When Muon Optimizer Meets Adversarial Training: A Theoretical and Empirical Study
Pith reviewed 2026-06-29 19:38 UTC · model grok-4.3
The pith
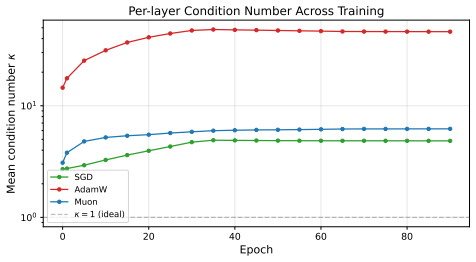
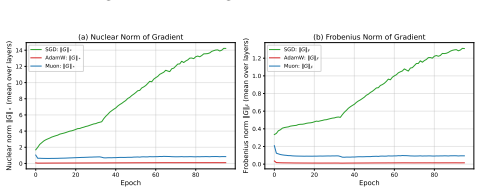
Muon imposes a spectral-norm stability ceiling on matrix updates during adversarial training, limiting uncontrolled spectral growth without shrinking weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
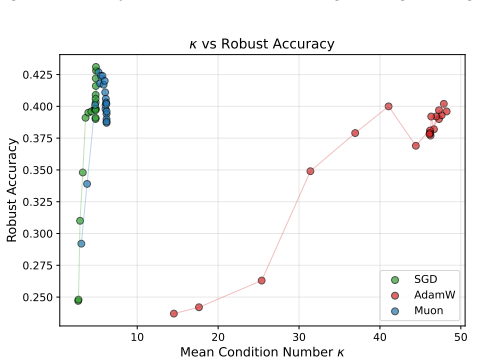
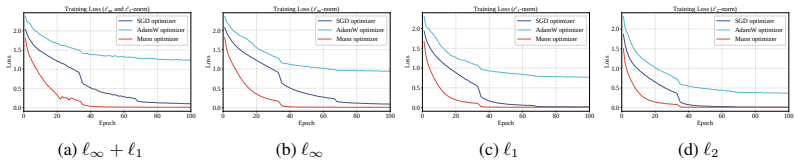
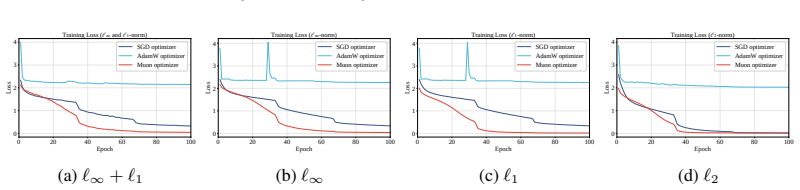
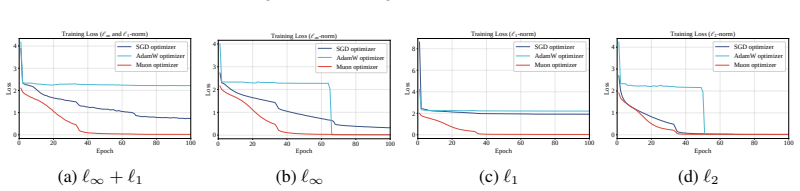
Muon imposes a spectral-norm stability ceiling on matrix updates, limiting uncontrolled spectral growth in the training dynamics without explicitly shrinking the learned weights. Empirically, across five architectures and three lp threat models and their union, Muon is competitive with SGD on CNNs and substantially outperforms AdamW on both CNNs and ViTs.
What carries the argument
Approximate polar decomposition to orthogonalize matrix-valued updates, which imposes the spectral-norm stability ceiling.
If this is right
- Muon achieves robustness competitive with SGD on CNNs under multiple threat models.
- Muon substantially outperforms AdamW on CNNs and vision transformers in adversarial training.
- Optimizer geometry acts as a security-relevant factor affecting robustness.
- Orthogonalized updates prove beneficial in regimes where adaptive methods fall short.
Where Pith is reading between the lines
- Similar orthogonalization techniques could be applied to other optimizers to test if they gain similar stability in AT.
- The approach might scale to larger models where spectral growth is more problematic.
- Future work could explore whether this stability holds for other min-max optimization problems beyond AT.
