A Matched Spectral Benchmark of Quantum Inspired Feature Maps
Pith reviewed 2026-06-30 13:54 UTC · model grok-4.3
The pith
Fixed quantum-inspired encodings do not provide reliable machine learning advantage on classical data
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fixed quantum-inspired encoding geometry alone is not a reliable source of machine-learning advantage on classical data, as amplitude encoding removes magnitude information through unit-sphere normalization, angle encoding becomes geometrically redundant with raw linear features, and basis encoding imposes a binary Hamming geometry poorly aligned with smooth decision structure.
What carries the argument
Matched spectral benchmark that evaluates amplitude, angle, and basis encodings against classical controls using effective rank, condition number, centered kernel alignment, predictive performance, and overhead under matched output dimensionality.
If this is right
- Amplitude encoding removes magnitude information through unit-sphere normalization.
- Angle encoding often becomes geometrically redundant with raw linear features.
- Basis encoding imposes binary Hamming geometry misaligned with smooth decision boundaries.
- No encoding shows consistent superiority in predictive performance over controls such as RBF SVMs or shallow networks.
Where Pith is reading between the lines
- Quantum machine learning advantage would need to come from trainable circuits or entanglement rather than fixed encodings alone.
- The same geometric metrics could be applied to test other proposed quantum feature maps for classical equivalence.
- Results could differ if encodings were made trainable instead of fixed or if datasets were chosen to exploit superposition explicitly.
Load-bearing premise
The chosen classical datasets and strong classical controls represent the regimes where a quantum encoding advantage would be expected to appear.
What would settle it
A demonstration on a new dataset that one encoding consistently outperforms all listed classical controls in predictive performance while showing superior geometric metrics under matched dimensionality would falsify the claim.
Figures
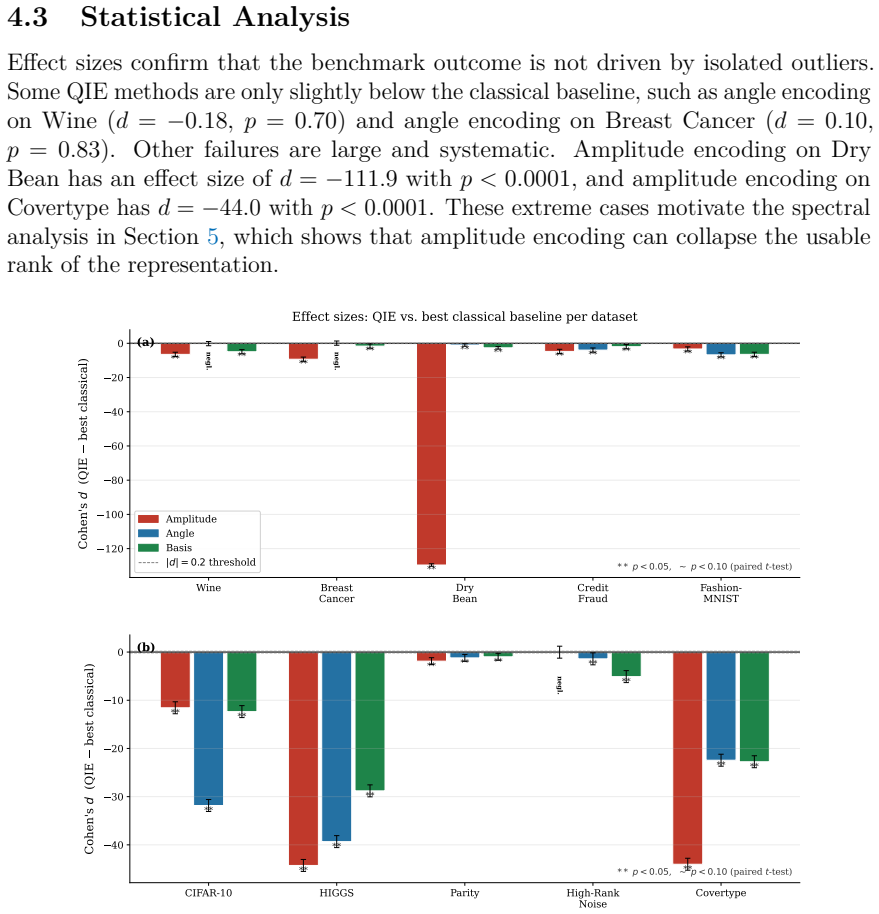
