FedCoE: Bridging Generalization and Personalization via Federated Coordinated Dual-level MoEs
Pith reviewed 2026-05-21 06:23 UTC · model grok-4.3
The pith
FedCoE coordinates multiple global experts through a shared gating network to achieve both strong generalization across clients and high personalization in federated learning under non-IID conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
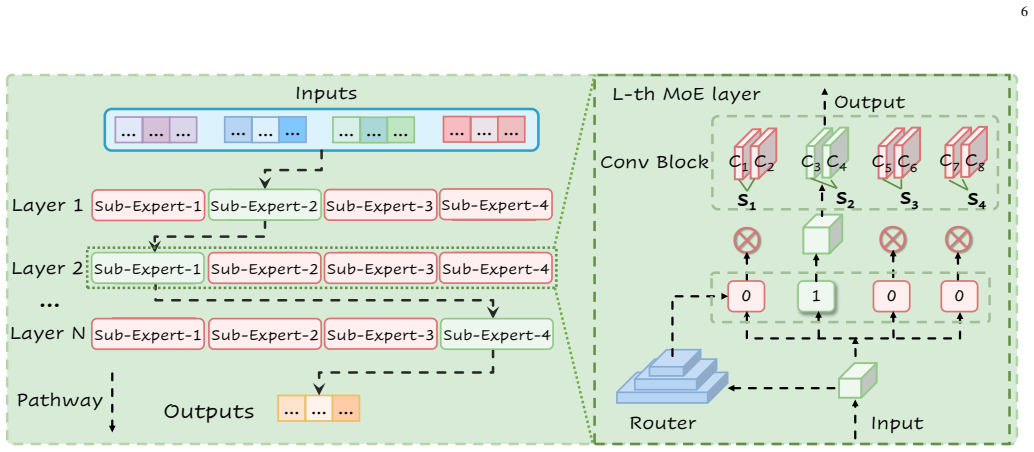
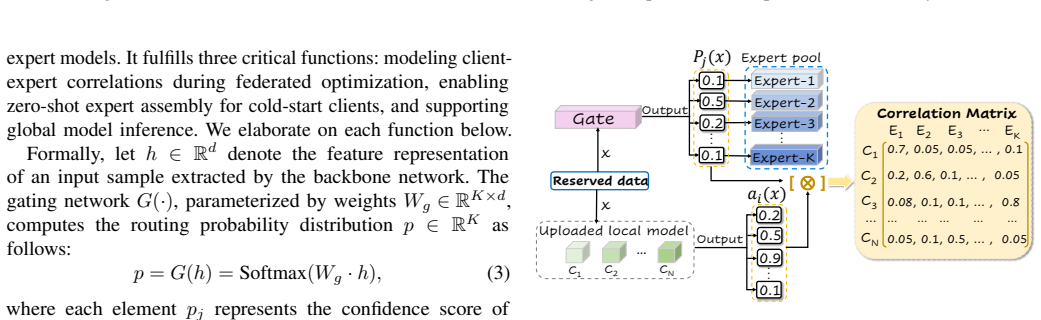
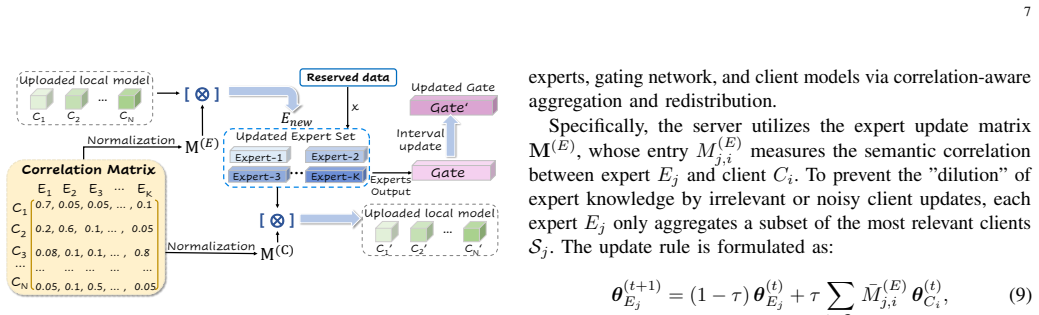
FedCoE maintains multiple independent global expert models on the server and employs a shared gating network to dynamically model client-expert correlations during aggregation, effectively mitigating expert drift and gating inconsistency. To address the cold-start challenge, an adaptive mechanism enables new clients to immediately leverage the global expert pool without extensive local training.
