Is TabPFN the Silver Bullet for Insurance Pricing?
Pith reviewed 2026-05-25 02:39 UTC · model grok-4.3
The pith
TabPFN does not consistently outperform GLM and XGBoost for motor insurance pricing and shows longer inference times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
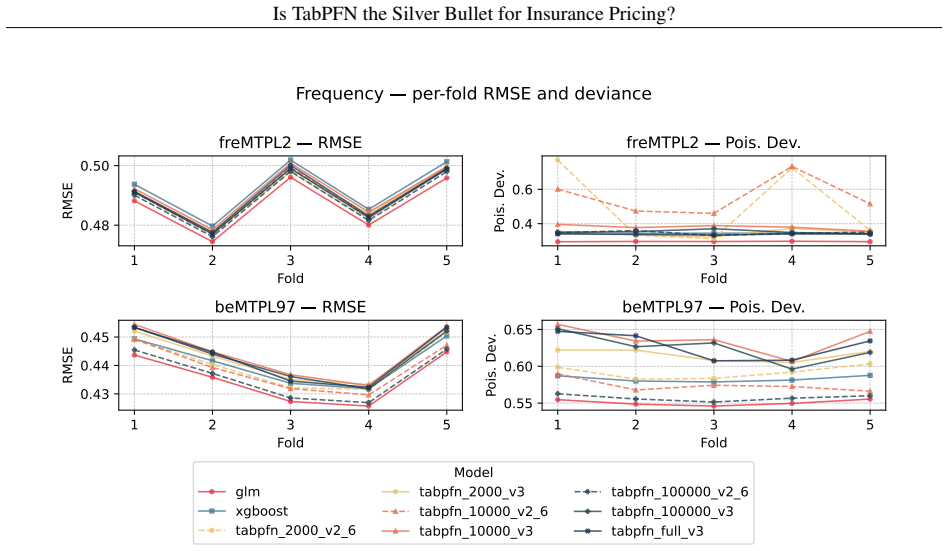
When applied to two public MTPL datasets via in-context learning, TabPFN does not consistently beat GLM or XGBoost in predictive performance for non-life insurance pricing, while incurring substantially longer inference times and exhibiting sensitivity to the size of the in-context training set. The authors conclude that tabular foundation models in their present form do not offer a viable replacement for established actuarial methods such as generalised linear models.
What carries the argument
TabPFN's in-context learning on pre-trained synthetic tabular data, which enables task inference without dataset-specific fitting or hyperparameter tuning.
Load-bearing premise
The two public MTPL datasets and the chosen in-context learning protocol are representative enough to support general conclusions about TabPFN for non-life insurance pricing.
What would settle it
TabPFN showing consistent outperformance over both GLM and XGBoost on several additional, diverse insurance datasets while matching their inference times would falsify the central claim.
Figures


read the original abstract
Modelling claim frequency and severity for non-life insurance pricing predominantly relies on generalised linear models, with gradient-boosted machines as the leading machine learning alternative. Tabular foundation models (TFMs) present a fundamentally different inference paradigm. By pre-training on large collections of synthetic datasets, TFMs enable inference on new data through in-context learning, without any dataset-specific fitting or hyperparameter tuning. This paper presents a first empirical evaluation of TabPFN for motor insurance pricing, benchmarking it against GLM and XGBoost on two publicly available MTPL datasets. Our results show that TabPFN does not consistently outperform established baselines, exhibits substantially longer inference times, and is sensitive to the size of the in-context training set. While tabular foundation models represent a promising direction, particularly in data-scarce settings, their current performance does not offer a viable replacement for established actuarial methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first empirical evaluation of TabPFN, a tabular foundation model using in-context learning, for motor third-party liability (MTPL) insurance pricing. It benchmarks TabPFN against GLM and XGBoost on two publicly available datasets, reporting that TabPFN does not consistently outperform the baselines, exhibits substantially longer inference times, and is sensitive to the size of the in-context training set. The authors conclude that while TFMs are promising in data-scarce settings, their current formulation does not offer a viable replacement for established actuarial methods.
