Set-Valued Policy Learning
Pith reviewed 2026-05-20 06:57 UTC · model grok-4.3
The pith
Set-valued policies output sets of plausible treatments rather than single recommendations to reflect decision uncertainty in multiple-treatment settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a set-valued policy learning paradigm for the multiple-treatment setting, in which policies output a set of plausible treatments rather than a single recommendation. This formulation enables intrinsic uncertainty quantification, with the size of the predicted set reflecting the degree of decision ambiguity. We extend the learning-to-defer framework to multiple treatments via a novel greatest Lower Bound method, and introduce conformal policy learning, which bridges the gap between unobserved ground-truth optimal treatments and estimated optimal treatment rules. Drawing on insights from the noisy-label literature, we develop a randomness-injection approach that guarantees marginal
What carries the argument
The set-valued policy that maps covariates to a collection of treatments whose size signals decision ambiguity, together with the randomness-injection technique that produces marginal coverage without assumptions on the black-box optimal rule.
If this is right
- When estimation uncertainty is high the policy naturally returns larger sets, giving clinicians explicit latitude to choose among options.
- The methods produce policies that remain actionable while automatically trading off performance against reliability in settings such as IVF.
- Conformal policy learning supplies coverage guarantees that survive model misspecification or finite-sample effects that normally plague point-valued rules.
- The framework extends directly to any multi-action causal decision problem where only noisy estimates of optimality are available.
Where Pith is reading between the lines
- Larger sets could serve as a signal to defer the final choice to a human expert or to collect additional patient data.
- The same construction might be applied to sequential decision problems by treating each time step as a multi-treatment choice.
- Empirical tests could check whether set sizes correlate with actual clinical disagreement among physicians on the same cases.
Load-bearing premise
The randomness-injection approach guarantees marginal coverage without requiring assumptions on underlying black-box optimal treatment rules.
What would settle it
A controlled simulation in which the randomness-injection procedure is applied to data with fully known optimal treatment assignments and the resulting sets fail to contain the true optimal treatment at the promised marginal rate would falsify the coverage claim.
Figures







read the original abstract
Conventional treatment policies map patient covariates to a single recommended intervention in order to maximize expected clinical outcomes. Although a rich body of causal inference methods has been developed to estimate such policies, point-valued recommendations can be highly sensitive to estimation uncertainty, model specification, and finite-sample variability, while typically providing little guidance about how confident one should be in the recommended action. In this work, we propose a set-valued policy learning paradigm for the multiple-treatment setting, in which policies output a set of plausible treatments rather than a single recommendation. This formulation enables intrinsic uncertainty quantification, with the size of the predicted set reflecting the degree of decision ambiguity. We extend the learning-to-defer framework to multiple treatments via a novel \textit{greatest Lower Bound} method, and introduce \textit{conformal policy learning}, which bridges the gap between unobserved ground-truth optimal treatments and estimated optimal treatment rules. Drawing on insights from the noisy-label literature, we develop a randomness-injection approach that guarantees marginal coverage without requiring assumptions on underlying black-box optimal treatment rules. Through experiments on synthetic data and a real-world application to In-Vitro Fertilization (IVF), we demonstrate that our methods produce robust and actionable policies that naturally incorporate clinical considerations while effectively balancing performance and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a set-valued policy learning paradigm for the multiple-treatment setting, in which policies output sets of plausible treatments to quantify decision uncertainty rather than single recommendations. It extends the learning-to-defer framework via a novel greatest lower bound method and introduces conformal policy learning that employs a randomness-injection technique to deliver marginal coverage guarantees without strong assumptions on black-box optimal treatment rules. The approach is evaluated on synthetic data and a real-world IVF application.
