Analogies between Transformer Layers and Power Method
Pith reviewed 2026-06-29 22:57 UTC · model grok-4.3
The pith
Transformer layers tilt token representations toward the principal eigenvector of the product of output and value weight matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
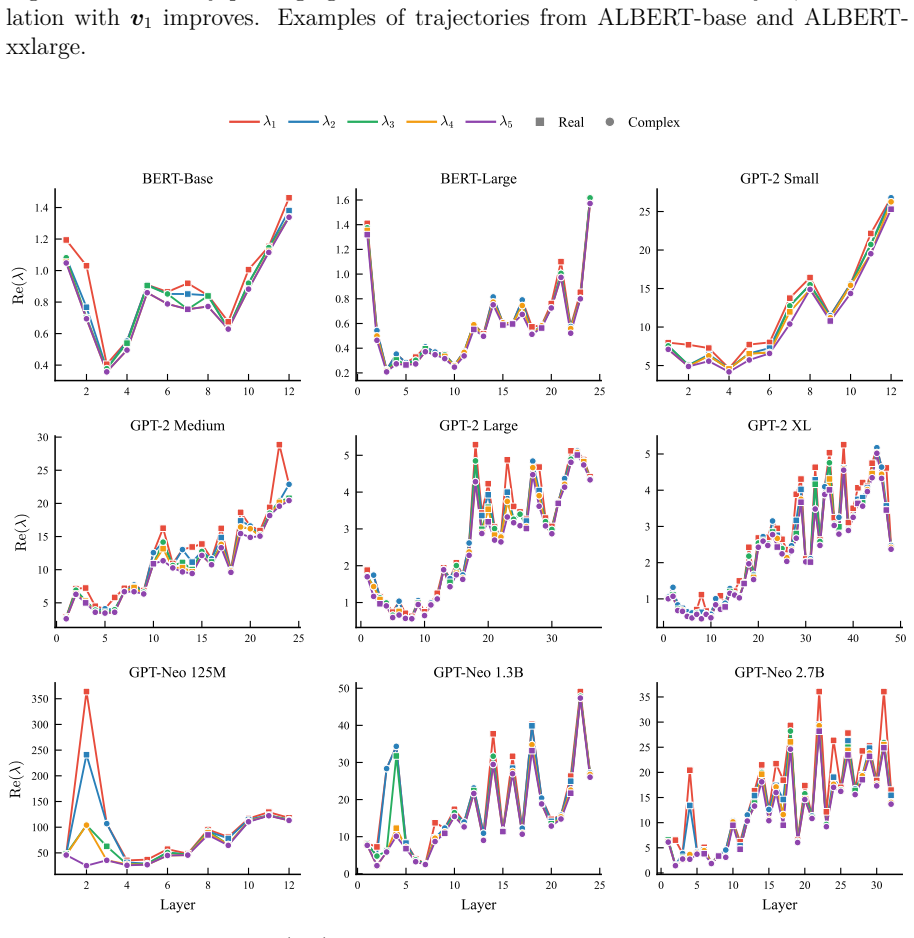
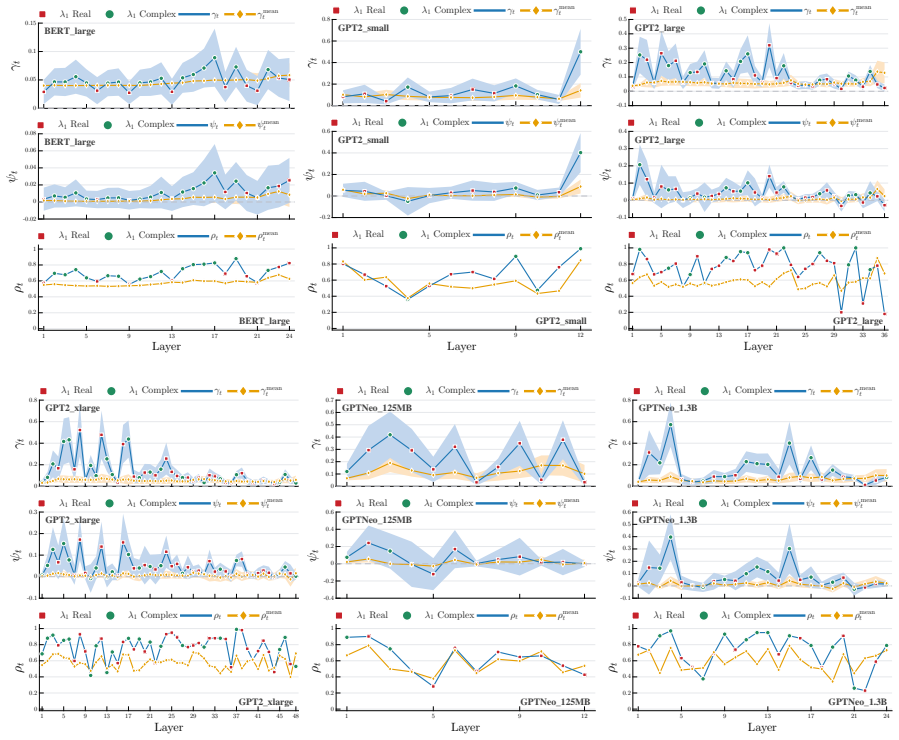
The operations inside a transformer layer (projections and layer normalizations, omitting the feed-forward sub-layer) are analogous to a single iteration of the power method. Consequently, after passing through the layer the token embeddings become more aligned with the principal eigenvector of the matrix W_o W_v formed from that layer's output and value weight matrices. When the transformer uses the same weights in every layer, this alignment strengthens with depth and admits an analytic proof.
