Finite-Time Regret Analysis of Retry-Aware Bandits
Pith reviewed 2026-05-21 05:57 UTC · model grok-4.3
The pith
ReMax achieves the first sublinear regret bound for Gaussian rewards and two attempts by using an expected-improvement balance condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
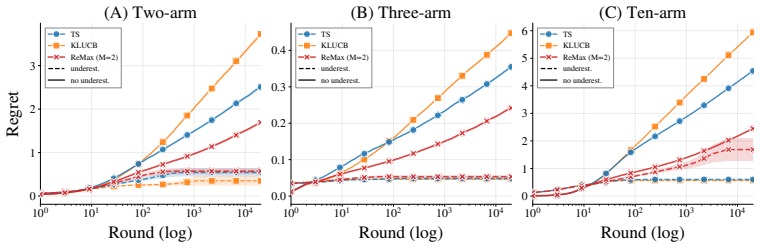
For Gaussian rewards and M=2, the optimal ReMax distribution is characterized by an expected-improvement balance condition. This characterization separates the saturation behavior of suboptimal arms from the ReMax-specific underestimation effect, where the optimal arm may be sampled too rarely after an unfavorable estimate, and thereby yields the first sublinear regret bound for ReMax.
What carries the argument
Expected-improvement balance condition that determines the optimal sampling distribution for ReMax when M=2 by balancing the expected improvements obtained from sampling different arms under the maximum-reward objective.
If this is right
- ReMax can be more exploitative than Thompson sampling because of the underestimation effect on the optimal arm.
- The regret analysis must separate usual saturation of suboptimal arms from the ReMax-specific underestimation effect.
- ReMax often outperforms KL-UCB and Thompson sampling under mild underestimation.
- Posterior-variance scaling empirically mitigates severe underestimation.
Where Pith is reading between the lines
- The same separation of saturation and underestimation might be useful for analyzing retry-aware objectives with non-Gaussian rewards.
- Generalizing the expected-improvement balance condition could produce regret bounds for M greater than 2.
- Retry-aware sampling may produce qualitatively different exploration rates in sequential problems beyond standard bandits.
Load-bearing premise
The proof assumes Gaussian reward distributions and is limited to the case of two attempts.
What would settle it
A long-horizon simulation with two Gaussian arms in which ReMax cumulative regret grows linearly with time rather than sublinearly would contradict the claimed bound.
Figures







read the original abstract
We study a stochastic bandit algorithm motivated by retry-aware objectives that value the best outcome among multiple attempts, such as pass@$k$ and max@$k$. Given a posterior over arm values, ReMax chooses a sampling distribution that maximizes the posterior expected maximum reward over $M$ virtual draws. Although this objective was introduced in reinforcement learning as an exploration mechanism under uncertainty, its regret properties in bandit problems have remained unclear. For Gaussian rewards and the first nontrivial case $M=2$, we characterize the optimal ReMax distribution through an expected-improvement balance condition and prove the first sublinear regret bound for ReMax. Our analysis separates the usual saturation behavior of suboptimal arms from a ReMax-specific underestimation effect, in which the optimal arm may be sampled too rarely after an unfavorable estimate. This explains why ReMax can be more exploitative than Thompson sampling (TS) and why its regret analysis is technically delicate. Experiments support this picture: ReMax often outperforms KL-UCB and Thompson sampling under mild underestimation, while posterior-variance scaling empirically mitigates severe underestimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies ReMax, a stochastic multi-armed bandit algorithm motivated by retry-aware objectives (e.g., pass@k or max@k) that selects a sampling distribution maximizing the posterior expected maximum reward over M virtual draws. For Gaussian rewards restricted to the first nontrivial case M=2, the authors characterize the optimal ReMax distribution via an expected-improvement balance condition, prove a finite-time sublinear regret bound, and separate the standard saturation of suboptimal arms from a ReMax-specific underestimation effect on the optimal arm. This explains ReMax's more exploitative behavior relative to Thompson sampling. Experiments show ReMax often outperforming KL-UCB and Thompson sampling under mild underestimation, with posterior-variance scaling mitigating severe cases.
