2021 , organization=
work page 2021
-
[14]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. arXiv preprint arXiv:1911.08731 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[15]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2104.05025 , year=
New insights on reducing abrupt representation change in online continual learning , author=. arXiv preprint arXiv:2104.05025 , year=
-
[17]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Semantic Aware Representation Learning for Lifelong Learning , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sparse coding in a dual memory system for lifelong learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Continual prototype evolution: Learning online from non-stationary data streams , author=
-
[20]
Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
icarl: Incremental classifier and representation learning , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Bring evanescent representations to life in lifelong class incremental learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
European Conference on Computer Vision , pages=
Memory-efficient incremental learning through feature adaptation , author=. European Conference on Computer Vision , pages=
-
[23]
AAAI Bridge Program on Continual Causality , pages=
Towards causal replay for knowledge rehearsal in continual learning , author=. AAAI Bridge Program on Continual Causality , pages=. 2023 , organization=
work page 2023
-
[24]
On Tiny Episodic Memories in Continual Learning
On tiny episodic memories in continual learning , author=. arXiv preprint arXiv:1902.10486 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[25]
arXiv preprint arXiv:2402.03917 , year=
Elastic feature consolidation for cold start exemplar-free incremental learning , author=. arXiv preprint arXiv:2402.03917 , year=
-
[26]
Lifelong Learning with Dynamically Expandable Networks
Lifelong learning with dynamically expandable networks , author=. arXiv preprint arXiv:1708.01547 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in Neural Information Processing Systems , volume=
Learning from failure: De-biasing classifier from biased classifier , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Do image classifiers generalize across time? , author=
-
[29]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
work page 2020
-
[30]
arXiv preprint arXiv:2310.16228 , year=
On the foundations of shortcut learning , author=. arXiv preprint arXiv:2310.16228 , year=
-
[31]
Mechanical Systems and Signal Processing , volume=
Domain-invariant feature exploration for intelligent fault diagnosis under unseen and time-varying working conditions , author=. Mechanical Systems and Signal Processing , volume=. 2025 , publisher=
work page 2025
-
[32]
Reliability Engineering & System Safety , volume=
Remaining useful lifetime prediction via deep domain adaptation , author=. Reliability Engineering & System Safety , volume=. 2020 , publisher=
work page 2020
-
[33]
Conference on Robot Learning , pages=
DIRL: Domain-invariant representation learning for sim-to-real transfer , author=. Conference on Robot Learning , pages=. 2021 , organization=
work page 2021
-
[34]
Cynthia Dwork and Vitaly Feldman and Moritz Hardt and Toniann Pitassi and Omer Reingold and Aaron Roth , title =. Science , volume =. 2015 , doi =. https://www.science.org/doi/pdf/10.1126/science.aaa9375 , abstract =
- [35]
-
[36]
Advances in Neural Information Processing Systems , volume=
Gradient episodic memory for continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Train faster, generalize better: Stability of stochastic gradient descent , author=. 2016 , organization=
work page 2016
-
[38]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Addressing Loss of Plasticity and Catastrophic Forgetting in Continual Learning , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Online continual learning with maximal interfered retrieval , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Umap: Uniform manifold approximation and projection for dimension reduction , author=. arXiv preprint arXiv:1802.03426 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Gradient based sample selection for online continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Wu, Ming-Ju and Jang, Jyh-Shing R. and Chen, Jui-Long , journal=. Wafer Map Failure Pattern Recognition and Similarity Ranking for Large-Scale Data Sets , year=
- [43]
-
[44]
A nearest neighbor-based concept drift detection strategy for reliable tool condition monitoring , author=. Proceedings of the 3rd International Workshop on Software Engineering and AI for Data Quality in Cyber-Physical Systems/Internet of Things , pages=
-
[45]
arXiv preprint arXiv:1902.09432 , year=
Scalable and order-robust continual learning with additive parameter decomposition , author=. arXiv preprint arXiv:1902.09432 , year=
-
[46]
International Conference on Learning Representations (ICLR) , year =
Measuring and Regularizing Networks in Function Space , author =. International Conference on Learning Representations (ICLR) , year =
-
[47]
arXiv preprint arXiv:2309.02195 , year=