What carries the argument
The analogy that maps the combined effect of value projection, attention-weighted summation, output projection, and layer normalization onto one multiplication-and-normalization step of the power method applied to the matrix W_o W_v.
If this is right
- Token alignment with the layer-specific eigenvector grows with depth.
- Shared-weight transformers exhibit analytically provable and empirically stronger alignment.
- The same matrix-eigenvector relation supplies a direct method to steer generated sequences toward an arbitrary target direction.
- The power-method view supplies a new decomposition of how information is progressively concentrated across layers.
Where Pith is reading between the lines
- Training procedures could explicitly regularize or initialize the singular vectors of W_o W_v to control how quickly alignment occurs.
- Mechanistic interpretability analyses might track the evolution of these per-layer principal directions rather than individual attention heads.
- Architectures that deliberately share or tie weights across layers could be designed to exploit the guaranteed convergence property.
- The steering technique might be combined with prompt engineering to enforce output constraints without fine-tuning.
Load-bearing premise
The attention and normalization steps inside each layer, when the feed-forward network is ignored, behave like repeated multiplication by the same fixed matrix followed by normalization.
What would settle it
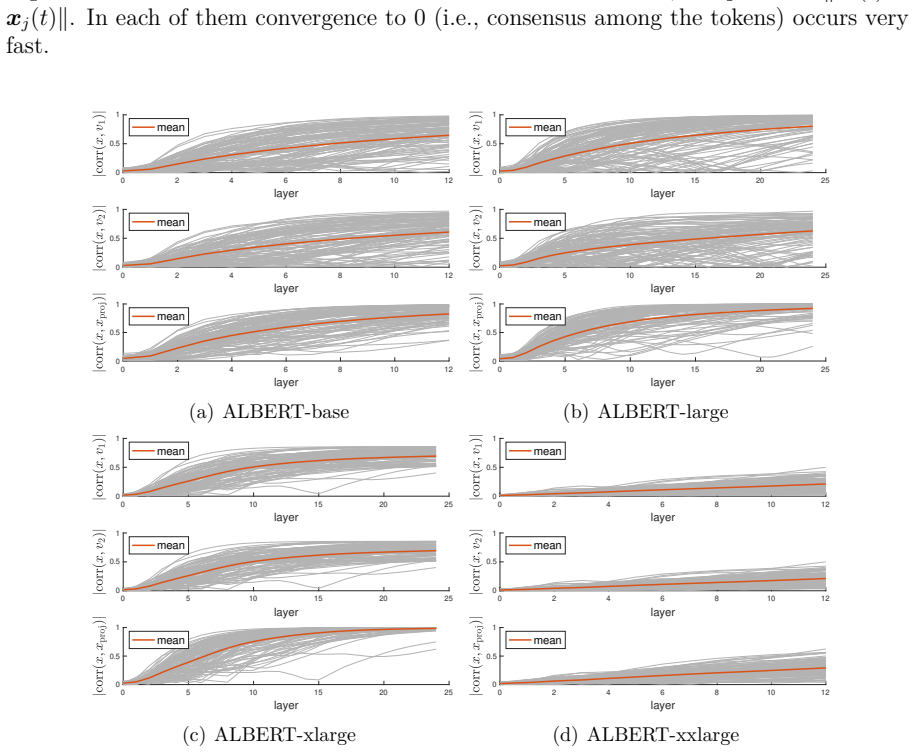
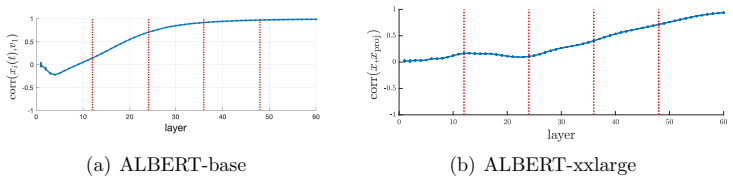
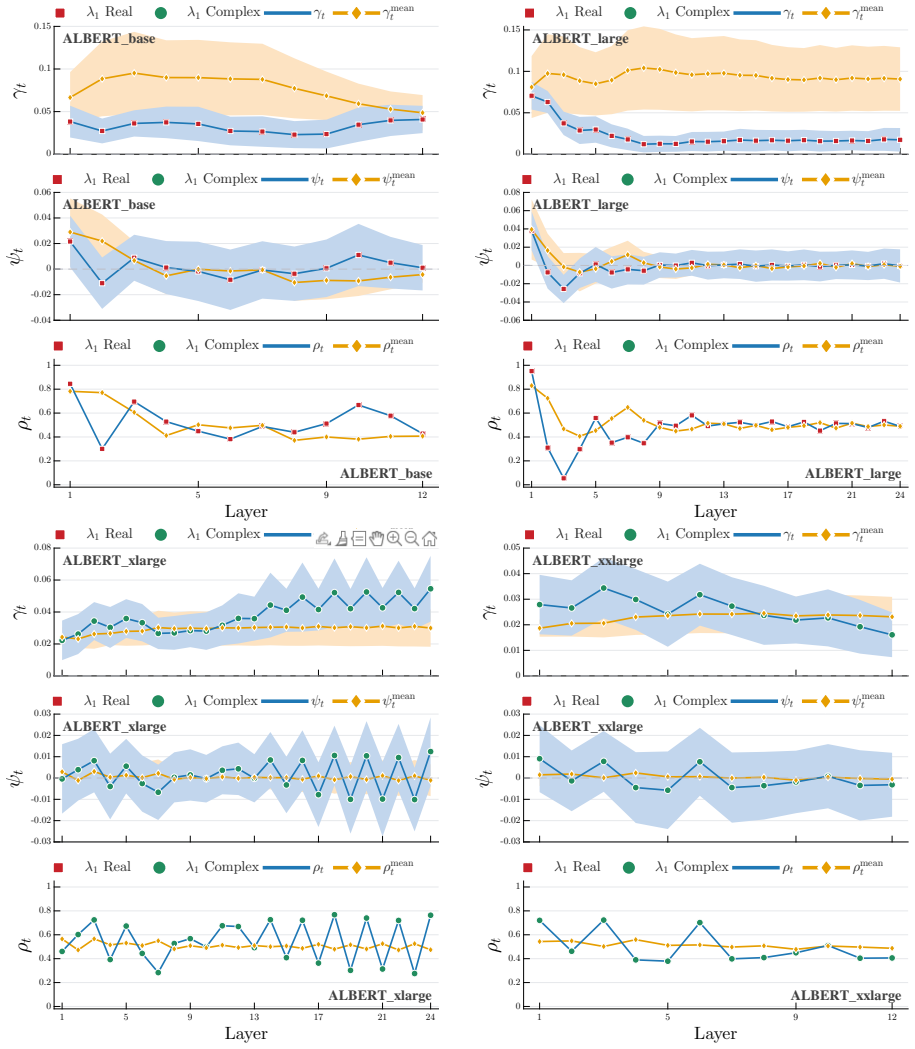
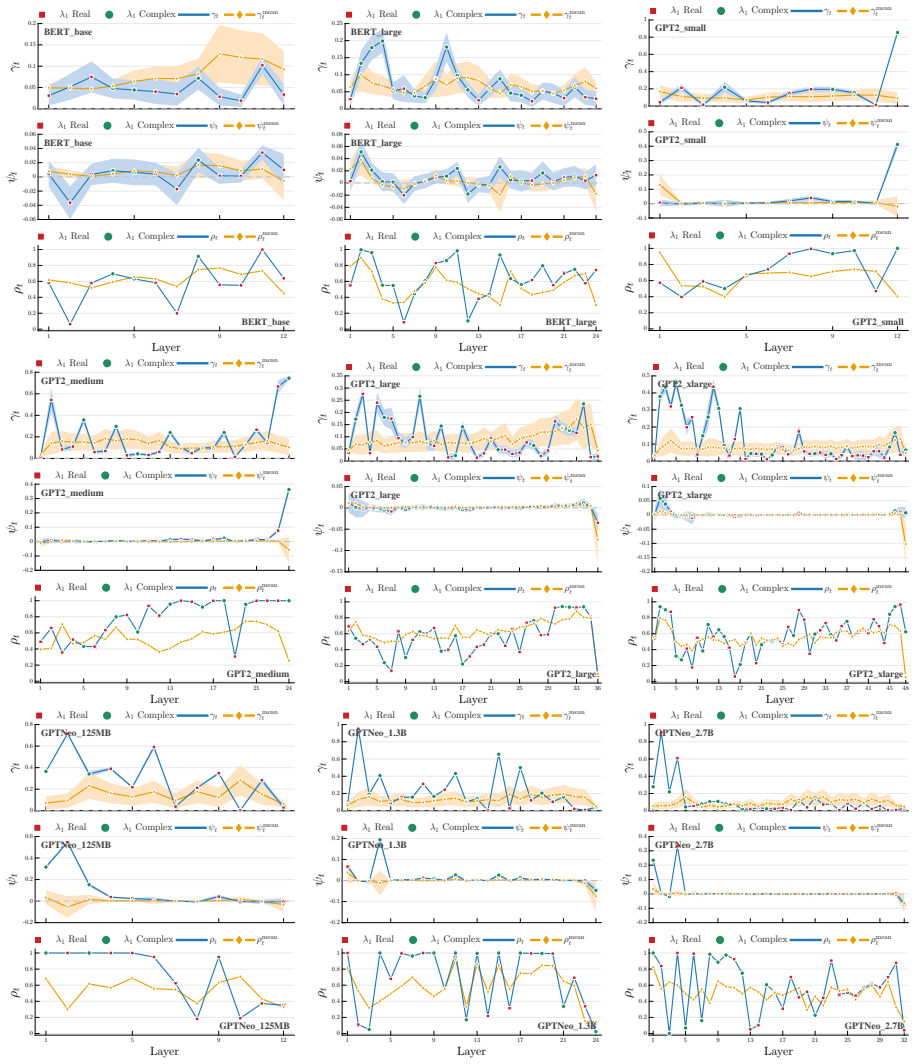
Compute the leading eigenvector of W_o W_v for a given layer, then measure the average cosine similarity of token vectors to this eigenvector immediately before and after the layer; the similarity must increase after the layer if the analogy holds.