Significance. If the sublinear regret bound holds, the work supplies the first rigorous finite-time analysis of ReMax in the bandit setting and introduces a technically delicate separation argument that isolates the underestimation phenomenon. The expected-improvement balance condition and the explicit comparison to Thompson sampling provide conceptual clarity for retry-aware exploration mechanisms, with direct relevance to both bandit theory and reinforcement-learning objectives that value maxima over multiple attempts. The empirical observation on variance scaling offers a practical takeaway.
major comments (1)
- [Regret analysis section (around the statement of the main theorem)] The central sublinear regret claim for Gaussian M=2 rests on characterizing the optimal distribution through the expected-improvement balance condition and then bounding the underestimation effect separately from saturation. The manuscript should state the main regret theorem (including the precise dependence on T and any problem-dependent constants) in a single location so that sublinearity can be verified without reconstructing the argument from the balance condition alone.
minor comments (2)
- The abstract refers to 'posterior-variance scaling' as an empirical fix for severe underestimation; a short paragraph or pointer to the relevant experimental subsection would help readers locate the implementation detail.
- Notation for the ReMax sampling distribution and the virtual draws could be introduced with a small display equation early in the preliminaries to reduce ambiguity when the balance condition is later defined.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Regret analysis section (around the statement of the main theorem)] The central sublinear regret claim for Gaussian M=2 rests on characterizing the optimal distribution through the expected-improvement balance condition and then bounding the underestimation effect separately from saturation. The manuscript should state the main regret theorem (including the precise dependence on T and any problem-dependent constants) in a single location so that sublinearity can be verified without reconstructing the argument from the balance condition alone.
Authors: We agree that an explicit, self-contained statement of the main regret theorem will improve readability. In the revised manuscript we will add a dedicated theorem in the regret analysis section that states the precise finite-time bound, including its dependence on the horizon T and all relevant problem-dependent constants. This will allow direct verification of sublinearity without requiring the reader to reconstruct the argument from the expected-improvement balance condition. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives the optimal ReMax sampling distribution for the Gaussian M=2 case directly from the posterior expected-maximum objective via an expected-improvement balance condition. It then establishes a finite-time sublinear regret bound by separating standard saturation of suboptimal arms from the ReMax-specific underestimation effect on the optimal arm. Neither step reduces to a fitted input renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain; the balance condition follows from the stated objective without presupposing the regret result, and the bound is externally falsifiable. The analysis is restricted to the first nontrivial case with explicit assumptions, keeping the central claim independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward distributions are Gaussian
Reference graph
Works this paper leans on
-
[1]
Further optimal regret bounds for thompson sampling
Shipra Agrawal and Navin Goyal. Further optimal regret bounds for thompson sampling. In Proceedings of the Sixteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2013, Scottsdale, AZ, USA, April 29 - May 1, 2013, JMLR Workshop and Conference Proceedings, pages 99–107. JMLR.org,
work page 2013
-
[2]
ISSN 0885-6125. doi: 10.1023/A: 1013689704352. URLhttp://dx.doi.org/10.1023/A:1013689704352. Jie Bian and Kwang-Sung Jun. Maillard sampling: Boltzmann exploration done optimally. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors,International Conference on Artificial Intelligence and Statistics, AISTATS 2022, 28-30 March 2022, Virtua...