What carries the argument
The shared gating network that dynamically models client-expert correlations during server aggregation to route heterogeneous client data to specialized global experts while coordinating updates.
If this is right
- Global accuracy reaches 78.00 percent on average across tested datasets.
- Personalized accuracy reaches 89.32 percent, exceeding baselines by 29.19 percent.
- Cold-start clients obtain 77.27 percent accuracy with zero local fine-tuning, exceeding baselines by more than 12.54 percent.
- Expert drift and gating inconsistency are reduced through coordinated dual-level aggregation.
- The framework avoids both parameter divergence from averaging and overfitting from isolated personalization.
Where Pith is reading between the lines
- The shared-gating design may allow the number of experts to grow without a matching increase in per-round communication volume.
- The same coordination pattern could be tested in other distributed settings such as cross-device edge clusters where clients also exhibit heterogeneous distributions.
- Longer training runs with increasing numbers of clients would show whether the learned client-expert correlations remain stable or require periodic re-initialization.
- The results suggest that explicit expert specialization can substitute for heavy regularization techniques commonly used to control overfitting in personalized federated learning.
Load-bearing premise
The shared gating network can reliably capture and preserve stable correlations between clients and experts even when data across clients is strongly non-IID.
What would settle it
An experiment in which the shared gating network produces inconsistent expert assignments for clients with similar data distributions across successive rounds, yielding no accuracy gain over standard federated averaging.
Figures




read the original abstract
Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving distributed learning. However, existing FL methods face a fundamental challenge. Traditional averaging-based approaches suffer from parameter divergence under non-IID conditions, while personalized FL methods overfit to local data and fail to generalize to new clients (cold-start problem). Mixture-of-Experts naturally addresses this by routing heterogeneous data to specialized experts rather than forcing uniform aggregation. In this paper, we propose FedCoE, a Federated Coordinated dual-level mixture-of-Experts framework that effectively balances global generalization with local personalization. FedCoE maintains multiple independent global expert models on the server and employs a shared gating network to dynamically model client-expert correlations during aggregation, effectively mitigating expert drift and gating inconsistency. To address the cold-start challenge, we introduce an adaptive mechanism that enables new clients to immediately leverage the global expert pool without extensive local training. Extensive experiments demonstrate that FedCoE achieves 78.00% global accuracy and 89.32% personalized accuracy on average, outperforming the baseline by 8.82% and 29.19%, respectively. In cold-start scenarios, FedCoE delivers 77.27% accuracy without any local fine-tuning, outperforming baselines by over 12.54%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedCoE, a Federated Coordinated dual-level Mixture-of-Experts framework for federated learning. It maintains multiple independent global expert models on the server and employs a shared gating network to dynamically model client-expert correlations during aggregation, with the goal of mitigating expert drift and gating inconsistency under non-IID conditions. An adaptive mechanism is introduced to allow new clients to leverage the global expert pool immediately without local fine-tuning. Experiments report average global accuracy of 78.00% and personalized accuracy of 89.32%, outperforming baselines by 8.82% and 29.19% respectively, along with 77.27% accuracy in cold-start scenarios without fine-tuning.
Significance. If the central claims hold, FedCoE would offer a practical advance in balancing generalization and personalization in federated learning by using MoE specialization to handle data heterogeneity without uniform averaging. The cold-start handling without extensive local training could be valuable for dynamic client settings. The dual-level design provides a structured separation of global experts and coordinated gating that, if shown to preserve client-specific routing, addresses a known tension in personalized FL.
major comments (2)
- [§3.2] §3.2 (aggregation of shared gating network): The description indicates standard parameter averaging of the gating network across clients, but provides no client-specific adaptation, regularization, or per-client fine-tuning to preserve heterogeneous routing preferences. This is load-bearing for the central claim of mitigating gating inconsistency and expert drift, because under non-IID data the averaged gate risks converging to a compromise that routes poorly for most clients, potentially explaining reported gains as artifacts of particular partitions rather than a general property of the design.
