Embedding-Based Federated Learning with Runtime Governance for Iron Deficiency Prediction
Pith reviewed 2026-05-22 09:44 UTC · model grok-4.3
The pith
Personalised aggregation in an embedding-based federated pipeline raises iron deficiency prediction accuracy at both of two dissimilar clinical sites over local-only training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In two structurally non-IID clinical datasets that differ in iron deficiency prevalence, population characteristics, and sample size, an embedding-based federated pipeline with runtime governance produces higher prediction performance when updates are aggregated by a personalised method than when sites train independently or when updates are averaged by sample size.
What carries the argument
FedMAP personalised aggregation applied to the output of a frozen site-local DeepCBC embedding extractor, with governance supplied by a healthcare FL platform.
Load-bearing premise
The two clinical datasets differ because of genuine population differences rather than sampling variation, and the frozen embedding model supplies representations that let a small classifier suffice.
What would settle it
Re-running the identical pipeline on two new sites whose patient distributions match more closely would show whether the performance lift from personalised aggregation disappears.
Figures


read the original abstract
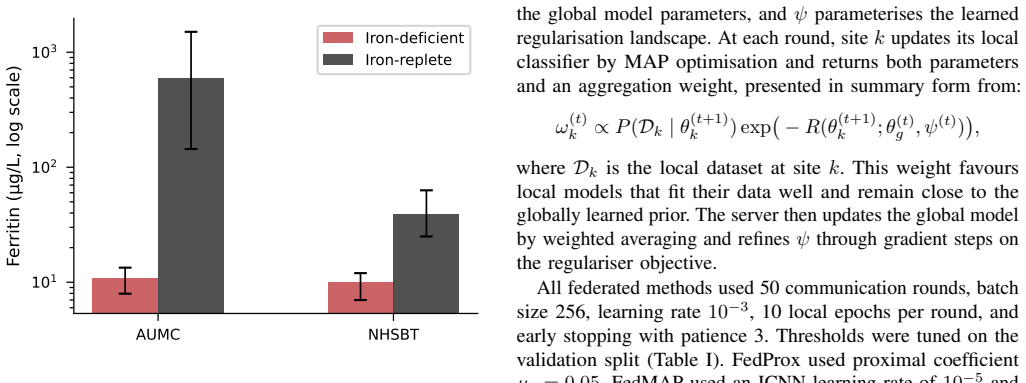
Recent reviews find that the vast majority of published healthcare federated learning (FL) studies never reach real-world deployment. We developed an embedding-based FL pipeline for iron deficiency prediction from routine full blood count (FBC) data and deployed it across real institutional environments at Amsterdam University Medical Centre (AUMC) and NHS Blood and Transplant (NHSBT), two clinical environments that differ markedly in iron deficiency prevalence, ferritin distribution, and subject populations. A frozen domain-specific haematology foundation model, DeepCBC, performs site-local representation extraction, restricting federated training to a compact downstream classifier and substantially reducing recurrent communication relative to full-encoder federation. The two clinical datasets are structurally not independent and identically distributed (non-IID), with heterogeneity arising from distinct population differences rather than sampling artefacts. Runtime governance is enforced by FLA$^3$, a healthcare-oriented FL platform providing study-scoped execution, policy-based authorisation, and signed audit logging. Standard sample-size-weighted aggregation (FedAvg) reduced the area under the receiver operating characteristic curve (ROC-AUC) at both sites relative to local-only training, as the global update was biased towards the larger AUMC distribution. FedMAP, a personalised aggregation method, raised ROC-AUC from 0.9470 to 0.9594 at AUMC and from 0.8558 to 0.8671 at NHSBT relative to local-only training, achieving the highest macro ROC-AUC of 0.9133 and the best macro balanced accuracy overall. These results support personalised aggregation in clinical federations where client sample size and task relevance diverge substantially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an embedding-based federated learning pipeline for iron deficiency prediction from routine full blood count data. A frozen DeepCBC haematology foundation model extracts site-local representations, after which a compact downstream classifier is trained via federated methods. The work deploys the system across two real clinical sites (AUMC and NHSBT) that exhibit structural non-IID heterogeneity, introduces the personalised aggregation method FedMAP, and enforces runtime governance through the FLA³ platform. Empirical results claim that FedMAP improves site-level ROC-AUC over local-only training (AUMC: 0.9594 vs 0.9470; NHSBT: 0.8671 vs 0.8558) and yields the highest macro ROC-AUC of 0.9133.
Significance. If the reported gains prove robust, the paper supplies a concrete, deployed example of federated learning in healthcare that combines reduced communication via frozen embeddings with governance mechanisms and personalised aggregation. This addresses a documented gap between published FL studies and real-world use, while demonstrating that sample-size-weighted aggregation can degrade performance when client distributions differ substantially in prevalence and size.
major comments (2)
- Results section (and abstract): The headline ROC-AUC improvements are reported as single point estimates (e.g., 0.9594 vs 0.9470 at AUMC) without standard deviations, confidence intervals, multiple random seeds, or hypothesis tests. Because the downstream classifier is compact and trained on embeddings, run-to-run variance from initialisation or mini-batch order can easily exceed the observed deltas of ~0.012; this directly undermines the load-bearing claim that FedMAP is superior in this non-IID clinical setting.
