ARC-STAR: Auditable Post-Hoc Correction for PDE Foundation Models
Pith reviewed 2026-05-22 07:10 UTC · model grok-4.3
The pith
ARC-STAR corrects pretrained PDE foundation models after training by routing refinement only to high-risk spatial blocks while keeping the solver frozen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
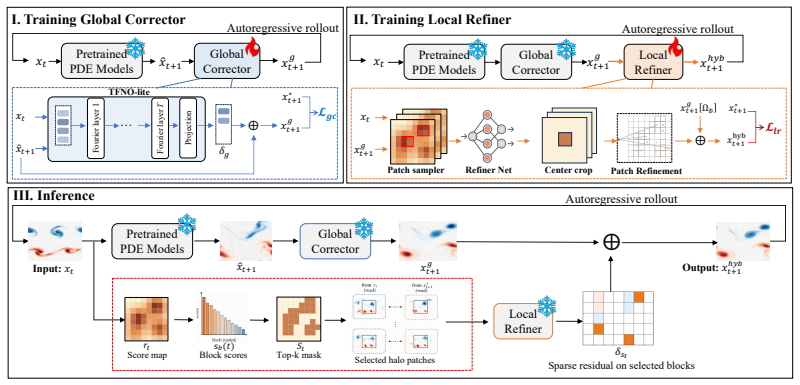
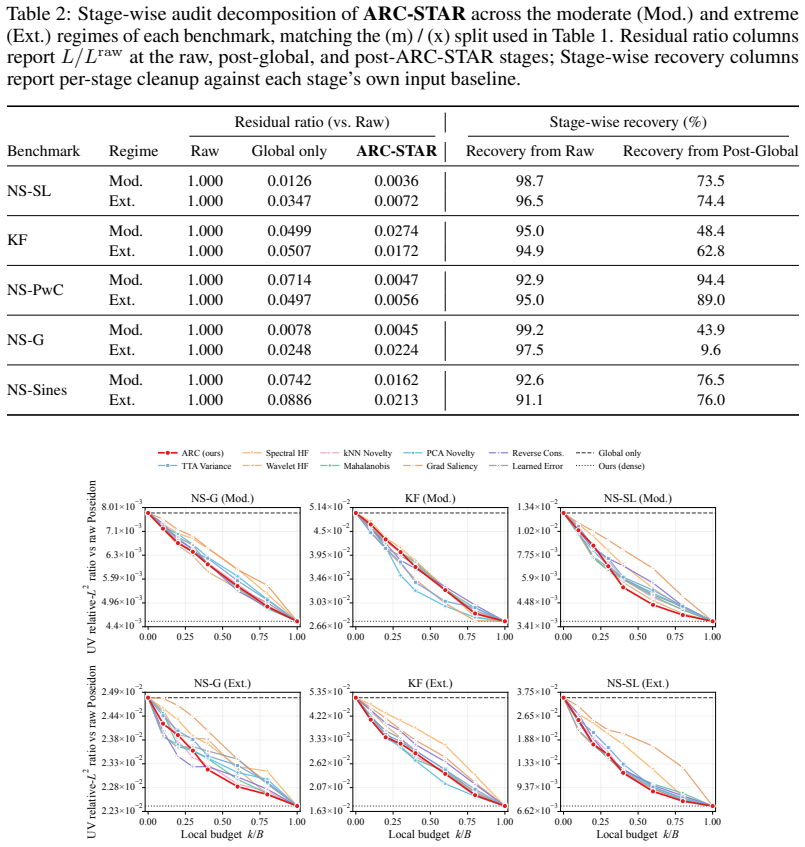
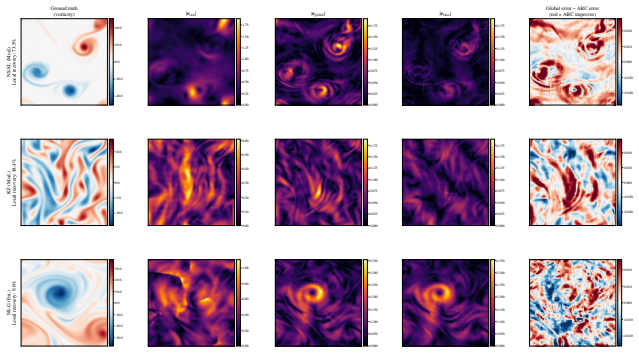
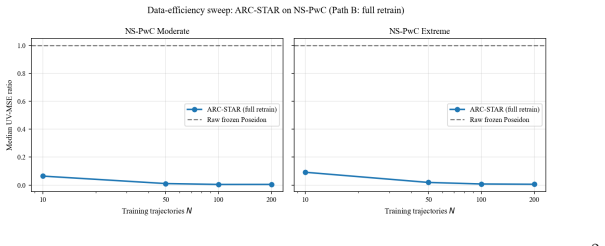
ARC-STAR organizes correction into three stages: a global corrector removes broad solver bias, a blockwise local refiner cleans the post-global residual, and a label-free score routes refinement to high-risk blocks under a compute budget. The framework is frozen-host, auditable, and budget-aware. Across five flow benchmarks spanning ten regime cells, it is the only method that cuts velocity rollout error by at least 36x over raw Poseidon on every cell, with the global stage reducing raw host error by 91-99% and the local stage further reducing the remaining residual by up to 94.4%.