- [§4] §4 (experimental evaluation): The reported accuracy numbers (78.00% global, 89.32% personalized, 77.27% cold-start) and improvements over baselines lack accompanying details on datasets, exact baseline implementations, number of independent runs, standard deviations, or statistical significance tests. This makes it difficult to confirm that gains are attributable to the dual-level MoE and shared gating rather than setup choices, directly affecting the soundness of the performance claims.
minor comments (2)
- [Abstract] Abstract: The phrase 'outperforming the baseline' is used without naming the specific baseline methods or providing a brief reference to the comparison setup.
- [Method] Notation in the method section could be clarified to explicitly distinguish the global expert parameters from the aggregated gating parameters in the equations describing the routing process.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of the FedCoE design and strengthen the experimental reporting. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (aggregation of shared gating network): The description indicates standard parameter averaging of the gating network across clients, but provides no client-specific adaptation, regularization, or per-client fine-tuning to preserve heterogeneous routing preferences. This is load-bearing for the central claim of mitigating gating inconsistency and expert drift, because under non-IID data the averaged gate risks converging to a compromise that routes poorly for most clients, potentially explaining reported gains as artifacts of particular partitions rather than a general property of the design.
Authors: We thank the referee for this observation. The gating network is indeed aggregated via standard parameter averaging. However, the coordination mechanism in FedCoE stems from the dual-level structure: multiple independent global experts are maintained on the server, and the shared gate is trained to capture dynamic client-expert correlations across communication rounds rather than forcing uniform routing. This separation allows expert specialization to handle heterogeneity while the shared gate provides a coordinated view that reduces inconsistency without per-client gate adaptation. We will revise §3.2 to include a clearer mathematical description of the correlation modeling during aggregation and add an ablation isolating the effect of shared-gate averaging versus independent gates. revision: partial
-
Referee: [§4] §4 (experimental evaluation): The reported accuracy numbers (78.00% global, 89.32% personalized, 77.27% cold-start) and improvements over baselines lack accompanying details on datasets, exact baseline implementations, number of independent runs, standard deviations, or statistical significance tests. This makes it difficult to confirm that gains are attributable to the dual-level MoE and shared gating rather than setup choices, directly affecting the soundness of the performance claims.
Authors: We agree that the experimental section would benefit from greater transparency. The results were obtained on CIFAR-10 and MNIST under Dirichlet non-IID partitions (α=0.1 and 0.5), with baselines re-implemented from their original papers using the same backbone architectures. All numbers are averages over 5 independent runs with different random seeds. In the revision we will report standard deviations, move key implementation details (hyperparameters, data splits, and baseline code references) from the appendix into the main text of §4, and include paired t-test p-values to establish statistical significance of the reported improvements. revision: yes
Circularity Check
No circularity: empirical method proposal with independent experimental validation
full rationale
The paper proposes FedCoE, a dual-level MoE framework for federated learning that uses multiple global experts and a shared gating network to balance generalization and personalization. The abstract and description present this as an architectural design choice to mitigate expert drift and gating inconsistency, with performance claims (78.00% global accuracy, 89.32% personalized accuracy, 77.27% cold-start) resting entirely on experimental comparisons to baselines rather than any mathematical derivation, fitted parameters renamed as predictions, or self-referential equations. No load-bearing steps reduce by construction to inputs; the central claims are falsifiable via external benchmarks and do not invoke self-citations or uniqueness theorems for justification. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
