Zeroth-Order Nonconvex Nonsmooth Optimization with Heavy-Tailed Noise
Pith reviewed 2026-06-30 15:01 UTC · model grok-4.3
The pith
A clipped two-point estimator in the online-to-nonconvex framework finds (δ, ε)-Goldstein stationary points for nonconvex Lipschitz objectives under p-moment bounded heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By clipping the two-point gradient estimator inside the online-to-nonconvex conversion framework, the algorithm achieves zeroth-order oracle complexity O(d^{p/2(p-1)} δ^{-1} ε^{-(2p-1)/(p-1)}) to locate a (δ, ε)-Goldstein stationary point of a Lipschitz continuous objective whose stochastic evaluations have bounded p-moments, p ∈ (1,2].
What carries the argument
Clipped two-point gradient estimator inside the online-to-nonconvex conversion framework
If this is right
- Dimension dependence on d matches the best-known stochastic zeroth-order results for convex nonsmooth problems.
- Dependence on δ and ε matches the best-known stochastic first-order results for nonconvex nonsmooth problems.
- The method applies directly to any Lipschitz objective whose stochastic evaluations satisfy the p-moment bound.
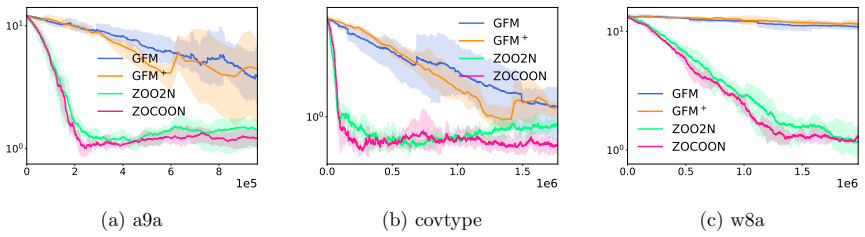
- Numerical experiments confirm practical effectiveness on standard test problems.
Where Pith is reading between the lines
- Clipping may serve as a modular robustness device for other derivative-free methods facing heavy-tailed noise.
- The same conversion-plus-clipping pattern could be tested on problems where only noisy gradient oracles exist rather than function values.
- Empirical checks could compare convergence when clipping is removed versus retained on data sets known to exhibit heavy tails.
Load-bearing premise
The objective is Lipschitz continuous and the stochastic function evaluations possess bounded p-moments for some p in (1,2].
What would settle it
Run the algorithm on a simple Lipschitz function whose noise has unbounded second moments and observe whether the iterates fail to approach any (δ, ε)-Goldstein point at the claimed rate.
Figures
read the original abstract
This paper considers the nonconvex nonsmooth problem in which the objective function is Lipschitz continuous. We focus on the stochastic setting where the algorithm can access stochastic function value evaluations with heavy-tailed noise, which is prevalent in many popular machine learning applications. We propose a stochastic zeroth-order algorithm that refines the framework of online-to-nonconvex conversion by clipping the two-point gradient estimator. The theoretical analysis shows that our algorithm can find a $(\delta, \epsilon)$-Goldstein stationary point with zeroth-order oracle complexity of ${\mathcal O}(d^{\frac{p}{2(p-1)}}\delta^{-1}\epsilon^{-\frac{2p-1}{p-1}})$, where $d$ is the problem dimension and $p\in(1,2]$ is the order of bounded moments. Note that our dependence on dimension $d$ matches the best-known results of stochastic zeroth-order optimization for finding the sub-optimal solution of a stochastic convex nonsmooth problem. In addition, our dependence on accuracy parameters $\delta$ and $\epsilon$ is consistent with that of the best-known stochastic first-order algorithms for stochastic nonconvex nonsmooth problems. Finally, we conduct numerical experiments to demonstrate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a stochastic zeroth-order algorithm for nonconvex nonsmooth Lipschitz optimization under heavy-tailed stochastic function evaluations with bounded p-moments (p ∈ (1,2]). It refines the online-to-nonconvex conversion framework by clipping the two-point gradient estimator and proves that the method finds a (δ, ε)-Goldstein stationary point with zeroth-order oracle complexity O(d^{p/2(p-1)} δ^{-1} ε^{-(2p-1)/p-1}). The rates are positioned as matching the best-known dimension dependence for stochastic convex nonsmooth ZO and the best-known accuracy dependence for stochastic nonconvex nonsmooth FO methods; numerical experiments are included to illustrate practical behavior.
