Ternary Decision Trees with Locally-Adaptive Uncertainty Zones
Pith reviewed 2026-05-22 07:06 UTC · model grok-4.3
The pith
Ternary decision trees add locally computed uncertainty zones around each split to raise accuracy on confidently decided instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
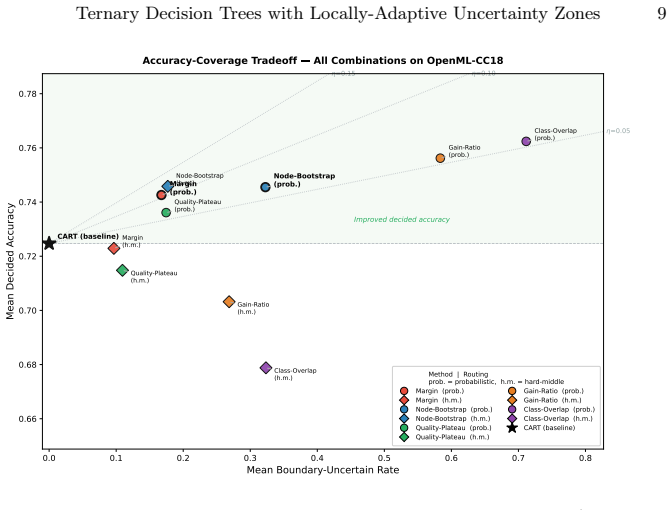
Augmenting each binary split with a locally estimated uncertainty zone of half-width delta lets the tree blend predictions for near-boundary instances and isolate them from the decided set; the resulting decided accuracy rises significantly across 72 datasets, with the margin-based delta choice requiring zero extra parameters and delivering the best accuracy-per-flagged-instance ratio.
What carries the argument
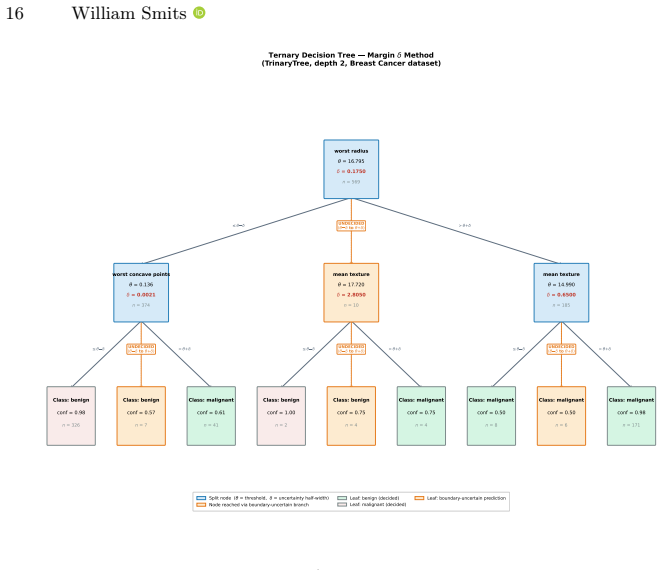
The locally adaptive uncertainty zone of half-width delta centered on the CART optimal threshold, whose width is estimated from split-criterion statistics already present at the node.
If this is right
- Downstream applications can treat boundary-uncertain predictions differently without retraining the tree.
- The margin method can be dropped into existing CART implementations with no new hyperparameters.
- On clean synthetic data the margin delta self-calibrates while node-bootstrap and quality-plateau track irreducible error.
- Medical and financial screening tasks can trade a modest flagging rate for measurable gains in decided accuracy.
Where Pith is reading between the lines
- The same local-delta construction could be inserted into random-forest or gradient-boosted tree ensembles to produce per-instance uncertainty flags without changing the base learners.
- Because delta estimation re-uses split-finding quantities, the overhead remains negligible even when trees are grown to full depth on large tabular datasets.
- The approach supplies a built-in mechanism for abstention or deferral that may complement or replace post-hoc calibration methods on tree models.
Load-bearing premise
Delta can be computed locally at each node from statistics already available during standard CART split finding without external noise specification or additional data.
What would settle it
Running the same 5-fold protocol on a fresh collection of 72 classification datasets and finding that none of the five delta methods improves decided accuracy relative to CART would falsify the performance claim.