Load-bearing premise
The approximate polar decomposition in Muon provides a reliable spectral-norm bound that holds throughout the adversarial training process on practical models and attacks.
What would settle it
An experiment showing that Muon allows spectral norms to grow uncontrollably during adversarial training, or that it fails to match SGD robustness on standard benchmarks.
Figures




read the original abstract
Adversarial training (AT) remains one of the most reliable empirical defenses against adversarial attacks. Its robustness critically depends on how the underlying min-max objective is optimized. In practice, Stochastic Gradient Descent (SGD) optimizer remains the default optimization choice for AT, whereas adaptive optimizers often improve standard training but may yield inferior robustness. Recently, the Muon optimizer, which orthogonalizes matrix-valued updates via an approximate polar decomposition, has achieved notable success in large-scale training at a memory cost comparable to SGD. This raises a security-relevant question: \textit{can orthogonalized optimization improve AT under strong and heterogeneous threat models?} Focusing on this problem, we conduct a comprehensive theoretical and empirical study. Theoretically, we show that Muon imposes a spectral-norm stability ceiling on matrix updates, limiting uncontrolled spectral growth in the training dynamics without explicitly shrinking the learned weights. Empirically, across five architectures and three $\ell_p$ threat models ($\ell_\infty$, $\ell_1$, $\ell_2$) and their union, Muon is competitive with SGD on CNNs and substantially outperforms AdamW on both CNNs and ViTs. These results identify optimizer geometry as a security-relevant factor in adversarial training, while clarifying the empirical regimes in which orthogonalized updates are beneficial. Overall, our findings highlight optimizer design as a security-critical component of AT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Muon optimizer, which orthogonalizes matrix-valued updates via approximate polar decomposition, imposes a spectral-norm stability ceiling on updates during adversarial training (AT). This limits uncontrolled spectral growth without explicitly shrinking weights. Empirically, across five architectures and three ℓ_p threat models (ℓ_∞, ℓ_1, ℓ_2) plus their union, Muon is competitive with SGD on CNNs and substantially outperforms AdamW on both CNNs and ViTs, identifying optimizer geometry as a security-relevant factor in AT.
Significance. If the theoretical stability claim holds under the approximation used by Muon, the work would usefully connect optimizer geometry to robustness in min-max optimization and provide practical guidance on when orthogonalized updates are beneficial. The broad empirical scope across architectures and heterogeneous threat models is a strength that would make the findings actionable for AT practitioners.
major comments (2)
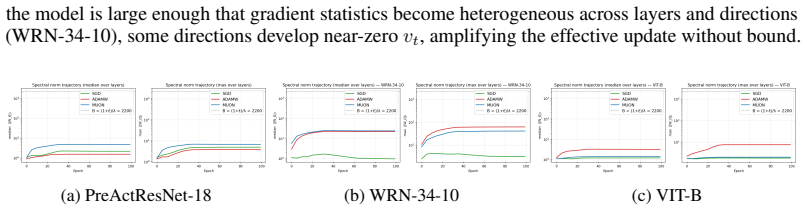
- [Theoretical analysis] Theoretical section on spectral-norm ceiling: The claim that Muon imposes a spectral-norm stability ceiling rests on the exact polar decomposition property that the orthogonal factor satisfies ||U||_2 = 1. Muon replaces this with a finite number of Newton-style iterations, yet no bound is derived on ||U_approx||_2 − 1 as a function of iteration count, gradient magnitude, or the size of the adversarial perturbation. In AT the effective gradients are larger and more variable than in standard training, so the approximation error could permit spectral growth beyond the claimed ceiling.
- [Empirical evaluation] Empirical results section: The reported robustness numbers compare final test accuracy under attack but do not include direct measurements (e.g., plots or tables) of the spectral norms of the matrix updates throughout training. Without such diagnostics it is impossible to confirm that the claimed stability ceiling is realized in practice under the studied threat models and architectures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our theoretical and empirical claims. We address each major point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical section on spectral-norm ceiling: The claim that Muon imposes a spectral-norm stability ceiling rests on the exact polar decomposition property that the orthogonal factor satisfies ||U||_2 = 1. Muon replaces this with a finite number of Newton-style iterations, yet no bound is derived on ||U_approx||_2 − 1 as a function of iteration count, gradient magnitude, or the size of the adversarial perturbation. In AT the effective gradients are larger and more variable than in standard training, so the approximation error could permit spectral growth beyond the claimed ceiling.