Significance. If the coverage guarantees hold under the stated conditions, the work offers a useful advance in robust policy learning for causal inference and clinical applications by naturally incorporating uncertainty through set size. The randomness-injection method, drawing from noisy-label ideas, provides a creative bridge between estimated rules and unobserved ground truth, and the IVF experiment illustrates practical utility in balancing performance with reliability.
major comments (1)
- [Conformal policy learning and randomness-injection] Conformal policy learning section: the randomness-injection approach is presented as guaranteeing marginal coverage without assumptions on the black-box optimal treatment rules. However, conformity scores are constructed from the estimated rules; the manuscript must explicitly address whether rule estimation and the subsequent injection/calibration step use disjoint data (or otherwise preserve exchangeability), as overlap would undermine the unconditional coverage claim that is load-bearing for the central contribution.
minor comments (1)
- [Abstract] Abstract and method descriptions: the phrase 'greatest Lower Bound' appears with inconsistent capitalization; align with the formal definition and notation used in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying this important clarification needed for the conformal policy learning procedure. We address the concern below and have revised the manuscript to make the data-splitting and exchangeability arguments fully explicit.
read point-by-point responses
-
Referee: [Conformal policy learning and randomness-injection] Conformal policy learning section: the randomness-injection approach is presented as guaranteeing marginal coverage without assumptions on the black-box optimal treatment rules. However, conformity scores are constructed from the estimated rules; the manuscript must explicitly address whether rule estimation and the subsequent injection/calibration step use disjoint data (or otherwise preserve exchangeability), as overlap would undermine the unconditional coverage claim that is load-bearing for the central contribution.
Authors: We agree that explicit treatment of exchangeability is essential for the unconditional marginal coverage claim. In the revised manuscript we now state that the procedure employs sample splitting: the black-box optimal treatment rule is estimated on a dedicated training fold, while the randomness-injection step and the subsequent calibration of conformity scores are performed on a completely disjoint calibration fold. Because the calibration observations are exchangeable with future test points and independent of the rule estimator, the standard conformal argument applies directly and yields the stated marginal coverage guarantee without further assumptions on the underlying rule. We have added a new paragraph in Section 4.2 together with a diagram (Figure 3) that illustrates the three-way split (training / calibration / test) and the corresponding exchangeability statement. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper's central contribution is a randomness-injection method for marginal coverage in set-valued policies, presented as drawing from noisy-label literature and requiring no assumptions on black-box optimal rules. No equations or steps in the provided abstract reduce a claimed prediction or guarantee to a fitted input or self-citation by construction. The derivation treats the black-box as fixed and invokes external insights, keeping the core claim independent rather than self-referential. This is the common honest non-finding for papers whose guarantees rest on stated external assumptions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we develop a randomness-injection approach that guarantees marginal coverage without requiring assumptions on underlying black-box optimal treatment rules
