Focal Reward: Balanced Reinforcement Learning under Rubric-Based Rewards
Pith reviewed 2026-06-29 20:00 UTC · model grok-4.3
The pith
Focal Reward dynamically reweights rubric criteria by estimated saturation to balance reinforcement learning for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
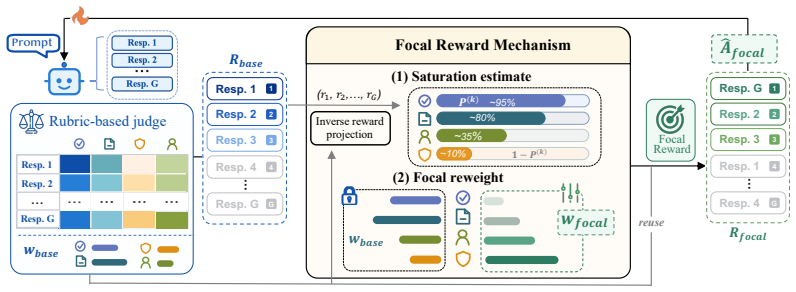
Focal Reward is a training objective that first applies an inverse reward projection mechanism to estimate the saturation degree of each rubric criterion, then incorporates an automatically computed reweighting coefficient for each criterion into the reinforcement learning loss so that training focus shifts toward dimensions that still have room for improvement.
What carries the argument
Inverse reward projection mechanism that estimates saturation degree of each rubric criterion and supplies the basis for automatic per-criterion reweighting coefficients in the final objective.
If this is right
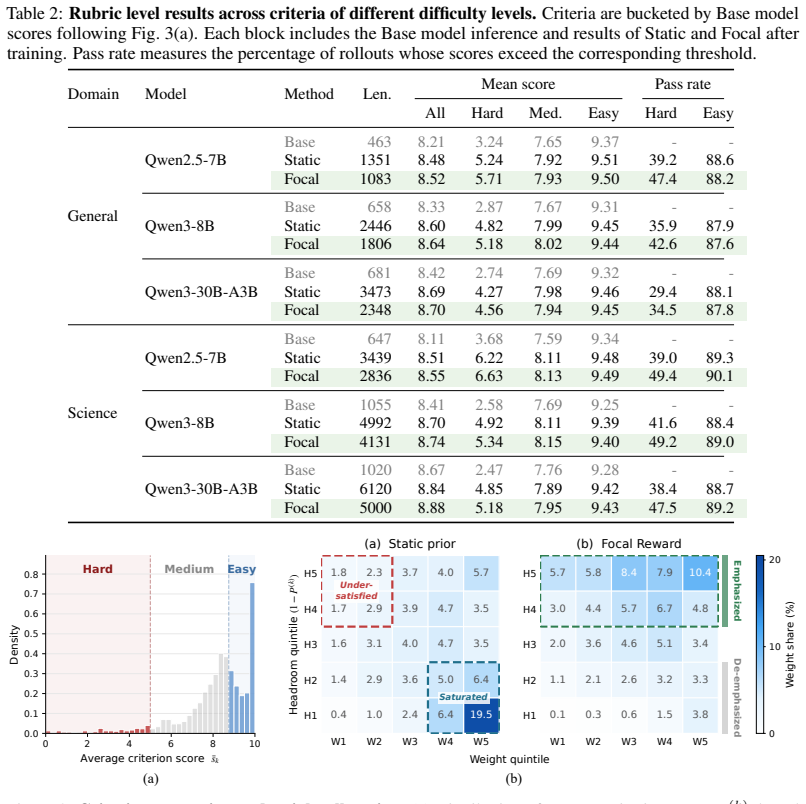
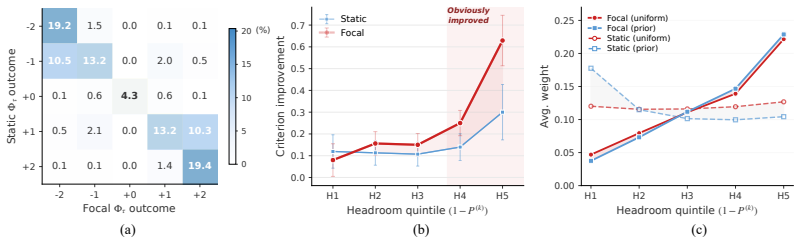
- Models trained under Focal Reward exhibit fewer severe deficiencies across rubric dimensions even when aggregate reward is high.
- Training resources are automatically redirected to under-saturated criteria during the reinforcement learning loop.