work page doi:10.1023/a: 2022
-
[3]
URL http://github.com/jax-ml/jax. Eric Brochu, Vlad M. Cora, and Nandode Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. eprint arXiv:1012.2599, arXiv.org, December
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https: //doi.org/10.1287/moor.22.1.222
doi: 10.1287/MOOR.22.1.222. URL https: //doi.org/10.1287/moor.22.1.222. Olivier Cappé, Aurélien Garivier, Odalric-Ambrym Maillard, Rémi Munos, and Gilles Stoltz. Kull- back–leibler upper confidence bounds for optimal sequential allocation.The Annals of Statistics, 41(3):1516–1541, 06
-
[5]
URL http://dx.doi.org/10.1214/ 13-AOS1119
doi: 10.1214/13-AOS1119. URL http://dx.doi.org/10.1214/ 13-AOS1119. Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sampling.Advances in neural information processing systems, 24,
-
[6]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models. arXiv preprint arXiv:2508.10751,
-
[7]
An asymptotically optimal bandit algorithm for bounded support models
Junya Honda and Akimichi Takemura. An asymptotically optimal bandit algorithm for bounded support models. In Adam Tauman Kalai and Mehryar Mohri, editors,COLT 2010 - The 23rd Conference on Learning Theory, Haifa, Israel, June 27-29, 2010, pages 67–79. Omnipress,
work page 2010
-
[8]
Junya Honda and Akimichi Takemura
URL http://colt2010.haifa.il.ibm.com/papers/COLT2010proceedings.pdf# page=75. Junya Honda and Akimichi Takemura. Optimality of thompson sampling for gaussian bandits depends on priors. InProceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, AISTATS 2014, Reykjavik, Iceland, April 22-25, 2014, JMLR Workshop and ...
work page 2014
-
[9]
Emilie Kaufmann, Nathaniel Korda, and Rémi Munos
URL http://proceedings.mlr.press/v33/ honda14.html. Emilie Kaufmann, Nathaniel Korda, and Rémi Munos. Thompson sampling: An asymptotically optimal finite-time analysis. In Nader H. Bshouty, Gilles Stoltz, Nicolas Vayatis, and Thomas Zeugmann, editors,Algorithmic Learning Theory - 23rd International Conference, ALT 2012, Lyon, France, October 29-31,
work page 2012
-
[10]
Adam: A Method for Stochastic Optimization
doi: 10.1007/978-3-642-34106-9\_18. URL https://doi.org/10. 1007/978-3-642-34106-9_18. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-642-34106-9
-
[11]
Rate-optimal Design for Anytime Best Arm Identification
PMLR. URLhttps://proceedings.mlr.press/v37/komiyama15.html. Junpei Komiyama, Kyoungseok Jang, and Junya Honda. Rate-optimal design for anytime best arm identification.arXiv preprint arXiv:2510.23199,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
ISSN 0030-364X. doi: 10.1287/opre.2016.1494. URL https: //doi.org/10.1287/opre.2016.1494. Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. Open bandit dataset and pipeline: Towards realistic and reproducible off-policy evaluation.arXiv preprint arXiv:2008.07146,
-
[13]
Yunhao Tang, Kunhao Zheng, Gabriel Synnaeve, and Rémi Munos. Optimizing language models for inference time objectives using reinforcement learning.arXiv preprint arXiv:2503.19595,
-
[14]
Christian Walder and Deep Karkhanis. Pass@ k policy optimization: Solving harder reinforcement learning problems.arXiv preprint arXiv:2505.15201,
-
[15]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Let ϕ and Φ denote the PDF and CDF of N(0,1) , and let δ:=µ 1 −ε−ˆµ1,n >0 . Then E= 1 4 Eθ1∼N(ˆµ1,n,1/n) [max (0, θ1 −(µ 1 −ε))](34) = 1 4√n ϕ(δ√n)−δ √nΦ c(δ√n) (35) ≥ 1 4√n 1 3 +δ 2n ϕ(δ√n)(byΦ c(x)≤ 1 x · 2+x2 3+x2 ·ϕ(x)[Mukherjee, 2016]) = 1 4 √ 2πn 1 3 +δ 2n exp (−nD(µ1 −ε∥ˆµ1,n)).(36) Lemma 1 shows that even when the optimal arm is underestimated, it...