- Experimental setup: No details are provided on train/validation/test splits, cross-validation procedure, hyperparameter search, or cohort selection criteria. Without these, it is impossible to rule out selection effects or data leakage that could inflate the macro ROC-AUC of 0.9133 and the balanced-accuracy ranking.
minor comments (2)
- Abstract and §2: The acronym FLA³ is introduced without expansion on first use; a brief parenthetical definition would improve readability.
- Figure captions: Ensure all axes, legends, and error indicators (if added) are fully described so that the performance tables can be interpreted without reference to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for statistical rigor and experimental transparency. We address each major comment below and will revise the manuscript to incorporate additional analyses and details.
read point-by-point responses
-
Referee: Results section (and abstract): The headline ROC-AUC improvements are reported as single point estimates (e.g., 0.9594 vs 0.9470 at AUMC) without standard deviations, confidence intervals, multiple random seeds, or hypothesis tests. Because the downstream classifier is compact and trained on embeddings, run-to-run variance from initialisation or mini-batch order can easily exceed the observed deltas of ~0.012; this directly undermines the load-bearing claim that FedMAP is superior in this non-IID clinical setting.
Authors: We agree that single point estimates alone do not fully establish robustness, particularly given the potential for run-to-run variance in classifier training. The observed improvements are consistent in direction across both heterogeneous clinical sites and align with the rationale for personalised aggregation under structural non-IID conditions. In the revision we will conduct additional experiments using multiple random seeds, report standard deviations and confidence intervals for all ROC-AUC and balanced-accuracy metrics, and include appropriate statistical comparisons (e.g., paired tests) between FedMAP, local training, and FedAvg. These results will be added to the Results section and reflected in the abstract. revision: yes
-
Referee: Experimental setup: No details are provided on train/validation/test splits, cross-validation procedure, hyperparameter search, or cohort selection criteria. Without these, it is impossible to rule out selection effects or data leakage that could inflate the macro ROC-AUC of 0.9133 and the balanced-accuracy ranking.
Authors: We acknowledge that the current manuscript lacks sufficient description of the data partitioning and experimental protocol. In the revised version we will insert a new subsection detailing: cohort inclusion/exclusion criteria at each site, the train/validation/test split strategy (including any stratification by prevalence or demographics), whether cross-validation was employed, and the hyperparameter search procedure with ranges and selection method. This information will enable readers to assess reproducibility and potential biases without compromising patient privacy. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on real clinical data with no derivation chain or self-referential reductions.
full rationale
The manuscript presents an empirical federated learning study that trains and evaluates models on two distinct real-world clinical datasets (AUMC and NHSBT). Reported gains in ROC-AUC for FedMAP versus local-only training are obtained by direct measurement on site-specific test data after standard training procedures. No equations, uniqueness theorems, or ansatzes are invoked that would reduce the performance deltas to quantities defined by the paper's own fitted parameters or prior self-citations. The pipeline description (frozen DeepCBC embeddings, compact downstream classifier, FLA³ governance) consists of implementation choices whose validity is assessed externally via the observed metrics rather than by internal construction. This is the most common honest finding for applied ML papers that rely on held-out evaluation rather than mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The two clinical datasets are structurally non-IID due to distinct population differences rather than sampling artefacts
invented entities (2)
-
DeepCBC
no independent evidence
-
FLA³
no independent evidence
Reference graph
Works this paper leans on
-
[1]
W. G. Thompson, T. Meola, M. Lipkin, and M. L. Freedman, “Red cell distribution width, mean corpuscular volume, and transferrin saturation in the diagnosis of iron deficiency,”Archives of Internal Medicine, vol. 148, no. 10, pp. 2128–2130, 1988
work page 1988
-
[2]
P. R. Sarma, “Red cell indices,” inClinical Methods: The History, Physical, and Laboratory Examinations, 3rd ed., H. K. Walker, W. D. Hall, and J. W. Hurst, Eds. Boston: Butterworths, 1990, ch. 152
work page 1990
-
[3]
