Active Query Synthesis for Preference Learning
Pith reviewed 2026-06-29 22:20 UTC · model grok-4.3
The pith
A continuous-space query synthesis method paired with a confidence-aware response model makes active preference learning more efficient by avoiding unreliable comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
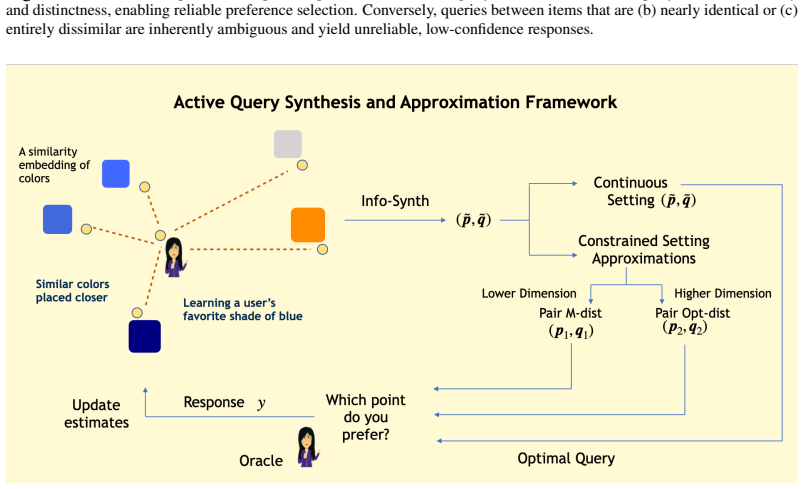
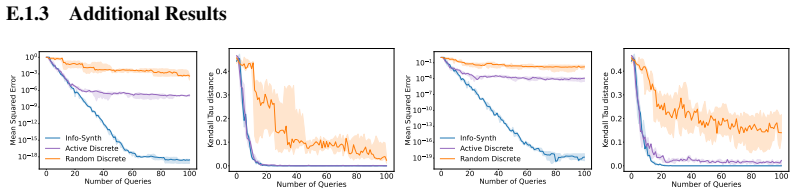
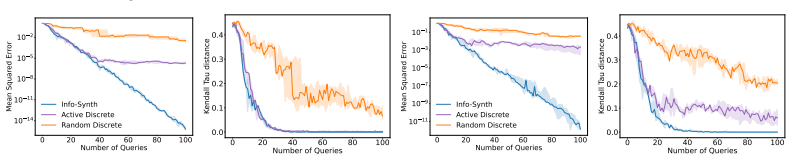
The authors claim that a confidence-aware response model combined with the Info-Synth framework, which maximizes mutual information to generate queries in continuous space, overcomes both the computational expense of pool-based active learning and the problem of unreliable feedback from ambiguous comparisons, leading to more efficient preference acquisition across multiple domains.
What carries the argument
Info-Synth, an active query synthesis framework that maximizes a mutual information objective over a continuous query space, together with a confidence-aware response model that assigns lower reliability to ambiguous pairwise comparisons.
If this is right
- Preference learning systems can generate queries without first enumerating a large discrete pool, lowering per-iteration computation.
- Explicit modeling of response confidence reduces the impact of low-information comparisons on the learned preference function.
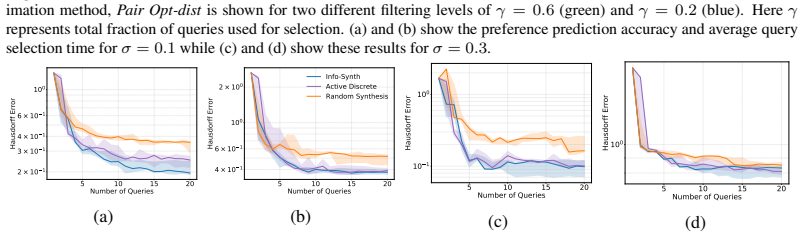
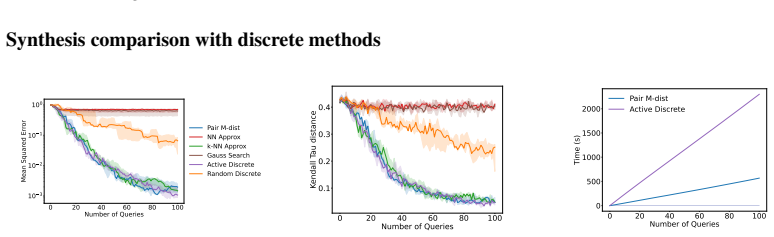
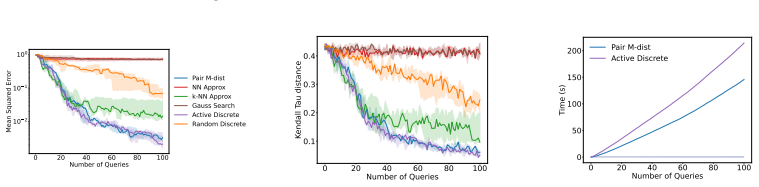
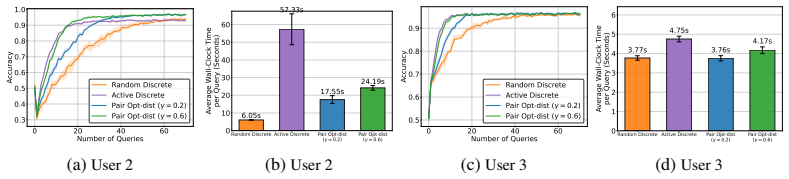
- The same mutual-information synthesis approach extends to finite pools through the Pair M-dist and Pair Opt-dist selection rules.