work page 2016
-
[17]
Require:Observation noiseσ η, horizonT 1:Init pulls:fori= 1,
Algorithm 1Exact ReMax with negative fixing (M= 2, Gaussian posterior, improper-prior init). Require:Observation noiseσ η, horizonT 1:Init pulls:fori= 1, . . . , K, pull armi, observer i ∼ N(µ i, σ2 η), setˆµi ←r i,σ 2 i ←σ 2 η 2:fort=K+ 1, . . . , Tdo 3: Compute the pairwise matrix Gij from Equation (195) using s2 ij =σ 2 i +σ 2 j , with Gii ←ˆµi 4:Initi...
work page 2025
-
[18]
The Gaussian-bandit mean used at run time is obtained by aggregating 103 impressions per pull and normalizing by the across-arm average click-outcome standard deviation ¯σclick = 0.057774753125 , giving µOBD i = CTR i √ 103/¯σclick (Section 5.2); the table itself reports the raw CTRs so that the source data are auditable independently of this 31 transform...
-
[19]
We parameterize the policy by softmax logits z∈R K, π(z) = softmax(z) , and use the sampled- mean estimator bJM of the previous display. The gradient with respect to the logits is the simplex- projected push-forward of the policy gradient: ∇zbJM(π(z)) =π(z)⊙ g− ⟨g, π(z)⟩ , g=∇ πbJM(π),(199) where⟨·,·⟩denotes the inner product over arms and⊙is elementwise....
work page 2014
-
[20]
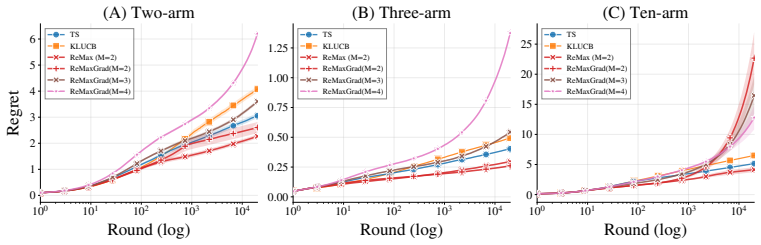
We swept the variance inflation scale over c2 ={2,3,4} and compared it with standard ReMax, TS, and KL-UCB. For the number of rounds and statistics, we used the same setting as in the main synthetic bandit experiments. Figure 10 shows the results. As expected, canonical ReMax suffers from larger underestimation than the baselines, which is the main contri...
work page 2018
-
[21]
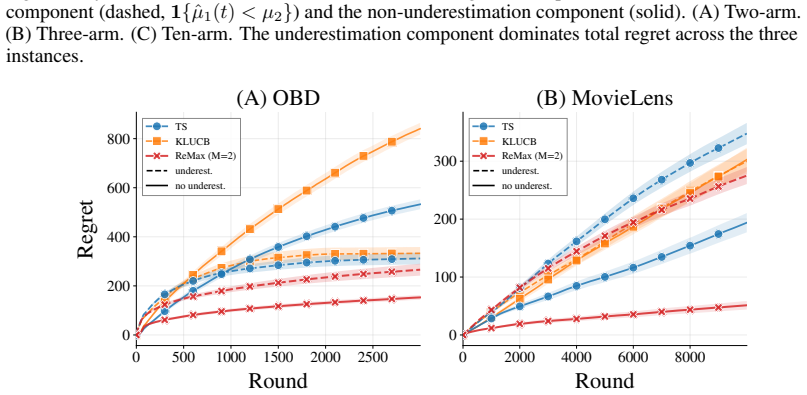
We cite it as the direct source of the numerical arm means used in our experiments
is available under a CC BY 4.0 license. We cite it as the direct source of the numerical arm means used in our experiments. For provenance, we also cite the original Open Bandit Dataset paper [Saito et al., 2020] and the MovieLens dataset paper [Harper and Konstan, 2015]. The original OBD is a public logged bandit dataset released by ZOZO Research, and th...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.