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
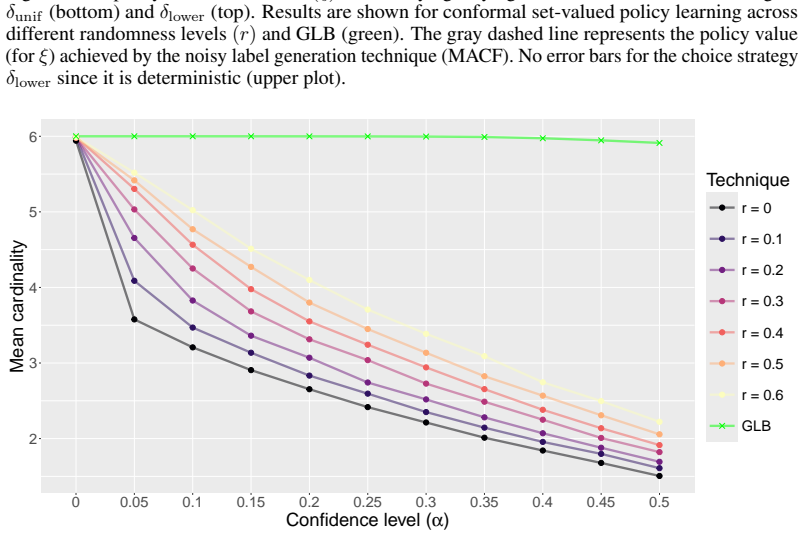
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ahmed M Alaa, Zaid Ahmad, and Mark van der Laan. Conformal meta-learners for predictive inference of individual treatment effects.Advances in neural information processing systems, 36:47682–47703, 2023
work page 2023
-
[2]
Generalized random forests.Ann
Susan Athey, Julie Tibshirani, and Stefan Wager. Generalized random forests.Ann. Statist., 47(2):1148–1178, 2019. ISSN 0090-5364,2168-8966. doi: 10.1214/18-AOS1709. URL https://doi.org/10.1214/18-AOS1709
-
[3]
On the utility of prediction sets in human-ai teams, 2022
Varun Babbar, Umang Bhatt, and Adrian Weller. On the utility of prediction sets in human-ai teams, 2022. URLhttps://arxiv.org/abs/2205.01411
-
[4]
Eli Ben-Michael, D James Greiner, Melody Huang, Kosuke Imai, Zhichao Jiang, and Sooahn Shin. Does ai help humans make better decisions? a statistical evaluation framework for experimental and observational studies.Proceedings of the National Academy of Sciences, 122 (38):e2505106122, 2025
work page 2025
-
[5]
Predictive inference with weak supervision.J
Maxime Cauchois, Suyash Gupta, Alnur Ali, and John Duchi. Predictive inference with weak supervision.J. Mach. Learn. Res., 25:Paper No. [118], 45, 2024. ISSN 1532-4435,1533-7928
work page 2024
-
[6]
XGBoost : A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, page 785–794, New York, NY , USA, 2016. Association for Computing Machinery. doi: 10.1145/2939672.2939785
-
[7]
Chen Cheng, Hilal Asi, and John Duchi. How many labelers do you have? a closer look at gold-standard labels.arXiv preprint arXiv:2206.12041, 2022
-
[8]
Victor Chernozhukov, Kaspar Wüthrich, and Yinchu Zhu. Toward personalized inference on individual treatment effects.Proceedings of the National Academy of Sciences, 120(7): e2300458120, 2023
work page 2023
-
[9]
Bo Dai, Ofir Nachum, Yinlam Chow, Lihong Li, Csaba Szepesvári, and Dale Schuurmans. Coindice: Off-policy confidence interval estimation.Advances in neural information processing systems, 33:9398–9411, 2020
work page 2020
-
[10]
Giovanni De Toni, Nastaran Okati, Suhas Thejaswi, Eleni Straitouri, and Manuel Rodriguez. Towards human-ai complementarity with prediction sets.Advances in Neural Information Processing Systems, 37:31380–31409, 2024
work page 2024
-
[11]
Doubly Robust Policy Evaluation and Learning
Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. arXiv preprint arXiv:1103.4601, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[12]
Angelopoulos, Asaf Gendler, and Yaniv Romano
Bat-Sheva Einbinder, Shai Feldman, Stephen Bates, Anastasios N. Angelopoulos, Asaf Gendler, and Yaniv Romano. Label noise robustness of conformal prediction.J. Mach. Learn. Res., 25: Paper No. [328], 66, 2024. ISSN 1532-4435,1533-7928
work page 2024
-
[13]
Laura Fuentes-Vicente, Mathieu Even, Gaëlle Dormion, Julie Josse, and Antoine Chambaz. Policy learning under constraint: Maximizing a primary outcome while controlling an adverse event.arXiv preprint arXiv:2601.22717, 2026