Sparse function-space representation of neural networks , author=. arXiv preprint arXiv:2309.02195 , year=
- [48]
-
[49]
Continual learning through synaptic intelligence , author=. 2017 , organization=
work page 2017
-
[50]
Wilds: A benchmark of in-the-wild distribution shifts , author=. 2021 , organization=
work page 2021
-
[51]
Bandi, Peter and Geessink, Oscar and Manson, Quirine and Van Dijk, Marcory and Balkenhol, Maschenka and Hermsen, Meyke and Bejnordi, Babak Ehteshami and Lee, Byungjae and Paeng, Kyunghyun and Zhong, Aoxiao and others , journal=. From detection of individual metastases to classification of lymph node status at the patient level: the. 2019 , publisher=
work page 2019
-
[52]
Clinical applications of continual learning machine learning , author=. 2020 , publisher=
work page 2020
-
[53]
Nature Machine Intelligence , volume=
Three types of incremental learning , author=. Nature Machine Intelligence , volume=. 2022 , publisher=
work page 2022
-
[54]
Forget-free continual learning with winning subnetworks , author=. 2022 , organization=
work page 2022
-
[55]
Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
Packnet: Adding multiple tasks to a single network by iterative pruning , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Not just selection, but exploration: Online class-incremental continual learning via dual view consistency , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
Class-incremental continual learning into the extended der-verse , author=. 2022 , publisher=
work page 2022
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Domain decorrelation with potential energy ranking , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Domaindrop: Suppressing domain-sensitive channels for domain generalization , author=
-
[60]
Jock A. Blackard and Denis J. Dean , booktitle =. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables , year =
-
[61]
International Conference on Learning Representations (ICLR) , year=
In Search of Lost Domain Generalization , author=. International Conference on Learning Representations (ICLR) , year=
-
[62]
Transactions on Machine Learning Research , year=
Uniformly distributed feature representations for fair and robust learning , author=. Transactions on Machine Learning Research , year=
-
[63]
Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
Domain generalization with adversarial feature learning , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern recognition , pages=
-
[64]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Self-Normalized Resets for Plasticity in Continual Learning , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[65]
Conference on robot learning , pages=
Core50: a new dataset and benchmark for continuous object recognition , author=. Conference on robot learning , pages=. 2017 , organization=
work page 2017
-
[66]
Revisiting Batch Normalization For Practical Domain Adaptation
Revisiting batch normalization for practical domain adaptation , author=. arXiv preprint arXiv:1603.04779 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Test-time training with self-supervision for generalization under distribution shifts , author=. 2020 , organization=
work page 2020
-
[68]
International Conference on Learning Representations (ICLR) , year=
Tent: Fully Test-Time Adaptation by Entropy Minimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[69]
AR-TTA: A Simple Method for Real-World Continual Test-Time Adaptation , booktitle =
S\'ojka, Damian and Cygert, Sebastian and Twardowski, Bart. AR-TTA: A Simple Method for Real-World Continual Test-Time Adaptation , booktitle =. 2023 , pages =
work page 2023
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Continual test-time domain adaptation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
Proceedings of the 30th ACM international conference on Multimedia , pages=
Delving into the continuous domain adaptation , author=. Proceedings of the 30th ACM international conference on Multimedia , pages=
-
[72]
arXiv preprint arXiv:2007.01807 , year=
Continuously indexed domain adaptation , author=. arXiv preprint arXiv:2007.01807 , year=
- [73]
-
[74]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Domain generalization for object recognition with multi-task autoencoders , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[75]
Alex Krizhevsky , title =
-
[76]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[77]
European Conference on Computer Vision , pages=
Learning to balance specificity and invariance for in and out of domain generalization , author=. European Conference on Computer Vision , pages=. 2020 , organization=
work page 2020
-
[78]
The many faces of robustness: A critical analysis of out-of-distribution generalization. 2021 IEEE , author=. CVF International Conference on Computer Vision (ICCV) , volume=
work page 2021
-
[79]
Eskandar, Masih and Imtiaz, Tooba and Hill, Davin and Wang, Zifeng and Dy, Jennifer , booktitle =
-
[80]
Advances in Neural Information Processing Systems , volume=
A unified approach to domain incremental learning with memory: Theory and algorithm , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.