Nonparametric Learning and Earning with One-Point Feedback under Nonstationarity
Pith reviewed 2026-05-21 05:00 UTC · model grok-4.3
The pith
A nonparametric pricing method learns demand from single revenue observations per period and adapts to market shifts via restarts, bounding revenue loss by time horizon and variation size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing revenue-based gradient approximations from one observation per period and incorporating a restarting mechanism that periodically refreshes the learning process, the seller's cumulative revenue loss relative to a fully informed benchmark depends on both the time horizon and the magnitude of market variation.
What carries the argument
Revenue-based gradient approximations from one observation per period, combined with a restarting mechanism that periodically refreshes the learning process to discount outdated information.
If this is right
- Cumulative revenue loss scales with both the time horizon and the total variation in market conditions.
- The procedure requires no parametric assumption on the demand function.
- A meta-learning layer allows adaptation when the degree of nonstationarity is unknown.
- Simulation results on synthetic and real-world data show practical effectiveness.
Where Pith is reading between the lines
- The same restart-and-meta structure could be tested in other limited-feedback sequential problems such as inventory control under drifting demand.
- Platforms could deploy the method to maintain pricing performance across seasonal cycles without requiring manual tuning of restart frequency.
- Adding occasional side observations, such as competitor prices, might tighten the loss bounds further.
Load-bearing premise
The restarting mechanism effectively discounts outdated information so that learning can track changes in the underlying demand relationship.
What would settle it
In a controlled setting with known abrupt demand shifts, removing the restarts produces revenue loss that grows linearly with the number of changes instead of staying bounded by the variation measure.
