Reviving Error Correction in Modern Deep Time-Series Forecasting
Pith reviewed 2026-05-21 05:21 UTC · model grok-4.3
The pith
Decomposing predictions into trend and seasonal parts lets a separate corrector reduce autoregressive error buildup in deep time-series models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a universal error corrector on the seasonal-trend decomposition of a base forecaster's outputs, the accumulated errors that arise during autoregressive inference can be reduced effectively, yielding better long-term predictions without any modification to the original model.
What carries the argument
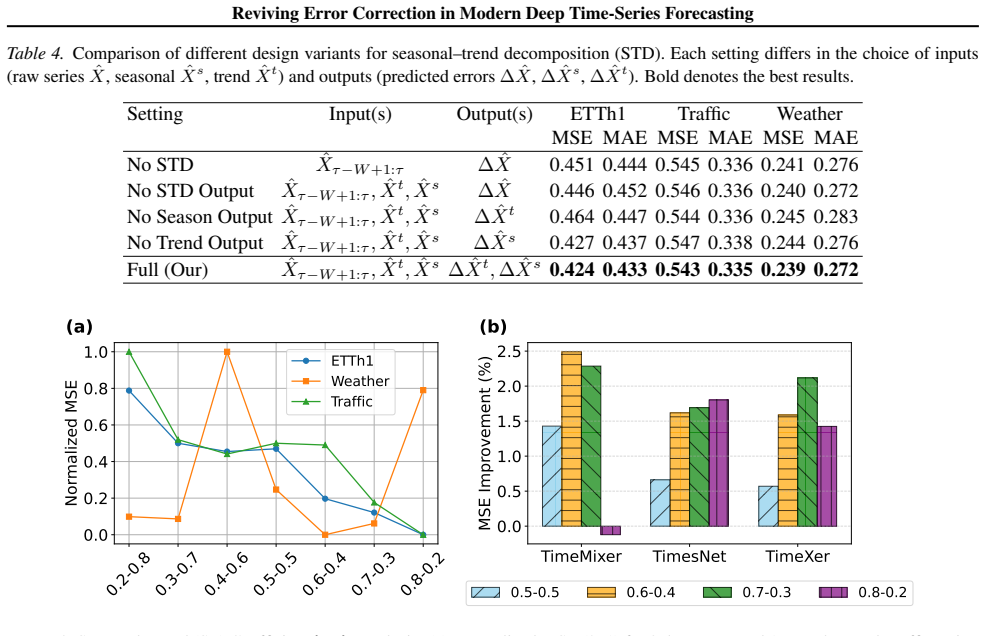
The Universal Error Corrector with Seasonal-Trend Decomposition (UEC-STD), which learns separate adjustments for the trend and seasonal components of the base model's predictions.
If this is right
- The corrector attaches to any existing deep forecaster as a post-processing step with no retraining required.
- Accuracy and robustness improve across four backbone architectures and ten standard datasets.
- Autoregressive error accumulation becomes addressable again for long-horizon forecasting tasks.
- The decomposition step allows the corrector to target different error patterns in trend versus seasonal behavior.
Where Pith is reading between the lines
- The same decomposition-plus-correction pattern could be tried on other autoregressive domains such as video or text generation.
- Hybrid systems that combine classical decomposition with modern networks may become more common for long-sequence tasks.
- Future tests could check whether the gains remain when the base forecaster is itself trained on very long contexts.
Load-bearing premise
A separately trained corrector can reliably fix the errors that accumulate when a base forecaster uses its own predictions as future inputs.
What would settle it
Running the same corrector on a fresh collection of time-series datasets or model architectures and finding no accuracy gain, or even worse results, would show the approach does not hold in general.
Figures





read the original abstract
Modern deep-learning models have achieved remarkable success in time-series forecasting. Yet, their performance degrades in long-term prediction due to error accumulation in autoregressive inference, where predictions are recursively used as inputs. While classical error correction mechanisms (ECMs) have long been used in statistical methods, their applicability to deep learning models remains limited or ineffective. In this work, we revisit the error accumulation problem in deep time-series forecasting and investigate the role and necessity of ECMs in this new context. We propose a simple, architecture-agnostic error correction model that can be integrated with any existing forecaster without requiring retraining. By explicitly decomposing predictions into trend and seasonal components and training the corrector to adjust each separately, we introduce the Universal Error Corrector with Seasonal-Trend Decomposition (UEC-STD), which significantly improves correction accuracy and robustness across 4 backbones and 10 datasets. Our findings provide a practical tool for enhancing forecasts while offering new insights into mitigating autoregressive errors in deep time-series models. Code is available at https://github.com/DA2I2-SLM/UEC-STD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that error accumulation during autoregressive inference degrades long-horizon performance of deep time-series forecasters. It proposes the Universal Error Corrector with Seasonal-Trend Decomposition (UEC-STD), an architecture-agnostic post-hoc module that decomposes base-model predictions into trend and seasonal components (via moving averages or STL), trains separate correctors for each, and applies the corrections without retraining or gradient flow back into the original forecaster. The authors assert that this yields significant gains in accuracy and robustness across 4 backbones and 10 datasets, with code released at https://github.com/DA2I2-SLM/UEC-STD.