Figures
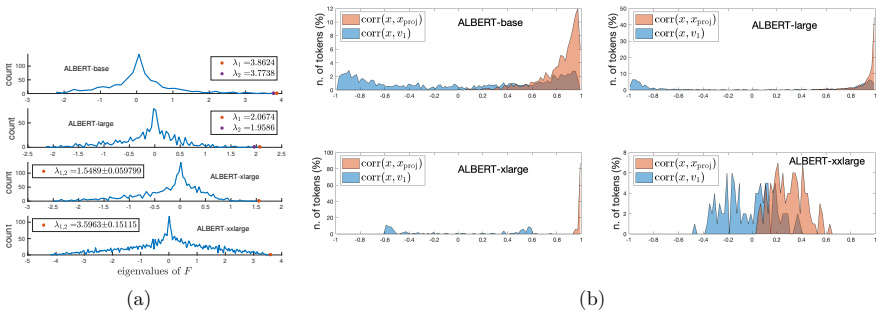
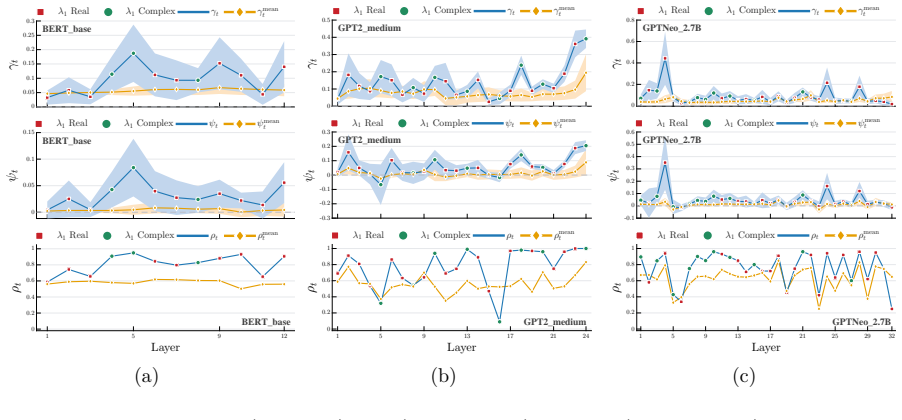
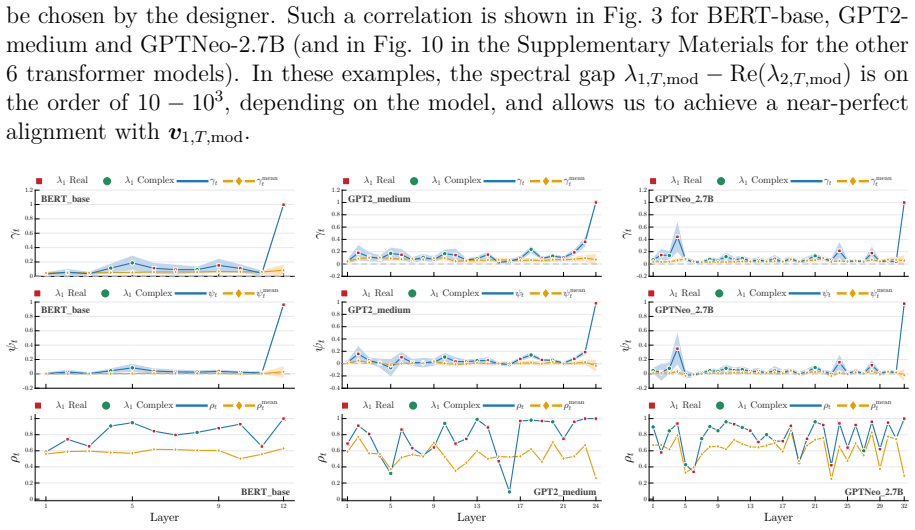
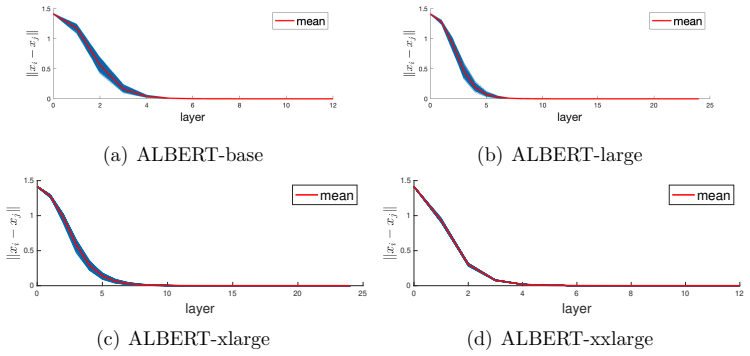




read the original abstract
In the paper we show that there is an analogy between the operations occurring in a layer of a transformer (projections and layer normalizations, disregarding the feedforward neural network) and a step in the power method. Coherently with this analogy, we show that passing through a layer the tokens tend to be tilted towards the principal eigenvector of a matrix which is the product of the output and value weight matrices of that layer. In the special case of a transformer with shared weights (i.e., in which all layers have identical weights) then the alignment with this principal eigenvector is particularly evident empirically, and can also be shown analytically. The analogy also suggests a method to steer the output of the transformer towards an arbitrary desired direction in token space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes an analogy between the linear projections and layer normalization operations in a transformer layer (excluding the feedforward network) and an iteration of the power method. Consequently, it argues that token representations are progressively aligned with the dominant eigenvector of the matrix W_O W_V, where W_O and W_V are the output and value projection matrices. This alignment is empirically demonstrated and analytically proven in the special case of shared-weight transformers, and the analogy is leveraged to propose a steering technique for directing the model's output.
Significance. Should the analogy and supporting derivations prove robust, this work contributes a mechanistic understanding of how transformer layers process token directions, with particular value in the shared-weight setting where the effect is pronounced. The provision of both empirical validation and an analytical demonstration strengthens the contribution, and the suggested steering method has potential practical implications for controlling generation.
minor comments (3)
- The abstract and introduction should explicitly state the modeling assumptions regarding the attention mechanism (which is not mentioned as disregarded), as the analogy is presented only for projections and layer norm; this affects how broadly the tilting claim applies to a full layer.
- In the empirical section on shared-weight models, include quantitative metrics (e.g., average cosine similarity to the principal eigenvector across tokens and layers) and details on the specific architectures tested to allow replication and assessment of effect size.
- The proposed steering method should be accompanied by ablation results showing its effect relative to simpler baselines (e.g., direct addition of a direction vector) to demonstrate the value added by the power-method analogy.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, recognition of the mechanistic contribution, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation follows from stated analogy and assumptions
full rationale
