VQ-Atom: Semantic Discretization of Local Atomic Environments for Molecular Representation Learning
Pith reviewed 2026-05-19 20:55 UTC · model grok-4.3
The pith
Vector quantization on atom embeddings yields discrete tokens for chemical contexts that boost protein-ligand prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VQ-Atom performs semantic discretization by feeding graph neural network embeddings of atoms into a vector quantization layer that assigns each atom to one of a learned set of codebook vectors; each codebook entry represents a chemically meaningful atomic context. The resulting sequence of discrete tokens defines a language representation of the molecule suitable for Transformer pretraining. When this representation is used for protein-ligand interaction prediction without 3D coordinates and under a protein-cold split, it produces higher predictive accuracy than models built on standard syntactic tokenizations.
What carries the argument
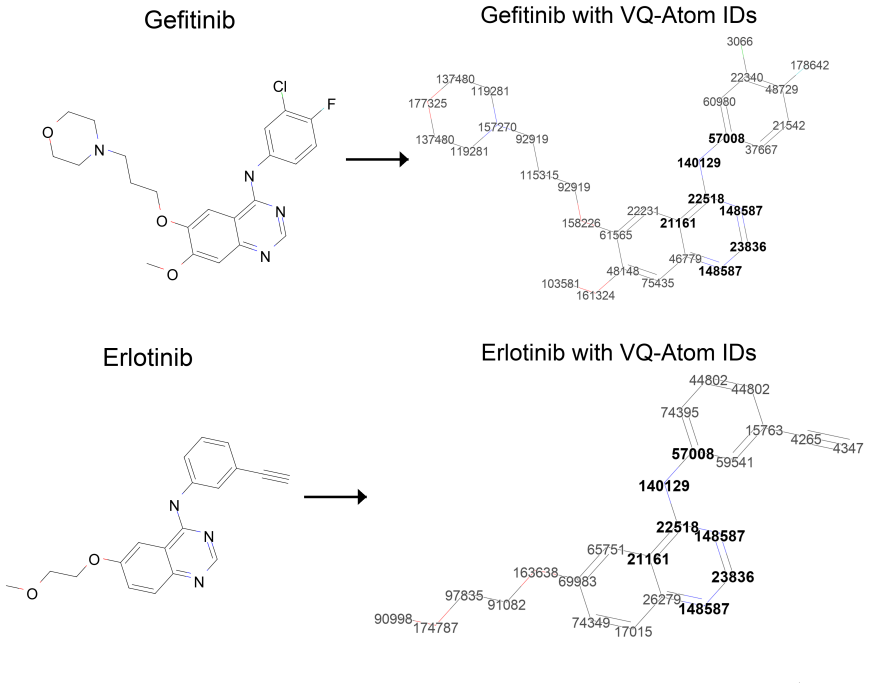
Vector quantization applied to graph neural network atom embeddings, which maps continuous vectors to discrete codebook entries that stand for distinct local chemical environments.
If this is right
- Semantically grounded discretization improves predictive performance on protein-ligand interaction tasks compared with syntactic tokenization.
- Token design itself determines how well Transformer language models learn useful representations of molecules.
- Strong results are possible without three-dimensional structural data in the prediction pipeline.
- The learned atomic contexts support generalization to proteins not seen during training.
Where Pith is reading between the lines
- The learned codebook could be inspected to identify recurring chemical motifs that drive the performance lift.
- The same quantization step might be applied to other graph-structured domains such as materials or protein sequences alone.
- Larger-scale pretraining on diverse molecular graphs could further increase the advantage of these discrete tokens for generative tasks.
Load-bearing premise
The codebook entries obtained from vector quantization on GNN embeddings correspond to chemically meaningful atomic contexts that remain relevant to the downstream task and generalize beyond the training distribution.
What would settle it
Retraining the same downstream model with randomly assigned discrete labels in place of the learned VQ tokens and observing no drop or even an increase in protein-ligand prediction accuracy under the protein-cold split would show that semantic content is not required for the reported gains.
