Exploiting Non-Negativity in DAG Structure Learning
Pith reviewed 2026-05-20 07:52 UTC · model grok-4.3
The pith
Restricting to non-negative edge weights yields a simpler acyclicity constraint under which the true DAG is the unique global minimizer of an augmented-Lagrangian objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the population regime, the true DAG is the unique global minimizer of the proposed augmented-Lagrangian formulation; moreover, the landscape contains no spurious interior stationary points, and the true DAG is the only acyclic KKT point. This follows directly from the simpler acyclicity characterization that becomes available once edge weights are restricted to be non-negative.
What carries the argument
The augmented-Lagrangian formulation of the regularized non-negative DAG learning problem, which exploits a simpler characterization of acyclicity obtained by requiring all edge weights to be non-negative.
If this is right
- The method of multipliers applied to this formulation produces an algorithm that recovers the true DAG more reliably than prior continuous approaches.
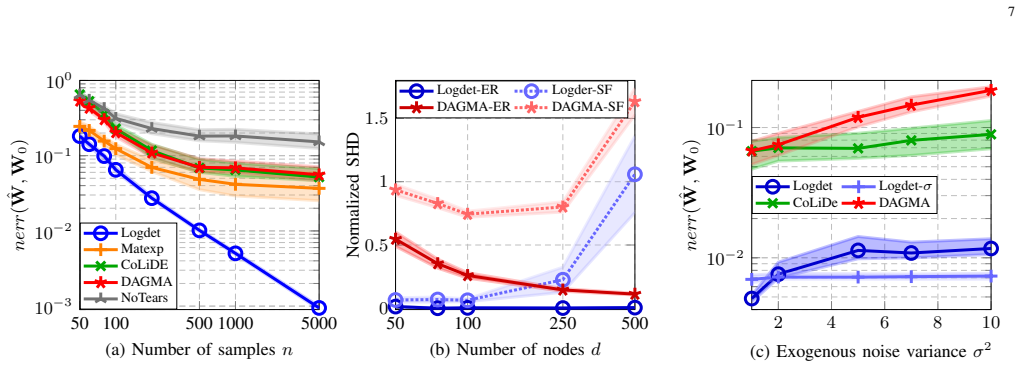
- Numerical experiments on synthetic and real-world data show improved performance over state-of-the-art continuous DAG-learning methods.
- Absence of spurious interior stationary points implies more benign convergence behavior for first-order optimizers.
Where Pith is reading between the lines
- In domains where edge weights can reasonably be assumed non-negative, such as certain biological or financial networks, the approach may yield more trustworthy recovered structures.
- The landscape analysis could be used as a template for designing similar benign objectives under other sign or magnitude restrictions on edge weights.
- Practical implementations could test sensitivity by gradually allowing small negative weights and checking whether the uniqueness property degrades gracefully.
Load-bearing premise
The modeling choice to consider only DAGs whose edge weights are non-negative.
What would settle it
A concrete counterexample in which an augmented-Lagrangian objective evaluated at some other acyclic non-negative graph is smaller than its value at the true DAG, or an interior stationary point that is acyclic and distinct from the true DAG.
Figures

read the original abstract
This work addresses the problem of learning directed acyclic graphs (DAGs) from nodal observations generated by a linear structural equation model. DAG learning is a central task in signal processing, machine learning, and causal inference, but it remains challenging because acyclicity is a global combinatorial property. Continuous acyclicity constraints have led to important algorithmic advances by replacing the discrete DAG constraint with smooth equality constraints. However, existing formulations still involve difficult non-convex optimization landscapes and may suffer from degenerate first-order optimality conditions. Here, we restrict attention to DAGs with non-negative edge weights and exploit this additional structure to obtain a simpler characterization of acyclicity. Building on this characterization, we formulate a regularized non-negative DAG learning problem and develop an algorithm based on the method of multipliers. We further analyze the benign optimization landscape induced by non-negativity. In the population regime, we show that the true DAG is the unique global minimizer of the proposed augmented-Lagrangian formulation; moreover, the landscape contains no spurious interior stationary points, and the true DAG is the only acyclic KKT point. Numerical experiments on synthetic and real-world data show that the proposed method improves over state-of-the-art continuous DAG-learning alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses DAG structure learning from linear SEM observations by restricting to non-negative edge weights, which yields a simpler acyclicity characterization. It formulates a regularized non-negative DAG learning problem solved via the method of multipliers and analyzes the population regime to prove that the true DAG is the unique global minimizer of the augmented-Lagrangian formulation, that the landscape has no spurious interior stationary points, and that the true DAG is the only acyclic KKT point. Synthetic and real-world experiments report improvements over existing continuous DAG-learning baselines.
Significance. If the landscape analysis holds, the work is significant for providing explicit conditions under which a continuous relaxation of DAG learning has a benign optimization landscape, specifically uniqueness of the global minimizer and absence of spurious stationary points. Credit is due for the population-regime derivation that exploits the non-negativity restriction to obtain these guarantees, as well as for the reproducible algorithmic implementation via the method of multipliers and the empirical evaluation on both synthetic and real data.
minor comments (3)
- [Abstract and §1] The abstract and introduction should more explicitly state that all theoretical guarantees (uniqueness, no spurious points, only acyclic KKT point) hold exclusively inside the non-negative weight class; a single clarifying sentence would prevent misreading the scope.