-
[14]
Marah Ghoummaid and Uri Shalit. When to act and when to ask: policy learning with deferral under hidden confounding.Advances in Neural Information Processing Systems, 37:56108– 56135, 2024
work page 2024
-
[15]
Conformal prediction and human decision making.arXiv preprint arXiv:2503.11709, 2025
Jessica Hullman, Yifan Wu, Dawei Xie, Ziyang Guo, and Andrew Gelman. Conformal prediction and human decision making.arXiv preprint arXiv:2503.11709, 2025
-
[16]
Kosuke Imai, Zhichao Jiang, D James Greiner, Ryan Halen, and Sooahn Shin. Experimental evaluation of algorithm-assisted human decision-making: Application to pretrial public safety assessment.Journal of the Royal Statistical Society Series A: Statistics in Society, 186(2): 167–189, 2023. 11
work page 2023
-
[17]
Ying Jin, Zhimei Ren, and Emmanuel J. Candès. Sensitivity analysis of individual treatment effects: a robust conformal inference approach.Proc. Natl. Acad. Sci. USA, 120(6):Paper No. e2214889120, 13, 2023. ISSN 0027-8424,1091-6490
work page 2023
-
[18]
Jef Jonkers, Jarne Verhaeghe, Glenn Van Wallendael, Luc Duchateau, and Sofie Van Hoecke. Conformal convolution and monte carlo meta-learners for predictive inference of individual treatment effects, 2025. URLhttps://arxiv.org/abs/2402.04906
-
[19]
kernlab-an s4 package for kernel methods in r.Journal of statistical software, 11:1–20, 2004
Alexandros Karatzoglou, Alexandros Smola, Kurt Hornik, and Achim Zeileis. kernlab-an s4 package for kernel methods in r.Journal of statistical software, 11:1–20, 2004
work page 2004
-
[20]
Edward H. Kennedy. Towards optimal doubly robust estimation of heterogeneous causal effects. Electron. J. Stat., 17(2):3008–3049, 2023. doi: 10.1214/23-ejs2157
-
[21]
Danijel Kivaranovic, Robin Ristl, Martin Posch, and Hannes Leeb. Conformal prediction intervals for the individual treatment effect.arXiv preprint arXiv:2006.01474, 2020
-
[22]
Shayan Kiyani, George Pappas, Aaron Roth, and Hamed Hassani. Decision theoretic foundations for conformal prediction: Optimal uncertainty quantification for risk-averse agents.arXiv preprint arXiv:2502.02561, 2025
-
[23]
Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. Metalearners for estimating heterogeneous treatment effects using machine learning.Proceedings of the National Academy of Sciences of the United States of America, 116:4156 – 4165, 2017
work page 2017
-
[24]
Human-ai collaboration in healthcare: A review and research agenda
Yi Lai, Atreyi Kankanhalli, and Desmond Ong. Human-ai collaboration in healthcare: A review and research agenda. 2021
work page 2021
-
[25]
Lihua Lei and Emmanuel J. Candès. Conformal inference of counterfactuals and individual treatment effects.J. R. Stat. Soc. Ser. B. Stat. Methodol., 83(5):911–938, 2021. ISSN 1369- 7412,1467-9868
work page 2021
-
[26]
Jiannan Lu, Peng Ding, and Tirthankar Dasgupta. Treatment effects on ordinal outcomes: Causal estimands and sharp bounds.Journal of Educational and Behavioral Statistics, 43(5): 540–567, 2018
work page 2018
-
[27]
Alex Luedtke and Incheoul Chung. One-step estimation of differentiable hilbert-valued parame- ters.The Annals of Statistics, 52(4):1534–1563, 2024
work page 2024
-
[28]
Alexander R. Luedtke and Mark J. van der Laan. Optimal individualized treatments in resource- limited settings.Int. J. Biostat., 12(1):283–303, 2016. doi: 10.1515/ijb-2015-0007
-
[29]