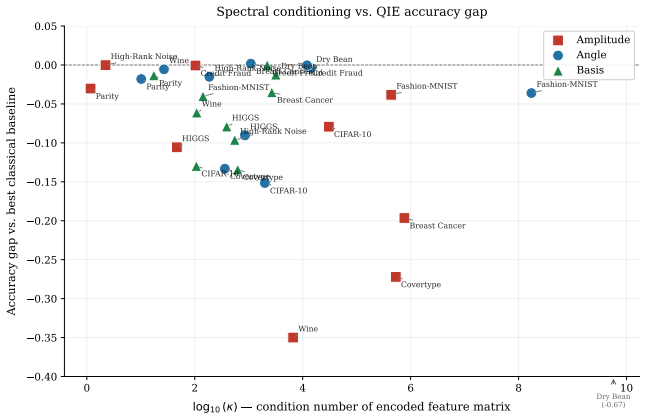
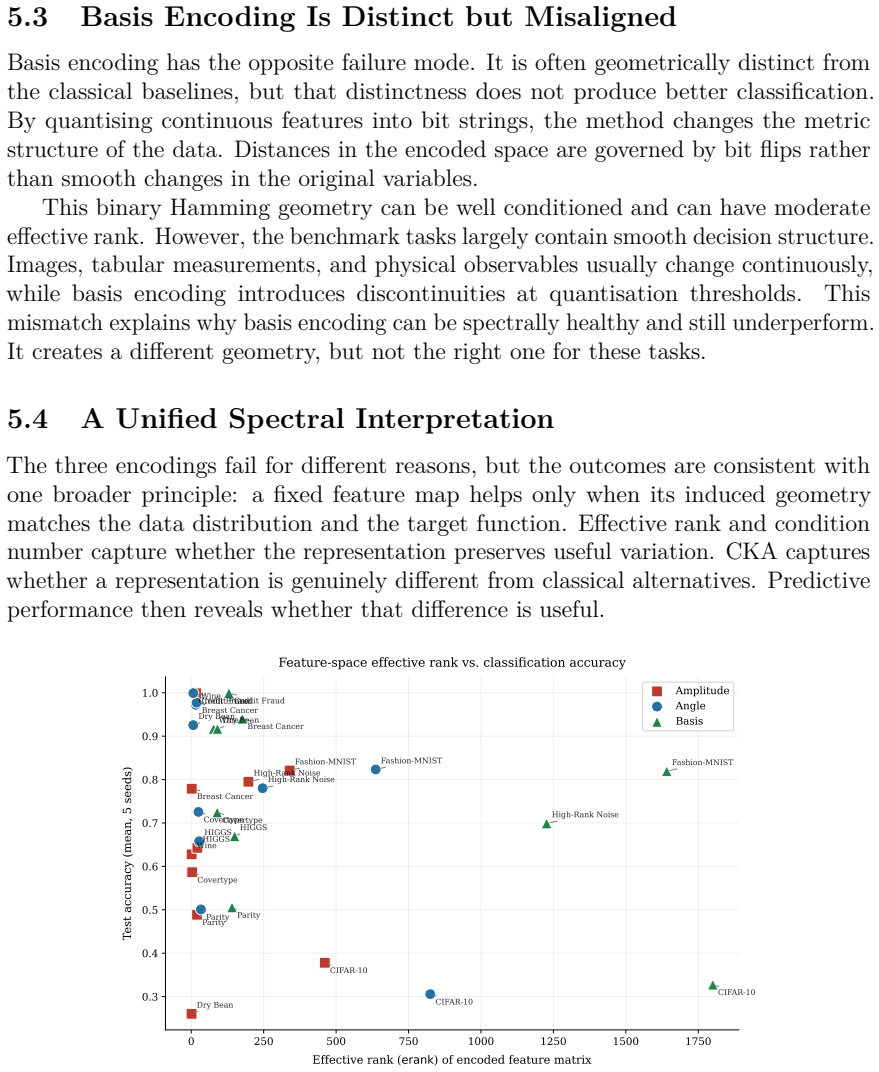
read the original abstract
Quantum machine learning is often motivated by the idea that quantum systems can expose useful high-dimensional structure that is difficult to access with classical models. We isolate one central component of this claim: the fixed data-encoding map. Amplitude, angle, and basis encoding are evaluated as deterministic feature maps for classical supervised learning under matched output dimensionality and strong classical controls. The benchmark compares these encodings against raw linear models, random Fourier features, polynomial features, PCA, RBF SVMs, and shallow neural networks across diverse classical datasets. Rather than treating performance as a single endpoint, we analyze the geometry of each representation through effective rank, condition number, centered kernel alignment, predictive performance, and practical overhead. The resulting picture is mechanistic: amplitude encoding can remove magnitude information through unit-sphere normalization, angle encoding can become geometrically redundant with raw linear features, and basis encoding can impose a binary Hamming geometry that is poorly aligned with smooth decision structure. These findings do not argue against quantum computation, however, they show that fixed quantum-inspired encoding geometry alone is not a reliable source of machine-learning advantage on classical data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks amplitude, angle, and basis encodings as deterministic feature maps for classical supervised learning, comparing them under matched output dimensionality to raw linear models, random Fourier features, polynomial features, PCA, RBF SVMs, and shallow neural networks across diverse classical datasets. Using geometric diagnostics (effective rank, condition number, centered kernel alignment) alongside predictive performance and overhead, it concludes that fixed quantum-inspired encoding geometry alone is not a reliable source of machine-learning advantage on classical data, due to effects such as magnitude removal, geometric redundancy, and Hamming misalignment with smooth structure.
