Provable Joint Decontamination for Benchmarking Multiple Large Language Models
Pith reviewed 2026-05-22 00:36 UTC · model grok-4.3
The pith
A conformal procedure selects shared benchmarks for multiple LLMs while provably controlling the global contamination rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
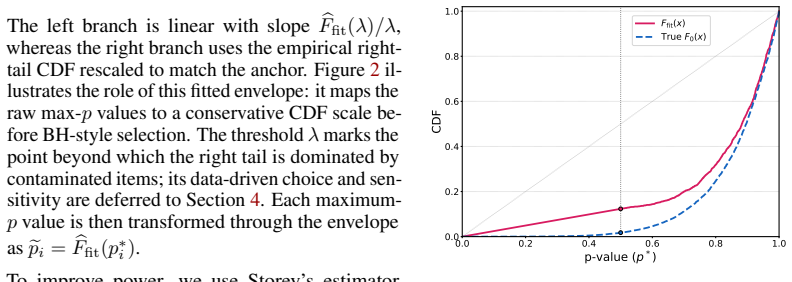
JECS computes per-model conformal p-values, aggregates them by the per-item maximum, reconstructs a conservative envelope of the max-p null distribution from right-tail observations above a data-driven threshold, and applies the adaptive Benjamini-Hochberg procedure to select a benchmark with provable global contamination rate control.
What carries the argument
The reconstruction of a conservative envelope for the distribution of maximum p-values, which rescales the statistics to enable joint control across models.
If this is right
- Provides a single decontaminated benchmark that supports fair performance comparisons across all audited models.
- Maintains the target global contamination rate control even when separate per-model detections would produce inconsistent selections.
- Achieves higher statistical power for identifying clean items compared to applying the maximum p-value directly without the envelope adjustment.
- Applies to various LLMs and benchmarks while consistently respecting the contamination control target.
Where Pith is reading between the lines
- Practitioners could adopt this for standardized evaluation suites shared among multiple model developers to reduce hidden contamination effects.
- The envelope approach might generalize to other joint multiple-testing problems where the maximum statistic is of interest.
- Testing the method on benchmarks with known partial contamination could reveal how sensitive the data-driven threshold is in practice.
Load-bearing premise
The conservative envelope built from right-tail observations above a data-driven threshold continues to upper-bound the true max-p null distribution when the individual conformal p-values meet their stated assumptions.
What would settle it
A simulation or real audit in which the fraction of actually contaminated items among those selected by JECS exceeds the nominal global contamination rate target.
Figures






read the original abstract
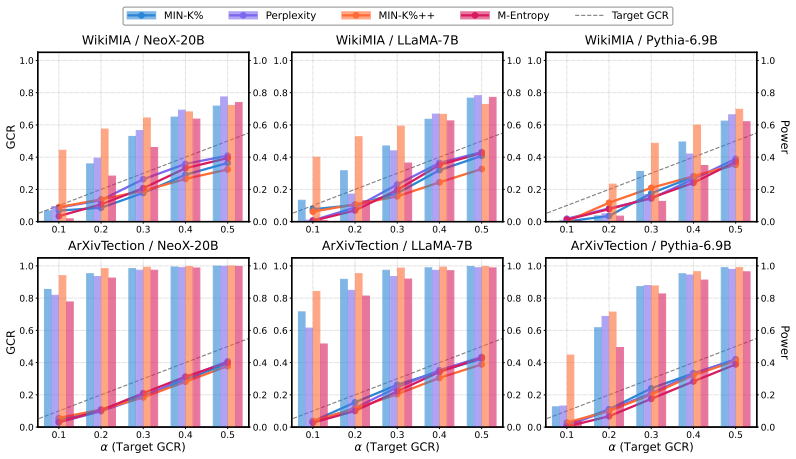
Benchmark data contamination has become a central challenge in LLM evaluation: when evaluation examples appear in the training data of one or more audited models, reported performance can be inflated and cross-model comparisons become unreliable. A broad line of training-data detection work designs scores to quantify how strongly a model memorizes a given data point, but these score-based methods lack theoretical guarantees. Recent conformal approaches provide provable false-identification control for a single model; however, applying them separately to each model can produce model-specific benchmarks, undermining fair comparison across models. In this work, we formalize multi-model benchmark decontamination as a joint selection problem and propose Joint Envelope Conformal Selection (JECS), a conformal procedure that enables global contamination rate (GCR) control under stated assumptions. Specifically, JECS computes per-model conformal p-values, aggregates them by the per-item maximum, and reconstructs a conservative envelope of the max-p null distribution from right-tail observations above a data-driven threshold. By applying the adaptive Benjamini-Hochberg (BH) procedure to the envelope-rescaled values, we select a benchmark with provable GCR control. Extensive experiments across various models and benchmarks demonstrate that JECS achieves higher power than the max-p baseline while consistently maintaining the target GCR control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes multi-model benchmark decontamination as a joint selection problem and proposes Joint Envelope Conformal Selection (JECS). JECS computes per-model conformal p-values, aggregates them via the per-item maximum, reconstructs a conservative envelope of the max-p null distribution from right-tail observations above a data-driven threshold, and applies the adaptive Benjamini-Hochberg procedure to the rescaled values to select a benchmark with provable global contamination rate (GCR) control under stated assumptions. Experiments across models and benchmarks are reported to show higher power than the max-p baseline while maintaining target GCR.
