Semantic-Aware Motion Encoding for Topology-Agnostic Character Animation
Pith reviewed 2026-06-29 14:41 UTC · model grok-4.3
The pith
Semantic modulation aligns functional joints to build a shared latent motion space across species.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
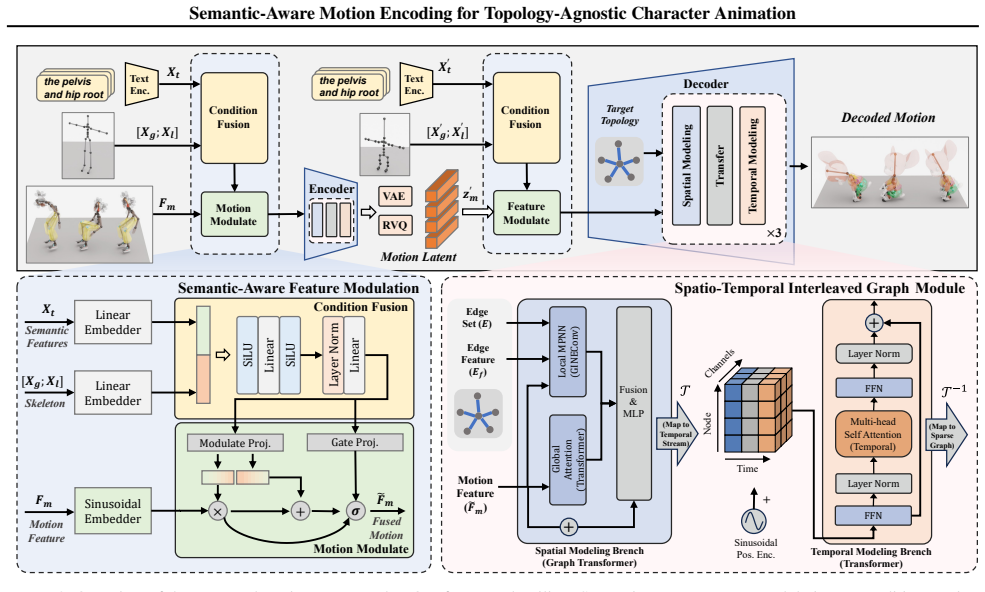
The Semantic-Aware Topology-Agnostic framework learns a unified latent manifold shared by disparate species. Unlike methods relying on fixed hierarchies or rigid padding strategies, the approach leverages a semantic modulation mechanism to align functional joint correspondences, thereby decoupling motion from topology and enabling the construction of a continuous, generative-friendly motion space from large-scale, unaligned raw BVH data.
What carries the argument
Semantic modulation mechanism that identifies and aligns functional joint correspondences from raw BVH sequences.
If this is right
- High-fidelity reconstruction of motions drawn from both human and animal datasets.
- Support for downstream text-to-motion generation tasks on the unified space.
- Zero-shot cross-species retargeting without any paired training examples.
- Construction of generative models directly from large collections of unaligned raw BVH files.
Where Pith is reading between the lines
- Animation pipelines could skip manual skeleton mapping steps when ingesting new character types.
- The same semantic alignment principle might extend to non-biological embodiments such as robotic arms.
- Text-to-motion models trained in this space could inherit cross-embodiment capability without additional fine-tuning.
Load-bearing premise
Semantic modulation can reliably identify and align functional joint correspondences across disparate species and topologies directly from unaligned raw BVH data.
What would settle it
A retargeting test between a human and a quadruped in which the generated motion produces biomechanically implausible joint angles or foot placements that violate the target skeleton's structure.
Figures





read the original abstract
Generalizing motion representation across diverse characters remains challenging due to significant topological variations in skeletal structures across datasets and species, which hinder the development of scalable generative models. To bridge this gap, we propose a Semantic-Aware Topology-Agnostic framework that learns a unified latent manifold shared by disparate species. Unlike methods relying on fixed hierarchies or rigid padding strategies, our approach leverages a semantic modulation mechanism to align functional joint correspondences, thereby decoupling motion from topology. This design enables the construction of a continuous, generative-friendly motion space from large-scale, unaligned raw BVH data. Experiments on human and animal datasets demonstrate that our framework achieves high-fidelity reconstruction and supports downstream text-to-motion tasks. Notably, the model enables zero-shot cross-species retargeting without paired data. Code and demos are available at: https://github.com/zzysteve/SATA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Semantic-Aware Topology-Agnostic (SATA) framework for motion encoding that learns a unified latent manifold across disparate skeletal topologies and species. It introduces a semantic modulation mechanism to align functional joint correspondences directly from unaligned raw BVH data, decoupling motion from topology. This is claimed to enable high-fidelity reconstruction, support text-to-motion tasks, and achieve zero-shot cross-species retargeting without paired data or explicit correspondence signals.
