TrajTok: Adaptive Spatial Tokenization for Trajectory Representation Learning
Pith reviewed 2026-05-20 06:33 UTC · model grok-4.3
The pith
TrajTok turns noisy GPS traces into multi-resolution hexagonal tokens that let one frozen encoder support similarity search, classification, and travel-time tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
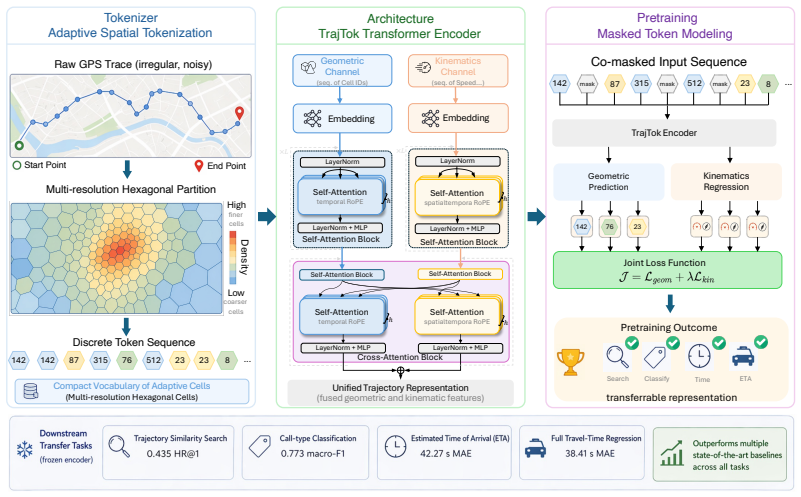
TrajTok shows that a learned multi-resolution hexagonal partition of space, paired with a factorized transformer using per-modality self-attention, cross-attention fusion, and ST-RoPE, plus masked-token pretraining, yields embeddings that remain effective when the encoder is frozen and reused across geometry-heavy and kinematics-heavy downstream tasks.
What carries the argument
The adaptive multi-resolution hexagonal cell partition learned from GPS point distribution, which discretizes trajectories into tokens for the factorized transformer with early modality-specific attention, cross-attention fusion, and ST-RoPE position embeddings.
If this is right
- A single pretrained trajectory encoder can be reused for both similarity-based retrieval and regression-style time prediction.
- Lightweight task adapters suffice once the encoder has learned general structure through masked pretraining.
- Hexagonal multi-resolution tokenization handles sparse cells and heterogeneous patterns better than fixed fine or coarse grids.
- Masked recovery of both geometry and kinematics during pretraining supports transfer without task-specific shortcuts.
Where Pith is reading between the lines
- The same tokenization approach could be tested on datasets with different sampling rates or urban densities to check geographic robustness.
- Adding explicit speed or heading features at the token level might further strengthen kinematics capture beyond what position and time already provide.
- Direct comparison against vector-quantized or learned grid alternatives would isolate whether the hexagonal multi-resolution choice is the main driver of transfer performance.
- Deployment in online settings such as live route planning would reveal whether the frozen encoder supports low-latency inference without retraining.
Load-bearing premise
Learning a multi-resolution hexagonal partition from the spatial distribution of GPS points will produce tokens that keep the geometric and movement information needed for multiple tasks without unacceptable loss from noise or irregular sampling.
What would settle it
A large performance gap appearing on one or more Porto tasks when the encoder is frozen, or clear failure to distinguish distinct movement patterns on a new city dataset, would show the tokenization does not preserve the required information.