What carries the argument
The ARC-STAR three-stage pipeline that separates global bias removal from blockwise local refinement and uses a label-free risk score to allocate refinement under a budget.
If this is right
- The global corrector alone removes 91-99% of the raw host error.
- The local refiner can cut up to 94.4% of whatever residual error remains after the global stage.
- The full reduction of at least 36x holds on every one of the ten regime cells across five benchmarks.
- The original pretrained solver stays frozen and stable throughout correction.
- Each stage can be trained and evaluated separately, making contributions measurable.
Where Pith is reading between the lines
- The same blockwise triage could be tested on pretrained models for other time-dependent simulations where errors also localize spatially.
- If the label-free risk score generalizes, it might reduce full-field correction costs in other sequential prediction settings that face compute limits.
- The auditable separation of stages could support verification requirements in applications where corrections must be inspected before use.
Load-bearing premise
Prediction errors concentrate in identifiable spatial blocks that a label-free risk score can reliably detect without ground-truth labels or destabilizing the frozen pretrained solver.
What would settle it
A flow regime in which errors spread uniformly across the domain rather than clustering in blocks, or in which the label-free risk score consistently selects regions whose actual error does not exceed the rest of the field on unseen data, would undermine the triage mechanism.
Figures





read the original abstract
Partial differential equation (PDE) foundation models are pretrained networks that forecast how physical fields like velocity and pressure evolve from a single reusable solver. On unfamiliar flows their predictions drift step by step, errors concentrate in a few regions, yet retraining destabilizes the network and uniform post-hoc correction overlooks this spatial concentration. To address this, we propose a frozen-solver post-hoc correction framework, Adaptive Risk-Calibrated Spatial Triage for Auditable Refinement (ARC-STAR). ARC-STAR organizes correction into three stages: a global corrector removes broad solver bias, a blockwise local refiner cleans the post-global residual, and, at deployment, a label-free score routes refinement to high-risk blocks under a compute budget. The framework is designed to be (i) frozen-host, preserving the pretrained solver without fine-tuning; (ii) auditable, with global and local stages trained and evaluated separately for measurable contributions; and (iii) budget-aware, using a blockwise interface that either refines the full field or routes limited compute to high-risk regions. Across five flow benchmarks spanning ten regime cells, ARC-STAR is the only method that cuts velocity rollout error by at least 36x over raw Poseidon on every cell. The global stage reduces raw host error by 91-99%, and the local stage further reduces the remaining post-global residual by up to 94.4%. Our code implementation is available at https://anonymous.4open.science/r/arc_star.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ARC-STAR, a frozen-solver post-hoc correction framework for PDE foundation models. It decomposes correction into a global corrector that removes broad solver bias, a blockwise local refiner that addresses post-global residuals, and a label-free risk score that routes limited compute to high-risk blocks at deployment. The framework is evaluated on five flow benchmarks spanning ten regime cells and claims to be the only method achieving at least a 36x reduction in velocity rollout error relative to raw Poseidon on every cell, with the global stage reducing raw host error by 91-99% and the local stage reducing the remaining residual by up to 94.4%. The design emphasizes auditability through separately trained and evaluated stages and budget awareness via the blockwise interface.