- The framework applies without modification to both synthetic preference data and real tasks such as text summary ranking and continuous controller tuning.
Where Pith is reading between the lines
- The continuous-space formulation may allow the same machinery to be reused for other active learning problems whose query spaces are naturally continuous rather than discrete.
- Modeling per-query confidence could be combined with existing preference models that already output uncertainty estimates, potentially improving sample efficiency further.
- If the optimization of the mutual information objective scales reliably, the method could support interactive systems where new queries must be generated on the fly from user responses.
Load-bearing premise
The mutual information objective defined over a continuous query space can be optimized tractably and the confidence model accurately represents real user ambiguity without creating new fitting problems that hurt overall performance.
What would settle it
A controlled experiment on one of the paper's datasets in which Info-Synth is run to completion yet produces no measurable reduction in the number of queries needed to reach a target preference model accuracy compared with standard pool-based active learning.
Figures

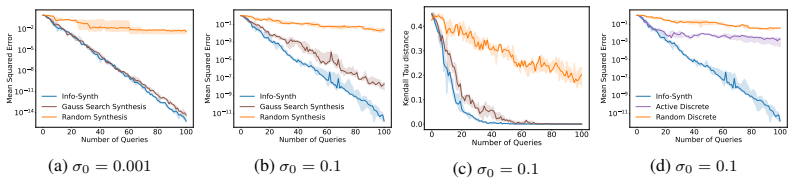
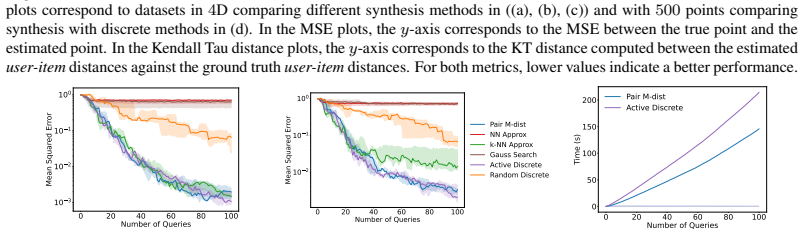
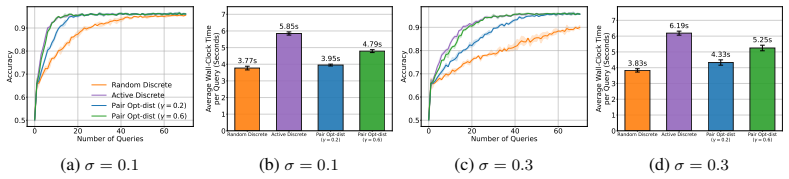

read the original abstract
Efficient learning of user preferences is crucial for many modern decision making systems but typically requires costly labeled data. Active learning reduces this cost, yet standard methods are computationally expensive due to pool-based evaluation. Further, most methods assume all query feedback is equally reliable, ignoring that pairwise queries between nearly identical or entirely dissimilar items yield ambiguous, low-confidence responses. To address the issue of feedback reliability, we introduce a novel confidence aware response model that explicitly accounts for these ambiguous comparisons. To overcome the computational bottleneck of pool-based evaluation, we propose an active query synthesis framework, Info-Synth that generates optimal queries by maximizing a mutual information-based objective within a continuous space. Moreover, we propose two strategies, Pair M-dist and Pair Opt-dist, that extend Info-Synth to select effective queries even when restricted to finite query pools. We demonstrate our framework's versatility and performance across synthetic preference learning, constrained text summary datasets, and subjective, continuous-space controller gain tuning for a simulated mobile robot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a confidence-aware response model to explicitly handle ambiguous pairwise comparisons in preference learning and proposes the Info-Synth active query synthesis framework, which generates optimal queries by maximizing a mutual information objective over a continuous query space; it also provides two pool-based extensions (Pair M-dist and Pair Opt-dist) and evaluates the approach on synthetic preference data, constrained text summarization, and simulated robot controller gain tuning.
