JacQuant: STE-Free Quantization-Aware Training via Learned Jacobian Surrogates
Pith reviewed 2026-06-29 22:51 UTC · model grok-4.3
The pith
JacQuant replaces the straight-through estimator with a learned diagonal Jacobian surrogate to stabilize quantization-aware training and reach higher accuracy on LLMs at two bits and below.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
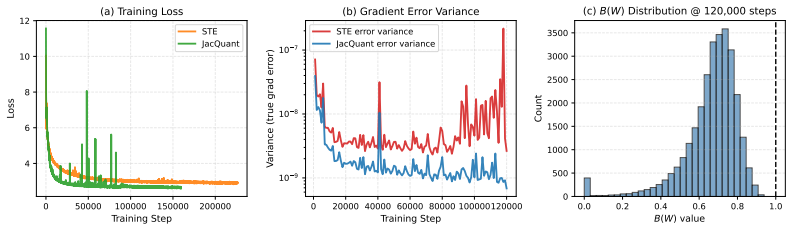
JacQuant learns a data-driven diagonal or block-diagonal approximation to the Jacobian of the model's output with respect to its parameters and uses this surrogate in place of the straight-through estimator during the backward pass, enabling stable training of ultra-low-bit models without any modification to the forward quantization operation.
What carries the argument
A learned diagonal or block-diagonal Jacobian surrogate that approximates the local sensitivity of model output to weight changes and is inserted into variance-reduced optimizers.
If this is right
- Higher accuracy than STE-based QAT across LLM benchmarks at ≤2 bits.
- Negligible added runtime cost under practical group sizes on various models.
- Convergence guarantees for non-convex objectives and linear rates under the PL condition.
- Drop-in compatibility with common weight and activation quantizers that leaves the forward pass unchanged.
- A simple calibration argument relates the learned sensitivity directly to end-to-end output fidelity.
Where Pith is reading between the lines
- The inexpensive nature of the diagonal surrogate suggests it could be recomputed periodically during long training runs to track distribution shifts.
- Similar learned sensitivity surrogates might be applied to other non-differentiable operations such as structured pruning or dynamic mixed-precision allocation.
- Because the method requires no change to the forward quantizer, it could be combined with existing quantization libraries without code changes.
- The calibration link between surrogate and output fidelity may extend to measuring how well other compression techniques preserve model behavior.
Load-bearing premise
The learned surrogate accurately approximates the model's local sensitivity to parameter changes and can be safely used inside standard variance-reduced optimizers without altering forward quantizer behavior.
What would settle it
On a small model where the true local Jacobian is computed exactly by automatic differentiation, replace JacQuant's learned surrogate with a version whose entries differ by more than a small constant factor and observe whether the accuracy advantage over STE disappears.
Figures

read the original abstract
Quantization-aware training (QAT) is widely deployed but typically relies on the Straight-Through Estimator (STE), which passes gradients through non-differentiable quantizers by fiat. This often makes training brittle near bin boundaries and weakly aligned with the actual behavior of the low-precision model. We introduce JacQuant, a QAT framework that learns a lightweight surrogate of the model's local sensitivity to parameter changes and uses it to stabilize and accelerate training within standard variance-reduced optimizers. The surrogate is inexpensive (diagonal or block-diagonal), data-driven, and compatible with common weight and activation quantizers. On code-preserving training phases, we prove convergence for non-convex objectives and obtain linear rates under a PL condition, and we relate the learned sensitivity to end-to-end output fidelity via a simple calibration argument. Across LLM benchmarks at $\leq 2$ bits, JacQuant consistently reaches higher accuracy than STE-based QAT, and the runtime analyses on various models show that the added cost remains negligible under practical group sizes. The method is drop-in and requires no changes to the forward quantizers; our empirical claims are scoped to ultra-low-bit LLM QAT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JacQuant, a QAT framework that replaces the Straight-Through Estimator with a learned lightweight (diagonal or block-diagonal) surrogate of local parameter sensitivity. The surrogate is integrated into standard variance-reduced optimizers without altering forward quantizer behavior. Convergence is proved for non-convex objectives on code-preserving phases, with linear rates under the PL condition; a calibration argument relates the surrogate to end-to-end output fidelity. Empirically, the method yields higher accuracy than STE-based QAT on LLM benchmarks at ≤2 bits while adding negligible runtime cost under practical group sizes.
Significance. If the surrogate accurately captures sensitivity and the scoped theoretical results hold, the work supplies a practical, drop-in alternative to STE that improves training stability and fidelity alignment in ultra-low-bit LLM quantization. The negligible overhead and compatibility with common quantizers strengthen the practical contribution; the convergence analysis and calibration argument provide theoretical grounding within the stated scope.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation and claims are self-contained
full rationale
The paper defines a data-driven surrogate Jacobian, applies it within standard variance-reduced optimizers, proves convergence on code-preserving phases using non-convex and PL analysis, and relates sensitivity to fidelity via a calibration step. These steps rely on external optimization theory and empirical benchmarks rather than reducing any prediction or result to a fitted input by construction. No self-citation chains, self-definitional loops, or renamed known results are present in the abstract or described claims. The empirical superiority over STE QAT is scoped to benchmarks and does not tautologically follow from the surrogate definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PACT: Parameterized Clipping Activation for Quantized Neural Networks
URLhttps://arxiv.org/abs/1805.06085. Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and S...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
URLhttps://arxiv.org/abs/1606.06160. 12 Contents 1 Introduction 1 2 Related Work 2 3 Method 3 3.1 Preliminaries: Grouped Quantization in LLMs . . . . . . . . . . . . . . . . . . . . 3 3.2 The Core Idea: Learning the Quantization Jacobian . . . . . . . . . . . . . . . . . 3 3.3 Practical Estimation ofB(W). . . . . . . . . . . . . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Despite empirical success, most QAT methods inheritSTE’s bias, which ignores discrete bin geometry and can induce optimization mismatch at 2–4 bits
learn per-layer step sizes, narrowing the accuracy gap at low bitwidths. Despite empirical success, most QAT methods inheritSTE’s bias, which ignores discrete bin geometry and can induce optimization mismatch at 2–4 bits. RecentSTE-free directions include proximal surrogates (e.g.,PV-T uning(Malinovskii et al., 2024)) and geometric transforms (e.g., theRo...
2024
-
[4]
interpretsVRasJacobian sketchingfor stochastic oracles, yielding low-variance quasi-gradient updates. A common and effective instantiation of this principle isSAGA-style memory (maintaining a table of historical per-index control variates), but suchdataset-sizedmemory is typically infeasible for LLM training.JacQuantadopts the control-variate principle bu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.