Authors: We agree that the theoretical analysis in the manuscript relies on the exact polar decomposition property (||U||_2 = 1) while Muon employs a finite Newton iteration approximation. No explicit error bound is derived as a function of iteration count or gradient statistics. We will add a new subsection discussing the quadratic convergence of the Newton iterations and the practical tolerance used in Muon (typically achieving ||U_approx||_2 within 10^{-4} of 1 after 5–6 steps). We will also note that the stability ceiling holds exactly only in the limit of the approximation and that larger adversarial gradients may increase the required iteration count; this limitation will be stated explicitly. revision: partial
-
Referee: [Empirical evaluation] Empirical results section: The reported robustness numbers compare final test accuracy under attack but do not include direct measurements (e.g., plots or tables) of the spectral norms of the matrix updates throughout training. Without such diagnostics it is impossible to confirm that the claimed stability ceiling is realized in practice under the studied threat models and architectures.
Authors: We concur that direct monitoring of spectral norms during training would strengthen the link between the theoretical ceiling and observed robustness. In the revised manuscript we will add a new figure (and corresponding table in the appendix) that tracks the spectral norm of the orthogonalized updates for Muon versus the raw gradient updates for SGD and AdamW across representative layers and threat models (ℓ_∞ and ℓ_2). These diagnostics will be computed on the same training runs reported in the main experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central theoretical claim—that Muon imposes a spectral-norm stability ceiling via polar decomposition—is presented as a direct mathematical consequence of the optimizer's update rule rather than a fitted quantity or self-referential definition. No equations, self-citations, or ansatzes in the provided text reduce the result to its own inputs by construction. The derivation chain remains independent of the empirical results and does not rely on load-bearing self-citations or renaming of known patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feature purification: How adversarial training performs robust deep learning
Zeyuan Allen-Zhu and Yuanzhi Li. Feature purification: How adversarial training performs robust deep learning. InIEEE 62nd annual symposium on foundations of computer science (FOCS), pages 977–988, 2022
2022
-
[2]
Understanding and improving fast ad- versarial training.Advances in Neural Information Processing Systems, 33:16048–16059, 2020
Maksym Andriushchenko and Nicolas Flammarion. Understanding and improving fast ad- versarial training.Advances in Neural Information Processing Systems, 33:16048–16059, 2020
2020
-
[3]
Towards understanding sharpness-aware minimization
Maksym Andriushchenko and Nicolas Flammarion. Towards understanding sharpness-aware minimization. InInternational conference on machine learning, pages 639–668, 2022
2022
-
[4]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational conference on machine learning, pages 274–283, 2018
2018
-
[5]
Synthesizing robust adver- sarial examples
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adver- sarial examples. InInternational conference on machine learning, pages 284–293, 2018
2018
-
[6]
The dynamics of sharpness-aware minimization: Bouncing across ravines and drifting towards wide minima.Journal of Machine Learning Research, 24(316):1–36, 2023
Peter L Bartlett, Philip M Long, and Olivier Bousquet. The dynamics of sharpness-aware minimization: Bouncing across ravines and drifting towards wide minima.Journal of Machine Learning Research, 24(316):1–36, 2023
2023
-
[7]
Modular duality in deep learning
Jeremy Bernstein and Laker Newhouse. Modular duality in deep learning. InICML, 2025
2025
-
[8]
Stochastic gradient descent tricks
Léon Bottou. Stochastic gradient descent tricks. InNeural networks: tricks of the trade: second edition, pages 421–436. Springer, 2012
2012
-
[9]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy (S&P), pages 39–57, 2017. 10
2017
-
[10]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints. arXiv preprint arXiv:2506.15054, 2025
-
[11]
Certified adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. Ininternational conference on machine learning, pages 1310–1320, 2019
2019
-
[12]
Robustbench: a standardized adversarial robustness benchmark