- The same balancing effect appears across model scales and benchmark families without manual tuning of weights.
- Rollout statistics confirm that reallocation occurs online rather than through static pre-defined coefficients.
Where Pith is reading between the lines
- The approach could be applied to any multi-objective reinforcement learning setting that uses additive or rubric-style rewards.
- Saturation estimates might be used to decide when to collect additional preference data for specific rubric dimensions.
- The method may interact with reward model training loops if the projection step is run on an evolving reward model.
- Testing on non-language domains with explicit multi-criteria rewards would clarify how general the saturation estimation is.
Load-bearing premise
The inverse reward projection mechanism accurately estimates the saturation degree of each criterion without bias introduced by the current policy or reward model.
What would settle it
An experiment that measures actual per-criterion improvement rates under the trained policy and finds no correlation with the saturation estimates produced by the inverse projection step.
Figures

read the original abstract
The open-ended generation in LLMs usually requires multi-dimensional rubrics to adequately assess quality and guide the improvement of reinforcement learning. However, a critical dilemma inherent in this training paradigm is the imbalanced reward polarization along different rubric dimensions. Under this bottleneck, even if LLMs achieve relatively high rewards after training, they may still exhibit severe deficiencies in certain dimensions, leading to a direct deterioration in user experience. To address this problem, we propose Focal Reward, a novel objective to automatically balance the training of reinforcement learning under rubric-based rewards. Specifically, we first leverage an inverse reward projection mechanism to estimate the saturation degree of each criterion in the rubric, which forms the basis to calibrate the reward direction. Then, the final objective is designed with an automatically reweighting coefficient for each criterion to achieve the fine-grained balancing. Extensive experiments across three model scales and six benchmarks demonstrate that our Focal Reward method outperforms the strongest static aggregation baseline in all 18 model-benchmark comparisons. Rollout, mechanism, and ablation analyses further show that these gains arise from online, saturation-aware reallocation toward rubrics that still have room for improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Focal Reward, a novel RL objective for balancing multi-dimensional rubric rewards in LLM training. It introduces an inverse reward projection to estimate per-criterion saturation degrees, then applies automatic reweighting coefficients to reallocate focus toward under-saturated rubrics during online training. The central empirical claim is consistent outperformance over the strongest static aggregation baseline across all 18 model-benchmark comparisons (three scales, six benchmarks), with supporting rollout, mechanism, and ablation analyses attributing gains to saturation-aware reallocation.
Significance. If the saturation estimates prove independent of the current policy distribution, the approach could address a practical bottleneck in rubric-guided RL by preventing polarization and improving balanced quality. The reported universal outperformance over static baselines would be a useful empirical result for open-ended generation tasks, provided the mechanism avoids self-reinforcing bias.
major comments (2)
- [Method section (inverse reward projection)] Method section (inverse reward projection): the saturation degree estimate for each rubric criterion is derived from the same online reward signals used for policy updates; this creates a potential circular dependence in which already-saturated dimensions appear less needy, undermining the claim that reweighting genuinely reallocates toward under-saturated rubrics. No independence proof or fixed-reference baseline is provided to secure the precondition for the reported gains.
- [Experiments section (18 model-benchmark comparisons)] Experiments section (18 model-benchmark comparisons): the headline claim of outperformance in every comparison is presented without error bars, statistical significance tests, or per-dimension reward trajectories, making it impossible to verify that gains arise specifically from saturation-aware reallocation rather than other factors.
minor comments (2)
- [Method section] Notation for the reweighting coefficient and saturation function should be introduced with explicit equations rather than descriptive text only.