The paper defines an explicit modeling analogy between (projections + layer norm) and one power iteration, then derives the eigenvector alignment consequence both empirically (shared-weight case) and analytically under that analogy. No step reduces by construction to a fitted parameter renamed as prediction, no self-definitional loop in the equations, and no load-bearing self-citation chain is invoked to justify the core claim. The analytical result for shared weights is presented as following directly from the power-method equivalence under the paper's modeling choices, making the derivation self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Á. R. Abella, J. P. Silvestre, and P. Tabuada. Consensus is all you get: The role of attention in transformers. In Forty-second International Conference on Machine Learning, 2025
2025
- [3]
-
[4]
S. P. Chowdhury, A. Solomou, A. Dubey, and M. Sachan. On learning the trans- former kernel, 2022
2022
-
[5]
arXiv preprint arXiv:1912.02164 , year =
S. Dathathri, A. Madotto, J. Lan, J. Hung, E. Frank, P. Molino, J. Yosinski, and R. Liu. Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164 , 2019
-
[6]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019
2019
-
[7]
Dong, J.-B
Y. Dong, J.-B. Cordonnier, and A. Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In International conference on machine learning , pages 2793–2803. PMLR, 2021
2021
- [8]
-
[9]
Dutta, T
S. Dutta, T. Gautam, S. Chakrabarti, and T. Chakraborty. Redesigning the trans- former architecture with insights from multi-particle dynamical systems. Advances in Neural Information Processing Systems , 34:5531–5544, 2021
2021
-
[10]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
B. Geshkovski, H. Koubbi, Y. Polyanskiy, and P. Rigollet. Dynamic metastability in the self-attention model. arXiv preprint arXiv:2410.06833 , 2024
-
[12]
Geshkovski, C
B. Geshkovski, C. Letrouit, Y. Polyanskiy, and P. Rigollet. The emergence of clusters in self-attention dynamics. Advances in Neural Information Processing Systems , 36:57026–57037, 2023
2023
-
[13]
Geshkovski, C
B. Geshkovski, C. Letrouit, Y. Polyanskiy, and P. Rigollet. A mathematical perspec- tive on transformers. Bulletin of the American Mathematical Society , 62(3):427–479, 2025. 13
2025
-
[14]
A. Giorlandino and S. Goldt. Two failure modes of deep transformers and how to avoid them: a unified theory of signal propagation at initialisation. arXiv preprint arXiv:2505.24333, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models, 2021
2021
-
[16]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Ha- jishirzi, and A. Farhadi. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. Albert: A lite bert for self-supervised learning of language representations, 2020
2020
-
[18]
Lester, R
B. Lester, R. Al-Rfou, and N. Constant. The power of scale for parameter-efficient prompt tuning, 2021
2021
-
[19]
arXiv preprint arXiv:2106.03764 , year=
V. Likhosherstov, K. Choromanski, and A. Weller. On the expressive power of self- attention matrices. ArXiv, abs/2106.03764, 2021
-
[20]
Y. Lu, Z. Li, D. He, Z. Sun, B. Dong, T. Qin, L. Wang, and T.-Y. Liu. Understanding and improving transformer from a multi-particle dynamic system point of view. arXiv preprint arXiv:1906.02762, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[21]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information ...
2023
-
[22]
Nguyen, T
