Objective-Induced Bias and Search Dynamics in Multiobjective Unsupervised Feature Selection
Pith reviewed 2026-05-22 09:53 UTC · model grok-4.3
The pith
A PCA reconstruction loss objective in multiobjective unsupervised feature selection produces compact subsets with test accuracy comparable to direct supervised optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
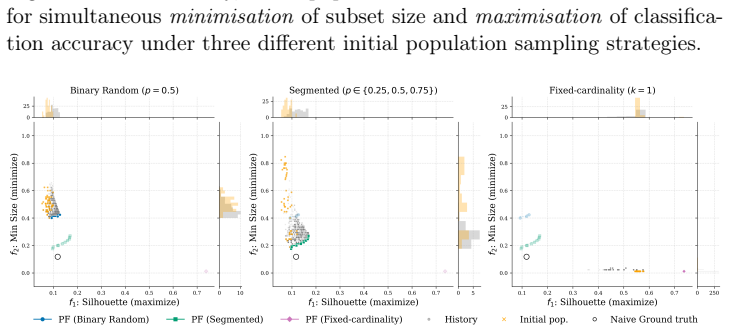
The formulation of the multiobjective problem, including the evaluation objective and the direction of subset-size regularisation, strongly affects search dynamics and the quality of the Pareto front. In particular, the PCA reconstruction loss objective produces compact subsets whose test accuracy is comparable to subsets obtained by directly optimising supervised accuracy, whereas silhouette-score formulations exhibit a strong bias toward trivial low-cardinality solutions that remain weak proxies for predictive performance.
What carries the argument
The six multiobjective formulations that pair one of three evaluation objectives (accuracy, silhouette score, PCA reconstruction loss) with either subset-size minimisation or maximisation, compared on a controlled synthetic dataset with known informative, redundant, and irrelevant features.
If this is right
- Objective choice determines whether the Pareto front contains useful compact subsets or collapses to trivial solutions.
- Silhouette score serves as a weak proxy for predictive performance in this setting.
- PCA loss functions as a viable unsupervised surrogate that can match the accuracy of supervised feature selection.
- Both initialisation strategy and the direction of size regularisation further shape the search trajectory and final front.
- Effective multiobjective unsupervised feature selection requires deliberate design of the evaluation objective.
Where Pith is reading between the lines
- The synthetic benchmark could serve as a controlled testbed for evaluating new search algorithms in feature selection.
- Objective-induced biases observed here may appear in other multiobjective combinatorial tasks in machine learning.
- When labels are unavailable, trying a PCA-based objective offers a concrete starting point for unsupervised selection.
- Hybrid objectives that blend PCA loss with other unsupervised metrics might reduce the bias seen in single-objective versions.
Load-bearing premise
Search dynamics and quality outcomes observed on the synthetic dataset with explicitly labeled feature types generalize to real high-dimensional data where such ground truth is unavailable.
What would settle it
Applying the PCA loss formulation to a real high-dimensional dataset and measuring test accuracy of the resulting subsets against those from supervised optimization would falsify the comparability claim if the unsupervised subsets perform substantially worse.
Figures





read the original abstract
Unsupervised feature selection is commonly formulated as a multiobjective optimisation problem that jointly optimises subset quality and subset size. Yet the behaviour of this formulation depends critically on the choice of evaluation objective, the direction of subset-size regularisation, and the initialisation strategy. We study these factors in a controlled setting using a synthetic dataset with known informative, redundant, and irrelevant feature types. Six formulations are compared by combining three evaluation objectives: accuracy, silhouette score, and PCA reconstruction loss with subset-size minimisation or maximisation. The results show that formulation strongly affects both search dynamics and the quality of the resulting Pareto front. Silhouette-based formulations exhibit a strong bias toward trivial low-cardinality solutions and remain weak proxies for predictive performance. In contrast, the proposed PCA loss objective produces compact subsets with test accuracy comparable to subsets obtained by directly optimising supervised accuracy. Overall, the study shows that objective design is central to effective multiobjective unsupervised feature selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies how the choice of evaluation objective (accuracy, silhouette score, or PCA reconstruction loss) and the direction of subset-size regularization (min or max) influence search dynamics and Pareto-front quality in multiobjective unsupervised feature selection. Experiments are conducted on a synthetic dataset whose features are explicitly partitioned into informative, redundant, and irrelevant types; six formulations are compared, with downstream supervised test accuracy used to assess the utility of the selected subsets. The central empirical result is that PCA-loss formulations yield compact subsets whose test accuracy is comparable to subsets obtained by directly optimizing supervised accuracy, whereas silhouette-based formulations exhibit a strong bias toward trivial low-cardinality solutions.
