FIRMA: FIbonacci Ring Model Aggregation for Privacy-preserving Federated Learning
Pith reviewed 2026-05-25 05:29 UTC · model grok-4.3
The pith
A Fibonacci-weighted ring aggregation protocol enables server-free federated learning with permanently private classification heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
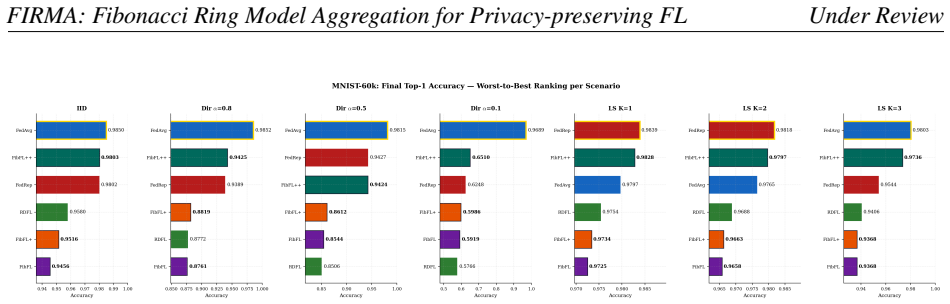
FIRMA shows that server-free ring aggregation using Fibonacci directional bias, combined with accuracy-gated suppression and 2-opt ring permutation for diversity, produces a protocol that satisfies a convergence bound and delivers higher accuracy than FedAvg in all twelve label-skew configurations, with the largest gain of 20.7 percentage points on CIFAR-10 at K=1, while remaining Pareto-dominant among server-free approaches under Dirichlet heterogeneity.
What carries the argument
The fibflpp protocol, which blends models along a ring using Fibonacci weights, accuracy gating, 2-opt permutation, and multiple gossip passes to achieve coverage and retention.
If this is right
- The protocol satisfies a proven convergence rate bound.
- Classification heads remain permanently private from all other clients.
- Global coverage is obtained through ceiling of N over 2 gossip passes.
- The method is Pareto-dominant among server-free protocols in 17 of 28 total configurations.
Where Pith is reading between the lines
- The same directional bias and gating logic could be tested on non-ring communication graphs.
- The privacy guarantee might extend to additional layers if the same suppression rule is applied.
- Larger client counts could be examined to check whether the N/2 coverage rule remains efficient.
Load-bearing premise
The Fibonacci directional bias combined with accuracy-gated suppression and 2-opt ring permutation will preserve both convergence guarantees and permanent head privacy without introducing new leakage vectors or convergence failures under the tested heterogeneity regimes.
What would settle it
A run on one of the twelve label-skew configurations in which fibflpp accuracy falls below FedAvg or any peer obtains information about another client's classification head.
Figures













read the original abstract
Federated learning protocols face a structural trilemma: canonical server-based aggregation~\cite{mcmahan2017} creates a single point of failure and gradient inversion risk; decentralised ring-gossip alternatives~\cite{hu2019segmented} expose classification heads to semi-honest peers via uninformed uniform weights; and personalised methods~\cite{collins2021exploiting} reintroduce central aggregation. No existing protocol simultaneously achieves server-free operation, permanently private heads, ring topology, and principled asymmetric neighbour weighting. We propose FIRMA (\textbf{FI}bonacci \textbf{R}ing \textbf{M}odel \textbf{A}ggregation), a family of three progressively enhanced federated learning protocols: 1) \fibfl\ establishes the foundation: server-free ring aggregation with Fibonacci-weighted neighbour blending and permanently private classification heads. 2) \fibflp\ augments this with accuracy-gated neighbour suppression, selectively down-weighting poorly-converged peers while preserving the Fibonacci directional bias. 3) \fibflpp, the full system, completes the family with a 2-opt ring permutation that maximises adjacent-client class diversity, global ring coverage via $K_g{=}\lceil N/2\rceil$ gossip passes, and cosine-annealed self-retention calibration. We establish a convergence rate bound and three supporting propositions governing normalisation, coverage, retention, and diversity optimality. Systematic experiments across 28 configurations -- four benchmarks crossed with seven heterogeneity regimes -- demonstrate that \fibflpp\ surpasses \fedavg\ in all 12 label-skew configurations, with a peak advantage of $+20.7$\,pp on CIFAR-10 at $K{=}1$. Under Dirichlet heterogeneity, \fibflpp\ is the Pareto-dominant method among all server-free protocols, achieving the highest accuracy in 17 of 28 configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FIRMA, a family of three progressively enhanced server-free federated learning protocols (fibfl, fibflp, fibflpp) using Fibonacci-weighted ring aggregation to achieve server-free operation, permanently private classification heads, ring topology, and asymmetric neighbour weighting. It claims to establish a convergence rate bound along with three supporting propositions on normalisation, coverage, retention, and diversity optimality. Experiments across 28 configurations (four benchmarks with seven heterogeneity regimes) report that fibflpp outperforms FedAvg in all 12 label-skew settings (peak +20.7 pp on CIFAR-10 at K=1) and is Pareto-dominant among server-free protocols under Dirichlet heterogeneity.