Significance. If the GCR control holds under the procedure's assumptions, the result would be significant for LLM evaluation: it would provide the first joint conformal method that enables fair cross-model comparisons by producing a single decontaminated benchmark with theoretical guarantees, rather than model-specific selections. The use of conformal p-values and adaptive BH is a natural extension of existing single-model decontamination work.
major comments (2)
- The central claim of provable GCR control rests on the conservative envelope reconstruction step, but the manuscript provides no explicit derivation, no statement of the full set of assumptions (e.g., on the dependence structure among per-model p-values), and no quantitative experimental results or tables in the provided description. This makes the guarantee impossible to verify from the text and is load-bearing for the main contribution.
- The envelope reconstruction from right-tail observations above a data-driven threshold (method description) may fail to stochastically dominate the true null distribution of the maximum when per-model conformal p-values for the same item are positively dependent, which is realistic for shared benchmark items. The data-driven threshold correlates with the observed maxima, and no explicit modeling or robustness argument for this dependence is given; a counterexample or additional proof under dependence would be required to support the GCR claim.
minor comments (2)
- The abstract claims 'extensive experiments' with higher power and GCR control but reports no numerical values, tables, or specific benchmarks/models; adding these would improve clarity.
- Notation for the envelope and rescaled p-values should be defined more precisely with equation numbers to allow direct reference in the proof.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments correctly identify that the theoretical guarantees are central to the contribution, and we will revise the manuscript to make the derivation, assumptions, and empirical verification fully explicit and self-contained.
read point-by-point responses
-
Referee: The central claim of provable GCR control rests on the conservative envelope reconstruction step, but the manuscript provides no explicit derivation, no statement of the full set of assumptions (e.g., on the dependence structure among per-model p-values), and no quantitative experimental results or tables in the provided description. This makes the guarantee impossible to verify from the text and is load-bearing for the main contribution.
Authors: We agree that the current presentation would benefit from greater explicitness. In the revised manuscript we will add a dedicated subsection (and appendix) containing the full derivation of the conservative envelope, the precise statement of all assumptions (including marginal validity of the per-model conformal p-values and the conditions under which the right-tail envelope stochastically dominates the null distribution of the maximum), and a self-contained proof of GCR control. We will also expand the experimental section with additional tables that report empirical GCR on both real benchmarks and controlled synthetic dependence scenarios. revision: yes
-
Referee: The envelope reconstruction from right-tail observations above a data-driven threshold (method description) may fail to stochastically dominate the true null distribution of the maximum when per-model conformal p-values for the same item are positively dependent, which is realistic for shared benchmark items. The data-driven threshold correlates with the observed maxima, and no explicit modeling or robustness argument for this dependence is given; a counterexample or additional proof under dependence would be required to support the GCR claim.