Significance. If the results hold, the work supplies a mechanistic empirical clarification of the limitations of fixed quantum encodings in classical ML settings, which can usefully inform QML research directions. The matched-dimensionality design, use of multiple geometric metrics, and inclusion of strong classical baselines are explicit strengths that make the negative finding more informative than single-metric comparisons.
major comments (2)
- [Methods (dataset description and selection)] The central claim requires that the selected datasets test regimes in which the encodings' distinctive geometric properties (unit-sphere normalization, angular redundancy, binary Hamming structure) could plausibly confer advantage. The manuscript should therefore justify dataset selection criteria and report whether any included datasets exhibit high intrinsic dimensionality, angular dominance, or binary structure that would favor the quantum-inspired maps over the listed controls.
- [Results (geometric diagnostics)] § on geometric analysis: the link between the reported metrics (effective rank, condition number, CKA) and the performance conclusions is not fully load-bearing without an explicit cross-metric correlation table or ablation showing that unfavorable geometry predicts the observed performance gaps even after controlling for the classical baselines.
minor comments (2)
- [Tables] Table captions should explicitly state the number of datasets, the output dimensionality matching procedure, and whether hyperparameter tuning was performed identically for all methods.
- [Notation and preliminaries] Define 'effective rank' and 'condition number' with a brief formula or reference on first use to aid readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments identify areas where the manuscript can be strengthened, particularly in justifying dataset choices and making the geometry-performance link more quantitative. We address each major comment below and commit to revisions that directly respond to the concerns.
read point-by-point responses
-
Referee: [Methods (dataset description and selection)] The central claim requires that the selected datasets test regimes in which the encodings' distinctive geometric properties (unit-sphere normalization, angular redundancy, binary Hamming structure) could plausibly confer advantage. The manuscript should therefore justify dataset selection criteria and report whether any included datasets exhibit high intrinsic dimensionality, angular dominance, or binary structure that would favor the quantum-inspired maps over the listed controls.
Authors: We agree that an explicit justification of dataset selection strengthens the central claim. The datasets were drawn from standard public repositories (UCI, scikit-learn, OpenML) to span a range of sample sizes, feature dimensionalities, and task difficulties typical in classical supervised learning. In the revised manuscript we will add a new subsection in Methods that states the selection criteria (coverage of low- and high-dimensional regimes, mix of continuous and discrete features, and avoidance of trivially separable or synthetic data) and will include a supplementary table reporting, for each dataset, (i) intrinsic dimensionality estimated from the number of principal components needed to explain 95 % variance, (ii) a simple angular-dominance statistic (median pairwise cosine similarity after centering), and (iii) the fraction of binary-valued features. This addition will allow readers to evaluate whether any dataset lies in a regime where the quantum-inspired geometries could plausibly help. revision: yes
-
Referee: [Results (geometric diagnostics)] § on geometric analysis: the link between the reported metrics (effective rank, condition number, CKA) and the performance conclusions is not fully load-bearing without an explicit cross-metric correlation table or ablation showing that unfavorable geometry predicts the observed performance gaps even after controlling for the classical baselines.