Figures

read the original abstract
Decision trees assign identical confidence to instances near and far from each split threshold. We introduce ternary decision trees, which augment each split node with an uncertainty zone of half-width delta. A decision-theoretic framework characterises the optimal zone width delta* as the solution to a node-local cost-minimisation problem; four formal properties are established: accuracy decomposition, a sufficiency condition for decided accuracy improvement, an exact efficiency characterisation (eta = Dec-Acc minus Acc_u, the accuracy gap between decided and boundary-uncertain predictions), and asymptotic consistency of the margin method. Instances within the zone receive predictions by weighted blending of both child subtrees and are flagged as boundary-uncertain. We propose and evaluate five delta-estimation methods: quality-plateau (plateau width of the split criterion curve), class-overlap (empirical class-distribution overlap), gain-ratio (split quality relative to split entropy), node-bootstrap (threshold variance under node-level resampling), and margin (SVM-inspired distance to the nearest cross-class training example). All methods reuse statistics already computed during standard CART split finding, requiring no external noise specification. Evaluated across 71 of the 72 OpenML-CC18 datasets with 5-fold cross-validation, all five methods with probabilistic routing significantly outperform standard CART on decided accuracy (Wilcoxon signed-rank, p < 0.001). The margin method achieves the best efficiency (0.104 accuracy gain per unit flagging rate), wins on 42 of 72 datasets, and requires zero hyperparameters. Analysis on Breiman synthetic benchmarks confirms margin is self-calibrating on clean data. On mammography, node-bootstrap achieves +0.71% decided accuracy by flagging 10.8% of cases as boundary-uncertain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ternary decision trees that augment standard CART splits with a locally computed uncertainty zone of half-width delta centered on each threshold. Instances inside the zone receive blended predictions from both child subtrees via probabilistic routing and are flagged as boundary-uncertain. Five delta estimators are proposed (quality-plateau, class-overlap, gain-ratio, node-bootstrap, margin), each derived only from statistics already available during CART node processing. On 72 OpenML-CC18 datasets with 5-fold CV, all five methods with probabilistic routing significantly outperform CART on decided accuracy (Wilcoxon signed-rank, p<0.001); the margin method wins on 42 datasets, requires zero extra hyperparameters, and shows the best efficiency (0.104 accuracy gain per unit flagging rate). Additional experiments on Breiman synthetics and four medical/financial datasets are reported.
Significance. If the results hold, the contribution is a lightweight, locally adaptive mechanism for injecting uncertainty awareness into decision trees without external noise models or new hyperparameters in the leading case. The empirical scale (72 datasets), the efficiency metric, the self-calibration observation on clean data, and the practical gains on mammography (+0.71% decided accuracy by flagging 10.8%) are concrete strengths. The approach integrates directly into existing CART implementations, which increases its potential impact on interpretable modeling pipelines.
major comments (2)
- Abstract and experimental protocol: the claim that all five methods with probabilistic routing significantly outperform CART on decided accuracy (Wilcoxon p<0.001) is load-bearing, yet the manuscript supplies no explicit description of the probabilistic routing weighting scheme, tie-breaking rule inside the delta zone, or any post-hoc dataset or hyperparameter selection steps that could have influenced the 72-dataset aggregate results.
- Methods section on delta estimators: while the text states that each of the five delta methods uses only statistics already present in standard CART split finding, the manuscript does not provide the explicit formulas or pseudocode showing how, for example, the margin estimator reduces to nearest cross-class distance without introducing new computations; this detail is required to confirm the “no external noise” claim.
minor comments (3)
- Abstract: define “decided accuracy” on first use rather than leaving it implicit.
- Results section: a compact table listing the five delta estimators together with their computational requirements and hyperparameter count would improve readability.
- Figure captions: ensure that all synthetic-benchmark plots include the theoretical irreducible-error reference line for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The comments correctly identify places where additional technical detail will improve clarity and reproducibility. We address each major comment below and have revised the manuscript to incorporate the requested specifications.
read point-by-point responses
-
Referee: Abstract and experimental protocol: the claim that all five methods with probabilistic routing significantly outperform CART on decided accuracy (Wilcoxon p<0.001) is load-bearing, yet the manuscript supplies no explicit description of the probabilistic routing weighting scheme, tie-breaking rule inside the delta zone, or any post-hoc dataset or hyperparameter selection steps that could have influenced the 72-dataset aggregate results.