Significance. If the continuous-space MI maximization proves tractable without hidden fitting artifacts in the confidence model, the work would offer a meaningful advance over standard pool-based active preference learning by simultaneously addressing feedback reliability and computational cost, with potential impact on recommendation systems and human-in-the-loop control.
major comments (1)
- [Info-Synth framework description] The central claim of computational advantage rests on tractable optimization of the mutual information objective in continuous space, yet the manuscript provides no description of the optimizer, the MI estimator, or differentiability assumptions on the response model (see the description of Info-Synth and the optimization procedure). Without these details the claimed superiority over pool-based methods cannot be verified and the framework's practicality remains unestablished.
minor comments (2)
- [Abstract] The abstract states that Pair M-dist and Pair Opt-dist 'extend Info-Synth' to finite pools, but the precise relationship between the continuous objective and these discrete strategies is not made explicit until later sections.
- [Response model section] Notation for the confidence-aware response model (e.g., how the ambiguity parameter enters the likelihood) should be introduced with an equation in the model section for clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for greater clarity on the optimization aspects of Info-Synth. We agree that the current description is insufficient to fully substantiate the claimed computational advantages and will revise the manuscript to include the requested details.
read point-by-point responses
-
Referee: The central claim of computational advantage rests on tractable optimization of the mutual information objective in continuous space, yet the manuscript provides no description of the optimizer, the MI estimator, or differentiability assumptions on the response model (see the description of Info-Synth and the optimization procedure). Without these details the claimed superiority over pool-based methods cannot be verified and the framework's practicality remains unestablished.
Authors: We acknowledge that the manuscript's description of the Info-Synth optimization procedure is too brief and lacks the necessary specifics. The mutual information objective is maximized via gradient-based optimization (specifically, Adam optimizer with a fixed learning rate schedule), using a Monte Carlo estimator for the MI term with 128 samples drawn from the posterior over user preferences. The confidence-aware response model is constructed to be fully differentiable, employing a temperature-scaled softmax over a continuous distance metric between query pairs, which permits direct backpropagation through the objective. We will add a dedicated subsection (approximately 1 page) in the revised manuscript detailing the optimizer choice, sample count, convergence criteria, and explicit differentiability proof sketch. This revision will enable readers to reproduce and verify the tractability claims relative to pool-based baselines. revision: yes
Circularity Check
No significant circularity; new models and MI objective are proposed contributions
full rationale
The paper proposes a novel confidence-aware response model and the Info-Synth framework that defines and maximizes a mutual information objective over continuous query space. These elements are introduced as original methodological contributions rather than derived from or reducing to prior fitted parameters, self-citations, or inputs by construction. Extensions to finite pools (Pair M-dist, Pair Opt-dist) are presented as additional strategies. No equations or claims in the provided text exhibit self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations; the work is a self-contained proposal validated empirically on synthetic, text, and robotics tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guest editorial annotation-efficient deep learning: the holy grail of medical imaging.IEEE transactions on medical imaging, 40(10):2526–2533, 2021
Nima Tajbakhsh, Holger Roth, Demetri Terzopoulos, and Jianming Liang. Guest editorial annotation-efficient deep learning: the holy grail of medical imaging.IEEE transactions on medical imaging, 40(10):2526–2533, 2021
2021
-
[2]
N segment: Label-specific deformations for remote sensing image segmentation.IEEE Geoscience and Remote Sensing Letters, 2025