Figures



read the original abstract
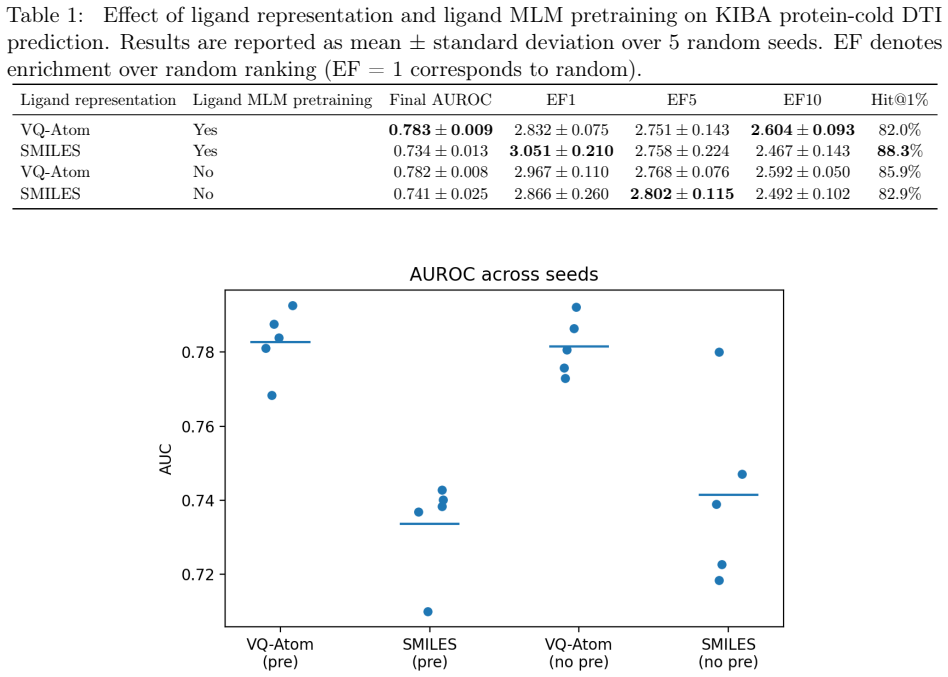
Large language models succeed by combining large-scale pretraining with meaningful discrete tokens. In molecular machine learning, SMILES is widely used as a token representation, but it is primarily a linearization format for molecular graphs rather than a semantic decomposition of chemistry. We propose VQ-Atom, a semantic tokenization framework that assigns discrete atom-level tokens based on local chemical environments via vector quantization. Unlike SMILES tokens, VQ-Atom tokens encode graph-local chemical context and are aligned with molecular structure. On protein-cold drug--target interaction prediction using the KIBA dataset, VQ-Atom substantially improves global ranking performance, achieving AUROC of 0.79 while substantially outperforming both SMILES-based and continuous molecular representations under an identical downstream architecture. Furthermore, VQ-Atom enables approximately 3 times faster downstream training than continuous atom-level representations by replacing per-atom continuous features with reusable discrete tokens. These results suggest that molecular tokenization is not merely a preprocessing step, but a central design choice. In particular, well-structured tokens can encode substantial chemical semantics, reducing the burden on downstream learning. VQ-Atom can be interpreted as defining a molecular language, where tokens correspond to chemically meaningful atomic environments, suggesting that token design may constitute an additional axis of machine learning research alongside architecture, objectives, and optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VQ-Atom, a semantic discretization framework that uses graph neural network embeddings followed by vector quantization to convert continuous atom-level representations into discrete tokens corresponding to local chemical environments. These tokens are positioned as a molecular language for subsequent Transformer-based pretraining. The approach is evaluated on protein-ligand interaction prediction under a protein-cold split without 3D structural information, with the claim that it yields consistent improvements over conventional tokenization methods.