Authors: We accept that an explicit quantitative bridge between the geometric diagnostics and the performance gaps would make the mechanistic interpretation more robust. While the current manuscript already juxtaposes the metrics with accuracy results, we will add, in the revised Results section, (i) a correlation table giving Spearman rank correlations between each geometric quantity (effective rank, condition number, CKA) and the performance delta relative to the strongest classical baseline on the same dataset, and (ii) a simple linear regression ablation in which performance gap is regressed on the three geometric metrics while controlling for dataset size and baseline type. The resulting coefficients and R² values will be reported to demonstrate that unfavorable geometry remains predictive after these controls. revision: yes
Circularity Check
Empirical benchmark with no derivation chain
full rationale
This is a purely empirical benchmark paper comparing fixed quantum-inspired encodings (amplitude, angle, basis) to classical controls on classical datasets. No mathematical derivation, first-principles prediction, or fitted parameter is claimed; performance, effective rank, condition number, and CKA are measured directly. The central claim follows from the observed results rather than reducing to any input by construction. No self-citation load-bearing steps or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Supervised learning with quantum-enhanced feature spaces,
Vojtěch Havlíček, Antonio D. Córcoles, Kristan Temme, Aram W. Harrow, Abhinav Kandala, Jerry M. Chow, and Jay M. Gambetta. Supervised learning with quantum-enhanced feature spaces.Nature, 567(7747):209–212, 2019. doi: 10.1038/s41586-019-0980-2
-
[2]
Maria Schuld and Nathan Killoran. Quantum machine learning in feature hilbert spaces.Physical Review Letters, 122(4):040504, 2019. doi: 10.1103/PhysRevLett. 122.040504
-
[3]
A quantum-inspired classical algorithm for recommendation systems
Ewin Tang. A quantum-inspired classical algorithm for recommendation systems. InProceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019, pages 217–228. Association for Computing Machinery,
2019
-
[4]
doi: 10.1145/3313276.3316310
-
[5]
Hsin-Yuan Huang, Michael Broughton, Masoud Mohseni, Ryan Babbush, Ser- gio Boixo, Hartmut Neven, and Jarrod R. McClean. Power of data in quantum machine learning.Nature Communications, 12:2631, 2021. doi: 10.1038/s41467-021-22539-9
-
[6]
Kübler, Simon Buchholz, and Bernhard Schölkopf
Jonas M. Kübler, Simon Buchholz, and Bernhard Schölkopf. The inductive bias of quantum kernels. InAdvances in Neural Information Processing Systems, volume 34, pages 12661–12673, 2021. URLhttps://proceedings.neurips.cc/ paper/2021/hash/69adc1e107f7f7d035d7baf04342e1ca-Abstract.html
2021
-
[7]
Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and José I. Latorre. Data re-uploading for a universal quantum classifier.Quantum, 4:226, 2020. doi: 10.22331/q-2020-02-06-226
-
[8]
Variational quantum algorithms,
M. Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C. Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R. McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, and Patrick J. Coles. Variational quantum algorithms.Nature Reviews Physics, 3:625–644, 2021. doi: 10.1038/s42254-021-00348-9
-
[9]
The power of quantum neural networks,
Amira Abbas, David Sutter, Christa Zoufal, Aurelien Lucchi, Alessio Figalli, and Stefan Woerner. The power of quantum neural networks.Nature Computational Science, 1:403–409, 2021. doi: 10.1038/s43588-021-00084-1
-
[10]
Cerezo, and Zoë Holmes
Supanut Thanasilp, Samson Wang, M. Cerezo, and Zoë Holmes. Exponential concentration in quantum kernel methods.Nature Communications, 15:5200,
-
[11]
doi: 10.1038/s41467-024-49287-w
-
[12]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in Neural Information Processing Systems, volume 20, 2007. URL https://papers.nips.cc/paper/ 3182-random-features-for-large-scale-kernel-machines. 17
2007
-
[13]
Smola.Learning with Kernels: Support Vec- tor Machines, Regularization, Optimization, and Beyond
Bernhard Schölkopf and Alexander J. Smola.Learning with Kernels: Support Vec- tor Machines, Regularization, Optimization, and Beyond. MIT Press, Cambridge, MA, 2002. ISBN 9780262194754
2002
-
[14]
Stefan Aeberhard and M. Forina. Wine. UCI Machine Learning Repository, 1991. URLhttps://archive.ics.uci.edu/ml/datasets/wine
1991
-
[15]
William Wolberg, Olvi Mangasarian, Nick Street, and W. Street. Breast cancer wisconsin (diagnostic). UCI Machine Learning Repository,
-
[16]
URL https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+ Wisconsin+(Diagnostic)
-
[17]
Murat Koklu and Ilker Ali Özkan. Multiclass classification of dry beans using computer vision and machine learning techniques.Computers and Electronics in Agriculture, 174:105507, 2020. doi: 10.1016/j.compag.2020.105507
-
[18]
Johnson, and Gianluca Bontempi
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson, and Gianluca Bontempi. Calibrating probability with undersampling for unbalanced classification. In2015 IEEE Symposium Series on Computational Intelligence, pages 159–166. IEEE,
-
[19]
doi: 10.1109/SSCI.2015.33
-
[20]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms, 2017. URLhttps:// arxiv.org/abs/1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. URLhttps: //www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[22]
Pierre Baldi, Peter Sadowski, and Daniel Whiteson. Searching for exotic particles in high-energy physics with deep learning.Nature Communications, 5:4308, 2014. doi: 10.1038/ncomms5308
-
[23]
Blackard and Denis J
Jock A. Blackard and Denis J. Dean. Forest covertype. UCI KDD Archive, 1998. URLhttps://kdd.ics.uci.edu/databases/covertype/covertype.html
1998
-
[24]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceed- ings of Machine Learning Research, pages 3519–3529. PMLR, 2019. URL https://proceedings.mlr.press/v97/kornblith19a.html. 18 A Supplementary...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.