Yechan Kim, DongHo Yoon, SooYeon Kim, and Moongu Jeon. N segment: Label-specific deformations for remote sensing image segmentation.IEEE Geoscience and Remote Sensing Letters, 2025
2025
-
[3]
Batched bayesian optimization for drug design in noisy environments.Journal of Chemical Information and Modeling, 62(17):3970–3981, 2022
Hugo Bellamy, Abbi Abdel Rehim, Oghenejokpeme I Orhobor, and Ross King. Batched bayesian optimization for drug design in noisy environments.Journal of Chemical Information and Modeling, 62(17):3970–3981, 2022
2022
-
[4]
A comprehensive benchmark of active learning strategies with automl for small-sample regression in materials science.Scientific Reports, 15(1):37167, 2025
Jinghou Bi, Yuanhao Xu, Felix Conrad, Hajo Wiemer, and Steffen Ihlenfeldt. A comprehensive benchmark of active learning strategies with automl for small-sample regression in materials science.Scientific Reports, 15(1):37167, 2025
2025
-
[5]
Active learning literature survey
Burr Settles. Active learning literature survey. 2009
2009
-
[6]
Active learning on medical image
Angona Biswas, Nasim Md Abdullah Al, Md Shahin Ali, Ismail Hossain, Md Azim Ullah, and Sajedul Talukder. Active learning on medical image. InData Driven Approaches on Medical Imaging, pages 51–67. Springer, 2023
2023
-
[7]
Active learning in the drug discovery process.Advances in Neural information processing systems, 14, 2001
Manfred KK Warmuth, Gunnar R ¨atsch, Michael Mathieson, Jun Liao, and Christian Lemmen. Active learning in the drug discovery process.Advances in Neural information processing systems, 14, 2001
2001
-
[8]
Active learning via query synthesis and nearest neighbour search.Neurocomputing, 147:426–434, 2015
Liantao Wang, Xuelei Hu, Bo Yuan, and Jianfeng Lu. Active learning via query synthesis and nearest neighbour search.Neurocomputing, 147:426–434, 2015
2015
-
[9]
Active preference-based learning of reward functions
Dorsa Sadigh, Anca D Dragan, Shankar Sastry, and Sanjit A Seshia. Active preference-based learning of reward functions. InProceedings of Robotics: Science and Systems (RSS), 2017
2017
-
[10]
Preference learning with gaussian processes
Wei Chu and Zoubin Ghahramani. Preference learning with gaussian processes. InProceed- ings of the 22nd international conference on Machine learning, pages 137–144, 2005
2005
-
[11]
London, 1963
Herbert Aron David.The method of paired comparisons, volume 12. London, 1963
1963
-
[12]
Random search for hyper-parameter optimization.Journal of machine learning research, 13(2), 2012
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization.Journal of machine learning research, 13(2), 2012
2012
-
[13]
Learn- ing controller gains on bipedal walking robots via user preferences
Noel Csomay-Shanklin, Maegan Tucker, Min Dai, Jenna Reher, and Aaron D Ames. Learn- ing controller gains on bipedal walking robots via user preferences. In2022 International Conference on Robotics and Automation (ICRA), pages 10405–10411. IEEE, 2022
2022
-
[14]
Psychological scaling without a unit of measurement.Psychological review, 57(3):145, 1950
Clyde H Coombs. Psychological scaling without a unit of measurement.Psychological review, 57(3):145, 1950
1950
-
[15]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[16]
Active embedding search via noisy paired comparisons
Gregory Canal, Andy Massimino, Mark Davenport, and Christopher Rozell. Active embedding search via noisy paired comparisons. InInternational Conference on Machine Learning, pages 902–911. PMLR, 2019
2019
-
[17]
Scalable and efficient comparison-based search without features
Daniyar Chumbalov, Lucas Maystre, and Matthias Grossglauser. Scalable and efficient comparison-based search without features. InInternational Conference on Machine Learn- ing, pages 1995–2005. PMLR, 2020
1995
-
[18]
Preference-based learning for exoskeleton gait optimization
Maegan Tucker, Ellen Novoseller, Claudia Kann, Yanan Sui, Yisong Yue, Joel W Burdick, and Aaron D Ames. Preference-based learning for exoskeleton gait optimization. In2020 IEEE international conference on robotics and automation (ICRA), pages 2351–2357. IEEE, 2020. 10
2020
-
[19]
Roial: Region of interest active learning for char- acterizing exoskeleton gait preference landscapes
Kejun Li, Maegan Tucker, Erdem Bıyık, Ellen Novoseller, Joel W Burdick, Yanan Sui, Dorsa Sadigh, Yisong Yue, and Aaron D Ames. Roial: Region of interest active learning for char- acterizing exoskeleton gait preference landscapes. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 3212–3218. IEEE, 2021