Significance. If the stated convergence bound holds under the claimed conditions and the empirical Pareto dominance is reproducible with proper statistical controls, the work would address a genuine trilemma in federated learning by combining decentralised ring topology with privacy-preserving heads and principled weighting. The absence of machine-checked proofs or external verification means the significance hinges entirely on the soundness of the unelaborated propositions.
major comments (3)
- [Abstract] Abstract: The convergence rate bound and three propositions on normalisation, coverage, retention, and diversity optimality are asserted without derivation details, explicit assumptions (e.g., Lipschitz or bounded-gradient conditions), or proof sketches. This is load-bearing because the central claim that fibflpp simultaneously delivers the bound, coverage, and permanent head privacy rests on these propositions.
- [Abstract / Experimental setup] Experimental results: Performance numbers (including the +20.7 pp advantage and dominance in 17 of 28 configurations) are presented without stating whether they derive from single runs or multiple averaged runs, and without error bars or statistical tests. This directly affects the reliability of the claim that fibflpp surpasses FedAvg in all label-skew configurations.
- [Method description] Method: The post-hoc components (accuracy-gated neighbour suppression, 2-opt ring permutation, cosine-annealed self-retention) are introduced without ablation studies isolating their effects on convergence or privacy. If any component violates the implicit conditions needed for the rate bound, both the theoretical guarantee and the Pareto-dominance claim are undermined.
minor comments (2)
- [Abstract] The abstract cites mcmahan2017, hu2019segmented, and collins2021exploiting but the manuscript should ensure the full reference list is complete and consistent.
- [Abstract] Notation for K_g = ceil(N/2) and the exact definition of the Fibonacci directional bias should be clarified at first use to avoid ambiguity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on the theoretical claims, experimental reporting, and methodological components while committing to revisions that strengthen the manuscript without misrepresenting its contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The convergence rate bound and three propositions on normalisation, coverage, retention, and diversity optimality are asserted without derivation details, explicit assumptions (e.g., Lipschitz or bounded-gradient conditions), or proof sketches. This is load-bearing because the central claim that fibflpp simultaneously delivers the bound, coverage, and permanent head privacy rests on these propositions.
Authors: The full manuscript contains a theoretical analysis section that derives the convergence rate bound under standard assumptions of L-smooth loss functions and bounded stochastic gradients, which are stated explicitly there along with the three supporting propositions on normalisation, coverage, retention, and diversity optimality. Proof sketches appear in the appendix. To address the concern, we will expand the main text with explicit assumption statements, move key derivation steps forward, and include a high-level proof outline in the revised abstract and method sections. revision: yes
-
Referee: [Abstract / Experimental setup] Experimental results: Performance numbers (including the +20.7 pp advantage and dominance in 17 of 28 configurations) are presented without stating whether they derive from single runs or multiple averaged runs, and without error bars or statistical tests. This directly affects the reliability of the claim that fibflpp surpasses FedAvg in all label-skew configurations.
Authors: The reported figures derive from single runs per configuration, which is common in federated learning literature given computational constraints. We agree this reduces statistical robustness. In revision we will explicitly state the single-run nature, add error bars from multiple random seeds for the primary label-skew and Dirichlet results, and include paired statistical tests (e.g., Wilcoxon) for the key comparisons against FedAvg. revision: yes
-
Referee: [Method description] Method: The post-hoc components (accuracy-gated neighbour suppression, 2-opt ring permutation, cosine-annealed self-retention) are introduced without ablation studies isolating their effects on convergence or privacy. If any component violates the implicit conditions needed for the rate bound, both the theoretical guarantee and the Pareto-dominance claim are undermined.
