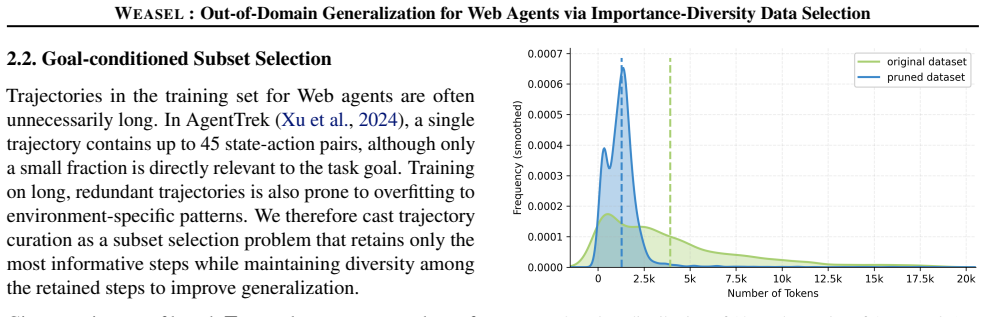
Weasel: Out-of-Domain Generalization for Web Agents via Importance-Diversity Data Selection
Pith reviewed 2026-05-21 08:04 UTC · model grok-4.3
The pith
Selecting important and diverse trajectories lets web agents generalize out of domain while cutting training costs by an order of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a greedy optimization of an objective combining unary importance scores with pairwise diversity measures across states, websites, and interaction patterns can identify a compact set of trajectories that, when used for fine-tuning, yields superior out-of-domain performance on web agent benchmarks compared to using the entire dataset, while delivering training speedups of approximately 9.7 to 12.5 times.
What carries the argument
The importance-diversity objective solved greedily to select trajectory steps, combined with target-centered AXTree pruning and model-generated rationales.
If this is right
- Out-of-domain success rates increase on WebArena, WorkArena, and MiniWob when training with the selected data.
- Training time is reduced by factors of 9.7 to 12.5 across Qwen2.5-7B, Gemma3-4B, and Qwen3-8B models.
- The method applies to both AgentTrek and NNetNav training datasets.
- Style-consistent rationales help reasoning-native models adapt better.
Where Pith is reading between the lines
- Similar selection criteria could improve efficiency in training agents for other environments like mobile apps or games.
- The focus on diversity over interaction patterns may help address long-tail behaviors in agent tasks.
- Reducing data volume this way might lower the barrier to iterating on web agent designs.
Load-bearing premise
A greedy solution to balancing importance and diversity will reliably choose trajectories from which the model learns generalizable behaviors for unseen websites and tasks.
What would settle it
If experiments on held-out websites show that models fine-tuned on Weasel-selected trajectories achieve lower task success rates than those trained on the full dataset or on randomly sampled trajectories of equal size.
Figures




read the original abstract
Large language models (LLMs) have enabled web agents that follow natural language goals through multi-step browser interactions. However, agents fine-tuned on specific trajectories and domain often struggle to generalize out of domain, and offline training can be compute-inefficient due to noisy, redundant trajectories and long accessibility-tree (AXTree) states. To address both issues, we propose Weasel, a trajectory selection method for offline training of web agents. Weasel selects a fixed-budget subset of trajectory steps by optimizing an objective that balances unary importance with pairwise diversity over states, websites, and interaction patterns, solving efficiently with a greedy algorithm. We further improve efficiency with target-centered AXTree pruning that keeps only content around the ground-truth action target, and we mitigate style mismatch for reasoning-native models by replacing expert traces with model-generated, style-consistent rationales. Across AgentTrek and NNetNav training datasets, evaluations in WebArena, WorkArena, and MiniWob, and experiments with Qwen2.5-7B, Gemma3-4B, and Qwen3-8B, Weasel improves out-of-domain performance while reducing training cost, producing roughly 9.7-12.5$\times$ training speedups over standard fine-tuning. We make the code available at https://github.com/fatemehpesaran310/weasel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Weasel, a trajectory selection method for offline training of web agents. It selects a fixed-budget subset of trajectory steps by optimizing an objective that balances unary importance with pairwise diversity over states, websites, and interaction patterns, solved via a greedy algorithm. Additional components include target-centered AXTree pruning and replacement of expert traces with model-generated rationales for style consistency. Experiments on AgentTrek and NNetNav training data, evaluated on WebArena, WorkArena, and MiniWob with Qwen2.5-7B, Gemma3-4B, and Qwen3-8B models, report improved out-of-domain performance together with 9.7-12.5× training speedups relative to standard fine-tuning. Code is released at the cited GitHub repository.