Figures


read the original abstract
Learning generalizable trajectory representations from raw GPS traces remains difficult because the data is continuous, noisy, and irregularly sampled. Spatial tokenization is also challenging: fine grids yield sparse cells with weak embeddings, while coarse grids merge heterogeneous movement patterns into the same token. We present TrajTok, a trajectory encoder with a simple pretraining recipe for transferable trajectory embeddings. TrajTok first learns a multi-resolution hexagonal cell partition from the spatial distribution of GPS points, converting noisy GPS sequences into discrete cell tokens. To capture both geometry and kinematics, it uses a factorized transformer encoder with early per-modality self-attention blocks, cross-attention fusion layers, and spatiotemporal rotary position embeddings, ST-RoPE, to encode where and when each token occurs. TrajTok is pretrained with masked-token modeling that recovers both geometric structure and kinematic patterns from partial trajectory observations. On the Porto dataset, a frozen TrajTok encoder with lightweight task adapters achieves strong performance across trajectory similarity search, classification, estimated time of arrival, and full travel-time regression, outperforming multiple task-specific methods. The same frozen encoder supports both geometry-dominated and kinematics-dominated tasks, suggesting that TrajTok learns transferable trajectory structure rather than task-specific shortcuts. These results indicate that learned multi-resolution spatial tokenization combined with masked-token pretraining is a promising direction for general-purpose trajectory foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrajTok, a trajectory encoder that learns a multi-resolution hexagonal cell partition directly from the spatial distribution of GPS points to produce discrete tokens. These tokens are processed by a factorized transformer with early per-modality self-attention, cross-attention fusion, and spatiotemporal rotary position embeddings (ST-RoPE). The model is pretrained via masked-token modeling to recover both geometric structure and kinematic patterns. The central empirical claim is that a frozen TrajTok encoder, combined with lightweight task adapters, outperforms multiple task-specific methods on the Porto dataset across trajectory similarity search, classification, estimated time of arrival, and full travel-time regression, while supporting both geometry-dominated and kinematics-dominated tasks.
Significance. If the reported gains hold under rigorous controls, the work would represent a meaningful step toward general-purpose trajectory foundation models. Demonstrating that a single pretrained encoder can be reused across diverse downstream tasks without retraining the backbone would reduce the need for task-specific architectures in mobility and transportation applications. The combination of adaptive spatial tokenization with masked pretraining is a plausible direction, though its advantage over existing grid- or point-based methods requires clear quantification.
major comments (2)
- [§4] §4 (Experiments on Porto dataset): The headline claim that the frozen encoder supports kinematics-dominated tasks (e.g., travel-time regression) rests on the unverified assumption that the spatially-derived hexagonal partition preserves sufficient velocity and acceleration information. No quantitative diagnostic—such as mutual information between token sequences and velocity profiles, or per-cell kinematic variance—is reported to show that aggregation under irregular GPS sampling does not erase critical movement details.
- [§3.1] §3.1 (Tokenization): The multi-resolution hexagonal partition is learned solely from point density; the manuscript does not demonstrate that this choice avoids merging trajectories with dissimilar headings or speeds into the same token at coarser levels, which would undermine the transferability argument for kinematics-heavy tasks.
minor comments (2)
- [Abstract] The abstract asserts 'strong performance' and 'outperforming multiple task-specific methods' without numerical values, baseline names, or error bars; these details should appear in the main results table for immediate assessment.
- [§3.2] Notation for ST-RoPE and the factorized attention blocks should be defined with explicit equations in §3.2 to allow reproduction of the position encoding.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and have incorporated revisions to provide the requested quantitative support for our claims about kinematic preservation.
read point-by-point responses
-
Referee: [§4] §4 (Experiments on Porto dataset): The headline claim that the frozen encoder supports kinematics-dominated tasks (e.g., travel-time regression) rests on the unverified assumption that the spatially-derived hexagonal partition preserves sufficient velocity and acceleration information. No quantitative diagnostic—such as mutual information between token sequences and velocity profiles, or per-cell kinematic variance—is reported to show that aggregation under irregular GPS sampling does not erase critical movement details.
Authors: We agree that an explicit diagnostic would make the claim more robust. While the strong empirical results on travel-time regression and ETA tasks (which are kinematics-dominated) already indicate that velocity and acceleration signals are retained through the token sequences and ST-RoPE, we will add in the revised manuscript a quantitative analysis including per-cell kinematic variance and mutual information between token IDs and velocity/acceleration statistics derived from the underlying GPS points. This will directly verify that the adaptive hexagonal aggregation preserves sufficient movement detail under irregular sampling. revision: yes
-
Referee: [§3.1] §3.1 (Tokenization): The multi-resolution hexagonal partition is learned solely from point density; the manuscript does not demonstrate that this choice avoids merging trajectories with dissimilar headings or speeds into the same token at coarser levels, which would undermine the transferability argument for kinematics-heavy tasks.
