Anytime PAC-Bayes for Constrained Density-Ratio Networks under Covariate Shift
Pith reviewed 2026-05-25 05:52 UTC · model grok-4.3
The pith
A constrained density-ratio network approximates dP/dQ to feed anytime PAC-Bayes certificates under covariate shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
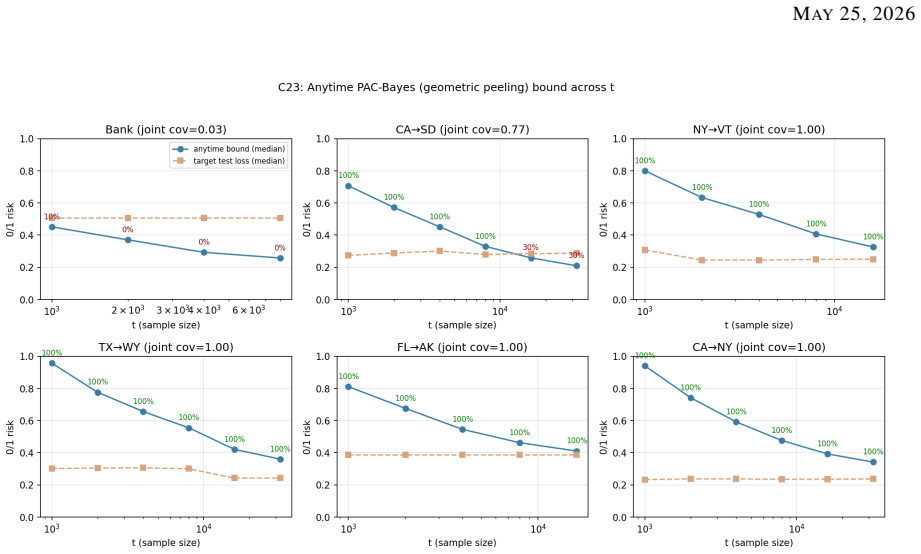
A constrained density-ratio network approximates the Radon-Nikodym derivative r* = dP/dQ and supplies the weights for an anytime PAC-Bayes generalization certificate that decomposes target risk into a ratio-bias term controlled by L2(Q) error and a generalization-gap term controlled by weighted-loss variability.
What carries the argument
The constrained density-ratio network that enforces normalization and moment-matching identities as hard integral constraints through an augmented-Lagrangian scheme, combined with geometric peeling to strengthen fixed-time Bernoulli-KL PAC-Bayes bounds into an anytime certificate uniform in t.
If this is right
- The learned ratio reduces target 0/1 loss compared with unweighted ERM and classical direct ratio estimators.
- The certificate remains valid uniformly for all t greater than or equal to a minimum time and quantifies stability under L2(Q) perturbations of the ratio.
- The network-weighted Gibbs posterior is the unique KL-regularized minimizer of the importance-weighted risk.
- A single fixed-time coverage failure aligns one-to-one with label-shift magnitude, confirming the covariate-only modeling choice is operationally tight.
Where Pith is reading between the lines
- If the L2(Q) approximation error of the ratio can be bounded independently, the risk decomposition cleanly isolates estimation bias from generalization error.
- The same constrained-network construction could be tested on problems where mild label shift is known to be present to measure the degradation of the certificate.
- Replacing the augmented-Lagrangian constraint enforcement with a softer penalty might trade calibration for faster training while preserving the anytime guarantee.
Load-bearing premise
The distribution shift is purely covariate-based with no label shift.
What would settle it
A PAC-Bayes coverage failure occurs precisely when label shift is introduced while covariate shift remains controlled.