Figures

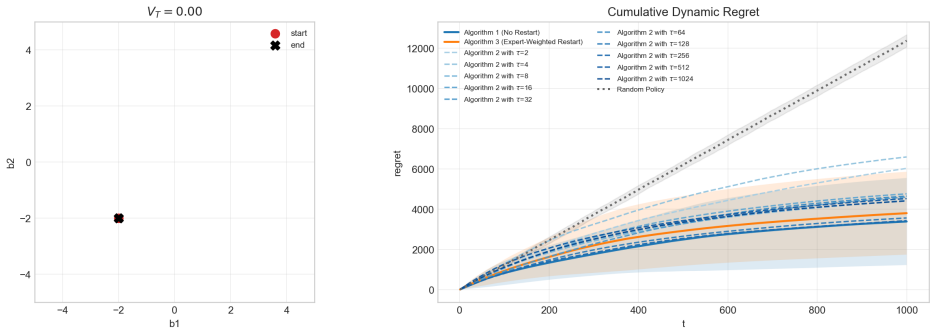
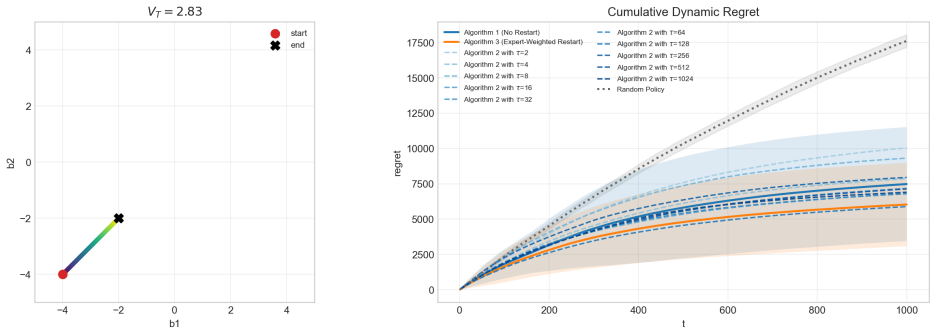



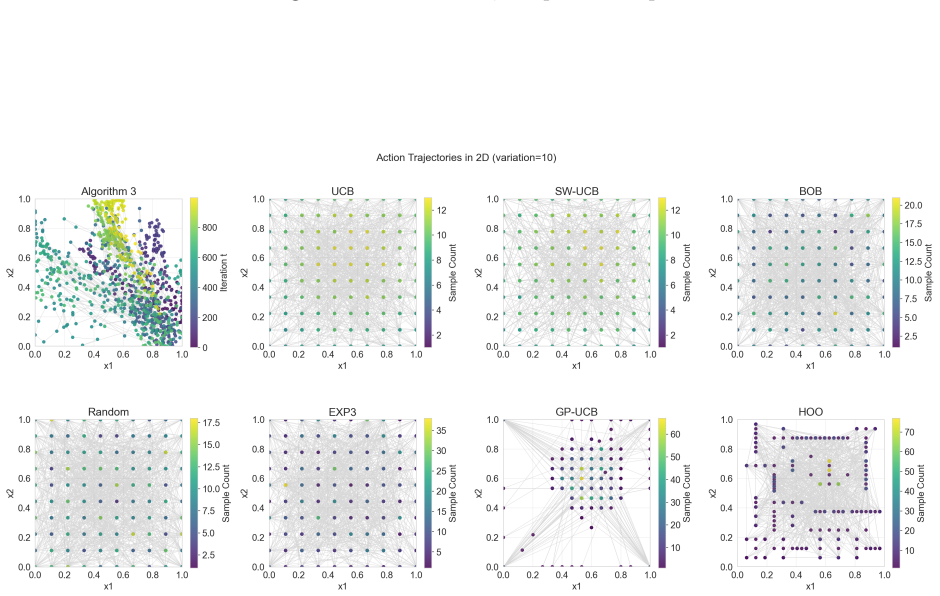








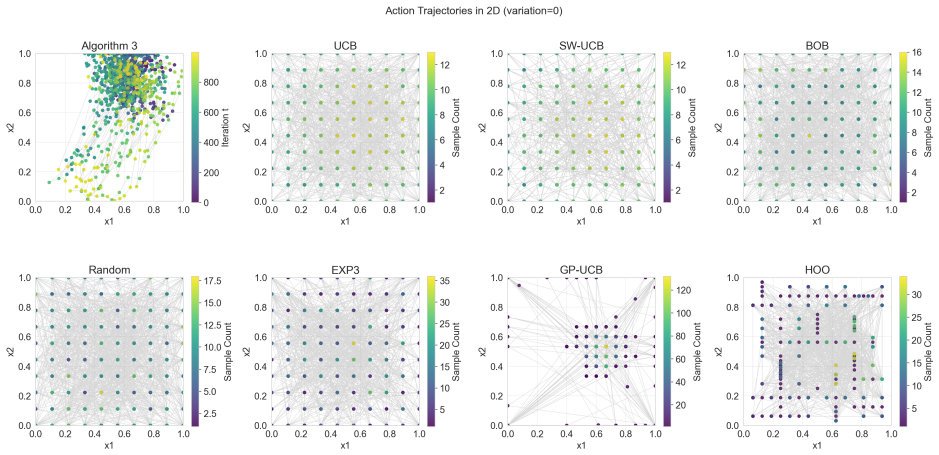





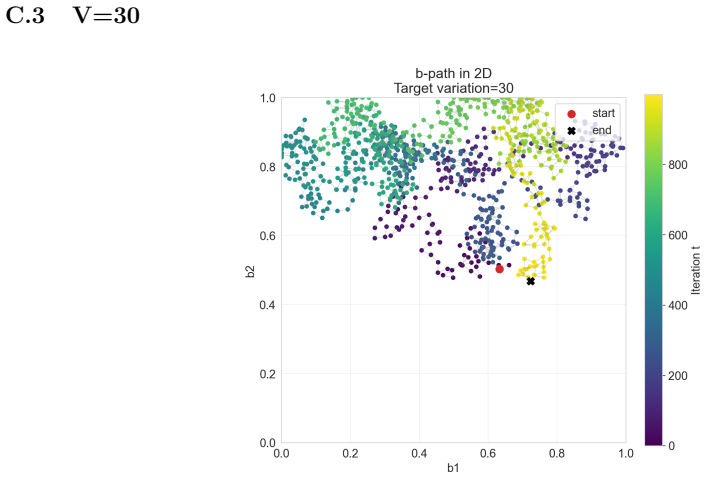
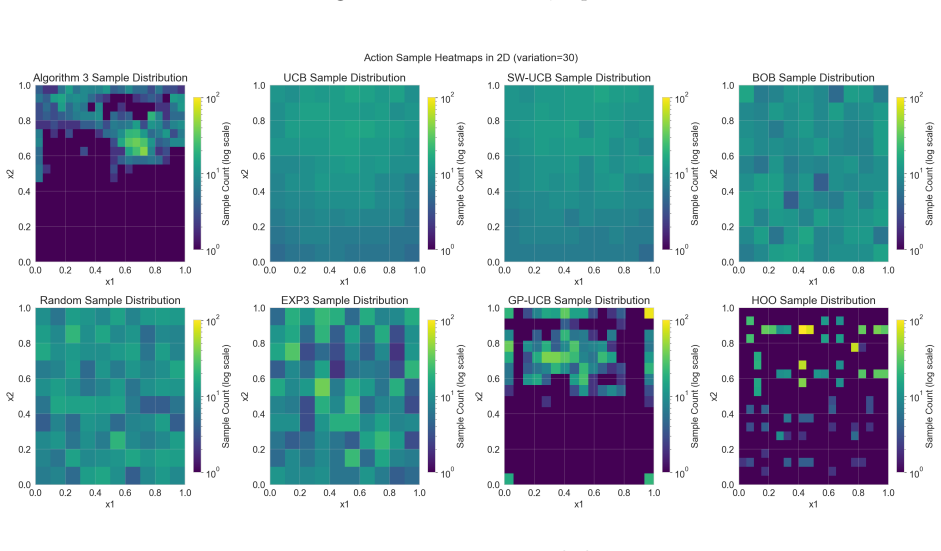


read the original abstract
Firms increasingly rely on dynamic pricing to respond to evolving customer demand, yet in many applications they observe only the revenue generated by a single posted price in each period. At the same time, market conditions may shift gradually or abruptly due to changes in customer preferences, competition, or external shocks. These features create two intertwined challenges: learning the revenue--demand relationship from limited feedback and adapting pricing decisions to a changing environment. We study how a seller can learn and earn effectively under these constraints, without assuming a specific parametric form for demand. We develop a learning framework that updates prices using revenue-based gradient approximations constructed from one observation per period. To address environmental changes, we incorporate a restarting mechanism that periodically refreshes the learning process so that outdated information is discounted. When the degree of nonstationarity is unknown, we further introduce a meta-learning layer to adaptively hedge across multiple restarting schedules. We provide performance guarantees for our approach, showing how cumulative revenue loss relative to a fully informed benchmark depends on both the time horizon and the magnitude of market variation. Simulation experiments using synthetic and real-world data illustrate the effectiveness of the proposed procedures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies nonparametric dynamic pricing with one-point (revenue-only) feedback in nonstationary environments. It proposes a framework that constructs revenue-based gradient approximations from single observations per