Authors: The density-driven multi-resolution design primarily addresses sparsity at fine scales and over-merging at coarse scales. The masked pretraining objective further encourages the model to recover kinematic patterns from context, supporting transfer to kinematics-heavy tasks. To strengthen this, we will include in the revision additional visualizations and metrics (e.g., intra-token variance of headings and speeds across resolutions) demonstrating that coarser tokens maintain acceptable homogeneity in movement characteristics rather than indiscriminately merging dissimilar trajectories. revision: yes
Circularity Check
TrajTok's tokenization and pretraining pipeline shows no circular reductions
full rationale
The derivation begins with learning a multi-resolution hexagonal partition from the empirical spatial distribution of GPS points, converts sequences to discrete tokens, applies a factorized transformer with ST-RoPE, and pretrains via standard masked-token modeling. Downstream results on Porto use frozen encoder plus separate lightweight adapters for similarity search, classification, ETA, and travel-time regression; these are independent held-out tasks rather than re-derivations of the pretraining loss or partition objective. No equations or claims reduce a prediction to a fitted input by construction, and the abstract contains no self-citations or uniqueness theorems invoked to force the architecture. The chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-resolution levels
axioms (1)
- domain assumption Hexagonal cells provide a suitable discrete representation for continuous GPS trajectories.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We build the token vocabulary with the hierarchical H3 hexagonal grid... Cells whose counts exceed a capacity threshold are split into their children... allocating finer cells to dense regions while preserving a compact vocabulary.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
factorized transformer encoder with early per-modality self-attention blocks, cross-attention fusion layers, and spatiotemporal rotary position embeddings, ST-RoPE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mobility network models of covid-19 explain inequities and inform reopening
Serina Chang, Emma Pierson, Pang Wei Koh, Jaline Gerardin, Beth Redbird, David Grusky, and Jure Leskovec. Mobility network models of covid-19 explain inequities and inform reopening. Nature, 589(7840):82–87, 2021
work page 2021
-
[2]
Contrastive trajectory similarity learning with dual-feature attention
Yanchuan Chang, Jianzhong Qi, Yuxuan Liang, and Egemen Tanin. Contrastive trajectory similarity learning with dual-feature attention. InProceedings of the 39th IEEE International Conference on Data Engineering (ICDE). IEEE, 2023. doi: 10.1109/ICDE55515.2023.00119
-
[3]
Nexus: Same Pretraining Loss, Better Downstream Generalization via Common Minima
Huanran Chen, Huaqing Zhang, Xiao Li, Yinpeng Dong, Ke Shen, and Jun Zhu. Nexus: Same pretraining loss, better downstream generalization via common minima, 2026. URL https://arxiv.org/abs/2604.09258. Direct support: the paper reports significantly better downstream performance despite achieving the same pretraining loss, challenging reliance on pretrainin...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
KGTS: Contrastive trajectory similarity learning over prompt knowledge graph embedding
Zhen Chen, Dalin Zhang, Shanshan Feng, Kaixuan Chen, Lisi Chen, Peng Han, and Shuo Shang. KGTS: Contrastive trajectory similarity learning over prompt knowledge graph embedding. In Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI). AAAI Press, 2024. doi: 10.1609/aaai.v38i8.28672
-
[5]
Efficient trajectory similarity computation with contrastive learning
Liwei Deng, Yan Zhao, Zidan Wang, Hao Fan, and Kai Zheng. Efficient trajectory similarity computation with contrastive learning. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM), pages 229–239. ACM, 2022. doi: 10.1145/ 3511808.3557308