Authors: The concern is well-taken. Positive dependence among p-values for the same item is plausible and the data-driven threshold introduces correlation with the observed maxima. In the revision we will (i) explicitly state the working assumption of conditional independence across models given the item (or, alternatively, provide a worst-case bound), (ii) supply a short proof sketch showing that the envelope remains conservative under this assumption, and (iii) include a small simulation study that injects controlled positive dependence and verifies that the realized GCR stays below the nominal level. If the dependence is judged too strong for the guarantee to hold, we will clearly delineate the limitation in the revised text. revision: partial
Circularity Check
JECS derivation relies on standard conformal and BH theory with independent envelope construction
full rationale
The paper proposes JECS by computing per-model conformal p-values (standard), aggregating via per-item max, reconstructing a conservative envelope of the max-p null from right-tail observations above a data-driven threshold, and feeding rescaled values into adaptive BH for GCR control. This chain builds on established conformal inference and multiple-testing results without reducing the claimed guarantee to a tautology, self-definition, or fitted input renamed as prediction. The envelope step is presented as a novel but externally motivated construction under stated assumptions rather than presupposing the target GCR; no load-bearing premise collapses to self-citation or ansatz smuggling. The procedure remains self-contained against external benchmarks for its core components.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Per-model conformal p-values are valid under the null of no contamination for each model.
- domain assumption The max-p null distribution can be conservatively reconstructed from right-tail observations above a data-driven threshold.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
JECS computes per-model conformal p-values, aggregates them by the per-item maximum, reconstructs a conservative envelope of the max-p null distribution from right-tail observations above a data-driven threshold, and applies the adaptive Benjamini-Hochberg procedure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
IEEE Symposium on Security and Privacy , pages=
Membership inference attacks against machine learning models , author=. IEEE Symposium on Security and Privacy , pages=. 2017 , organization=
work page 2017
-
[3]
International Conference on Learning Representations , year=
How much of my dataset did you use? Quantitative Data Usage Inference in Machine Learning , author=. International Conference on Learning Representations , year=
-
[4]
International Conference on Learning Representations , year=
Quantifying Memorization Across Neural Language Models , author=. International Conference on Learning Representations , year=
-
[5]
Regulation (EU) 2016/679 (General Data Protection Regulation) , howpublished =. 2016 , month =
work page 2016
-
[6]
The California Consumer Privacy Act of 2018 (CCPA) , institution =. 2018 , number =
work page 2018
-
[7]
IEEE Conference on Secure and Trustworthy Machine Learning , pages=
Position: Membership Inference Attacks Cannot Prove That a Model was Trained on Your Data , author=. IEEE Conference on Secure and Trustworthy Machine Learning , pages=. 2025 , organization=
work page 2025
-
[8]
arXiv preprint arXiv:2309.10677 , year=
Estimating contamination via perplexity: Quantifying memorisation in language model evaluation , author=. arXiv preprint arXiv:2309.10677 , year=
-
[9]
International Conference on Learning Representations , year=
Detecting Pretraining Data from Large Language Models , author=. International Conference on Learning Representations , year=
-
[10]
IEEE Symposium on Security and Privacy (SP) , pages=
Membership inference attacks from first principles , author=. IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
work page 2022
-
[11]
Privacy risk in machine learning: Analyzing the connection to overfitting , author=. 2018 , organization=
work page 2018
-
[12]
Ahmed Salem and Yang Zhang and Mathias Humbert and Pascal Berrang and Mario Fritz and Michael Backes , title =
-
[13]
ACM SIGSAC Conference on Computer and Communications Security , pages=
Enhanced membership inference attacks against machine learning models , author=. ACM SIGSAC Conference on Computer and Communications Security , pages=
-
[14]
Advances in Neural Information Processing Systems , volume=
Scalable membership inference attacks via quantile regression , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Membership Inference Attacks against Large Vision-Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[16]
International Conference on Machine Learning , year=
Low-Cost High-Power Membership Inference Attacks , author=. International Conference on Machine Learning , year=
-
[17]
Advances in Neural Information Processing Systems , year=