Significance. If the stated complexity holds under the given assumptions, the work is significant for extending zeroth-order methods to heavy-tailed noise settings common in machine learning while preserving optimal dependence on dimension and accuracy parameters from related convex and first-order results. Credit is due for explicitly aligning the new bound with prior best-known rates rather than claiming improvement, and for including numerical validation.
minor comments (3)
- The abstract states the complexity but does not indicate whether the proof of the clipping step (which is central to handling p-moments) appears in a dedicated theorem or is embedded in the online-to-nonconvex reduction; a pointer to the relevant theorem number would improve readability.
- Notation for the (δ, ε)-Goldstein stationarity definition is used without an explicit reminder of its relation to standard Goldstein subdifferential; a one-sentence recall in §2 would aid readers unfamiliar with the nonsmooth nonconvex literature.
- The numerical experiments section would benefit from reporting the specific p values tested and whether the observed iteration counts scale consistently with the derived exponent -(2p-1)/(p-1).
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper, recognition of its significance in extending zeroth-order methods to heavy-tailed noise while aligning with best-known dimension and accuracy dependencies, and recommendation for minor revision. We appreciate the credit given for the explicit rate comparisons and numerical validation.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper derives a complexity bound for a clipped two-point zeroth-order algorithm in an online-to-nonconvex framework under explicit assumptions of Lipschitz continuity and bounded p-moments. The stated rate O(d^{p/2(p-1)} δ^{-1} ε^{-(2p-1)/p-1}) follows from standard analysis of the Goldstein stationarity measure and does not reduce by construction to any fitted parameter, self-citation chain, or renamed input. Comparisons to prior convex ZO and nonconvex FO rates are external benchmarks, not load-bearing justifications internal to the derivation. No self-definitional, fitted-prediction, or uniqueness-imported steps are present.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective function is Lipschitz continuous.
- domain assumption Stochastic function evaluations have bounded p-moments for p ∈ (1,2].
Reference graph
Works this paper leans on
-
[1]
Optimal algorithms for online convex optimization with multi-point bandit feedback
Alekh Agarwal, Ofer Dekel, and Lin Xiao. Optimal algorithms for online convex optimization with multi-point bandit feedback. InProc. COLT, pages 28–40, 2010
2010
-
[2]
Kwangjun Ahn, Xiang Cheng, Minhak Song, Chulhee Yun, Ali Jadbabaie, and Suvrit Sra. Linear attention is (maybe) all you need (to understand transformer optimization).arXiv preprint arXiv:2310.01082, 2023
-
[3]
Zeroth-order nonconvex stochastic optimization: Handling constraints, high dimensionality, and saddle points.Foundations of Computational Mathematics, 22(1):35–76, 2022
Krishnakumar Balasubramanian and Saeed Ghadimi. Zeroth-order nonconvex stochastic optimization: Handling constraints, high dimensionality, and saddle points.Foundations of Computational Mathematics, 22(1):35–76, 2022
2022
-
[4]
Libsvm: A library for support vector machines.ACM Transactions on Intelligent Systems and Technology, 2(3, article 27), 2007
Chih Chung Chang and Chih Jen Lin. Libsvm: A library for support vector machines.ACM Transactions on Intelligent Systems and Technology, 2(3, article 27), 2007
2007
-
[5]
Faster gradient-free algorithms for nonsmooth nonconvex stochastic optimization
Lesi Chen, Jing Xu, and Luo Luo. Faster gradient-free algorithms for nonsmooth nonconvex stochastic optimization. InInternational Conference on Machine Learning, pages 5219–5233. PMLR, 2023
2023
-
[6]
Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. InProceedings of the 10th ACM workshop on artificial intelligence and security, pages 15–26, 2017