T. Nguyen, T. Nguyen, and R. Baraniuk. Mitigating over-smoothing in transformers via regularized nonlocal functionals. Advances in Neural Information Processing Systems, 36:80233–80256, 2023
2023
-
[23]
L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, and A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. Advances in Neural Information Processing Systems , 35:27198–27211, 2022
2022
-
[24]
Oja and J
E. Oja and J. Karhunen. On stochastic approximation of the eigenvectors and eigenvalues of the expectation of a random matrix. Journal of mathematical analysis and applications , 106(1):69–84, 1985
1985
-
[25]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners. 2019
2019
- [26]
-
[27]
M. E. Sander, P. Ablin, M. Blondel, and G. Peyré. Sinkformers: Transformers with doubly stochastic attention. In International Conference on Artificial Intelligence and Statistics , pages 3515–3530. PMLR, 2022
2022
-
[28]
M. Scholkemper, X. Wu, A. Jadbabaie, and M. T. Schaub. Residual connections and normalization can provably prevent oversmoothing in gnns. arXiv preprint arXiv:2406.02997, 2024
-
[29]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
S. Schulhoff, M. Ilie, N. Balepur, K. Kahadze, A. Liu, C. Si, Y. Li, A. Gupta, H. Han, S. Schulhoff, et al. The prompt report: A systematic survey of prompt engineering techniques. arXiv preprint arXiv:2406.06608 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [30]
-
[31]
T. Shin, Y. Razeghi, R. L. Logan IV, E. Wallace, and S. Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 4222–4235, 2020
2020
-
[32]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. Mac- Diarmid. Steering language models with activation engineering, 2024
2024
-
[33]
Ustaomeroglu and G
M. Ustaomeroglu and G. Qu. A theoretical study of (hyper) self-attention through the lens of interactions: Representation, training, generalization, 2025
2025
-
[34]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information pro- cessing systems , 30, 2017
2017
-
[35]
X. Wu, A. Ajorlou, Y. Wang, S. Jegelka, and A. Jadbabaie. On the role of attention masks and layernorm in transformers. Advances in Neural Information Processing Systems, 37:14774–14809, 2024
2024
-
[36]
Yoshizawa, U
S. Yoshizawa, U. Helmke, and K. Starkov. Convergence analysis for principal com- ponent flows. International Journal of Applied Mathematics and Computer Science , 11(1):223–236, 2001
2001
-
[37]
Zelikman, Y
E. Zelikman, Y. Wu, J. Mu, and N. D. Goodman. Star: Bootstrapping reasoning with reasoning, 2022
2022
-
[38]
layer matrix
S. Zhai, T. Likhomanenko, E. Littwin, D. Busbridge, J. Ramapuram, Y. Zhang, J. Gu, and J. M. Susskind. Stabilizing transformer training by preventing attention entropy collapse. In International Conference on Machine Learning , pages 40770– 40803. PMLR, 2023. 15 Supplementary Materials A Relation to the Standard Transformer Formula- tion The main paper ad...
2023
-
[41]
FV Pn j=1 xj = 0}
polygonal equilibria: {xi ∈ Sd−1 s.t. FV Pn j=1 xj = 0}. Proof. An equilibrium point xi satisfies x+ i = xi for all i, hence, from (10), xi = ˜xi ∥ ˜xi∥ , which implies that ˜xi and xi must be collinear, i.e., ˜xi = φxi for some φ ∈ R. If y = 1 n FV Pn j=1 xj, then from (10), ˜xi = xi + ηy holds iff also y and xi are collinear or y = 0. This condition can...