Membership Inference Attacks against Fine-tuned Large Language Models via Self-prompt Calibration , author=. Advances in Neural Information Processing Systems , year=
-
[18]
USENIX Security Symposium , pages=
Extracting training data from large language models , author=. USENIX Security Symposium , pages=
-
[19]
arXiv preprint arXiv:2503.07482 , year=
Efficient Membership Inference Attacks by Bayesian Neural Network , author=. arXiv preprint arXiv:2503.07482 , year=
-
[20]
International Conference on Learning Representations , year=
Fine-tuning can Help Detect Pretraining Data from Large Language Models , author=. International Conference on Learning Representations , year=
-
[21]
Journal of Machine Learning Research , volume=
Selection by prediction with conformal p-values , author=. Journal of Machine Learning Research , volume=
-
[22]
Journal of the Royal Statistical Society , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society , volume=. 1995 , publisher=
work page 1995
-
[23]
The control of the false discovery rate in multiple testing under dependency , author=. Annals of Statistics , pages=. 2001 , publisher=
work page 2001
-
[24]
International Conference on Learning Representations , year=
Proving test set contamination in black-box language models , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
A Statistical Approach for Controlled Training Data Detection , author=. International Conference on Learning Representations , year=
-
[26]
Deyao Zhu and Jun Chen and Xiaoqian Shen and Xiang Li and Mohamed Elhoseiny , booktitle=. Mini. 2024 , url=
work page 2024
-
[27]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[30]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep residual learning for image recognition , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
IEEE Conference on Computer Vision and Pattern Recognition , pages=
Densely connected convolutional networks , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
International Conference on Machine Learning , year=
Andr. International Conference on Machine Learning , year=
-
[35]
Language Models are Unsupervised Multitask Learners , author=. 2019 , url=
work page 2019
-
[36]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author=. arXiv preprint arXiv:2101.00027 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Narayan, Shashi and Cohen, Shay B. and Lapata, Mirella. Don ' t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. Conference on Empirical Methods in Natural Language Processing. doi:10.18653/v1/D18-1206
-
[38]
Yucheng Li and Frank Guerin and Chenghua Lin , title =
-
[39]
Learning multiple layers of features from tiny images , author=. 2009 , journal=
work page 2009
-
[40]
USENIX Security Symposium , pages=
Systematic evaluation of privacy risks of machine learning models , author=. USENIX Security Symposium , pages=
-
[41]
Berkeley Symposium on Mathematical Statistics and Probability , volume=
On measures of entropy and information , author=. Berkeley Symposium on Mathematical Statistics and Probability , volume=. 1961 , organization=
work page 1961
-
[42]
Dong, Yihong and Jiang, Xue and Liu, Huanyu and Jin, Zhi and Gu, Bin and Yang, Mengfei and Li, Ge. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.716
-
[45]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[46]
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Sainz, Oscar and Campos, Jon and Garc \'i a-Ferrero, Iker and Etxaniz, Julen and de Lacalle, Oier Lopez and Agirre, Eneko. NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.722
-
[47]
Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLM s
Balloccu, Simone and Schmidtov \'a , Patr \'i cia and Lango, Mateusz and Dusek, Ondrej. Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLM s. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics. 2024. doi:10.18653/v1/2024.eacl-long.5
-
[48]
Proceedings of the IEEE Symposium on Security and Privacy (SP) , pages=
Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning , author=. Proceedings of the IEEE Symposium on Security and Privacy (SP) , pages=. 2019 , organization=
work page 2019
-
[49]
International Conference on Machine Learning , pages=
White-box vs black-box: Bayes optimal strategies for membership inference , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[50]
Advances in Neural Information Processing Systems , year =
Gaussian Membership Inference Privacy , author =. Advances in Neural Information Processing Systems , year =
-
[51]
IEEE Transactions on Computational Social Systems , volume=
Socinf: Membership inference attacks on social media health data with machine learning , author=. IEEE Transactions on Computational Social Systems , volume=. 2019 , publisher=
work page 2019
-
[52]
Lauren Watson and Chuan Guo and Graham Cormode and Alexandre Sablayrolles , title =
-
[54]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
Inbal Magar and Roy Schwartz , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
-
[55]
International Conference on Learning Representations , year=