2017
-
[7]
Structured evolution with compact architectures for scalable policy optimization
Krzysztof Choromanski, Mark Rowland, Vikas Sindhwani, Richard Turner, and Adrian Weller. Structured evolution with compact architectures for scalable policy optimization. InInternational Conference on Machine Learning, pages 970–978. PMLR, 2018
2018
-
[8]
SIAM, 1990
Frank H Clarke.Optimization and nonsmooth analysis. SIAM, 1990
1990
-
[9]
Optimal stochastic non-smooth non-convex optimization through online-to-non-convex conversion
Ashok Cutkosky, Harsh Mehta, and Francesco Orabona. Optimal stochastic non-smooth non-convex optimization through online-to-non-convex conversion. InInternational Conference on Machine Learning, pages 6643–6670. PMLR, 2023
2023
-
[10]
Stochastic model-based minimization of weakly convex functions
Damek Davis and Dmitriy Drusvyatskiy. Stochastic model-based minimization of weakly convex functions. SIAM Journal on Optimization, 29(1):207–239, 2019
2019
-
[11]
Proximally guided stochastic subgradient method for nonsmooth, nonconvex problems.SIAM Journal on Optimization, 29(3):1908–1930, 2019
Damek Davis and Benjamin Grimmer. Proximally guided stochastic subgradient method for nonsmooth, nonconvex problems.SIAM Journal on Optimization, 29(3):1908–1930, 2019
1908
-
[12]
A gradient sampling method with complexity guarantees for Lipschitz functions in high and low dimensions
Damek Davis, Dmitriy Drusvyatskiy, Yin Tat Lee, Swati Padmanabhan, and Guanghao Ye. A gradient sampling method with complexity guarantees for Lipschitz functions in high and low dimensions. In Proc. NeurIPS, 2022. 10
2022
-
[13]
Randomized smoothing for stochastic optimization.SIAM Journal on Optimization, 22(2):674–701, 2012
John C Duchi, Peter L Bartlett, and Martin J Wainwright. Randomized smoothing for stochastic optimization.SIAM Journal on Optimization, 22(2):674–701, 2012
2012
-
[14]
Variable selection via nonconcave penalized likelihood and its oracle properties.Journal of the American statistical Association, 96(456):1348–1360, 2001
Jianqing Fan and Runze Li. Variable selection via nonconcave penalized likelihood and its oracle properties.Journal of the American statistical Association, 96(456):1348–1360, 2001
2001
-
[15]
On proximal policy optimization’s heavy- tailed gradients
Saurabh Garg, Joshua Zhanson, Emilio Parisotto, Adarsh Prasad, Zico Kolter, Zachary Lipton, Sivaraman Balakrishnan, Ruslan Salakhutdinov, and Pradeep Ravikumar. On proximal policy optimization’s heavy- tailed gradients. InInternational Conference on Machine Learning, pages 3610–3619. PMLR, 2021
2021
-
[16]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
2013
-
[17]
Deep sparse rectifier neural networks
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 315–323. JMLR Workshop and Conference Proceedings, 2011
2011
-
[18]
Goldstein
A.A. Goldstein. Optimization of Lipschitz continuous functions.Mathematical Programming, 13:14–22, 1977
1977
-
[19]
Discrete optimization via simulation using compass.Operations research, 54(1):115–129, 2006
L Jeff Hong and Barry L Nelson. Discrete optimization via simulation using compass.Operations research, 54(1):115–129, 2006
2006
-
[20]
From gradient clipping to normalization for heavy tailed sgd.arXiv preprint arXiv:2410.13849,
Florian H¨ ubler, Ilyas Fatkhullin, and Niao He. From gradient clipping to normalization for heavy tailed sgd.arXiv preprint arXiv:2410.13849, 2024
-
[21]
Deterministic nonsmooth nonconvex optimization
Michael Jordan, Guy Kornowski, Tianyi Lin, Ohad Shamir, and Manolis Zampetakis. Deterministic nonsmooth nonconvex optimization. InThe Thirty Sixth Annual Conference on Learning Theory, pages 4570–4597. PMLR, 2023
2023
-
[22]
Gradient-free methods for non-smooth convex stochastic optimization with heavy-tailed noise on convex compact.Computational Management Science, 20(1):37, 2023