-
[42]
consensus: y = φixi, for some scalar φi > 0; 27
-
[43]
bipartite consensus: y = −φixi, for some scalar φi > 0
-
[44]
In fact, in the first two cases, Πxixi = ±φi(xi − xi(xi)T xi) = 0 , since (xi)T xi = 1
polygonal equilibria: y = 0. In fact, in the first two cases, Πxixi = ±φi(xi − xi(xi)T xi) = 0 , since (xi)T xi = 1 . The third case follows trivially. To show that consensus must be an eigenvector of FV , observe that at this equilibrium point we have y = FV xi, since xi = xj. Combining with y = φixi, we have FV xi = φixi, i.e., xi is an eigenvector of F...
-
[45]
if 1 + ηλk > 0, 1−ηλk+η2λ2 k 1+ηλk of multiplicity n, while if 1 + ηλk < 0, −1−3ηλk+η2λ2 k 1+ηλk of multiplicity 1 and −1−ηλk+η2λ2 k 1+ηλk of multiplicity n − 1
-
[46]
, k− 1, k + 1,
1+ηλh |1+ηλk| of multiplicity 1, h = 1, . . . , k− 1, k + 1, . . . , d
-
[47]
1 |1+ηλk| of multiplicity nd − d − n + 1. Proof. When computing the Jacobian (11) at the consensus xi = vk ∀ i, we get J(vk) = ∂f (x) ∂x xi=vk = 11T ⊗ sgn(1 + ηλk) η n FV − η n λkvkvT k 1 + ηλk + I ⊗ sgn(1 + ηλk)I − ηλk(1 − ηλk)vkvT k 1 + ηλk . (12) where we have used vT k (I − vkvT k ) = 0 . The first term represents a factor present in all entries of J(...
-
[48]
If 1 + ηλk > 0, then choose p = [0
The eigenvectors of the first class depend on the sign of 1 + ηλk. If 1 + ηλk > 0, then choose p = [0 . . . 0 vk 0 . . . 0] and compute the two components of J(vk): ( sgn(1+ηλk) η n FV − η n λkvkvT k 1+ηλk vk = η n (1−1) 1+ηλk vk = 0 sgn(1+ηλk)I−ηλk(1−ηλk)vkvT k 1+ηλk vk = 1−ηλk(1−ηλk) 1+ηλk vk meaning that J(vk)p = 1 − ηλk + η2λ2 k 1 + ηλk p i.e., 1−ηλk+...
-
[49]
For the second class of eigenvectors choosing qh = [vh . . . vh] for h ̸= k, leads to ( sgn(1+ηλk) η n FV − η n λkvkvT k 1+ηλk vh = η n λh |1+ηλk| vh sgn(1+ηλk)I−ηλk(1−ηλk)vkvT k 1+ηλk vh = 1 |1+ηλk| vh and hence to J(vk)qh = 1 + ηλh |1 + ηλk| qh i.e., 1+ηλh |1+ηλk| is an eigenvalue of J(vk). There are d − 1 such eigenvalues. 30
-
[50]
extrinsic Jacobian
The remaining nd − d − n + 1 eigenvectors are assembled by considering vectors r = (z1)T (z2)T . . . (zn)T T s.t. vT k zi = 0 for all i = 1 , . . . , n and all h = 1, . . . , k − 1, k + 1, . . . , d and qT h r = 0 . Since the number of such constraints is d − 1 + n, there exist nd − n − d + 1 such vectors r, and they can always be chosen so that Pn i=1 zi...
-
[51]
If 1+ηλk > 0, then we have 1+ηλ1 1+ηλk > 1 because this is equivalent to 1+ηλ1 > 1+ηλk
-
[52]
intrinsic
If 1+ηλk < 0, then we must show that it is − 1+ηλ1 1+ηλk > 1, i.e., that 1+ηλ1 > −1−ηλk, or η(λ1 + λk) > −2. As λ1 + λk < 0, the expression holds if it holds for the largest possible value of η. Taking η = 2 |λ1+λd| , we obtain the following inequality − 2(λ1+λk) λ1+λd > −2, or, equivalently, λ1 + λk > λ 1 + λd which is always true. 31 In both situations ...