Significance. If the reported gains prove robust, the approach could meaningfully advance efficient offline training of generalizable web agents by addressing redundancy and noise in trajectory data. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] Abstract: the reported OOD gains and speedups are presented without error bars, exact baseline implementation details, or an ablation isolating the diversity term from AXTree pruning and rationale replacement; these omissions are load-bearing because they prevent determining whether the central selection procedure, rather than the auxiliary efficiency steps, drives the claimed improvements.
- [Method (objective and greedy algorithm)] Method section describing the objective and greedy algorithm: the claim that optimizing unary importance plus pairwise diversity over states/websites/patterns produces trajectories whose induced policies transfer to unseen websites and tasks rests on the untested assumption that the diversity term captures cross-domain interaction patterns rather than merely reducing in-domain redundancy. Without targeted ablations (e.g., diversity term removed, random selection baseline, or correlation analysis between marginal gains and OOD robustness), the observed gains on WebArena/WorkArena/MiniWob could be explained by the other modifications instead.
minor comments (1)
- The abstract states a selection budget but does not report its concrete value or sensitivity analysis; adding this would improve clarity without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported OOD gains and speedups are presented without error bars, exact baseline implementation details, or an ablation isolating the diversity term from AXTree pruning and rationale replacement; these omissions are load-bearing because they prevent determining whether the central selection procedure, rather than the auxiliary efficiency steps, drives the claimed improvements.
Authors: We agree that error bars, precise baseline details, and an isolating ablation are necessary to attribute gains clearly. In the revised manuscript we will add error bars to all reported OOD and speedup results, expand the experimental section with exact baseline implementation details (including training hyperparameters, data preprocessing, and model versions), and insert a dedicated ablation that holds AXTree pruning and rationale replacement fixed while varying only the selection objective (full importance-diversity vs. importance-only vs. random). These changes will isolate the contribution of the core selection procedure. revision: yes
-
Referee: [Method (objective and greedy algorithm)] Method section describing the objective and greedy algorithm: the claim that optimizing unary importance plus pairwise diversity over states/websites/patterns produces trajectories whose induced policies transfer to unseen websites and tasks rests on the untested assumption that the diversity term captures cross-domain interaction patterns rather than merely reducing in-domain redundancy. Without targeted ablations (e.g., diversity term removed, random selection baseline, or correlation analysis between marginal gains and OOD robustness), the observed gains on WebArena/WorkArena/MiniWob could be explained by the other modifications instead.
Authors: We acknowledge that the current manuscript does not contain an explicit ablation removing the diversity term or a correlation analysis linking diversity metrics to OOD gains. To address this directly, the revision will add (i) an ablation that removes the pairwise diversity component while retaining importance scoring, AXTree pruning, and rationale replacement, (ii) a random-selection baseline matched for budget, and (iii) a supplementary analysis correlating per-trajectory diversity scores with observed OOD performance deltas across the three evaluation suites. While we continue to hold that the multi-aspect diversity objective (states, websites, interaction patterns) is motivated by the goal of broader coverage, the requested ablations will provide the empirical evidence needed to substantiate its role in OOD transfer. revision: yes
Circularity Check
Empirical selection procedure with no definitional circularity
full rationale
The paper describes Weasel as a practical trajectory selection algorithm that optimizes a unary-importance-plus-pairwise-diversity objective via a stated greedy procedure, followed by AXTree pruning and rationale replacement. Reported OOD gains and 9.7-12.5× speedups are obtained from direct experimental comparisons on AgentTrek, NNetNav, WebArena, WorkArena, and MiniWob with multiple base models; these outcomes are not algebraically forced by any fitted parameter, self-referential normalization, or uniqueness theorem internal to the paper. The method is self-contained against external benchmarks and contains no load-bearing self-citations or ansatzes that reduce the central claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- selection budget
axioms (1)
- domain assumption Greedy algorithm yields a good approximation to the joint importance-diversity objective
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate a fixed-budget subset selection problem with a quadratic objective that balances unary importance with pairwise diversity over states, websites, and interaction patterns, solving efficiently with a greedy algorithm.
-
IndisputableMonolith/Foundation/BranchSelection.leanRCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
D(i, j) = max(δ(si, sj), δ(yi, yj)) with δ = 1 − BERTScore
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.