period, incorporates periodic restarts to discount outdated information, and adds a meta-learning layer that hedges across multiple restarting schedules when the degree of nonstationarity is unknown. Performance guarantees are claimed showing that cumulative revenue loss relative to a fully informed benchmark scales with the time horizon T and a measure of market variation V; the claims are illustrated with synthetic and real-world simulations.
Significance. If the stated regret bounds hold, the work provides a useful nonparametric extension of online learning techniques to nonstationary pricing problems with minimal feedback. The adaptive restarting-plus-meta-learning construction and the explicit dependence on a variation measure V are technically interesting and practically relevant for revenue management applications. The simulation results on real data add empirical support, though the theoretical contribution would be strengthened by matching lower bounds or comparisons to parametric baselines.
major comments (2)
- [§3] §3 (variation measure definition): the paper introduces a specific measure V of market variation to obtain the claimed O(T^{2/3} + V) type bound, but it is unclear whether this V is equivalent to standard total-variation or Lipschitz notions used in the nonstationary bandit literature; an explicit comparison or reduction would clarify whether the bound is novel or recovers known rates.
- [§4.2] §4.2 (meta-learning analysis): the regret decomposition for the adaptive hedging layer over restarting schedules appears to rely on the variation being bounded within each restart interval; the proof sketch should explicitly state the assumption on intra-interval variation and show how the meta-regret term remains sublinear when V is unknown.
minor comments (2)
- [Abstract] The abstract states that performance guarantees exist but does not mention the precise rate or the variation measure V; adding one sentence with the dependence on T and V would improve readability for readers who stop at the abstract.