Significance. If the reported behavior holds beyond the synthetic setting, the work supplies concrete guidance on objective design for multiobjective unsupervised feature selection and demonstrates that PCA reconstruction loss can act as a label-free proxy that preserves predictive utility while promoting compactness. The controlled synthetic construction with known feature types is a methodological strength that permits direct measurement of bias and search dynamics.
major comments (2)
- [§4] §4 (Experimental Results): The claim that the PCA-loss objective produces subsets with test accuracy comparable to direct supervised optimization is demonstrated only on synthetic data whose informative/redundant/irrelevant partition is known a priori. Because both the reconstruction loss and the evolutionary search can exploit this explicit partition, the observed Pareto-front quality and compactness may not transfer to real high-dimensional data where the partition is latent and feature interactions are denser; the manuscript should either qualify the transfer claim or add at least one real-world dataset experiment.
- [§3.2] §3.2 (Objective Formulations): The paper does not report the number of independent runs, statistical tests for differences in Pareto-front quality, or sensitivity analysis to the evolutionary algorithm hyperparameters. Without these, it is difficult to assess whether the reported superiority of PCA loss over silhouette score is robust or could be an artifact of a single run or particular hyperparameter setting.
minor comments (2)
- [Abstract] The abstract states that silhouette-based formulations 'remain weak proxies for predictive performance' but does not quantify this weakness with a specific metric (e.g., average test accuracy gap or hypervolume difference) that could be compared across tables.
- [§2] Notation for the multiobjective formulation (e.g., the precise definition of the PCA reconstruction loss inside the evolutionary loop) should be introduced earlier and used consistently when describing the six formulations.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive comments, which help clarify the scope and robustness of our findings. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): The claim that the PCA-loss objective produces subsets with test accuracy comparable to direct supervised optimization is demonstrated only on synthetic data whose informative/redundant/irrelevant partition is known a priori. Because both the reconstruction loss and the evolutionary search can exploit this explicit partition, the observed Pareto-front quality and compactness may not transfer to real high-dimensional data where the partition is latent and feature interactions are denser; the manuscript should either qualify the transfer claim or add at least one real-world dataset experiment.
Authors: We thank the referee for this observation and note that the controlled synthetic construction with known feature types is explicitly identified as a methodological strength in the report. The study was deliberately designed to enable direct measurement of bias and search dynamics, which would not be possible with latent partitions in real data. We agree that transferability is not demonstrated and will revise the manuscript to qualify all claims about PCA-loss comparability by adding explicit statements that the results hold for the synthetic dataset with an a priori known informative/redundant/irrelevant partition. This qualification will be inserted in §4 and the abstract without adding new real-world experiments, as the current design prioritizes controlled analysis over broad empirical claims. revision: yes
-
Referee: [§3.2] §3.2 (Objective Formulations): The paper does not report the number of independent runs, statistical tests for differences in Pareto-front quality, or sensitivity analysis to the evolutionary algorithm hyperparameters. Without these, it is difficult to assess whether the reported superiority of PCA loss over silhouette score is robust or could be an artifact of a single run or particular hyperparameter setting.