Figures







read the original abstract
A unified framework for learning under covariate shift is presented, in which a constrained density-ratio network approximates the Radon-Nikodym derivative $r^\star = dP/dQ$ and feeds an anytime PAC-Bayes generalization certificate. A change-of-measure identity decomposes the gap between target risk and importance-weighted source risk into a ratio-bias term governed by $\|r_\theta - r^\star\|_{L^2(Q)}$ and a generalization-gap term governed by the variability of the weighted loss. Normalization and moment-matching identities are enforced as hard integral constraints through an augmented-Lagrangian scheme, with a second-moment penalty controlling the effective sample size. PAC-Bayes is instantiated on the weighted risk in a fixed-time regime that yields Bernoulli-KL bounds, identifies the network-weighted Gibbs posterior as the unique KL-regularized minimizer, and quantifies stability under $L^2(Q)$ perturbations of the learned ratio, and is then strengthened by geometric peeling to an anytime certificate uniform in $t \geq t_{\min}$. A pre-registered two-campaign protocol combining a patch test against analytic ground truth with a real-data deployment validates the framework: the network produces calibrated ratios, reduces target $0/1$ loss against unweighted ERM and classical direct ratio-estimation baselines, and attains the anytime certificate. A single fixed-time coverage failure is recorded, with per-split coverage aligning one-to-one with the magnitude of the label shift, confirming that the covariate-only assumption is operationally tight rather than a defect of the certificate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a unified framework for learning under covariate shift: a constrained density-ratio network approximates r^*=dP/dQ via augmented-Lagrangian enforcement of E_Q[r_θ]=1 and moment-matching plus a second-moment penalty; a change-of-measure identity decomposes target risk minus weighted source risk into an L²(Q) ratio-bias term and a generalization gap; PAC-Bayes is applied to the weighted risk to obtain Bernoulli-KL bounds on a network-weighted Gibbs posterior, with stability under L² perturbations and geometric peeling to an anytime certificate uniform in t; pre-registered experiments (patch test on analytic ground truth plus real-data deployment) show calibrated ratios, reduced 0/1 loss versus baselines, and coverage that aligns with label-shift magnitude.
Significance. If the derivations hold, the work would supply a practical route to anytime-valid certificates under pure covariate shift by tightly coupling constrained ratio estimation with PAC-Bayes, including an explicit decomposition of bias and generalization terms and a pre-registered validation protocol. The geometric-peeling extension to anytime bounds and the explicit stability quantification under L²(Q) perturbations of the learned ratio are potentially useful technical contributions.
major comments (2)
- [Abstract] Abstract (PAC-Bayes instantiation paragraph): the claim that the framework 'yields Bernoulli-KL bounds' on the weighted risk presupposes that the importance-weighted loss r_θ·ℓ (ℓ the 0/1 loss) takes values in [0,1]. The only controls stated are the hard integral constraints E_Q[r_θ]=1, moment matching, and a second-moment penalty; these do not imply an almost-sure upper bound on r_θ, so r_θ·ℓ ranges in [0,r_θ] and the standard Bernoulli-KL derivation does not apply without an additional range argument or rescaling.
- [Abstract] Abstract (change-of-measure identity and weighted Gibbs posterior): the decomposition of target risk minus weighted source risk into an L²(Q) ratio-bias term plus generalization gap, followed by identification of the network-weighted Gibbs posterior as the unique KL-regularized minimizer, is load-bearing for the certificate; without the range control above, the subsequent stability claim under L²(Q) perturbations of the learned ratio cannot be instantiated with the stated Bernoulli-KL form.
minor comments (2)
- [Abstract] The abstract refers to 'geometric peeling' for the anytime certificate but does not indicate the precise peeling schedule or the dependence on t_min; a short clarifying sentence would help readers locate the argument in the main text.
- [Abstract] The single coverage failure is attributed to label shift, but the manuscript should explicitly state whether any diagnostic for detecting label shift (beyond post-hoc alignment) is provided to users of the certificate.
Simulated Author's Rebuttal
We thank the referee for the careful identification of the range condition needed to instantiate the Bernoulli-KL PAC-Bayes bounds. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract (PAC-Bayes instantiation paragraph): the claim that the framework 'yields Bernoulli-KL bounds' on the weighted risk presupposes that the importance-weighted loss r_θ·ℓ (ℓ the 0/1 loss) takes values in [0,1]. The only controls stated are the hard integral constraints E_Q[r_θ]=1, moment matching, and a second-moment penalty; these do not imply an almost-sure upper bound on r_θ, so r_θ·ℓ ranges in [0,r_θ] and the standard Bernoulli-KL derivation does not apply without an additional range argument or rescaling.