- [Simulation section] Figure captions for the simulation results should include the exact parameter settings (e.g., number of restarts, meta-learning rates) used to generate each curve so that the experiments are fully reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation for minor revision. We address each major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [§3] §3 (variation measure definition): the paper introduces a specific measure V of market variation to obtain the claimed O(T^{2/3} + V) type bound, but it is unclear whether this V is equivalent to standard total-variation or Lipschitz notions used in the nonstationary bandit literature; an explicit comparison or reduction would clarify whether the bound is novel or recovers known rates.
Authors: We appreciate this suggestion for clarification. Our variation measure V is defined as the sum over time of the total variation in the revenue curve, specifically V := sum_{t=1}^{T-1} sup_p |r_t(p) - r_{t+1}(p)| where r_t is the revenue function at time t. This is a natural extension of the total variation for functions. In the revised version, we will include a remark in Section 3 explicitly relating V to the standard notions: when the demand functions are Lipschitz continuous with constant L, our V is bounded by L times the total variation in the demand parameters, thus recovering the standard rates in the literature. This comparison highlights that our bound is novel in the nonparametric one-point feedback setting but consistent with prior work. revision: yes
-
Referee: [§4.2] §4.2 (meta-learning analysis): the regret decomposition for the adaptive hedging layer over restarting schedules appears to rely on the variation being bounded within each restart interval; the proof sketch should explicitly state the assumption on intra-interval variation and show how the meta-regret term remains sublinear when V is unknown.
Authors: Thank you for this observation. In our analysis, we assume that the variation within each restart interval of length tau is at most V * (tau / T), which follows from the definition of V as the total variation. For the meta-learning layer, we employ a standard exponential weights algorithm over a grid of possible restart frequencies, and the meta-regret is bounded by O(sqrt(K log T)) where K is the number of schedules, independent of V. When V is unknown, the adaptive choice ensures the overall regret remains O(T^{2/3} + V). We will expand the proof sketch in the appendix to explicitly state this assumption and derive the sublinear meta-regret term. revision: yes
Circularity Check
No significant circularity; bounds derived from independent variation measure and restart schedule
full rationale
The paper defines a market variation measure V externally from the sequence of demand functions, then constructs a restarting-plus-meta-learning procedure whose regret analysis yields an explicit dependence on both T and V. This dependence is obtained by standard online-learning arguments applied to the restarted nonparametric gradient estimates; it is not obtained by fitting V to the regret or by renaming an internal quantity. No load-bearing step reduces by construction to a fitted parameter or to a self-citation whose content is the target bound itself. The derivation therefore remains self-contained against the stated external parameters.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a learning framework that updates prices using revenue-based gradient approximations constructed from one observation per period. To address environmental changes, we incorporate a restarting mechanism...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the dynamic regret of Algorithm 2 is of order O(poly(d)T^(2p̂+q)/(3p̂+q) V_T^(p̂/(3p̂+q)))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Walmart Cuts Profit Outlook as It Lowers Prices to Move Goods
Sarah Nassauer. Walmart Cuts Profit Outlook as It Lowers Prices to Move Goods. 2022
work page 2022
-
[2]
Dynamic pricing and learning: Historical origins, current research, and new directions , journal =
Arnoud V. Dynamic pricing and learning: Historical origins, current research, and new directions , journal =. 2015 , issn =
work page 2015
-
[3]