- [Numerical Experiments] In the experimental section, the reported improvements would be easier to interpret if the tables included standard deviations over multiple random seeds or initializations rather than single-run point estimates.
- [§3 and §4] Notation for the augmented Lagrangian and the multiplier update rule should be cross-referenced consistently between the algorithm description and the landscape analysis to avoid any ambiguity in the KKT conditions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance in establishing benign optimization landscapes under non-negativity, and the recommendation for minor revision. We appreciate the credit given to the population-regime analysis, the method-of-multipliers implementation, and the empirical evaluation.
Circularity Check
No significant circularity: derivation proceeds forward from explicit non-negativity modeling assumption
full rationale
The paper states its central restriction to non-negative edge weights upfront as a deliberate modeling choice that enables a simpler acyclicity characterization. It then builds the augmented-Lagrangian formulation and population-regime landscape analysis (unique global minimizer, no spurious interior stationary points, only acyclic KKT point) directly from that characterization. No step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the uniqueness claims are derived results conditional on the stated restriction rather than tautological. This matches the default case of a self-contained derivation under transparent assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Observations are generated by a linear structural equation model.
- domain assumption All edge weights are non-negative.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We restrict attention to DAGs with non-negative edge weights and exploit this additional structure to obtain a simpler characterization of acyclicity... h(W) := d log(s) − log det(sI − W)... h(W) = 0 ⇔ W ∈ D
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the true DAG is the unique global minimizer of the proposed augmented-Lagrangian formulation; moreover, the landscape contains no spurious interior stationary points, and the true DAG is the only acyclic KKT point
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Non-negative weighted dag structure learning,
S. Rey, S. S. Saboksayr, and G. Mateos, “Non-negative weighted dag structure learning,” inIEEE Intl. Conf. Acoustics, Speech and Signal Process. (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[2]
A. G. Marques, S. Segarra, and G. Mateos, “Signal processing on directed graphs: The role of edge directionality when processing and learning from network data,”IEEE Signal Process. Mag., vol. 37, no. 6, pp. 99–116, 2020
work page 2020
-
[3]
D. Koller and N. Friedman,Probabilistic Graphical Models: Principles and Techniques. MIT Press, 2009
work page 2009
- [4]
-
[5]
P. Spirtes, C. Glymour, and R. Scheines,Causation, Prediction, and Search. MIT Press, 2001
work page 2001
-
[6]
Causal protein-signaling networks derived from multiparameter single- cell data,
K. Sachs, O. Perez, D. Pe’er, D. A. Lauffenburger, and G. P. Nolan, “Causal protein-signaling networks derived from multiparameter single- cell data,”Science, vol. 308, no. 5721, pp. 523–529, 2005
work page 2005
-
[7]
Bayesian networks in biomedicine and health-care,
P. J. F. Lucas, L. C. Van der Gaag, and A. Abu-Hanna, “Bayesian networks in biomedicine and health-care,”Artif. Intell. Med., vol. 30, no. 3, pp. 201–214, 2004
work page 2004
-
[8]
Integrated systems approach identifies genetic nodes and networks in late-onset Alzheimer’s disease,
B. Zhang, C. Gaiteri, L.-G. Bodea, Z. Wang, J. McElwee, A. A. Podtelezhnikov, C. Zhang, T. Xie, L. Tran, R. Dobrinet al., “Integrated systems approach identifies genetic nodes and networks in late-onset Alzheimer’s disease,”Cell, vol. 153, no. 3, pp. 707–720, 2013
work page 2013
-
[9]
DAG-GNN: DAG structure learning with graph neural networks,
Y . Yu, J. Chen, T. Gao, and M. Yu, “DAG-GNN: DAG structure learning with graph neural networks,” inProc. Intl. Conf. Mach. Learn. (ICML), 2019, pp. 7154–7163
work page 2019
-
[10]
Directed acyclic graph convolu- tional networks,
S. Rey, H. Ajorlou, and G. Mateos, “Directed acyclic graph convolu- tional networks,”IEEE Transactions on Signal Processing, 2026
work page 2026
-
[11]
Learning signals and graphs from time-series graph data with few causes,