Lina M Montoya, Mark J van der Laan, Alexander R Luedtke, Jennifer L Skeem, Jeremy R Coyle, and Maya L Petersen. The optimal dynamic treatment rule superlearner: considerations, performance, and application to criminal justice interventions.The International Journal of Biostatistics, 19(1):217–238, 2023
work page 2023
-
[30]
Consistent estimators for learning to defer to an expert
Hussein Mozannar and David Sontag. Consistent estimators for learning to defer to an expert. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 7076–7087. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/mozannar20b.html
work page 2020
-
[31]
J. A. Nelder and R. W. M. Wedderburn. Generalized linear models.Journal of the Royal Statistical Society. Series A (General), 135(3):370–384, 1972
work page 1972
-
[32]
Policy learning with the polle package.arXiv preprint arXiv:2212.02335, 2022
Andreas Nordland and Klaus K Holst. Policy learning with the polle package.arXiv preprint arXiv:2212.02335, 2022
-
[33]
Inductive confidence machines for regression
Harris Papadopoulos, Kostas Proedrou, V olodya V ovk, and Alex Gammerman. Inductive confidence machines for regression. InMachine learning: ECML 2002, volume 2430 ofLecture Notes in Comput. Sci., pages 345–356. Springer, Berlin, 2002. ISBN 3-540-44036-4. doi: 10.1007/3-540-36755-1\_29. URLhttps://doi.org/10.1007/3-540-36755-1_29. 12
-
[34]
URL https://CRAN.R-project.org/package=SuperLearner
Eric Polley, Erin LeDell, Chris Kennedy, and Mark van der Laan.SuperLearner: Super Learner Prediction, 2024. URL https://CRAN.R-project.org/package=SuperLearner. R package version 2.0-29
work page 2024
-
[35]
Min Qian and Susan A. Murphy. Performance guarantees for individualized treatment rules. Ann. Statist., 39(2):1180–1210, 2011. ISSN 0090-5364,2168-8966. doi: 10.1214/10-AOS864. URLhttps://doi.org/10.1214/10-AOS864
-
[36]
Donald B. Rubin. Causal inference using potential outcomes: design, modeling, decisions.J. Amer. Statist. Assoc., 100(469):322–331, 2005. ISSN 0162-1459,1537-274X. doi: 10.1198/ 016214504000001880. URLhttps://doi.org/10.1198/016214504000001880
-
[37]
Transduction with confidence and credibility
Craig Saunders, Alexander Gammerman, and V olodya V ovk. Transduction with confidence and credibility. InProceedings of the Sixteenth International Joint Conference on Artificial Intelligence, IJCAI ’99, page 722–726, San Francisco, CA, USA, 1999. Morgan Kaufmann Publishers Inc. ISBN 1558606130
work page 1999
-
[38]
Conformal prediction for causal effects of continuous treatments, 2025
Maresa Schröder, Dennis Frauen, Jonas Schweisthal, Konstantin Heß, Valentyn Melnychuk, and Stefan Feuerriegel. Conformal prediction for causal effects of continuous treatments, 2025. URLhttps://arxiv.org/abs/2407.03094
-
[39]
Matteo Sesia, Y . X. Rachel Wang, and Xin Tong. Adaptive conformal classification with noisy labels.J. R. Stat. Soc. Ser. B. Stat. Methodol., 87(3):796–815, 2025. ISSN 1369-7412,1467-9868. doi: 10.1093/jrsssb/qkae114. URLhttps://doi.org/10.1093/jrsssb/qkae114
-
[40]
A tutorial on conformal prediction.J
Glenn Shafer and Vladimir V ovk. A tutorial on conformal prediction.J. Mach. Learn. Res., 9: 371–421, 2008. ISSN 1532-4435,1533-7928
work page 2008
-
[41]
Eleni Straitouri and Manuel Gomez Rodriguez. Designing decision support systems using counterfactual prediction sets.arXiv preprint arXiv:2306.03928, 2023
-
[42]
Improving expert predictions with conformal prediction, 2023
Eleni Straitouri, Lequn Wang, Nastaran Okati, and Manuel Gomez Rodriguez. Improving expert predictions with conformal prediction, 2023. URLhttps://arxiv.org/abs/2201.12006