employs a shared gating network to dynamically model client-expert correlations during aggregation, effectively mitigating expert drift and gating inconsistency
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs a client-expert correlation matrix ... M = Σ p(x) a(x)⊤ ... selective correlation-guided update
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015. 12
work page 2015
-
[2]
General data protection regulation,
P. Regulation, “General data protection regulation,”Intouch, vol. 25, pp. 1–5, 2018
work page 2018
-
[3]
The california consumer privacy act: towards a european- style privacy regime in the united states,
S. L. Pardau, “The california consumer privacy act: towards a european- style privacy regime in the united states,”J. Tech. L. & Pol’y, vol. 23, p. 68, 2018
work page 2018
-
[4]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummingset al., “Advances and open problems in federated learning,”Foundations and trends® in machine learning, vol. 14, no. 1–2, pp. 1–210, 2021
work page 2021
-
[5]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of International Conference on Artificial Intelligence and Statistics. PMLR, 2017, pp. 1273–1282
work page 2017
-
[6]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProceedings of Annual Conference on Machine Learning and System, vol. 2, 2020, pp. 429–450
work page 2020
-
[7]
Federated learning on non-iid data silos: an experimental study,
Q. Li, Y . Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: an experimental study,” inProceedings of IEEE International Conference on Data Engineering. IEEE, 2022, pp. 965–978
work page 2022
-
[8]
Overcom- ing noisy labels and non-iid data in edge federated learning,
Y . Xu, Y . Liao, L. Wang, H. Xu, Z. Jiang, and W. Zhang, “Overcom- ing noisy labels and non-iid data in edge federated learning,”IEEE Transactions on Mobile Computing, vol. 23, no. 12, pp. 11 406–11 421, 2024
work page 2024
-
[9]
Federated Learning with Personalization Layers
M. G. Arivazhagan, V . Aggarwal, A. K. Singh, and S. Choud- hary, “Federated learning with personalization layers,”arXiv preprint arXiv:1912.00818, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[10]
Towards personalized federated learning via heterogeneous model reassembly,
J. Wang, X. Yang, S. Cui, L. Che, L. Lyu, D. D. Xu, and F. Ma, “Towards personalized federated learning via heterogeneous model reassembly,” inProceedings of Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 29 515–29 531
work page 2023
-
[11]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: the sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[13]
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Aminabadi, A. A. Awan, J. Rasley, and Y . He, “Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale,” inProceedings of International Conference on Machine Learning. PMLR, 2022, pp. 18 332–18 346
work page 2022
-
[14]
Designing effective sparse expert models,
B. Zoph, “Designing effective sparse expert models,” inProceedings of IEEE International Parallel and Distributed Processing Symposium Workshops. IEEE, 2022, pp. 1044–1044
work page 2022
-
[15]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
work page 2022
-
[16]
Scaling vision with sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. S. Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,” inProceedings of Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 8583–8595
work page 2021
-
[17]
Fed-MoE: Efficient federated learning for Mixture-of-Experts models via empirical pruning,
Y . Zou, S. Qi, Y . Yuan, D. Wang, S. Shen, L. Wu, S. Guo, and D. Yu, “Fed-MoE: Efficient federated learning for Mixture-of-Experts models via empirical pruning,” inProceedings of International Conference on Parallel and Distributed Computing: Applications and Technologies. Springer, 2024, pp. 128–139
work page 2024
-
[18]
Fedmoe: Personal- ized federated learning via heterogeneous mixture of experts,
H. Mei, D. Cai, A. Zhou, S. Wang, and M. Xu, “Fedmoe: Personalized federated learning via heterogeneous mixture of experts,”arXiv preprint arXiv:2408.11304, 2024
-
[19]
FedMoE-DA: Federated mixture of experts via domain aware fine-grained aggregation,
C. Wu, “FedMoE-DA: Federated mixture of experts via domain aware fine-grained aggregation,” inProceedings of International Conference on Mobility, Sensing and Networking, 2024