Significance. If the empirical results are robust, the work supplies a useful negative benchmark on public data that tempers enthusiasm for immediate adoption of current tabular foundation models in non-life pricing. The explicit comparison of inference cost and context-size sensitivity, together with the use of held-out public datasets, provides concrete guidance for future TFM development in actuarial applications.
major comments (3)
- [Abstract and §5 (Conclusion)] The generalization that TabPFN 'does not offer a viable replacement for established actuarial methods' rests on results from only two MTPL datasets under a single in-context protocol. The manuscript should either restrict the claim to the tested setting or supply additional evidence (e.g., results on other lines of business or alternative protocols) that these cases are representative; otherwise the central negative conclusion is under-supported.
- [§4 (Experiments)] §4 (Experiments): the benchmark tables and figures report point estimates without error bars, standard deviations across random seeds, or statistical significance tests. Given the paper's own finding that performance is sensitive to in-context training-set size, the absence of variability measures makes it impossible to judge whether observed differences versus GLM and XGBoost are reliable.
- [§3 (Methodology)] §3 (Methodology): the in-context learning protocol is described at a high level but omits concrete details on feature encoding (especially exposure and categorical insurance variables), the precise construction of the in-context set, and any preprocessing steps. These choices are load-bearing for reproducing the reported sensitivity and inference-time results.
minor comments (2)
- [Tables 1–3] Table captions and axis labels should explicitly state the performance metric (e.g., Poisson deviance, Gini coefficient) and the exact context size used for each TabPFN entry.
- [Abstract and §4] The abstract states 'substantially longer inference times' without quantifying the factor or hardware; a short table or sentence in §4 giving wall-clock times per prediction would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §5 (Conclusion)] The generalization that TabPFN 'does not offer a viable replacement for established actuarial methods' rests on results from only two MTPL datasets under a single in-context protocol. The manuscript should either restrict the claim to the tested setting or supply additional evidence (e.g., results on other lines of business or alternative protocols) that these cases are representative; otherwise the central negative conclusion is under-supported.
Authors: We agree that the central conclusion is based solely on the two MTPL datasets and the single in-context protocol examined. We will revise the abstract and §5 to explicitly restrict the claim to these tested settings and datasets, while noting that broader applicability to other lines of business would require additional evaluation. We are not in a position to supply results on further datasets or protocols in the current revision. revision: partial
-
Referee: [§4 (Experiments)] §4 (Experiments): the benchmark tables and figures report point estimates without error bars, standard deviations across random seeds, or statistical significance tests. Given the paper's own finding that performance is sensitive to in-context training-set size, the absence of variability measures makes it impossible to judge whether observed differences versus GLM and XGBoost are reliable.
Authors: We accept this criticism. In the revised version we will report standard deviations across multiple random seeds for the in-context sets in all tables and figures, and we will add statistical significance tests comparing TabPFN to the baselines to allow readers to assess the reliability of the differences. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): the in-context learning protocol is described at a high level but omits concrete details on feature encoding (especially exposure and categorical insurance variables), the precise construction of the in-context set, and any preprocessing steps. These choices are load-bearing for reproducing the reported sensitivity and inference-time results.
Authors: We will expand the methodology section to include the missing details: the exact encoding of exposure and categorical variables, the sampling procedure and size selection for the in-context set, and all preprocessing steps applied to the two datasets. revision: yes
Circularity Check
No circularity: pure empirical benchmarking on held-out data
full rationale
The paper performs a direct empirical comparison of TabPFN against GLM and XGBoost baselines on two fixed public MTPL datasets using a stated in-context protocol. No derivations, parameter fits renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes are present in the central claims. Results are reported from held-out evaluation without any reduction of outputs to inputs by construction, rendering the analysis self-contained.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.