Authors: We agree that greater transparency on experimental protocol would strengthen the presentation. The reported results were obtained from multiple independent runs of the evolutionary algorithm to mitigate stochasticity, although this detail was omitted from the original text. In the revision we will specify the number of runs, report mean and standard deviation of key metrics (e.g., Pareto-front hypervolume and test accuracy), and include statistical comparisons such as Wilcoxon rank-sum tests between formulations. We will also add a short sensitivity discussion in §3.2 that examines the effect of the main hyperparameters (population size, mutation rate, and number of generations) based on the values used throughout the study. revision: yes
Circularity Check
No circularity: purely empirical comparison on synthetic data
full rationale
The paper conducts an empirical study comparing six multiobjective formulations for unsupervised feature selection using accuracy, silhouette score, and PCA reconstruction loss on a synthetic dataset with known feature types. Results are measured directly against held-out supervised test accuracy and subset cardinality, with no mathematical derivations, predictions, or self-referential definitions that reduce to fitted inputs. No self-citations are invoked as load-bearing premises, and the central claims rest on observable search dynamics and Pareto fronts rather than any construction that equates outputs to inputs by definition. The study is self-contained against its external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The synthetic dataset with known informative, redundant, and irrelevant feature types accurately reflects the feature interactions encountered in real high-dimensional data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an unsupervised objective, PCA loss which to the best to our knowledge has not been applied in this context, and analyse its behaviour under subset-size regularisation... The objective function then tries to minimise the Mean Square Error (loss) between Z and ˆZ
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Six formulations are compared by combining three evaluation objectives: accuracy, silhouette score, and PCA reconstruction loss with subset-size minimisation or maximisation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jun Chin Ang, Andri Mirzal, Habibollah Haron, and Haza Nuzly Ab- dull Hamed. Supervised, Unsupervised, and Semi-Supervised Feature Selection: A Review on Gene Selection.IEEE/ACM Transactions on Computational Biology and Bioinformatics, 13(5):971–989, September 2016. 19
work page 2016
-
[2]
pymoo: Multi-objective Optimiza- tion in Python.IEEE Access, 8:89497–89509, 2020
Julian Blank and Kalyanmoy Deb. pymoo: Multi-objective Optimiza- tion in Python.IEEE Access, 8:89497–89509, 2020. arXiv:2002.04504 [cs]
-
[3]
Thomas H. W. Bäck, Anna V. Kononova, Bas Van Stein, Hao Wang, Kirill A. Antonov, Roman T. Kalkreuth, Jacob De Nobel, Diederick Vermetten, Roy De Winter, and Furong Ye. Evolutionary Algorithms for Parameter Optimization—Thirty Years Later.Evolutionary Com- putation, 31(2):81–122, June 2023
work page 2023
-
[4]
objective-induced bias and search dynamics in multiobjective unsupervised feature selection
Mathieu Cherpitel, Thomas Bäck, Martijn R. Tannemaat, and Anna V. Kononova. Supplementary material for “objective-induced bias and search dynamics in multiobjective unsupervised feature selection”, 2026
work page 2026
-
[5]
David Davies and Don Bouldin. A Cluster Separation Measure.Pat- tern Analysis and Machine Intelligence, IEEE Transactions on, PAMI- 1:224–227, May 1979
work page 1979
-
[6]
Rajesh Dwivedi, Aruna Tiwari, Neha Bharill, Milind Ratnaparkhe, and Alok Kumar Tiwari. A taxonomy of unsupervised feature selection methods including their pros, cons, and challenges.The Journal of Supercomputing, 80(16):24212–24240, November 2024
work page 2024
-
[7]
Feature Selection for Unsupervised Learning
Jennifer G Dy. Feature Selection for Unsupervised Learning
-
[8]
Christos Emmanouilidis, Andrew Hunter, and John Macintyre.A mul- tiobjective evolutionary setting for feature selection and a commonality- based crossover operator, volume 1. February 2000. Journal Abbrevia- tion: Proceedings of the 2000 Congress on Evolutionary Computation Pages: 316 vol.1 Publication Title: Proceedings of the 2000 Congress on Evolutiona...