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark. InConference on Neural Information Processing Systems, 2021
2021
-
[13]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216, 2020
2020
-
[14]
Adversarial robustness against multiple and single l_p- threat models via quick fine-tuning of robust classifiers
Francesco Croce and Matthias Hein. Adversarial robustness against multiple and single l_p- threat models via quick fine-tuning of robust classifiers. InInternational Conference on Machine Learning, pages 4436–4454, 2022
2022
-
[15]
Revisiting outer optimization in adversarial training
Ali Dabouei, Fariborz Taherkhani, Sobhan Soleymani, and Nasser M Nasrabadi. Revisiting outer optimization in adversarial training. InEuropean Conference on Computer Vision, pages 244–261, 2022
2022
-
[16]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255, 2009
2009
-
[17]
Towards understanding the dynamics of the first-order adversaries
Zhun Deng, Hangfeng He, Jiaoyang Huang, and Weijie Su. Towards understanding the dynamics of the first-order adversaries. InInternational Conference on Machine Learning, pages 2484– 2493, 2020
2020
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, pages 1–13, 2021
2021
-
[19]
An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv
-
[20]
Sharpness-aware mini- mization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware mini- mization for efficiently improving generalization. InICLR, 2021
2021
-
[21]
Convergence of adversarial training in overparametrized neural networks.Advances in Neural Information Processing Systems, 32, 2019
Ruiqi Gao, Tianle Cai, Haochuan Li, Cho-Jui Hsieh, Liwei Wang, and Jason D Lee. Convergence of adversarial training in overparametrized neural networks.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[22]
Explaining and harnessing adversar- ial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversar- ial examples. InICLR, 2015
2015
-
[23]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[24]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InEuropean conference on computer vision, pages 630–645. Springer, 2016
2016
-
[25]
Formal guarantees on the robustness of a classifier against adversarial manipulation.Advances in neural information processing systems, 30, 2017
Matthias Hein and Maksym Andriushchenko. Formal guarantees on the robustness of a classifier against adversarial manipulation.Advances in neural information processing systems, 30, 2017
2017
-
[26]
SIAM, 2008
Nicholas J Higham.Functions of matrices: theory and computation. SIAM, 2008. 11
2008
-
[27]
Improving dnn robustness to adversarial attacks using jacobian regularization
Daniel Jakubovitz and Raja Giryes. Improving dnn robustness to adversarial attacks using jacobian regularization. InProceedings of the European conference on computer vision (ECCV), pages 514–529, 2018
2018
-
[28]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. https:// kellerjordan.github.io/posts/muon/, 2024
2024
-
[29]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015
2015
-
[30]
A learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. A learning multiple layers of features from tiny images. http://www.cs.toronto.edu/~kriz/cifar.html, 2009
2009
-
[31]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Cosmos: A hybrid adaptive optimizer for memory-efficient training of llms
Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, and Tuo Zhao. Cosmos: A hybrid adaptive optimizer for memory-efficient training of llms. arXiv preprint arXiv:2502.17410, 2025
-
[33]
Bad global minima exist and sgd can reach them.Advances in Neural Information Processing Systems, 33:8543–8552, 2020
Shengchao Liu, Dimitris Papailiopoulos, and Dimitris Achlioptas. Bad global minima exist and sgd can reach them.Advances in Neural Information Processing Systems, 33:8543–8552, 2020
2020
-
[34]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2017
2017
-
[35]
Understanding the robustness difference between stochastic gradient descent and adaptive gradient methods.Transactions on Machine Learning Research, 2023
Avery Ma, Yangchen Pan, and Amir-massoud Farahmand. Understanding the robustness difference between stochastic gradient descent and adaptive gradient methods.Transactions on Machine Learning Research, 2023
2023
-
[36]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InICLR, 2018
2018
-
[37]
Training transformers with enforced lipschitz constants.arXiv preprint arXiv:2507.13338, 2025