-
[6]
Yanyan Fan, Ye Yuan, Guoliang Lv, Hao Chen, Jian Li, and Feifei Liu. MetaER-TTE: An adaptive meta-learning model for en route travel time estimation. InProceedings of the Thirty- First International Joint Conference on Artificial Intelligence, pages 1806–1812, 2022. doi: 10.24963/ijcai.2022/251
-
[7]
Xiaomin Fang, Jizhou Huang, Fan Wang, Lingke Zeng, Haijin Liang, and Haifeng Wang. ConSTGAT: Contextual spatial-temporal graph attention network for travel time estimation at baidu maps. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2697–2705, 2020. doi: 10.1145/3394486.3403316
-
[8]
SSML: Self-supervised meta-learner for en route travel time estimation at baidu maps
Xiaomin Fang, Jizhou Huang, Fan Wang, Lihang Liu, Yibo Sun, and Haifeng Wang. SSML: Self-supervised meta-learner for en route travel time estimation at baidu maps. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2840–2848, 2021. doi: 10.1145/3447548.3467109
-
[9]
Model-agnostic meta-learning for fast adap- tation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adap- tation of deep networks. InProceedings of the 34th International Conference on Machine Learning, pages 1126–1135, 2017
work page 2017
-
[10]
Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks
Kun Fu, Fanlin Meng, Jieping Ye, and Zheng Wang. CompactETA: A fast inference system for travel time prediction. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 3337–3345, 2020. doi: 10.1145/3394486. 3403387
-
[11]
Self- supervised trajectory representation learning with temporal regularities and travel semantics
Jiawei Jiang, Dayan Pan, Houxing Ren, Xiaohan Jiang, Chao Li, and Jingyuan Wang. Self- supervised trajectory representation learning with temporal regularities and travel semantics. In 2023 IEEE 39th international conference on data engineering (ICDE), pages 843–855. IEEE, 2023
work page 2023
-
[12]
Satclip: Global, general-purpose location embeddings with satellite imagery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. Satclip: Global, general-purpose location embeddings with satellite imagery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4347–4355, 2025. 10
work page 2025
-
[13]
Xiucheng Li, Kaiqi Zhao, Gao Cong, Christian S. Jensen, and Wei Wei. Deep representation learning for trajectory similarity computation. InProceedings of the 34th IEEE International Conference on Data Engineering (ICDE), pages 617–628. IEEE, 2018
work page 2018
-
[14]
Yan Lin, Huaiyu Wan, Shengnan Guo, Jilin Hu, Christian S. Jensen, and Youfang Lin. Pre- training general trajectory embeddings with maximum multi-view entropy coding.IEEE Transactions on Knowledge and Data Engineering, 2023. doi: 10.48550/arXiv.2207.14539
-
[15]
Hao Long, Silin Zhou, Lisi Chen, and Shuo Shang. Region-point joint representation for effective trajectory similarity learning.Proceedings of the AAAI Conference on Artificial Intelligence, 40(18):15439–15447, Mar. 2026. doi: 10.1609/aaai.v40i18.38571. URL https: //ojs.aaai.org/index.php/AAAI/article/view/38571
-
[16]
More than routing: Joint gps and route modeling for refine trajectory representation learning
Zhipeng Ma, Zheyan Tu, Xinhai Chen, Yan Zhang, Deguo Xia, Guyue Zhou, Yilun Chen, Yu Zheng, and Jiangtao Gong. More than routing: Joint gps and route modeling for refine trajectory representation learning. InProceedings of the ACM Web Conference 2024, pages 3064–3075, 2024
work page 2024
-
[17]
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. Multi- scale representation learning for spatial feature distributions using grid cells.arXiv preprint arXiv:2003.00824, 2020
-
[18]
Multi-scale representation learning for spatial feature distributions using grid cells
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. Multi-scale representation learning for spatial feature distributions using grid cells. In8th International Conference on Learning Representations, ICLR 2020, 2020
work page 2020
-
[19]
Towards a foundation model for trajectory intelligence