Authors: We agree that the standard Bernoulli-KL form requires the (weighted) loss to lie in [0,1] almost surely. The stated integral constraints and second-moment penalty control expectations and effective sample size but do not enforce an a.s. upper bound on r_θ. We will revise the manuscript by adding an explicit almost-sure bound on r_θ (via an additional hard constraint or clipping term in the augmented Lagrangian) and will rescale the weighted loss accordingly so that the Bernoulli-KL derivation applies directly. The abstract and the PAC-Bayes instantiation section will be updated to state this range control explicitly. revision: yes
-
Referee: [Abstract] Abstract (change-of-measure identity and weighted Gibbs posterior): the decomposition of target risk minus weighted source risk into an L²(Q) ratio-bias term plus generalization gap, followed by identification of the network-weighted Gibbs posterior as the unique KL-regularized minimizer, is load-bearing for the certificate; without the range control above, the subsequent stability claim under L²(Q) perturbations of the learned ratio cannot be instantiated with the stated Bernoulli-KL form.
Authors: We concur that the change-of-measure decomposition, the identification of the network-weighted Gibbs posterior, and the L²(Q)-stability claim all presuppose a valid Bernoulli-KL bound on the weighted risk. Once the range control is added as described above, these elements will be instantiated with the corrected Bernoulli-KL form. We will revise the abstract to make the dependence on the range condition and its resolution explicit, and we will verify that the stability quantification remains valid under the added constraint. revision: yes
Circularity Check
No circularity: derivation applies external PAC-Bayes to learned weighted risk
full rationale
The abstract describes a change-of-measure decomposition into ratio-bias and generalization terms, hard constraints on the density-ratio network via augmented Lagrangian, a second-moment penalty, and instantiation of standard Bernoulli-KL PAC-Bayes bounds on the importance-weighted risk to obtain an anytime certificate via geometric peeling. These steps invoke general theorems (change-of-measure identities and PAC-Bayes) rather than reducing any claimed prediction or certificate to a fitted quantity or self-citation by construction. No self-citations, ansatzes smuggled via prior work, or uniqueness theorems from the same authors are referenced. The framework remains self-contained against external benchmarks such as PAC-Bayes theory and moment-matching optimization.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function.Jour- nal of Statistical Planning and Inference, 90(2):227–244, 2000. https://doi.org/10.1016/S0378-3758(00) 00115-4
-
[2]
M. Sugiyama, M. Krauledat, and K.-R. Müller. Covariate shift adaptation by importance weighted cross validation. Journal of Machine Learning Research, 8:985–1005, 2007
work page 2007
-
[3]
J. A. Anderson. Multivariate logistic compounds.Biometrika, 66(1):17–26, 1979. https://doi.org/10.1093/ biomet/66.1.17
work page 1979
-
[4]
S. Moro, P. Cortez, and P. Rita. A data-driven approach to predict the success of bank telemarketing.Decision Support Systems, 62:22–31, 2014.https://doi.org/10.1016/j.dss.2014.03.001
- [5]
-
[6]
M. Sugiyama, S. Nakajima, H. Kashima, P. von Bünau, and M. Kawanabe. Direct importance estimation with model selection and its application to covariate shift adaptation. InAdvances in Neural Information Processing Systems 20, pages 1433–1440, 2008
work page 2008
-
[7]
M. Sugiyama, T. Suzuki, S. Nakajima, H. Kashima, P. von Bünau, and M. Kawanabe. Direct importance estimation for covariate shift adaptation.Annals of the Institute of Statistical Mathematics, 60(4):699–746, 2008. https://doi.org/10.1007/s10463-008-0197-x
-
[8]
T. Kanamori, S. Hido, and M. Sugiyama. A least-squares approach to direct importance estimation.Journal of Machine Learning Research, 10:1391–1445, 2009
work page 2009
-
[9]
X. Nguyen, M. J. Wainwright, and M. I. Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010. https: //doi.org/10.1109/TIT.2010.2068870
-
[10]
A. G. Zhang and J. Chen. Density ratio model with data-adaptive basis function.Journal of Multivariate Analysis, 191:105043, 2022.https://doi.org/10.1016/j.jmva.2022.105043