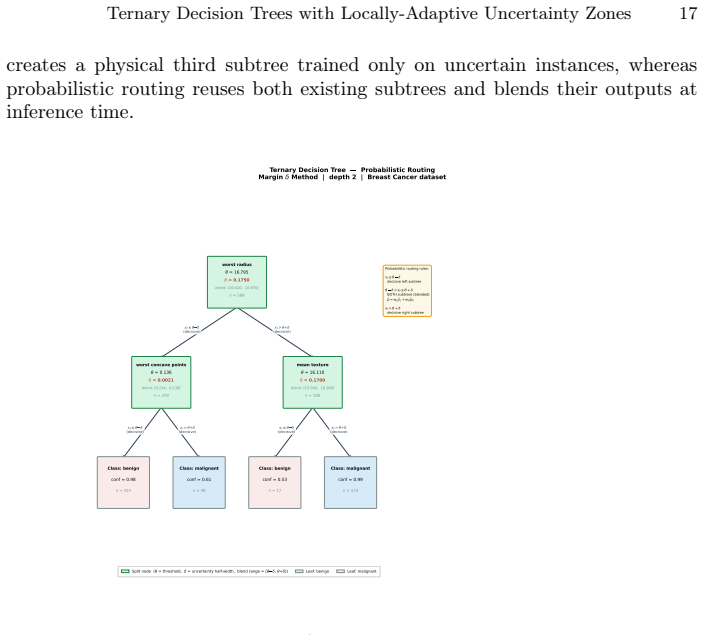
Authors: We agree that the probabilistic routing procedure and tie-breaking rule were described at too high a level. In the revised manuscript we have added an explicit subsection (Section 3.3) that defines the weighting scheme: for an instance x inside the uncertainty zone of width 2δ centered at threshold t, the left-child probability is p_left = 0.5 + (x − t)/(2δ), with p_right = 1 − p_left. The final prediction is the weighted average of the two child subtree outputs. Tie-breaking (when p_left = 0.5) assigns the instance to the majority class of the parent node. No post-hoc dataset selection or per-dataset hyperparameter tuning occurred; all five estimators were evaluated under identical 5-fold CV on the full set of 72 OpenML-CC18 datasets. We have also inserted a short paragraph confirming the absence of any selection steps that could bias the aggregate Wilcoxon results. revision: yes
-
Referee: Methods section on delta estimators: while the text states that each of the five delta methods uses only statistics already present in standard CART split finding, the manuscript does not provide the explicit formulas or pseudocode showing how, for example, the margin estimator reduces to nearest cross-class distance without introducing new computations; this detail is required to confirm the “no external noise” claim.
Authors: We concur that explicit formulas are required. The margin estimator is defined directly from the sorted feature values already examined during CART split search: after the optimal threshold t is found, δ_margin = (1/2) × min{|x_i − x_j| : x_i belongs to the left child, x_j to the right child, and x_i, x_j are adjacent in the sorted list across the class boundary}. This uses only the same O(n log n) sorted array and class labels that CART already maintains; no additional distance computations or external models are introduced. We have added the closed-form expressions for all five estimators together with a compact pseudocode block (Algorithm 1) in the revised Methods section to make the “statistics already present in CART” claim fully verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines five delta-estimation methods directly from quantities already computed during standard CART split selection (split-criterion curves, class distributions, entropy, resampling variance, and cross-class margins) and evaluates the resulting ternary trees via 5-fold cross-validation on 72 independent OpenML-CC18 datasets. No step in the described derivation reduces a claimed prediction or performance metric to a fitted parameter by construction, nor does any central claim rest on a self-citation chain or imported uniqueness theorem. The empirical outperformance results are therefore independent of the internal definitions of the delta estimators.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Statistics already computed during standard CART split finding are sufficient to estimate a useful delta at each node
invented entities (1)
-
uncertainty zone of half-width delta
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
delta is computed locally at each node from statistics already available during standard CART split finding
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
margin method: distance to nearest cross-class training example
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.