work page 2000
-
[9]
ArturJ.FerreiraandMárioA.T.Figueiredo. Anunsupervisedapproach to feature discretization and selection.Pattern Recognition, 45(9):3048– 3060, September 2012
work page 2012
-
[10]
Comparison between Supervised and Unsupervised Feature Se- lection Methods:
Lilli Haar, Katharina Anding, Konstantin Trambitckii, and Gunther Notni. Comparison between Supervised and Unsupervised Feature Se- lection Methods:. InProceedings of the 8th International Conference on Pattern Recognition Applications and Methods, pages 582–589, Prague, Czech Republic, 2019. SCITEPRESS - Science and Technology Publi- cations. 20
work page 2019
-
[11]
Emrah Hancer, Bing Xue, Mengjie Zhang, Dervis Karaboga, and Bahriye Akay. Pareto front feature selection based on artificial bee colony optimization.Information Sciences, 422:462–479, January 2018
work page 2018
-
[12]
Julia Handl and Joshua Knowles. Feature Subset Selection in Unsuper- vised Learning via Multiobjective Optimization.International Journal of Computational Intelligence Research, 2(3), 2006
work page 2006
-
[13]
Laplacian Score for Fea- ture Selection
Xiaofei He, Deng Cai, and Partha Niyogi. Laplacian Score for Fea- ture Selection. InAdvances in Neural Information Processing Systems, volume 18. MIT Press, 2005
work page 2005
-
[14]
Ruwang Jiao, Bach Hoai Nguyen, Bing Xue, and Mengjie Zhang. A Survey on Evolutionary Multiobjective Feature Selection in Classifica- tion: Approaches, Applications, and Challenges.IEEE Transactions on Evolutionary Computation, 28(4):1156–1176, August 2024
work page 2024
-
[15]
Syn- thetic Data for Feature Selection, November 2022
Firuz Kamalov, Hana Sulieman, and Aswani Kumar Cherukuri. Syn- thetic Data for Feature Selection, November 2022. arXiv:2211.03035 [cs]
-
[16]
Evolutionary model selection in unsupervised learning.Intell
YongSeog Kim, Nick Street, and Filippo Menczer. Evolutionary model selection in unsupervised learning.Intell. Data Anal., 6:531–556, De- cember 2002
work page 2002
-
[17]
Joshua D. Knowles, Richard A. Watson, and David W. Corne. Reducing Local Optima in Single-Objective Problems by Multi-objectivization. In Eckart Zitzler, Lothar Thiele, Kalyanmoy Deb, Carlos Artemio Coello Coello, and David Corne, editors,Evolutionary Multi-Criterion Optimization, pages 269–283, Berlin, Heidelberg, 2001. Springer
work page 2001
-
[18]
Nikita Kozodoi, Stefan Lessmann, Konstantinos Papakonstantinou, Yiannis Gatsoulis, and Bart Baesens. A multi-objective approach for profit-driven feature selection in credit scoring.Decision Support Sys- tems, 120:106–117, May 2019
work page 2019
-
[19]
Xiaoliang Ma, Zhitao Huang, Xiaodong Li, Yutao Qi, Lei Wang, and Zexuan Zhu. Multiobjectivization of Single-Objective Optimization in Evolutionary Computation: A Survey.IEEE Transactions on Cyber- netics, 53(6):3702–3715, June 2023
work page 2023
-
[20]
Information preserving multi- objective feature selection for unsupervised learning
Ingo Mierswa and Michael Wurst. Information preserving multi- objective feature selection for unsupervised learning. InProceedings 21 of the 8th annual conference on Genetic and evolutionary computation, GECCO ’06, pages 1545–1552, New York, NY, USA, 2006. Association for Computing Machinery
work page 2006
-
[21]
Pabitra Mitra, Chaitra Murthy, and Sankar Pal. Unsupervised feature selection using feature similarity.Pattern Analysis and Machine Intel- ligence, IEEE Transactions on, 24:301–312, April 2002
work page 2002
-
[22]
Scikit-learn: Machine Learning in Python
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Andreas Müller, Joel Nothman, Gilles Louppe, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Courna- peau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine Learning...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Peter Rousseeuw. Rousseeuw, P.J.: Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. Comput. Appl. Math. 20, 53-65.Journal of Computational and Applied Mathematics, 20:53–65, November 1987
work page 1987
-
[24]
Hang Xu, Bing Xue, and Mengjie Zhang. Segmented initialization and offspring modification in evolutionary algorithms for bi-objective fea- ture selection. InProceedings of the 2020 Genetic and Evolutionary Computation Conference, GECCO ’20, pages 444–452, New York, NY, USA, 2020. Association for Computing Machinery
work page 2020
-
[25]
Bing Xue, Mengjie Zhang, and Will N. Browne. Particle Swarm Opti- mization for Feature Selection in Classification: A Multi-Objective Ap- proach.IEEE Transactions on Cybernetics, 43(6):1656–1671, December 2013. 22
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.