Significance. If the empirical results hold under rigorous validation, the work would supply a practical, plug-and-play enhancement for existing deep forecasters by adapting classical error-correction ideas to the nonlinear, autoregressive setting. The open-source code is a clear strength for reproducibility. The architecture-agnostic design could broaden adoption, though the ultimate significance hinges on whether separate trend/seasonal correction actually interrupts recursive error propagation.
major comments (2)
- [§3] §3 (UEC-STD architecture): The central claim rests on the assumption that a separately trained corrector operating on decomposed base-model outputs can counteract autoregressive error compounding without any feedback loop or retraining of the forecaster. Because decomposition (moving average or STL) is performed on the already erroneous predicted sequence, residual cross-term errors between trend and seasonality are not guaranteed to be removed; the manuscript provides neither a theoretical argument nor targeted ablations demonstrating that corrected outputs, when fed back as inputs, prevent continued accumulation over long horizons.
- [§4] §4 (Experiments): The reported improvements across 4 backbones and 10 datasets are load-bearing for the practical contribution, yet the text supplies insufficient detail on training/validation splits, whether the corrector is applied at every autoregressive step, confidence intervals, or statistical tests. Without these, it is impossible to determine whether the gains arise from the proposed decomposition or from weaker baselines or post-hoc tuning.
minor comments (2)
- [Figure 1] Figure 1 (architecture diagram): The flow from base prediction through decomposition to separate correctors and final output would be clearer with explicit arrows indicating the autoregressive feedback of corrected values.
- [§3.1] Notation in §3.1: Define the decomposition operator (e.g., STL or MA) with a short equation to avoid ambiguity when the same operator is applied to both ground-truth and predicted sequences.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment in detail below, providing clarifications and committing to specific revisions that strengthen the empirical and methodological rigor of the work.
read point-by-point responses
-
Referee: [§3] §3 (UEC-STD architecture): The central claim rests on the assumption that a separately trained corrector operating on decomposed base-model outputs can counteract autoregressive error compounding without any feedback loop or retraining of the forecaster. Because decomposition (moving average or STL) is performed on the already erroneous predicted sequence, residual cross-term errors between trend and seasonality are not guaranteed to be removed; the manuscript provides neither a theoretical argument nor targeted ablations demonstrating that corrected outputs, when fed back as inputs, prevent continued accumulation over long horizons.
Authors: We agree that a formal theoretical guarantee for complete removal of cross-term errors is difficult to establish given the nonlinear nature of deep forecasters. The UEC-STD design is motivated by the empirical observation that separate correction of trend and seasonal components reduces the compounding of mixed errors during recursive inference. In the current experiments the corrector is applied iteratively at every autoregressive step; the sustained gains over long horizons (reported across all 10 datasets) provide evidence that this procedure limits error propagation. In the revision we will add a dedicated ablation subsection that (i) compares single-shot versus iterative correction and (ii) plots per-step error growth with and without UEC-STD. These results, together with the existing multi-backbone evaluation, will directly address the concern about continued accumulation. revision: partial
-
Referee: [§4] §4 (Experiments): The reported improvements across 4 backbones and 10 datasets are load-bearing for the practical contribution, yet the text supplies insufficient detail on training/validation splits, whether the corrector is applied at every autoregressive step, confidence intervals, or statistical tests. Without these, it is impossible to determine whether the gains arise from the proposed decomposition or from weaker baselines or post-hoc tuning.