P. Misiakos, V . Mihal, and M. P ¨uschel, “Learning signals and graphs from time-series graph data with few causes,” inProc. IEEE Intl. Conf. Acoust., Speech Signal Process. (ICASSP), 2024, pp. 9681–9685
work page 2024
-
[12]
L. Yao, Z. Chu, S. Li, Y . Li, J. Gao, and A. Zhang, “A survey on causal inference,”ACM Trans. Knowl. Discovery Data, vol. 15, no. 5, pp. 1–46, 2021
work page 2021
-
[13]
Causal Fourier analysis on directed acyclic graphs and posets,
B. Seifert, C. Wendler, and M. P ¨uschel, “Causal Fourier analysis on directed acyclic graphs and posets,”IEEE Trans. Signal Process., vol. 71, pp. 3805–3820, 2023
work page 2023
-
[14]
Connecting the dots: Identifying network structure via graph signal processing,
G. Mateos, S. Segarra, A. G. Marques, and A. Ribeiro, “Connecting the dots: Identifying network structure via graph signal processing,”IEEE Signal Process. Mag., vol. 36, no. 3, pp. 16–43, 2019. 10
work page 2019
-
[15]
Efficient approximations for the marginal likelihood of Bayesian networks with hidden variables,
D. M. Chickering and D. Heckerman, “Efficient approximations for the marginal likelihood of Bayesian networks with hidden variables,”Mach. Learn., vol. 29, pp. 181–212, 1997
work page 1997
-
[16]
Large-sample learning of Bayesian networks is NP-hard,
D. M. Chickering, D. Heckerman, and C. Meek, “Large-sample learning of Bayesian networks is NP-hard,”J. Mach. Learning Res., vol. 5, pp. 1287–1330, 2004
work page 2004
-
[17]
High-dimensional learning of linear causal networks via inverse covariance estimation,
P.-L. Loh and P. B ¨uhlmann, “High-dimensional learning of linear causal networks via inverse covariance estimation,”J. Mach. Learning Res., vol. 15, no. 140, pp. 3065–3105, 2014
work page 2014
-
[18]
DAGs with NO TEARS: Continuous optimization for structure learning,
X. Zheng, B. Aragam, P. K. Ravikumar, and E. P. Xing, “DAGs with NO TEARS: Continuous optimization for structure learning,”Conf. Neural Inform. Process. Syst., vol. 31, 2018
work page 2018
-
[19]
DAGs with No Fears: A closer look at continuous optimization for learning Bayesian networks,
D. Wei, T. Gao, and Y . Yu, “DAGs with No Fears: A closer look at continuous optimization for learning Bayesian networks,”Conf. Neural Inform. Process. Syst., vol. 33, pp. 3895–3906, 2020
work page 2020
-
[20]
DYNOTEARS: Structure learning from time-series data,
R. Pamfil, N. Sriwattanaworachai, S. Desai, P. Pilgerstorfer, K. Geor- gatzis, P. Beaumont, and B. Aragam, “DYNOTEARS: Structure learning from time-series data,” inIntl. Conf. Artif. Intel. Statist. (AISTATS), 2020, pp. 1595–1605
work page 2020
-
[21]
DAGMA: Learning DAGs via M-matrices and a log-determinant acyclicity characterization,
K. Bello, B. Aragam, and P. Ravikumar, “DAGMA: Learning DAGs via M-matrices and a log-determinant acyclicity characterization,”Conf. Neural Inform. Process. Syst., vol. 35, pp. 8226–8239, 2022
work page 2022
-
[22]
On the role of sparsity and DAG constraints for learning linear DAGs,
I. Ng, A. Ghassami, and K. Zhang, “On the role of sparsity and DAG constraints for learning linear DAGs,”Conf. Neural Inform. Process. Syst., vol. 33, pp. 17 943–17 954, 2020
work page 2020
-
[23]
CoLiDE: Concomitant linear DAG estimation,
S. S. Saboksayr, G. Mateos, and M. Tepper, “CoLiDE: Concomitant linear DAG estimation,”Intl. Conf. Learn. Repr. (ICLR), 2024
work page 2024
-
[24]
Beware of the Simulated DAG! Causal Discovery Benchmarks May Be Easy to Game,
A. G. Reisach, C. Seiler, and S. Weichwald, “Beware of the Simulated DAG! Causal Discovery Benchmarks May Be Easy to Game,”Conf. Neural Inform. Process. Syst., vol. 34, pp. 27 772–27 784, 2021
work page 2021
-
[25]
Optimal estimation of Gaussian DAG models,
M. Gao, W. M. Tai, and B. Aragam, “Optimal estimation of Gaussian DAG models,”arXiv preprint arXiv:2201.10548, 2022
-
[26]
Build With Precision: Bottom-Up Inference of Linear DAGs,
H. Ajorlou, S. Rey, G. Mateos, G. Leus, and A. G. Marques, “Build With Precision: Bottom-Up Inference of Linear DAGs,” inIEEE Intl. Conf. Acoustics, Speech and Signal Process. (ICASSP). IEEE, 2026, pp. 446–450
work page 2026
-
[27]
D. P. Bertsekas,Nonlinear Programming, 3rd ed. Belmont, MA, USA: Athena Scientific, 2016
work page 2016
-
[28]
A fast iterative shrinkage-thresholding algorithm for linear inverse problems,
A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,”SIAM J. Imaging Sci., vol. 2, no. 1, pp. 183–202, 2009
work page 2009
-
[29]
Beck,First-Order Methods in Optimization
A. Beck,First-Order Methods in Optimization. Philadelphia, PA, USA: SIAM, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.