- [11]
- [12]
-
[13]
S. Liu, M. Yamada, N. Collier, and M. Sugiyama. Change-point detection in time-series data by relative density- ratio estimation.Neural Networks, 43:72–83, 2013.https://doi.org/10.1016/j.neunet.2013.01.012
-
[14]
M. Sugiyama, T. Suzuki, and T. Kanamori.Density Ratio Estimation in Machine Learning. Cambridge University Press, Cambridge, 2012.https://doi.org/10.1017/CBO9781139035613
-
[15]
D. A. McAllester. Some PAC-Bayesian theorems.Machine Learning, 37(3):355–363, 1999. https://doi.org/ 10.1023/A:1007618624809
-
[16]
D. A. McAllester. PAC-Bayesian model averaging. InProceedings of the Twelfth Annual Conference on Computational Learning Theory (COLT), pages 164–170, 1999. https://doi.org/10.1145/307400.307435
-
[17]
D. A. McAllester. PAC-Bayesian stochastic model selection.Machine Learning, 51(1):5–21, 2003. https: //doi.org/10.1023/A:1021840411064. 47 MAY25, 2026
-
[18]
D. A. McAllester. Simplified PAC-Bayesian margin bounds. InProceedings of the 16th Annual Con- ference on Computational Learning Theory (COLT), pages 203–215, 2003. https://doi.org/10.1007/ 978-3-540-45167-9_16
work page 2003
-
[19]
M. Seeger. PAC-Bayesian generalisation error bounds for Gaussian process classification.Journal of Machine Learning Research, 3:233–269, 2002
work page 2002
-
[20]
Pac-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning
O. Catoni.PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning, volume 56 ofIMS Lecture Notes Monograph Series. Institute of Mathematical Statistics, Beachwood, OH, 2007. https: //arxiv.org/abs/0712.0248
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[21]
I. Tolstikhin and Y . Seldin. PAC-Bayes-empirical-Bernstein inequality. InAdvances in Neural Information Processing Systems 26, pages 109–117, 2013
work page 2013
-
[22]
N. Thiemann, C. Igel, O. Wintenberger, and Y . Seldin. A strongly quasiconvex PAC-Bayesian bound. In Proceedings of the 28th International Conference on Algorithmic Learning Theory (ALT), volume 76 ofProceedings of Machine Learning Research, pages 1–26, 2017
work page 2017
-
[23]
P. Germain, A. Lacasse, F. Laviolette, M. Marchand, and S. Shanian. From PAC-Bayes bounds to KL regularization. InAdvances in Neural Information Processing Systems 22, pages 603–610, 2009
work page 2009
-
[24]
P. Alquier, J. Ridgway, and N. Chopin. On the properties of variational approximations of Gibbs posteriors. Journal of Machine Learning Research, 17(236):1–41, 2016
work page 2016
-
[25]
J. Keshet, D. McAllester, and T. Hazan. PAC-Bayesian approach for minimization of phoneme error rate. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2224–2227, 2011.https://doi.org/10.1109/ICASSP.2011.5946923
- [26]
-
[27]
B. Rodríguez-Gálvez, R. Thobaben, and M. Skoglund. More PAC-Bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime validity.Journal of Machine Learning Research, 25(110):1–43, 2024
work page 2024
-
[28]
D. A. Levin and Y . Peres.Markov Chains and Mixing Times. American Mathematical Society, second edition, 2017.https://bookstore.ams.org/mbk-107
work page 2017
-
[29]
T. M. Cover and J. A. Thomas.Elements of Information Theory. John Wiley & Sons, second edition, 2005. https://doi.org/10.1002/047174882X
-
[30]
Billingsley.Probability and Measure
P. Billingsley.Probability and Measure. Wiley Series in Probability and Statistics. John Wiley & Sons, anniversary edition, 2012. ISBN 978-1-118-34191-9
work page 2012
-
[31]
Çınlar.Probability and Stochastics
E. Çınlar.Probability and Stochastics. Graduate Texts in Mathematics, vol. 261. Springer, 2011. https: //doi.org/10.1007/978-0-387-87859-1
-
[32]
L. C. Evans.Partial Differential Equations. Graduate Studies in Mathematics, vol. 19. American Mathematical Society, second edition, 2010.https://bookstore.ams.org/gsm-19-r
work page 2010
-
[33]
M. Ledoux and M. Talagrand.Probability in Banach Spaces: Isoperimetry and Processes. Classics in Mathematics. Springer-Verlag Berlin Heidelberg, 1991, reprinted 2011.https://doi.org/10.1007/978-3-642-20212-4. 48 MAY25, 2026 A Measure theory and the Radon-Nikodym theorem The entire framework developed in this paper rests on a single object, the Radon-Nikod...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.