Alameen Najjar. Towards a foundation model for trajectory intelligence. In2023 IEEE International Conference on Data Mining Workshops (ICDMW), pages 832–835. IEEE, 2023
work page 2023
-
[20]
Stefan Schestakov and Simon Gottschalk. Trajectory representation learning on road networks and grids with spatio-temporal dynamics.arXiv preprint arXiv:2411.14014, 2024
-
[21]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[22]
H3: A Hexagonal Hierarchical Geospatial Indexing System (version 4)
Uber Technologies. H3: A Hexagonal Hierarchical Geospatial Indexing System (version 4). https://h3geo.org/, 2022. Accessed: April 22, 2026
work page 2022
-
[23]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[24]
When will you arrive? estimating travel time based on deep neural networks
Dong Wang, Junbo Zhang, Wei Cao, Jian Li, and Yu Zheng. When will you arrive? estimating travel time based on deep neural networks. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pages 2500–2507, 2018
work page 2018
-
[25]
Large-scale order dispatch in on-demand ride-hailing platforms: A learning and planning approach
Zhe Xu, Zhixin Li, Qingwen Guan, Dingshui Zhang, Qiang Li, Junxiao Nan, Chunyang Liu, Wei Bian, and Jieping Ye. Large-scale order dispatch in on-demand ride-hailing platforms: A learning and planning approach. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 905–913, 2018
work page 2018
-
[26]
Huang, Shawn Yue, and Ge Zhang
Chen Yang, Junzhuo Li, Xinyao Niu, Xinrun Du, Songyang Gao, Haoran Zhang, Zhaoliang Chen, Xingwei Qu, Ruibin Yuan, Yizhi Li, Jiaheng Liu, Stephen W. Huang, Shawn Yue, and Ge Zhang. The fine line: Navigating large language model pretraining with down-streaming capability analysis, 2024. URL https://arxiv.org/abs/2404.01204. Direct support: the abstract exp...
-
[27]
Chuang Yang, Renhe Jiang, Xiaohang Xu, Chuan Xiao, and Kaoru Sezaki. SIMformer: Single- layer vanilla transformer can learn free-space trajectory similarity.Proceedings of the VLDB Endowment, 2025. doi: 10.14778/3705829.3705853. 11
-
[28]
Sean Bin Yang, Chenjuan Guo, Jilin Hu, Jian Tang, and Bin Yang. Unsupervised path rep- resentation learning with curriculum negative sampling.arXiv preprint arXiv:2106.09373, 2021
-
[29]
Learning deep representation for trajectory clustering.Expert Systems, 35(2):e12252, 2018
Di Yao, Chao Zhang, Zhihua Zhu, Qin Hu, Zheng Wang, Jianhui Huang, and Jingping Bi. Learning deep representation for trajectory clustering.Expert Systems, 35(2):e12252, 2018. doi: https://doi.org/10.1111/exsy.12252. URL https://onlinelibrary.wiley.com/doi/abs/ 10.1111/exsy.12252. e12252 10.1111/exsy.12252
-
[30]
Di Yao, Chao Zhang, Zhihua Zhu, Jianhui Hu, and Jingping Bi. Computing trajectory similarity in linear time: A generic seed-guided neural metric learning approach. InProceedings of the 35th IEEE International Conference on Data Engineering (ICDE), pages 1358–1369. IEEE,
-
[31]
doi: 10.1109/ICDE.2019.00123
-
[32]
TrajGAT: A graph-based long-term dependency modeling approach for trajectory similarity computation
Di Yao, Haonan Hu, Lun Du, Gao Cong, Shi Han, and Jingping Bi. TrajGAT: A graph-based long-term dependency modeling approach for trajectory similarity computation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pages 2275–2285. ACM, 2022. doi: 10.1145/3534678.3539358
-
[33]
Yu Zheng, Licia Capra, Ouri Wolfson, and Hai Yang. Urban computing: concepts, methodolo- gies, and applications.ACM Transactions on Intelligent Systems and Technology (TIST), 5(3): 1–55, 2014
work page 2014
-
[34]
Unitraj: Learning a universal trajectory foundation model from billion-scale worldwide traces
Yuanshao Zhu, James Jianqiao Yu, Xiangyu Zhao, Xun Zhou, Liang Han, Xuetao Wei, and Yuxuan Liang. Unitraj: Learning a universal trajectory foundation model from billion-scale worldwide traces. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. A Algorithm: Density-Adaptive Vocabulary Construction Algorithm 1Density-Adapti...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.