S. Kurstjens, I. Belov, W. de Kort, M. van de Schootbrugge, W. Oost- erhuis, and J. A. van Balveren, “Automated prediction of low ferritin concentrations using a machine learning algorithm based on routine laboratory test results,”Clinical Chemistry and Laboratory Medicine (CCLM), vol. 60, no. 7, pp. e173–e176, 2022
work page 2022
-
[4]
D. Kreuteret al., “Artificial intelligence for pre-anaemic iron deficiency detection using rich complete blood count data,”medRxiv, 2025. [Online]. Available: https://www.medrxiv.org/content/early/2025/06/24/ 2025.06.18.25329494
work page 2025
-
[5]
M. J. Shelleret al., “Federated learning in medicine: facilitating multi- institutional collaborations without sharing patient data,”Scientific Reports, vol. 10, no. 1, p. 12598, 2020
work page 2020
-
[6]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), ser. Proceedings of Machine Learning Research, vol. 54, 2017, pp. 1273–1282
work page 2017
-
[7]
The future of digital health with federated learning,
N. Riekeet al., “The future of digital health with federated learning,” npj Digital Medicine, vol. 3, no. 1, p. 119, 2020
work page 2020
-
[8]
M. Li, P. Xu, J. Hu, Z. Tang, and G. Yang, “From challenges and pitfalls to recommendations and opportunities: Implementing federated learning in healthcare,”Medical Image Analysis, vol. 101, p. 103497,
-
[9]
Available: https://www.sciencedirect.com/science/article/ pii/S1361841525000453
[Online]. Available: https://www.sciencedirect.com/science/article/ pii/S1361841525000453
-
[10]
Recent methodological advances in federated learning for healthcare,
F. Zhanget al., “Recent methodological advances in federated learning for healthcare,”Patterns, vol. 5, no. 6, p. 101006, Jun. 2024
work page 2024
-
[11]
F. Zhanget al., “Building privacy-and-security-focused federated learning infrastructure for global multi-centre healthcare research,”arXiv preprint arXiv:2603.10063, 2026
-
[12]
Z. L. Teoet al., “Federated machine learning in healthcare: A systematic review on clinical applications and technical architecture,”Cell Reports Medicine, vol. 5, no. 2, p. 101419, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2666379124000429
work page 2024
-
[13]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProceedings of Machine Learning and Systems, vol. 2, 2020, pp. 429–450
work page 2020
-
[14]
FedMAP: Personalised federated learning for real large-scale healthcare systems,
F. Zhanget al., “FedMAP: Personalised federated learning for real large-scale healthcare systems,” 2025. [Online]. Available: https://arxiv.org/abs/2405.19000
-
[15]
A. Vaidet al., “Federated learning of electronic health records to improve mortality prediction in hospitalized patients with covid-19: Machine learning approach,”JMIR Medical Informatics, vol. 9, no. 1, p. e24207, 2021
work page 2021
-
[16]
Swarm learning for decentralized and confidential clinical machine learning,
S. Warnat-Herresthalet al., “Swarm learning for decentralized and confidential clinical machine learning,”Nature, vol. 594, no. 7862, pp. 265–270, 2021
work page 2021
-
[17]
S. Malaviya, M. Shukla, and S. Lodha, “Reducing communication overhead in federated learning for pre-trained language models using parameter-efficient finetuning,” inProceedings of The 2nd Conference on Lifelong Learning Agents, ser. Proceedings of Machine Learning Research, S. Chandar, R. Pascanu, H. Sedghi, and D. Precup, Eds., vol. 232. PMLR, 22–25 Aug...
work page 2023
-
[18]
E. Di Angelantonioet al., “Efficiency and safety of varying the frequency of whole blood donation (interval): a randomised trial of 45 000 donors,” The Lancet, vol. 390, no. 10110, pp. 2360–2371, November 2017. [Online]. Available: http://dx.doi.org/10.1016/S0140-6736(17)31928-1
-
[19]
S. Kaptogeet al., “Longer-term efficiency and safety of increasing the frequency of whole blood donation (INTERV AL): extension study of a randomised trial of 20 757 blood donors,”The Lancet Haematology, vol. 6, no. 10, pp. e510–e520, Oct. 2019, publisher: Elsevier. [Online]. Available: https://www.thelancet.com/journals/lanhae/ article/PIIS2352-3026(19)3...
work page 2019
-
[20]
WHO Guidelines Approved by the Guidelines Review Committee
World Health Organisation,WHO Guideline on Use of Ferritin Concentrations to Assess Iron Status in Individuals and Populations, ser. WHO Guidelines Approved by the Guidelines Review Committee. Geneva: World Health Organization, 2020. [Online]. Available: http://www.ncbi.nlm.nih.gov/books/NBK569880/
work page 2020
-
[21]
Flower: A Friendly Federated Learning Research Framework
D. J. Beutelet al., “Flower: A friendly federated learning research framework,” 2020. [Online]. Available: https://arxiv.org/abs/2007.14390
work page internal anchor Pith review arXiv 2020
-
[22]
A. Fletcher, A. Forbes, N. Svenson, and D. W. Thomas, “Guideline for the laboratory diagnosis of iron deficiency in adults (excluding pregnancy) and children,”British Journal of Haematology, vol. 196, no. 3, pp. 523–529, 2022, a British Society for Haematology Good Practice Paper. [Online]. Available: https://onlinelibrary.wiley.com/doi/ abs/10.1111/bjh.17900
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.