Laker Newhouse, R Preston Hess, Franz Cesista, Andrii Zahorodnii, Jeremy Bernstein, and Phillip Isola. Training transformers with enforced lipschitz constants.arXiv preprint arXiv:2507.13338, 2025
-
[38]
Rethinking softmax cross-entropy loss for adversarial robustness
Tianyu Pang, Kun Xu, Yinpeng Dong, Chao Du, Ning Chen, and Jun Zhu. Rethinking softmax cross-entropy loss for adversarial robustness. InICLR, 2020
2020
-
[39]
Bag of tricks for adversarial training
Tianyu Pang, Xiao Yang, Yinpeng Dong, Hang Su, and Jun Zhu. Bag of tricks for adversarial training. InICLR, 2021
2021
-
[40]
A stochastic approximation method.The annals of mathematical statistics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The annals of mathematical statistics, pages 400–407, 1951
1951
-
[41]
Adversarial training for free!Advances in neural information processing systems, 32, 2019
Ali Shafahi, Mahyar Najibi, Mohammad Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S Davis, Gavin Taylor, and Tom Goldstein. Adversarial training for free!Advances in neural information processing systems, 32, 2019
2019
-
[42]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Re- thinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Re- thinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
2016
-
[44]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Good- fellow, and Rob Fergus. Intriguing properties of neural networks. InICLR, 2014
2014
-
[45]
On adaptive attacks to adversarial example defenses.Advances in neural information processing systems, 33:1633–1645, 2020
Florian Tramer, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. On adaptive attacks to adversarial example defenses.Advances in neural information processing systems, 33:1633–1645, 2020. 12
2020
-
[46]
Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks.Advances in neural information processing systems, 31, 2018
Yusuke Tsuzuku, Issei Sato, and Masashi Sugiyama. Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks.Advances in neural information processing systems, 31, 2018
2018
-
[47]
On the convergence and robustness of adversarial training
Yisen Wang, Xingjun Ma, James Bailey, Jinfeng Yi, Bowen Zhou, and Quanquan Gu. On the convergence and robustness of adversarial training. InInternational Conference on Machine Learning, pages 6586–6595, 2019
2019
-
[48]
Fast is better than free: Revisiting adversarial training
Eric Wong, Leslie Rice, and J Zico Kolter. Fast is better than free: Revisiting adversarial training. InICLR, 2020
2020
-
[49]
Adversarial weight perturbation helps robust generalization.Advances in neural information processing systems, 33:2958–2969, 2020
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. Adversarial weight perturbation helps robust generalization.Advances in neural information processing systems, 33:2958–2969, 2020
2020
-
[50]
Feature squeezing: Detecting adversarial examples in deep neural networks
Weilin Xu, David Evans, and Yanjun Qi. Feature squeezing: Detecting adversarial examples in deep neural networks. InProceedings 2018 Network and Distributed System Security Symposium, 2018
2018
-
[51]
Wide residual networks
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. InBritish Machine Vision Conference, pages 1–15, 2016
2016
-
[52]
Theoretically principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. InInternational conference on machine learning, pages 7472–7482, 2019
2019
-
[53]
On the duality between sharpness-aware minimization and adversarial training
Yihao Zhang, Hangzhou He, Jingyu Zhu, Huanran Chen, Yifei Wang, and Zeming Wei. On the duality between sharpness-aware minimization and adversarial training. InInternational Conference on Machine Learning, pages 59024–59041, 2024
2024
-
[54]
Sharpness-aware minimization efficiently selects flatter minima late in training
Zhanpeng Zhou, Mingze Wang, Yuchen Mao, Bingrui Li, and Junchi Yan. Sharpness-aware minimization efficiently selects flatter minima late in training. InICLR, 2025. 13 Algorithm 2One Muon Step under AT (expands line 10 of Alg. 1 when Opt = Muon; Newton– Schulz iteration inlined as sub-steps of S2). Require: Weight block W∈R m×n, momentum buffer M (init. 0)...
2025
-
[55]
Hence ∇xmy,j(x) =J gθ(x)⊤(ey −e j),(21) and therefore, it satisfies ∥∇xmy,j(x)∥2 ≤ √ 2∥J gθ(x)∥2 ≤ √ 2 LY ℓ=1 ∥Wℓ∥2,(22) where the last inequality follows from Proposition 2.2 assuming 1-Lipschitz activations. Otherwise, the product is replaced byL L−1 ϕ Q ℓ ∥Wℓ∥2. Since the multiclass margin can be written as mθ(x, y) =g θ(x)y −max j̸=y gθ(x)j = min j̸=y...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.