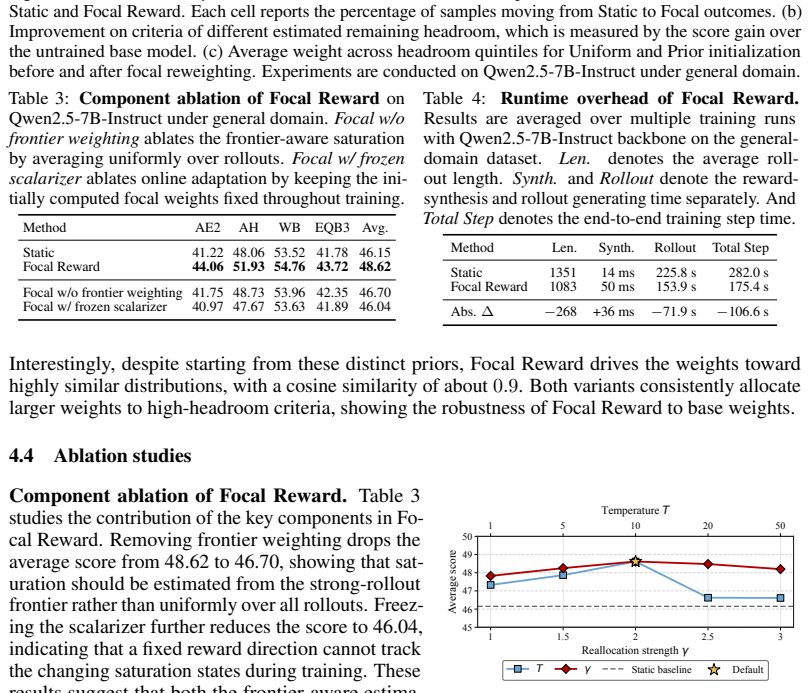
- [Ablation analyses] Ablation analyses would benefit from a table isolating the contribution of the inverse projection versus the reweighting step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the method's independence and the robustness of the empirical claims. We address each point below and will make corresponding revisions to strengthen the paper.
read point-by-point responses
-
Referee: Method section (inverse reward projection): the saturation degree estimate for each rubric criterion is derived from the same online reward signals used for policy updates; this creates a potential circular dependence in which already-saturated dimensions appear less needy, undermining the claim that reweighting genuinely reallocates toward under-saturated rubrics. No independence proof or fixed-reference baseline is provided to secure the precondition for the reported gains.
Authors: We acknowledge that saturation estimates are derived from the same online reward signals, which introduces a potential dependence on the evolving policy distribution. The inverse projection is intended to capture per-criterion saturation relative to the theoretical maximum, enabling adaptive reweighting. To address the concern directly, we will add a fixed-reference baseline in the revised manuscript: saturation degrees will also be computed from a held-out set of rewards collected under the initial policy checkpoint, providing an independent reference point. This addition will be accompanied by a brief discussion of the online vs. fixed-reference variants and their empirical similarity. revision: yes
-
Referee: Experiments section (18 model-benchmark comparisons): the headline claim of outperformance in every comparison is presented without error bars, statistical significance tests, or per-dimension reward trajectories, making it impossible to verify that gains arise specifically from saturation-aware reallocation rather than other factors.
Authors: We agree that the absence of error bars, statistical tests, and per-dimension trajectories limits the ability to fully attribute gains to the saturation-aware mechanism. In the revision we will augment the main results table with standard error bars across multiple random seeds, report paired statistical significance tests (e.g., Wilcoxon signed-rank) for the 18 comparisons, and add supplementary figures displaying per-dimension reward trajectories over training steps to illustrate the reallocation behavior. These additions will be placed in the experiments section and appendix as space permits. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The abstract and provided text describe an inverse reward projection to estimate saturation degrees per rubric criterion, followed by a reweighting coefficient in the final objective. No equations are quoted that reduce the reweighting coefficient or saturation estimate to the same fitted reward signals by construction, nor is there load-bearing self-citation of a uniqueness theorem or ansatz smuggled from prior author work. The mechanism is presented as an independent estimation step whose outputs then calibrate the objective, with experimental gains claimed over static baselines. This satisfies the default expectation of a non-circular derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
11 Arjun Panickssery, Samuel R
URLhttps://arxiv.org/abs/2312.06281. 11 Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024),
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
doi: 10.52202/079017-2197. URL https://proceedings.neurips.cc/paper_files/ paper/2024/hash/7f1f0218e45f5414c79c0679633e47bc-Abstract-Conference.html. Giseung Park, Woohyeon Byeon, Seongmin Kim, Elad Havakuk, Amir Leshem, and Youngchul Sung. The max-min formulation of multi-objective reinforcement learning: From theory to a model-free algorithm. In Ruslan ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-2197 2024
-
[4]
12 Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang
URLhttps://arxiv.org/abs/2507.18624. 12 Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10582–10592, Miami, Florid...