Significance. If the empirical gains are robust and the discretization is shown to capture chemically relevant contexts that generalize, the work could meaningfully advance molecular representation learning by moving beyond syntactic tokenizations such as SMILES toward semantically grounded discrete units. The protein-cold split provides a relevant test of generalization for drug-discovery applications. The emphasis on token design as a key factor is a useful perspective, though its impact depends on stronger validation of the semantic claims.
major comments (2)
- [Results section] Results section: The abstract and introduction assert consistent predictive improvements, yet no specific quantitative metrics (e.g., AUC or precision values), baseline implementations, number of runs, or statistical significance tests are supplied. This absence prevents verification of the magnitude and reliability of the reported gains, which are central to the paper's contribution.
- [Method and interpretation sections] Method and interpretation sections: The claim that codebook entries represent 'chemically meaningful atomic contexts' is not supported by any post-hoc analysis (e.g., mapping indices to atom types, hybridization states, or functional groups) or ablation isolating the semantic content of the tokens from other pipeline choices such as GNN depth or the Transformer objective. Without these checks, performance differences could arise from regularization effects of discretization rather than chemical relevance, weakening the interpretation of the headline result.
minor comments (2)
- [Notation] Notation for embeddings, codebook, and quantization loss could be summarized in a table for clarity.
- [Related work] A few additional references to prior discrete representation work in graph-based molecular models would strengthen the related-work discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation and support for our claims.
read point-by-point responses
-
Referee: [Results section] Results section: The abstract and introduction assert consistent predictive improvements, yet no specific quantitative metrics (e.g., AUC or precision values), baseline implementations, number of runs, or statistical significance tests are supplied. This absence prevents verification of the magnitude and reliability of the reported gains, which are central to the paper's contribution.
Authors: We acknowledge that the abstract and introduction currently describe improvements only in qualitative terms. The results section reports comparative performance on the protein-ligand task, but to address the referee's concern directly we will revise the abstract and introduction to include explicit quantitative metrics (e.g., AUC values), details on baseline implementations, the number of independent runs performed, and statistical significance testing. These changes will make the magnitude and reliability of the gains immediately verifiable. revision: yes
-
Referee: [Method and interpretation sections] Method and interpretation sections: The claim that codebook entries represent 'chemically meaningful atomic contexts' is not supported by any post-hoc analysis (e.g., mapping indices to atom types, hybridization states, or functional groups) or ablation isolating the semantic content of the tokens from other pipeline choices such as GNN depth or the Transformer objective. Without these checks, performance differences could arise from regularization effects of discretization rather than chemical relevance, weakening the interpretation of the headline result.
Authors: We agree that additional analysis is needed to substantiate the semantic interpretation. In the revised manuscript we will add a post-hoc examination mapping codebook entries to atom types, hybridization states, and functional groups, together with ablation studies that vary GNN depth and isolate the contribution of vector quantization from the Transformer pretraining objective. These additions will help distinguish semantic relevance from possible regularization effects. revision: yes
Circularity Check
No significant circularity; empirical gains reported from experiments
full rationale
The paper proposes VQ-Atom as a discretization method that applies vector quantization to GNN-derived atom embeddings to produce discrete tokens representing local chemical contexts, then uses these tokens for Transformer pretraining and evaluates the approach on protein-ligand binding prediction under a protein-cold split. The headline result is framed as an observed performance improvement relative to baseline tokenization schemes, not as a quantity algebraically derived from or equivalent to fitted parameters, self-citations, or prior ansatzes within the same work. No equations or steps in the described pipeline reduce by construction to the inputs (e.g., no fitted codebook entries are relabeled as predictions of chemical meaning, and no uniqueness theorem is imported from overlapping prior authorship). The validation remains externally falsifiable via held-out experimental metrics, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph neural network embeddings of atoms capture local chemical environments in a form suitable for meaningful discretization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Vector quantization is applied using per-atom-type codebooks of size 10,000, initialized via k-means and updated with exponential moving averages... L = L_commit + λ1 L_lat-repel + λ2 L_cb-repel
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VQ-Atom tokens encode graph-local chemical context and are aligned with molecular structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.