Min-K\ author=. International Conference on Learning Representations , year=
-
[56]
Do Membership Inference Attacks Work on Large Language Models? , author=. 2024 , booktitle=
work page 2024
-
[58]
International Conference on Learning Representations , year=
Infilling Score: A Pretraining Data Detection Algorithm for Large Language Models , author=. International Conference on Learning Representations , year=
-
[60]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
A direct approach to false discovery rates , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2002 , publisher=
work page 2002
-
[61]
Vladimir Vovk and Ilia Nouretdinov and Alex Gammerman , title =
-
[62]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
-
[63]
The Annals of Statistics , volume=
Testing for outliers with conformal p-values , author=. The Annals of Statistics , volume=. 2023 , publisher=
work page 2023
-
[64]
Computational Statistics & Data Analysis , volume=
Beta kernel estimators for density functions , author=. Computational Statistics & Data Analysis , volume=. 1999 , publisher=
work page 1999
-
[65]
Journal of Nonparametric Statistics , volume=
Bias reductions for beta kernel estimation , author=. Journal of Nonparametric Statistics , volume=. 2016 , publisher=
work page 2016
-
[66]
Journal of the American Statistical Association , volume=
Improvement of kernel type density estimators , author=. Journal of the American Statistical Association , volume=. 1977 , publisher=
work page 1977
-
[67]
Pierre Neuvial , title =. J. Mach. Learn. Res. , volume =
-
[68]
Adaptive linear step-up procedures that control the false discovery rate , author=. Biometrika , volume=. 2006 , publisher=
work page 2006
-
[69]
Journal of Educational and Behavioral Statistics , volume=
On the adaptive control of the false discovery rate in multiple testing with independent statistics , author=. Journal of Educational and Behavioral Statistics , volume=. 2000 , publisher=
work page 2000
-
[70]
Proceedings of the Sixteenth International Conference on Machine Learning , pages =
Vovk, Volodya and Gammerman, Alexander and Saunders, Craig , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , isbn =
work page 1999
-
[71]
ACM transactions on intelligent systems and technology , volume=
A survey on evaluation of large language models , author=. ACM transactions on intelligent systems and technology , volume=. 2024 , publisher=
work page 2024
-
[72]
Investigating data contamination in modern benchmarks for large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[74]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[76]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[78]
arXiv preprint arXiv:2211.15533 , year=
The stack: 3 tb of permissively licensed source code , author=. arXiv preprint arXiv:2211.15533 , year=
-
[79]
StarCoder: may the source be with you!
Starcoder: may the source be with you! , author=. arXiv preprint arXiv:2305.06161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Advances in Neural Information Processing Systems , volume=
Redpajama: an open dataset for training large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[82]
Advances in Neural Information Processing Systems , volume=
The refinedweb dataset for falcon llm: Outperforming curated corpora with web data only , author=. Advances in Neural Information Processing Systems , volume=
-
[83]
2024 , month = jul, day =
work page 2024
-
[84]
Forty-third International Conference on Machine Learning , year=
Provable Training Data Identification for Large Language Models , author=. Forty-third International Conference on Machine Learning , year=
-
[85]
The Fourteenth International Conference on Learning Representations , year=
Multi-Condition Conformal Selection , author=. The Fourteenth International Conference on Learning Representations , year=
-
[86]
Forty-second International Conference on Machine Learning , year=
Multivariate Conformal Selection , author=. Forty-second International Conference on Machine Learning , year=
-
[87]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Sok: Membership inference attacks on llms are rushing nowhere (and how to fix it) , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
work page 2025
-
[88]
Advances in Neural Information Processing Systems , volume=
LLM Dataset Inference: Did you train on my dataset? , author=. Advances in Neural Information Processing Systems , volume=
-
[89]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: a unified approach , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2004 , publisher=
work page 2004
-
[90]
Detecting Non-Membership in LLM Training Data via Rank Correlations , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[91]
Forty-second International Conference on Machine Learning , year=
How Contaminated Is Your Benchmark? Measuring Dataset Leakage in Large Language Models with Kernel Divergence , author=. Forty-second International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.