Authors: We acknowledge that the experimental section requires additional transparency. The revised manuscript will explicitly document the train/validation/test splits for each of the 10 datasets, state that the corrector is applied at every autoregressive inference step, report mean and standard deviation over five independent runs with confidence intervals, and include paired statistical significance tests (Wilcoxon signed-rank) between UEC-STD and the base models. These additions will allow readers to verify that the observed improvements stem from the seasonal-trend decomposition rather than baseline weaknesses or post-hoc tuning. revision: yes
Circularity Check
No significant circularity: novel post-hoc corrector is self-contained
full rationale
The paper proposes UEC-STD as an architecture-agnostic error corrector trained separately on trend and seasonal decompositions of base forecaster outputs, without retraining or feedback into the original model. No equations, derivations, or fitted parameters are shown that reduce claimed improvements to quantities defined by the same inputs or by self-citation chains. The central contribution is an external training procedure evaluated empirically across backbones and datasets, remaining independent of the base model's internal autoregressive dynamics. This is a standard empirical method proposal with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Error accumulation during autoregressive rollout can be mitigated by a separately trained corrector that receives only the base model's output and operates on its trend-seasonal decomposition.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By explicitly decomposing predictions into trend and seasonal components and training the corrector to adjust each separately, we introduce the Universal Error Corrector with Seasonal-Trend Decomposition (UEC-STD)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
architecture-agnostic error correction model that can be integrated with any existing forecaster without requiring retraining
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Structural changes in the cointegrated vector autoregressive model , journal =
Peter Reinhard Hansen , keywords =. Structural changes in the cointegrated vector autoregressive model , journal =. 2003 , issn =. doi:https://doi.org/10.1016/S0304-4076(03)00085-X , url =
-
[2]
Journal of the American Statistical Association , year =
Matteo Barigozzi and Giuseppe Cavaliere and Lorenzo Trapani and , title =. Journal of the American Statistical Association , volume =. 2024 , publisher =. doi:10.1080/01621459.2022.2128807 , URL =
-
[3]
Forecasting Economics and Financial Time Series: ARIMA vs. LSTM
Forecasting economics and financial time series: ARIMA vs. LSTM , author=. arXiv preprint arXiv:1803.06386 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the VLDB Endowment , volume=
TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods , author=. Proceedings of the VLDB Endowment , volume=. 2024 , publisher=
work page 2024
-
[5]
Journal of forecasting , volume=
ARMA models and the Box--Jenkins methodology , author=. Journal of forecasting , volume=. 1997 , publisher=
work page 1997
-
[6]
Shuai Zhang and Yong Chen and Wenyu Zhang and Ruijun Feng , keywords =. A novel ensemble deep learning model with dynamic error correction and multi-objective ensemble pruning for time series forecasting , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.ins.2020.08.053 , url =
-
[7]
Journal of Physics: Conference Series , volume=
Difference attention based error correction LSTM model for time series prediction , author=. Journal of Physics: Conference Series , volume=. 2020 , organization=
work page 2020
-
[8]
Nandutu, Irene and Atemkeng, Marcellin and Mgqatsa, Nokubonga and Toadoum Sari, Sakayo and Okouma, Patrice and Rockefeller, Rockefeller and Ansah-Narh, Theophilus and Ebongue Kedieng Fendji, Jean Louis and Tchakounte, Franklin , TITLE =. Mathematics , VOLUME =. 2022 , NUMBER =
work page 2022
-
[9]
Olmos and Antonio Artés-Rodríguez , keywords =
Fernando Moreno-Pino and Pablo M. Olmos and Antonio Artés-Rodríguez , keywords =. Deep autoregressive models with spectral attention , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.patcog.2022.109014 , url =
-
[10]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
-
[11]
The Eleventh International Conference on Learning Representations , year=
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. The Eleventh International Conference on Learning Representations , year=
-
[12]
Timemixer: Decomposable multiscale mixing for time series forecasting , author=. arXiv preprint arXiv:2405.14616 , year=
-
[13]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[14]
The Twelfth International Conference on Learning Representations , year=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
The Twelfth International Conference on Learning Representations , year=
Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
The Thirteenth International Conference on Learning Representations , year=
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
International Conference on Data Management, Analytics & Innovation , pages=
A comprehensive survey of regression-based loss functions for time series forecasting , author=. International Conference on Data Management, Analytics & Innovation , pages=. 2024 , organization=
work page 2024
-
[18]
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[19]
Xgboost: A scalable tree boosting system , author=. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
- [20]
-
[21]
International Conference on Machine Learning , year=
TimeBridge: Non-Stationarity Matters for Long-term Time Series Forecasting , author=. International Conference on Machine Learning , year=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
TimeMixer++: A General Time Series Pattern Machine for Universal Predictive Analysis , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Monash Time Series Forecasting Archive
Rakshitha Godahewa and Christoph Bergmeir and Webb, \ Geoffrey I.\ and Hyndman, \ Rob J.\ and Pablo Montero-Manso. Monash Time Series Forecasting Archive. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1 (NeurIPS Datasets and Benchmarks 2021). 2021
work page 2021
-
[24]
Exploring Accuracy Law for Deep Time Series Forecasters: An Empirical Study
Accuracy law for the future of deep time series forecasting , author=. arXiv preprint arXiv:2510.02729 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2025 IEEE International Conference on Data Mining (ICDM) , pages=
Accelerating Long-Term Molecular Dynamics with Physics-Informed Time-Series Forecasting , author=. 2025 IEEE International Conference on Data Mining (ICDM) , pages=. 2025 , organization=
work page 2025
-
[26]
arXiv preprint arXiv:2602.01588 , year=
Spectral Text Fusion: A Frequency-Aware Approach to Multimodal Time-Series Forecasting , author=. arXiv preprint arXiv:2602.01588 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.