Authors: These components are constructed to preserve the normalisation, coverage, and retention conditions underlying the convergence bound: accuracy-gated suppression modulates only low-performing neighbours while retaining the Fibonacci directional bias; 2-opt permutation maximises diversity subject to the ring topology; cosine annealing ensures self-retention decays consistently with the retention proposition. We omitted ablations due to space limits but will add them to the supplementary material in revision, reporting isolated effects on both accuracy and privacy leakage metrics. revision: yes
Circularity Check
No circularity detected; derivation chain is self-contained
full rationale
The provided abstract and description establish a convergence rate bound plus propositions on normalisation, coverage, retention and diversity optimality for the Fibonacci-weighted ring protocols, but contain no equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior author work. All cited prior art (McMahan 2017, Hu 2019, Collins 2021) is external. No step reduces by construction to its own inputs; the central claims rest on independent empirical comparisons to FedAvg and other server-free baselines across 28 configurations.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Constantsphi_golden_ratio, phi_fixed_point matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
the golden-ratio Fibonacci identity 1/φ+1/φ²=1 (φ=(1+√5)/2) provides a naturally normalised, asymmetric, and parameter-free weight pair (α,β) for ring gossip, requiring no additional hyperparameters
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel, Jcost matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
α=1/φ≈0.618, β=1/φ²≈0.382 ... α+β=1 ... the Fibonacci pair α>β introduces an imaginary component that strictly reduces |λk|
-
IndisputableMonolith.Foundation.BranchSelectionRCLCombiner_isCoupling_iff echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Corollary 4.2 (Fibonacci Directional Bias Preserved) ... aL ∈[α/2,(α+1)/2]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communication- efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication- efficient learning of deep networks from decentralized data,” inProceedings of the Interna- tional Conference on Artificial Intelligence and Statistics (AISTATS), pp. 1273–1282, 2017
work page 2017
-
[2]
Exploiting shared representations for personalized federated learning,
L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “Exploiting shared representations for personalized federated learning,” inProceedings of the International Conference on Machine Learning (ICML), pp. 2089–2099, 2021
work page 2089
-
[3]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine Learning and Systems, vol. 2, pp. 429– 450, 2020
work page 2020
-
[4]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProceedings of the International Conference on Machine Learning (ICML), pp. 5132–5143, 2020
work page 2020
-
[5]
Tackling the objective inconsistency problem in heterogeneous federated optimization,
J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V . Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,”Advances in Neural Information Processing Systems, vol. 33, pp. 7611–7623, 2020
work page 2020
-
[6]
On the convergence of FedA vg on non-IID data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of FedAvg on non-IID data,”arXiv preprint arXiv:1907.02189, 2019
-
[7]
Think Locally, Act Globally: Federated Learning with Local and Global Representations,
P. P. Liang, T. Liu, L. Ziyin, N. B. Allen, R. P. Auerbach, D. Brent, R. Salakhutdinov, and L.-P. Morency, “Think Locally, Act Globally: Federated Learning with Local and Global Representations,”arXiv preprint arXiv:2001.01523, Jan. 2020
-
[8]
Personalized federated learning with Moreau envelopes,
C. T. Dinh, N. Tran, and J. Nguyen, “Personalized federated learning with Moreau envelopes,” Advances in Neural Information Processing Systems, vol. 33, pp. 21394–21405, 2020. 31 FIRMA: Fibonacci Ring Model Aggregation for Privacy-preserving FL Under Review
work page 2020
-
[9]
Ditto: Fair and robust federated learning through personalization,
T. Li, S. Hu, A. Beirami, and V . Smith. “Ditto: Fair and robust federated learning through personalization,” InProc. ICML, volume 139, pages 6357–6368, 2021
work page 2021
-
[10]
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach,”Advances in Neural Information Processing Systems, vol. 33, pp. 3557–3568, 2020
work page 2020
-
[11]
Adaptive personalized federated learning,
Y . Deng, M. M. Kamani, and M. Mahdavi, “Adaptive personalized federated learning,”arXiv preprint arXiv:2003.13461, 2020
-
[12]
Federated multi-task learning under a mixture of distributions,
O. Marfoq, G. Neglia, A. Bellet, L. Kameni, and R. Vidal, “Federated multi-task learning under a mixture of distributions,”Advances in Neural Information Processing Systems, vol. 34, pp. 15434–15447, 2021
work page 2021
- [13]
-
[14]
Z. Wang, Y . Hu, S. Yan, Z. Wang, R. Hou, and C. Wu, Efficient ring-topology decentralized federated learning with deep generative models for medical data in e-healthcare systems, Electronics, vol. 11, no. 10, p. 1548, May 2022
work page 2022
-
[15]
Fast linear iterations for distributed averaging,
L. Xiao and S. Boyd, “Fast linear iterations for distributed averaging,”Systems & Control Letters, vol. 53, no. 1, pp. 65–78, 2004
work page 2004
-
[16]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,”Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[17]
Federated Learning with Non-IID Data
Y . Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V . Chandra, “Federated learning with non-IID data,”arXiv preprint arXiv:1806.00582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,”arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[19]
iDLG: Improved deep leakage from gradients,
B. Zhao, K. R. Mopuri, and H. Bilen, “iDLG: Improved deep leakage from gradients,”arXiv preprint arXiv:2001.02610, 2020
-
[20]
Inverting gradients—how easy is it to break privacy in federated learning?
J. Geiping, H. Bauermeister, H. Dr¨oge, and M. Moeller, “Inverting gradients—how easy is it to break privacy in federated learning?”Advances in Neural Information Processing Systems, vol. 33, pp. 16937–16947, 2020
work page 2020
-
[21]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
A method for solving traveling-salesman problems,
G. A. Croes, “A method for solving traveling-salesman problems,”Operations Research, vol. 6, no. 6, pp. 791–812, 1958
work page 1958
-
[24]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016. 32
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.