Nikita Kornilov, Alexander Gasnikov, Pavel Dvurechensky, and Darina Dvinskikh. Gradient-free methods for non-smooth convex stochastic optimization with heavy-tailed noise on convex compact.Computational Management Science, 20(1):37, 2023
2023
-
[23]
Accelerated zeroth-order method for non-smooth stochastic convex optimization problem with infinite variance.Advances in Neural Information Processing Systems, 36:64083–64102, 2023
Nikita Kornilov, Ohad Shamir, Aleksandr Lobanov, Darina Dvinskikh, Alexander Gasnikov, Innokentiy Shibaev, Eduard Gorbunov, and Samuel Horv´ ath. Accelerated zeroth-order method for non-smooth stochastic convex optimization problem with infinite variance.Advances in Neural Information Processing Systems, 36:64083–64102, 2023
2023
-
[24]
Nikita Kornilov, Yuriy Dorn, Aleksandr Lobanov, Nikolay Kutuzov, Innokentiy Shibaev, Eduard Gorbunov, Alexander Gasnikov, and Alexander Nazin. Median clipping for zeroth-order non-smooth convex optimization and multi-armed bandit problem with heavy-tailed symmetric noise.arXiv preprint arXiv:2402.02461, 2024
-
[25]
An algorithm with optimal dimension-dependence for zero-order nonsmooth nonconvex stochastic optimization.Journal of Machine Learning Research, 25(122):1–14, 2024
Guy Kornowski and Ohad Shamir. An algorithm with optimal dimension-dependence for zero-order nonsmooth nonconvex stochastic optimization.Journal of Machine Learning Research, 25(122):1–14, 2024
2024
-
[26]
Gradient-free methods for deterministic and stochastic nonsmooth nonconvex optimization.Advances in Neural Information Processing Systems, 35:26160–26175, 2022
Tianyi Lin, Zeyu Zheng, and Michael Jordan. Gradient-free methods for deterministic and stochastic nonsmooth nonconvex optimization.Advances in Neural Information Processing Systems, 35:26160–26175, 2022
2022
-
[27]
High-probability bound for non-smooth non-convex stochastic optimization with heavy tails
Langqi Liu, Yibo Wang, and Lijun Zhang. High-probability bound for non-smooth non-convex stochastic optimization with heavy tails. InForty-first International Conference on Machine Learning, 2024
2024
-
[28]
Zeroth-order methods for constrained nonconvex nonsmooth stochastic optimization
Zhuanghua Liu, Cheng Chen, Luo Luo, and Bryan Kian Hsiang Low. Zeroth-order methods for constrained nonconvex nonsmooth stochastic optimization. InForty-first International Conference on Machine Learning, 2024. 11
2024
-
[29]
Online convex optimization with heavy tails: Old algorithms, new regrets, and applications
Zijian Liu. Online convex optimization with heavy tails: Old algorithms, new regrets, and applications. arXiv preprint arXiv:2508.07473, 2025
-
[30]
Nonconvex stochastic optimization under heavy-tailed noises: Opti- mal convergence without gradient clipping
Zijian Liu and Zhengyuan Zhou. Nonconvex stochastic optimization under heavy-tailed noises: Opti- mal convergence without gradient clipping. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Simple random search provides a competitive approach to reinforcement learning
Horia Mania, Aurelia Guy, and Benjamin Recht. Simple random search provides a competitive approach to reinforcement learning.arXiv preprint arXiv:1803.07055, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Sparsenet: Coordinate descent with nonconvex penalties.Journal of the American Statistical Association, 106(495):1125–1138, 2011
Rahul Mazumder, Jerome H Friedman, and Trevor Hastie. Sparsenet: Coordinate descent with nonconvex penalties.Journal of the American Statistical Association, 106(495):1125–1138, 2011
2011
-
[33]
Rectified linear units improve restricted boltzmann machines
Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), pages 807–814, 2010
2010
-
[34]
Optimization via simulation over discrete decision variables
Barry L Nelson. Optimization via simulation over discrete decision variables. InRisk and optimization in an uncertain world, pages 193–207. Informs, 2010
2010
-
[35]
Random gradient-free minimization of convex functions.Founda- tions of Computational Mathematics, 17(2):527–566, 2017
Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex functions.Founda- tions of Computational Mathematics, 17(2):527–566, 2017
2017
-
[36]
Improved convergence in high probability of clipped gradient methods with heavy-tailed noise
Ta Duy Nguyen, Thien Hang Nguyen, Alina Ene, and Huy Le Nguyen. High probability convergence of clipped-sgd under heavy-tailed noise.arXiv preprint arXiv:2302.05437, 2023
-
[37]
Online Learning: A Modern Introduction Using Convex Optimization
Francesco Orabona. A modern introduction to online learning.arXiv preprint arXiv:1912.13213, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[38]
High-probability bounds for stochastic optimization and variational inequalities: the case of unbounded variance
Abdurakhmon Sadiev, Marina Danilova, Eduard Gorbunov, Samuel Horv´ ath, Gauthier Gidel, Pavel Dvurechensky, Alexander Gasnikov, and Peter Richt´ arik. High-probability bounds for stochastic optimization and variational inequalities: the case of unbounded variance. InInternational Conference on Machine Learning, pages 29563–29648. PMLR, 2023
2023
-
[39]
A tail-index analysis of stochastic gradient noise in deep neural networks
Umut Simsekli, Levent Sagun, and Mert Gurbuzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. InInternational Conference on Machine Learning, pages 5827–5837. PMLR, 2019
2019
-
[40]
Do differentiable simulators give better policy gradients? InInternational Conference on Machine Learning, pages 20668–20696
Hyung Ju Suh, Max Simchowitz, Kaiqing Zhang, and Russ Tedrake. Do differentiable simulators give better policy gradients? InInternational Conference on Machine Learning, pages 20668–20696. PMLR, 2022
2022
-
[41]
Tao Sun, Xinwang Liu, and Kun Yuan. Gradient normalization provably benefits nonconvex sgd under heavy-tailed noise.arXiv preprint arXiv:2410.16561, 2024
-
[42]
Lai Tian and Anthony Man-Cho So. No dimension-free deterministic algorithm computes approximate stationarities of lipschitzians.arXiv preprint arXiv:2210.06907, 2022
-
[43]
On the finite-time complexity and practical computation of approximate stationarity concepts of Lipschitz functions
Lai Tian, Kaiwen Zhou, and Anthony Man-Cho So. On the finite-time complexity and practical computation of approximate stationarity concepts of Lipschitz functions. InProc. ICML, pages 21360– 21379, 2022
2022
-
[44]
On stochastic gradient and subgradient methods with adaptive steplength sequences.Automatica, 48(1):56–67, 2012
Farzad Yousefian, Angelia Nedi´ c, and Uday V Shanbhag. On stochastic gradient and subgradient methods with adaptive steplength sequences.Automatica, 48(1):56–67, 2012
2012
-
[45]
Nearly unbiased variable selection under minimax concave penalty.The Annals of Statistics, 2010
Cun-Hui Zhang. Nearly unbiased variable selection under minimax concave penalty.The Annals of Statistics, 2010
2010
-
[46]
Why are adaptive methods good for attention models?Advances in Neural Information Processing Systems, 33:15383–15393, 2020
Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models?Advances in Neural Information Processing Systems, 33:15383–15393, 2020. 12
2020
-
[47]
Complexity of finding stationary points of nonconvex nonsmooth functions
Jingzhao Zhang, Hongzhou Lin, Stefanie Jegelka, Suvrit Sra, and Ali Jadbabaie. Complexity of finding stationary points of nonconvex nonsmooth functions. InInternational Conference on Machine Learning, pages 11173–11182. PMLR, 2020
2020
-
[48]
Analysis of multi-stage convex relaxation for sparse regularization.Journal of Machine Learning Research, 11(3), 2010
Tong Zhang. Analysis of multi-stage convex relaxation for sparse regularization.Journal of Machine Learning Research, 11(3), 2010. 13 The appendix is organized as follows. Section A introduces several key lemmas that are essential for the convergence analysis of the ZOCOON method. Section B presents the proof of the in-expectation and high-probability con...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.