Operations Research , volume =
Besbes, Omar and Gur, Yonatan and Zeevi, Assaf , title =. Operations Research , volume =
-
[4]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Tracking Slowly Moving Clairvoyant: Optimal Dynamic Regret of Online Learning with True and Noisy Gradient , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , volume =
work page 2016
-
[5]
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages=
Hu, Xiaowei and Prashanth, LA and Gy. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages=. 2016 , month =
work page 2016
-
[6]
A one-measurement form of simultaneous perturbation stochastic approximation , journal =. 1997 , issn =
work page 1997
-
[7]
and Kalai, Adam Tauman and McMahan, H
Flaxman, Abraham D. and Kalai, Adam Tauman and McMahan, H. Brendan , title =. Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages =. 2005 , isbn =
work page 2005
-
[8]
Gao, Katelyn and Sener, Ozan , booktitle =. Generalizing. 2022 , volume =
work page 2022
-
[9]
Mirror descent and nonlinear projected subgradient methods for convex optimization , journal =. 2003 , issn =
work page 2003
-
[10]
Improved Regret Guarantees for Online Smooth Convex Optimization with Bandit Feedback , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages =. 2011 , volume =
work page 2011
-
[11]
Chen, Tianyi and Giannakis, Georgios B. , journal=. Bandit Convex Optimization for Scalable and Dynamic IoT Management , year=
-
[12]
Journal of Machine Learning Research , year =
Peng Zhao and Guanghui Wang and Lijun Zhang and Zhi-Hua Zhou , title =. Journal of Machine Learning Research , year =
-
[13]
Cheung, Wang Chi and Simchi-Levi, David and Zhu, Ruihao , title =. Management Science , volume =
-
[14]
Prediction, Learning, and Games , publisher=
Cesa-Bianchi, Nicolo and Lugosi, Gabor , year=. Prediction, Learning, and Games , publisher=
-
[15]
Bandit Algorithms , publisher=
Lattimore, Tor and Szepesv\'. Bandit Algorithms , publisher=
-
[16]
Besbes, Omar and Zeevi, Assaf , title =. Management Science , volume =
-
[17]
Proceedings of the Twentieth International Conference on Machine Learning , pages =
Zinkevich, Martin , title =. Proceedings of the Twentieth International Conference on Machine Learning , pages =. 2003 , isbn =
work page 2003
-
[18]
Foundations and Trends in Optimization , volume=
Gradient-based algorithms for zeroth-order optimization , author=. Foundations and Trends in Optimization , volume=. 2025 , publisher=
work page 2025
-
[19]
Bandit Convex Optimisation , publisher=
Lattimore, Tor , year=. Bandit Convex Optimisation , publisher=
-
[20]
Operations Research , volume =
Besbes, Omar and Zeevi, Assaf , title =. Operations Research , volume =
-
[21]
den Boer, Arnoud V. and Keskin, N. Bora , title =. Management Science , volume =
-
[22]
Aviv, Yossi and Pazgal, Amit , title =. Management Science , volume =
-
[23]
Keskin, N. Bora and Li, Meng , title =. Operations Research , volume =
-
[24]
Learning and control in a changing economic environment , journal =. 2002 , note =
work page 2002
-
[25]
den Boer, Arnoud V. and Keskin, Nuri Bora. Dynamic Pricing and Demand Learning in Nonstationary Environments. The Elements of Joint Learning and Optimization in Operations Management. 2022
work page 2022
-
[26]
Bora and Zeevi, Assaf , title =
Keskin, N. Bora and Zeevi, Assaf , title =. Mathematics of Operations Research , volume =
-
[27]
Tracking the market: Dynamic pricing and learning in a changing environment , journal =. 2015 , author =
work page 2015
-
[28]
Jeff and Li, Chenghuai and Luo, Jun , title =
Hong, L. Jeff and Li, Chenghuai and Luo, Jun , title =. Naval Research Logistics (NRL) , volume =
-
[29]
Nonparametric multi-product dynamic pricing with demand learning via simultaneous price perturbation , journal =. 2024 , author =
work page 2024
-
[30]
On upper-confidence bound policies for switching bandit problems , year =
Garivier, Aur\'. On upper-confidence bound policies for switching bandit problems , year =. Proceedings of the 22nd International Conference on Algorithmic Learning Theory , pages =
- [31]
-
[32]
Production and Operations Management , volume =
Miao, Sentao and Chen, Xi and Chao, Xiuli and Liu, Jiaxi and Zhang, Yidong , title =. Production and Operations Management , volume =