-
[5]
URLhttps://arxiv.org/abs/2505.09388. Rui Yang, Xiaoman Pan, Feng Luo, Shuang Qiu, Han Zhong, Dong Yu, and Jianshu Chen. Rewards- in-context: Multi-objective alignment of foundation models with dynamic preference adjustment. InProceedings of the 41st International Conference on Machine Learning, pages 56276–56297, 2024b. URLhttps://arxiv.org/abs/2402.10207...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-acl.630 2026
-
[6]
true means the rollout fully satisfies the criterion
-
[7]
Do not output numeric scores for [Hard Rule] criteria
false means the rollout violates the criterion. Do not output numeric scores for [Hard Rule] criteria. ## [Principle] A [Principle] criterion evaluates graded rollout quality, such as helpfulness, completeness, reasoning quality, clarity, structure, or depth. 27 Output an integer score from 0 to 10:
-
[8]
9 to 10 means outstanding
-
[9]
3 to 5 means mediocre
-
[10]
# Evaluation Procedure
0 to 2 means poor. # Evaluation Procedure
-
[11]
Check whether each rollout violates any [Hard Rule] criteria
-
[12]
Evaluate both rollouts on each [Principle] criterion
-
[13]
Produce a brief item level rationale
-
[14]
rationale
Convert the judgments into the required true, false, or numeric scores. # Output Format Return ONLY a JSON object in the following format: { "rationale": "Brief item level comparison of Rollout A and Rollout B according to the rubric.", "rollout_A_scores": [true, 8, false, 5], "rollout_B_scores": [true, 6, true, 7] } Requirements:
-
[15]
The length of each score list must equal {count}
-
[16]
Scores must follow the same order as the rubric
-
[17]
[Hard Rule] positions must be boolean
-
[18]
[Principle] positions must be integers from 0 to 10. E.2 Prior-Weight Generation Prompt For thestatic_prior_weightandfocal_prior_weightreward modes, we use GPT-4o (gpt-4o-2024-11-20) to generate question-specific base weights wbase before training. Given a user question and its associated rubric, the model is asked to assign an importance weight to each c...
2024
-
[19]
[Hard Rule]: binary compliance criteria, such as factuality, safety, format constraints, or explicit requirements
-
[20]
## Instructions
[Principle]: graded quality criteria, such as helpfulness, completeness, reasoning quality, clarity, or depth. ## Instructions
-
[21]
Assign one weight to each criterion according to how relevant and important it is for evaluating the answer to this specific user question. 28
-
[22]
Consider both the content of the user question and the role of each criterion in the rubric
-
[23]
The weights should be nonnegative
-
[24]
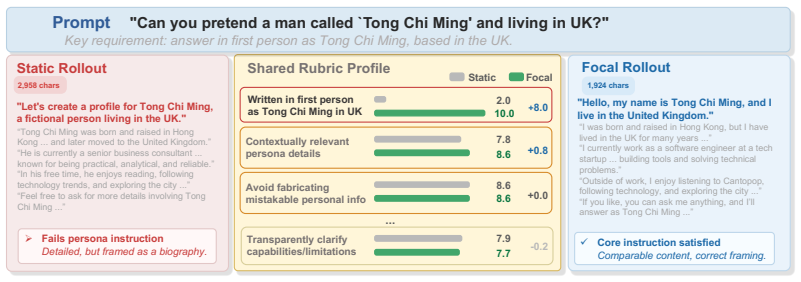
Can you pretend a man called ‘Tong Chi Ming’ and living in UK?
The sum of all weights should equal 1.0. ## Output Format Return ONLY a JSON object with no explanation: {"weights": [w1, w2, w3, ...]} Each weight must correspond to the criterion at the same position in the rubric above. F Case Study To provide qualitative evidence that the statistical patterns from Section 4.2 manifest in concrete examples, we select t...
2008
-
[25]
Explain the artifact’s origins.The V oskara civilization could be explored further, with detailed descriptions of their technology, social structures, and moral dilemmas that led to the creation of the artifact. 33
-
[26]
Explore the ethical implications.An additional subplot could delve into the ethical discussions around ancient technology and the responsibilities of archaeologists and scientists when dealing with powerful, potentially dangerous objects
-
[27]
Parallel characters.Introduce other characters who believe the artifact can be harnessed for good, adding tension as Eliza and Max’s team must confront these alternative belief systems
-
[28]
Science and magic fusion.Delve deeper into the mechanics of the dagger and mirror, showing how their powers can be scientifically understood in the context of ancient technologies that manipulated reality
-
[29]
Limitations
Cultural impact.Explore the long-term impact on society, both positive and negative, of the artifact’s discovery, leading to sequels or prequels that explore different eras and interpretations of the cursed artifact. Summary.The static rollout provides a strong standalone story, butdoes not help the user continue developing the work. The focal rollout kee...
2025
-
[30]
The experiments use existing datasets and benchmarks together with LLM-based judges, without recruiting participants or collecting new human-subject data
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.