-
[53]
consensus: xi = vk ∀ i, and k = 1, . . . , d
-
[54]
bipartite consensus: xi = ±vk ∀ i and k = 1, . . . , d
-
[55]
FV Pn j=1 Aij(x)xj = 0}, i = 1,
polygonal equilibria: {xi ∈ Sd−1 s.t. FV Pn j=1 Aij(x)xj = 0}, i = 1, . . . , n
-
[56]
consensus
clustering equilibria: {xi ∈ Sd−1 s.t. φixi = FV Pn j=1 Aij(x)xj} for some scalars φi, i = 1, . . . , n, k = 1, . . . , d. Proof. Once we replace y with yi =Pn j=1 Aij(x)FV xj, the proof of the first three cases is identical to that of Lemma 1. The clustering equilibria correspond to yi ∈ ker(I − xixT i ), or, equivalently, yi aligned with xi, i = 1 , . ....
-
[57]
Denote also γk 1 = n1αk 1 −n2αk 2 βk 1 and γk 2 = n2αk 1 −n1αk 2 βk 2 . Theorem 3 For the self-attention dynamics (8), under Assumption 1, and, if −λd > λ 1, for η < 2 |λ1+λd| , the consensus equilibrium associated to the principal eigenvector v1 of FV is always locally asymptotically stable, while the other consensus equilibria vk, k = 2, . . . , d, are ...
-
[58]
|1−(1−ηλkγk i )ηλkγk i | 1+ηλkγk i < 1, i = 1, 2
-
[59]
, k− 1, k + 1,
ak j dk j − bk j ck j < 1 and ak j + dk j < 1 +ak j dk j − bk j ck j , ∀ j = 1, . . . , k− 1, k + 1, . . . , d, where ak j = 1 + ηn1 αk 1 βk 1 λj 1 + ηλkγk 1 , bk j = ηn2 αk 2 βk 1 λj 1 + ηλkγk 1 , ck j = ηn1 αk 2 βk 2 λj 1 + ηλkγk 2 , dk j = 1 + ηn2 αk 1 βk 2 λj 1 + ηλkγk 2 (14)
-
[60]
All polygonal equilibria are unstable
1 1+ηλkγk i < 1, i = 1, 2. All polygonal equilibria are unstable. The proof, based on Lyapunov indirect method, is broken down into various lemmas. As in Section D.2, let fi(x) be the right-hand side of (8) and f (x) its vectorization. The (extrinsic, see Remark 2) Jacobian of f (x) is as follows. 38 Lemma 10 The Jacobian of (8), J(x) = ∂f (x) ∂x = h ∂fi(...
-
[61]
1−(1−ηλkγk 1 )ηλkγk 1 1+ηλkγk 1 of multiplicity n1, and 1−(1−ηλkγk 2 )ηλkγk 2 1+ηλkγk 2 of multiplicity n2
-
[62]
, k − 1, k + 1,
µk j,± = 1 2 ak j + dk j ± q (ak j − dk j )2 + 4ck j bk j for j = 1 , . . . , k − 1, k + 1, . . . , d, where ak j , bk j , ck j and dk j are given by (14)
-
[63]
1 1+ηλkγk 1 and 1 1+ηλkγk 2 , of total multiplicity nd − n − 2d + 2. Proof. For J(±vk) there are 3 classes of eigenvectors:
-
[64]
0| {z } ℓ−1 vT k 0
If 1 + ηλkγk i > 0, i = 1, 2, then choose pℓ = [ 0 . . . 0| {z } ℓ−1 vT k 0 . . . 0| {z } n−ℓ ]T . There are n such eigenvectors, and they are obviously all orthogonal to each other. For ℓ ≤ n1 it is 8 >>>>>< >>>>>: J 11 o vk = η αk 1 βk 1 (FV −λkvkvT k ) 1+ηλkγk 1 vk = η αk 1 βk 1 (λkvk−λkvk) 1+ηλkγk 1 = 0 J 21 o vk = η αk 2 βk 2 (FV −λkvkvT k ) 1+ηλkγk ...
-
[65]
qh = [ (wh 1 )T
Second class: Consider d−1 vectors qh s.t. qh = [ (wh 1 )T . . . (wh 1 )T | {z } n1 times (wh 2 )T . . . (wh 2 )T | {z } n2 times ]T , with wh 1 =Pd j=1 ξh,1 j vj and wh 2 =Pd j=1 ξh,2 j vj. Choose wh i s.t. ξh,i k = 0 , so that vT k wh i = 0. We have J 11 o wh 1 = η αk 1 βk 1 P j̸=k λjξh,1 j vj 1 + ηλkγk 1 J 12 o wh 2 = η αk 2 βk 1 P j̸=k λjξh,2 j vj 1 +...
-
[66]
extrinsic
The third class contains the nd − n − 2d + 2 remaining eigenvectors subdivided into two groups: r1 = ϵ1vT h . . . ϵ n1vT h 0 . . . 0 T and r2 = 0 . . . 0 ε1vT h . . . ε n2vT h T where vh is an eigenvector of FV , h ̸= k, and Pn1 j=1 ϵj = 0 ,Pn2 j=1 εj = 0 . By con- struction, vT k vh = 0 and (wj ℓ )T vh = 0 for all j = 1 , . . . , k − 1, k + 1, . . . , d ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.