-
[33]
Mathematics of Operations Research , volume =
Luo, Yiyun and Sun, Will Wei and Liu, Yufeng , title =. Mathematics of Operations Research , volume =
-
[34]
Journal of the American Statistical Association , number=
Contextual dynamic pricing: Algorithms, optimality, and local differential privacy constraints , author=. Journal of the American Statistical Association , number=. 2026 , publisher=
work page 2026
-
[35]
Manufacturing & Service Operations Management , volume =
Zhang, Huanan and Jasin, Stefanus , title =. Manufacturing & Service Operations Management , volume =
-
[36]
and Chen, Hongfan (Kevin) and Keskin, N
Birge, John R. and Chen, Hongfan (Kevin) and Keskin, N. Bora , title =. Operations Research , volume =
-
[37]
Meylahn, Janusz M. and V. den Boer, Arnoud , title =. Manufacturing & Service Operations Management , volume =
-
[38]
Koolen and Dirk van der Hoeven , title =
Tim van Erven and Wouter M. Koolen and Dirk van der Hoeven , title =. Journal of Machine Learning Research , year =
-
[39]
Introduction to Online Convex Optimization , edition =
Hazan, Elad , isbn=. Introduction to Online Convex Optimization , edition =. 2022 , publisher=
work page 2022
-
[40]
Tracking the Best Expert in Non-stationary Stochastic Environments , volume =
Wei, Chen-Yu and Hong, Yi-Te and Lu, Chi-Jen , booktitle =. Tracking the Best Expert in Non-stationary Stochastic Environments , volume =
-
[41]
2018 Annual American Control Conference (ACC) , pages=
On abruptly-changing and slowly-varying multiarmed bandit problems , author=. 2018 Annual American Control Conference (ACC) , pages=. 2018 , organization=
work page 2018
-
[42]
Proceedings of the 31st Conference On Learning Theory , pages =
Efficient Contextual Bandits in Non-stationary Worlds , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , editor =
work page 2018
-
[43]
Jadbabaie, Ali and Rakhlin, Alexander and Shahrampour, Shahin and Sridharan, Karthik , booktitle =. 2015 , volume =
work page 2015
-
[44]
Proceedings of the 35th International Conference on Machine Learning , pages =
Dynamic Regret of Strongly Adaptive Methods , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
work page 2018
-
[45]
Besbes, Omar and Gur, Yonatan and Zeevi, Assaf , title =. Stochastic Systems , volume =
- [46]
- [47]
-
[48]
Proceedings of the 37th International Conference on Machine Learning , pages =
When Demands Evolve Larger and Noisier: Learning and Earning in a Growing Environment , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
work page 2020
-
[49]
Bandit Learning in Concave N-Person Games , volume =
Bravo, Mario and Leslie, David and Mertikopoulos, Panayotis , booktitle =. Bandit Learning in Concave N-Person Games , volume =
-
[50]
Operations Research , volume =
Ba, Wenjia and Lin, Tianyi and Zhang, Jiawei and Zhou, Zhengyuan , title =. Operations Research , volume =
-
[51]
SIAM journal on computing , volume=
The nonstochastic multiarmed bandit problem , author=. SIAM journal on computing , volume=. 2002 , publisher=
work page 2002
- [52]
-
[53]
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. arXiv preprint arXiv:0912.3995 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Finite-time analysis of the multiarmed bandit problem , author=. Machine learning , volume=. 2002 , publisher=
work page 2002
-
[55]
Naval Research Logistics (NRL) , volume =
Zhang, Huanan and Shi, Cong and Qin, Chao and Hua, Cheng , title =. Naval Research Logistics (NRL) , volume =
-
[56]
Learning When to Restart: Nonstationary Newsvendor from Uncensored to Censored Demand , author=. 2025 , eprint=
work page 2025
-
[57]
Production and Operations Management , volume =
Chen, Boxiao , title =. Production and Operations Management , volume =
-
[58]
Mathematics of Operations Research , volume =
Chen, Boxiao and Chao, Xiuli and Shi, Cong , title =. Mathematics of Operations Research , volume =
-
[59]
Chen G, Teboulle M. 1993. Convergence analysis of a proximal-like minimization algorithm using Bregman functions. SIAM Journal on Optimization, 3 (3), 538-543
work page 1993
-
[60]
Cesa-Bianchi N, Lugosi G. 2006. Prediction, Learning, and Games. Cambridge University Press
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.