-
[43]
Treatment allocation under uncertain costs.arXiv preprint arXiv:2103.11066, 2021
Hao Sun, Evan Munro, Georgy Kalashnov, Shuyang Du, and Stefan Wager. Treatment allocation under uncertain costs.arXiv preprint arXiv:2103.11066, 2021
-
[44]
Erik Sverdrup, Ayush Kanodia, Zhengyuan Zhou, Susan Athey, and Stefan Wager. policytree: Policy learning via doubly robust empirical welfare maximization over trees.Journal of Open Source Software, 5(50):2232, 2020
work page 2020
-
[45]
Muhammad Faaiz Taufiq, Jean-Francois Ton, Rob Cornish, Yee Whye Teh, and Arnaud Doucet. Conformal off-policy prediction in contextual bandits.Advances in Neural Information Pro- cessing Systems, 35:31512–31524, 2022
work page 2022
-
[46]
Julie Tibshirani, Susan Athey, Rina Friedberg, Vitor Hadad, David Hirshberg, Luke Miner, Erik Sverdrup, Stefan Wager, Marvin Wright, and Maintainer Julie Tibshirani. Package ‘grf’. Comprehensive R Archive Network, 2018
work page 2018
-
[47]
van der Laan and Sherri Rose.Targeted learning
Mark J. van der Laan and Sherri Rose.Targeted learning. Springer Series in Statistics. Springer, New York, 2011. ISBN 978-1-4419-9781-4. doi: 10.1007/978-1-4419-9782-1. URL https://doi.org/10.1007/978-1-4419-9782-1 . Causal inference for observational and experimental data
-
[48]
Mark J. van der Laan and Daniel Rubin. Targeted maximum likelihood learning.Int. J. Biostat., 2:Art. 11, 40, 2006. ISSN 1557-4679. doi: 10.2202/1557-4679.1043. URL https: //doi.org/10.2202/1557-4679.1043
-
[49]
Mark J. van der Laan, Eric C. Polley, and Alan E. Hubbard. Super learner.Stat. Appl. Genet. Mol. Biol., 6:Art. 25, 23, 2007. doi: 10.2202/1544-6115.1309
-
[50]
Conformal prediction for dose-response models with continuous treatments, 2024
Jarne Verhaeghe, Jef Jonkers, and Sofie Van Hoecke. Conformal prediction for dose-response models with continuous treatments, 2024. URLhttps://arxiv.org/abs/2409.20412. 13
-
[51]
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, New York, 2005. ISBN 978-0387-00152-4; 0-387-00152-2
work page 2005
-
[52]
Blei, Alp Kucukelbir, and Jon D
Stefan Wager and Susan Athey. Estimation and inference of heterogeneous treatment effects using random forests.J. Amer. Statist. Assoc., 113(523):1228–1242, 2018. doi: 10.1080/ 01621459.2017.1319839. URLhttps://doi.org/10.1080/01621459.2017.1319839
-
[53]
Marvin N. Wright and Andreas Ziegler. ranger: A fast implementation of random forests for high dimensional data in C++ and R.Journal of Statistical Software, 077:1–17, 2015
work page 2015
-
[54]
Bin Yu and Rebecca L Barter.Veridical data science: The practice of responsible data analysis and decision making. MIT Press, 2024
work page 2024
-
[55]
Conformal off-policy prediction
Yingying Zhang, Chengchun Shi, and Shikai Luo. Conformal off-policy prediction. InPro- ceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of Machine Learning Research, pages 2751–2768. PMLR, 25–27 Apr 2023. URLhttps://proceedings.mlr.press/v206/zhang23c.html. 14 A Technical proofs A.1 Proof of...
work page 2023
-
[56]
Conformal policy learning: the procedure involves estimation at steps 1 and 2 in Section 4.1 (a) Black-box label generation: we generated the noisy labels ˆA∗ i =B(D b)(Xi) (i.e. OTR estimators) using the double-robust Q-learning implementation via polle package [32]. We employed a linear model [ 31] for the Q-model (µ) while the g-model (πb) was specifie...
work page 2051
-
[57]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.