work page 2024
-
[20]
Mixture of specialized experts for Model- Heterogeneous personalized federated learning,
T. Liang, M. Hu, and E. Sun, “Mixture of specialized experts for Model- Heterogeneous personalized federated learning,”IEEE Networking Letters, vol. 7, no. 3, pp. 224–228, 2025
work page 2025
-
[21]
Scaffold: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learning,” in Proceedings of International Conference on Machine Learning. PMLR, 2020, pp. 5132–5143
work page 2020
-
[22]
Personalized federated learning with first order model optimization,
M. Zhang, K. Sapra, S. Fidler, S. Yeung, and J. M. Alvarez, “Personalized federated learning with first order model optimization,” inProceedings of International Conference on Learning Representations, 2021
work page 2021
-
[23]
Communication-efficient federated learning via knowledge distillation,
C. Wu, F. Wu, L. Lyu, Y . Huang, and X. Xie, “Communication-efficient federated learning via knowledge distillation,”Nature Communications, vol. 13, no. 1, p. 2032, 2022
work page 2032
-
[24]
Fedus, W.; Zoph, B.; and Shazeer, N
Y . Farhat, H. E. Shili, F. Liao, C. Dun, M. H. Garcia, G. Zheng, A. H. Awadallah, R. Sim, D. Dimitriadis, and A. Kyrillidis, “Learning to specialize: Joint gating-expert training for adaptive moes in decentralized settings,”arXiv preprint arXiv:2306.08586, 2025
-
[25]
Think Locally, Act Globally: Federated Learning with Local and Global Representations,
P. P. Liang, T. Liu, L. Ziyin, N. B. Allen, R. P. Auerbach, D. Brent, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,”arXiv preprint arXiv:2001.01523, 2020
-
[26]
PerFedRLNAS: One-for-all personalized federated neural architecture search,
D. Yao and B. Li, “PerFedRLNAS: One-for-all personalized federated neural architecture search,” inProceedings of AAAI Conference on Artificial Intelligence, vol. 38, no. 15, 2024, pp. 16 398–16 406
work page 2024
-
[27]
Personalized federated learning: A meta-learning approach,
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning: a meta-learning approach,”arXiv preprint arXiv:2002.07948, 2020
-
[28]
PeFLL: Personalized federated learning by learning to learn,
J. Scott, H. Zakerinia, and C. H. Lampert, “PeFLL: Personalized federated learning by learning to learn,” inProceedings of International Conference on Learning Representations, 2024
work page 2024
-
[29]
P. M. Ghari and Y . Shen, “Personalized federated learning with mixture of models for adaptive prediction and model fine-tuning,” inProceedings of Advances in Neural Information Processing Systems, 2024, pp. 92 155– 92 183
work page 2024
-
[30]
PM-MOE: Mixture of experts on private model parameters for personalized federated learning,
Y . Feng, Y . ao Geng, Y . Zhu, Z. Han, X. Yu, K. Xue, H. Luo, M. Sun, G. Zhang, and M. Song, “PM-MOE: Mixture of experts on private model parameters for personalized federated learning,” inProceedings of ACM on Web Conference, 2025, pp. 134–146
work page 2025
-
[31]
Heterogeneous federated learning with scalable server mixture-of-experts,
J. Jiang, Y . Chen, X. Liu, H. Jiang, and C. Fan, “Heterogeneous federated learning with scalable server mixture-of-experts,” inProceedings of International Joint Conference on Artificial Intelligence, 2025, pp. 5480– 5488
work page 2025
-
[32]
Robust mixture-of-expert training for convolutional neural networks,
Y . Zhang, R. Cai, T. Chen, G. Zhang, H. Zhang, P.-Y . Chen, S. Chang, Z. Wang, and S. Liu, “Robust mixture-of-expert training for convolutional neural networks,” inProceedings of IEEE/CVF International Conference on Computer Vision, 2023, pp. 90–101
work page 2023
-
[33]
L. Yi, H. Yu, C. Ren, H. Zhang, G. Wang, X. Liu, and X. Li, “Pfedmoe: Data-level personalization with mixture of experts for model-heterogeneous personalized federated learning,”arXiv preprint arXiv:2402.01350, 2024
-
[34]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[35]
Imagenet: a large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: a large-scale hierarchical image database,” inProceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255
work page 2009
-
[36]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,” inProceedings of Advances in Neural Information Processing Systems, vol. 32, 2019. Penglin Dai(S’15-M’17) received the B.S. degree in mathematics and applied mathematic...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.