2021
-
[20]
Erdem Bıyık, Malayandi Palan, Nicholas C Landolfi, Dylan P Losey, and Dorsa Sadigh. Asking easy questions: A user-friendly approach to active reward learning.arXiv preprint arXiv:1910.04365, 2019
-
[21]
A bayesian interactive optimiza- tion approach to procedural animation design
Eric Brochu, Tyson Brochu, and Nando De Freitas. A bayesian interactive optimiza- tion approach to procedural animation design. InProceedings of the 2010 ACM SIG- GRAPH/Eurographics Symposium on Computer Animation, pages 103–112, 2010
2010
-
[22]
Preferential bayesian optimization
Javier Gonz ´alez, Zhenwen Dai, Andreas Damianou, and Neil D Lawrence. Preferential bayesian optimization. InInternational Conference on Machine Learning, pages 1282–1291. PMLR, 2017
2017
-
[23]
Batch active preference-based learning of reward functions
Erdem Biyik and Dorsa Sadigh. Batch active preference-based learning of reward functions. InConference on robot learning, pages 519–528. PMLR, 2018
2018
-
[24]
Human-in-the-loop controller tuning using preferential bayesian optimization.IFAC-PapersOnLine, 58(14):13–18, 2024
Joao PL Coutinho, Ivan Castillo, and Marco S Reis. Human-in-the-loop controller tuning using preferential bayesian optimization.IFAC-PapersOnLine, 58(14):13–18, 2024
2024
-
[25]
Safe controller optimization for quadrotors with gaussian processes
Felix Berkenkamp, Angela P Schoellig, and Andreas Krause. Safe controller optimization for quadrotors with gaussian processes. In2016 IEEE International Conference on Robotics and Automation (ICRA), pages 491–496. IEEE, 2016
2016
-
[26]
Virtual vs
Alonso Marco, Felix Berkenkamp, Philipp Hennig, Angela P Schoellig, Andreas Krause, Ste- fan Schaal, and Sebastian Trimpe. Virtual vs. real: Trading off simulations and physical ex- periments in reinforcement learning with bayesian optimization. In2017 IEEE International Conference on Robotics and Automation (ICRA), pages 1557–1563. IEEE, 2017
2017
-
[27]
Active heteroscedastic regres- sion
Kamalika Chaudhuri, Prateek Jain, and Nagarajan Natarajan. Active heteroscedastic regres- sion. InInternational Conference on Machine Learning, pages 694–702. PMLR, 2017
2017
-
[28]
Near optimal het- eroscedastic regression with symbiotic learning
Aniket Das, Dheeraj M Nagaraj, Praneeth Netrapalli, and Dheeraj Baby. Near optimal het- eroscedastic regression with symbiotic learning. InThe Thirty Sixth Annual Conference on Learning Theory, pages 3696–3757. PMLR, 2023
2023
-
[29]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[30]
Xinyu Li, Ruiyang Zhou, Zachary C Lipton, and Liu Leqi. Personalized language modeling from personalized human feedback.arXiv preprint arXiv:2402.05133, 2024
-
[31]
Pal: Sample- efficient personalized reward modeling for pluralistic alignment
Daiwei Chen, Yi Chen, Aniket Rege, Zhi Wang, and Ramya Korlakai Vinayak. Pal: Sample- efficient personalized reward modeling for pluralistic alignment. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[32]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained trans- former language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
A stable track- ing control method for an autonomous mobile robot
Yutaka Kanayama, Yoshihiko Kimura, Fumio Miyazaki, and Tetsuo Noguchi. A stable track- ing control method for an autonomous mobile robot. InProceedings., IEEE International Conference on Robotics and Automation, pages 384–389. IEEE, 1990
1990
-
[34]
The bernstein polynomial basis: A centennial retrospective.Computer Aided Geometric Design, 29(6):379–419, 2012
Rida T Farouki. The bernstein polynomial basis: A centennial retrospective.Computer Aided Geometric Design, 29(6):379–419, 2012
2012
-
[35]
Stan: A probabilistic programming language.Journal of statistical software, 76:1–32, 2017
Bob Carpenter, Andrew Gelman, Matthew D Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell. Stan: A probabilistic programming language.Journal of statistical software, 76:1–32, 2017. 11 A Problem setup To estimate the preferences of a userw∈R d, we assume all query items are embedded in the sam...
2017
-
[36]
A is better than B
The link function and entropy-related termg, whereΦ(x)is noise distribution CDF g(f) = Φ(f) log(Φ(f)) + Φ(−f) log(Φ(−f)) C.1 Gradient Derivation The gradient with respect topis obtained via the chain rule ∇pI(p,q) = dH dπ ∇pπ+∇ p (EW [g(f(w))]) = dH dπ ∇pπ+E W dg d f∇pf(w) Derivation of dH dπ dH dπ = log 1−π π 15 Derivation of∇ pπ ∇pπ=E W [Φ′(f)∇ pf(w)] D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.