Significance. If the reported error reductions are supported by detailed per-cell baselines, statistical tests, and explicit validation of the label-free routing, the work would offer a practical, auditable alternative to retraining or uniform correction for improving out-of-distribution performance of PDE foundation models. The separate staging for measurability and the public code release are clear strengths that aid reproducibility and community verification.
major comments (2)
- [§3.3] §3.3 (Routing mechanism): The central claim that selective refinement under a compute budget delivers the 36x velocity error reduction on every cell rests on the label-free risk score correctly identifying spatially concentrated error blocks. The manuscript should report the correlation (e.g., Spearman or Pearson) between the risk score and ground-truth per-block rollout error on held-out regime cells, together with the fraction of high-error blocks that would be missed under the chosen budget threshold. Absent this, the contribution of the local stage to the headline gains cannot be isolated from uniform refinement.
- [Table 2] Table 2 or main results table (per-cell breakdown): The statement that ARC-STAR is the only method achieving at least 36x reduction 'on every cell' requires explicit per-cell velocity rollout errors for raw Poseidon, global-only, local-only, and full ARC-STAR (plus competing post-hoc baselines). Aggregate or best-case reporting leaves open whether the minimum factor holds uniformly or is driven by a subset of the ten regime cells.
minor comments (2)
- [Abstract] Abstract: Specify the precise rollout error metric (e.g., relative L2 norm averaged over 50 steps) and name the full set of baselines used to support the 'only method' claim.
- [§4] §4 (Experimental setup): Clarify the data splits, number of random seeds, and statistical test used for the 91-99% and 94.4% figures so that the numerical claims can be reproduced from the released code.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to strengthen the empirical support for our claims. We respond to each major comment below and indicate the specific revisions we will make.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Routing mechanism): The central claim that selective refinement under a compute budget delivers the 36x velocity error reduction on every cell rests on the label-free risk score correctly identifying spatially concentrated error blocks. The manuscript should report the correlation (e.g., Spearman or Pearson) between the risk score and ground-truth per-block rollout error on held-out regime cells, together with the fraction of high-error blocks that would be missed under the chosen budget threshold. Absent this, the contribution of the local stage to the headline gains cannot be isolated from uniform refinement.
Authors: We agree that an explicit correlation analysis would help isolate the local stage's contribution from uniform refinement. In the revised manuscript we will add to §3.3 the Spearman rank correlation between the label-free risk score and ground-truth per-block rollout error on the held-out regime cells, together with the fraction of high-error blocks missed at the operating budget threshold. These quantities will be computed using the same evaluation splits and error metric as the main results. revision: yes
-
Referee: [Table 2] Table 2 or main results table (per-cell breakdown): The statement that ARC-STAR is the only method achieving at least 36x reduction 'on every cell' requires explicit per-cell velocity rollout errors for raw Poseidon, global-only, local-only, and full ARC-STAR (plus competing post-hoc baselines). Aggregate or best-case reporting leaves open whether the minimum factor holds uniformly or is driven by a subset of the ten regime cells.
Authors: We acknowledge that aggregate reporting leaves the uniformity of the 36x claim open to question. We will revise Table 2 (or add a dedicated supplementary table if length constraints apply) to list the velocity rollout error for each of the ten regime cells under raw Poseidon, global-only, local-only, full ARC-STAR, and all competing post-hoc baselines. This will allow direct verification that the minimum 36x factor is attained on every cell. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical post-hoc correction framework with separately trained global and local stages whose contributions are measured on benchmarks. No equations, derivations, or self-referential definitions appear that reduce the reported error reductions (36x, 91-99%, 94.4%) to quantities defined by fitted parameters or prior self-citations. The label-free routing score is presented as a design choice evaluated empirically rather than derived from the target metrics by construction. The central claims rest on experimental results across ten regime cells rather than any load-bearing self-citation chain or ansatz smuggled via prior work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ARC-STAR organizes correction into three stages: a global corrector removes broad solver bias, a blockwise local refiner cleans the post-global residual, and, at deployment, a label-free score routes refinement to high-risk blocks under a compute budget.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each cell is partitioned into 64 blocks of 16×16 pixels; tile color is per-block error share
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.