Significance. If the central mechanism holds, the work would address a key scalability barrier in generative character animation by removing reliance on fixed hierarchies or padding, potentially enabling broader use of large unaligned motion corpora across humans and animals.
major comments (3)
- [Abstract, §3] Abstract and §3 (method overview): the zero-shot cross-species retargeting claim rests on semantic modulation discovering functional alignments (e.g., human wrist to quadruped forepaw) from raw motion statistics alone. No loss term, training objective, or ablation is supplied to demonstrate that this occurs without implicit correspondence leakage from a combined human+animal corpus or external joint-type embeddings.
- [Abstract] Abstract: the statement that the framework is built 'directly from large-scale, unaligned raw BVH data' is load-bearing for the topology-agnostic claim, yet the manuscript provides neither the architecture diagram, modulation equations, nor any quantitative isolation of the semantic component from topology priors.
- [Experiments] Experiments section (implied by abstract claims): no error bars, baseline comparisons, or validation procedures are described for the 'high-fidelity reconstruction' or downstream text-to-motion results, making it impossible to assess whether the reported outcomes support the generalization claims.
minor comments (1)
- [Abstract] The GitHub link is provided but no code or model details are referenced in the text to allow reproduction of the semantic modulation module.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We provide point-by-point responses to the major comments and indicate revisions to be made.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method overview): the zero-shot cross-species retargeting claim rests on semantic modulation discovering functional alignments (e.g., human wrist to quadruped forepaw) from raw motion statistics alone. No loss term, training objective, or ablation is supplied to demonstrate that this occurs without implicit correspondence leakage from a combined human+animal corpus or external joint-type embeddings.
Authors: We acknowledge that the manuscript does not currently supply an explicit ablation or isolated loss term to demonstrate the alignment discovery mechanism. In the revision, we will add details on the training objective in §3 and include an ablation study in the experiments to address potential concerns about correspondence leakage. revision: yes
-
Referee: [Abstract] Abstract: the statement that the framework is built 'directly from large-scale, unaligned raw BVH data' is load-bearing for the topology-agnostic claim, yet the manuscript provides neither the architecture diagram, modulation equations, nor any quantitative isolation of the semantic component from topology priors.
Authors: We agree with this observation. The revised manuscript will include the architecture diagram, the explicit modulation equations, and a quantitative analysis isolating the semantic modulation component. revision: yes
-
Referee: [Experiments] Experiments section (implied by abstract claims): no error bars, baseline comparisons, or validation procedures are described for the 'high-fidelity reconstruction' or downstream text-to-motion results, making it impossible to assess whether the reported outcomes support the generalization claims.
Authors: We will revise the experiments section to report error bars, provide baseline comparisons, and describe the validation procedures for all results. revision: yes
Circularity Check
No circularity detected; derivation chain not inspectable from provided text
full rationale
The abstract and surrounding description present a high-level framework description with no equations, loss terms, training procedures, or derivation steps that could be walked for self-definition, fitted predictions, or self-citation load-bearing. No load-bearing claims reduce to their own inputs by construction, and the zero-shot retargeting claim is stated without accompanying math or ablations that would allow circularity assessment. This is the normal case of an honest non-finding when the paper text supplies no derivational content to analyze.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Skeleton-aware networks for deep motion retargeting
Aberman, K., Li, P., Lischinski, D., Sorkine-Hornung , O., Cohen-Or , D., and Chen, B. Skeleton-aware networks for deep motion retargeting. ACM Transactions on Graphics, 39 0 (4), 2020
2020
-
[2]
J., and Varol, G
Athanasiou, N., Petrovich, M., Black, M. J., and Varol, G. TEACH : Temporal Action Composition for 3D Humans . In 2022 International Conference on 3D Vision ( 3DV ) , pp.\ 414--423, 2022
2022
-
[3]
MotionBuilder , a 3D character animation software
Autodesk. MotionBuilder , a 3D character animation software. https://www.autodesk.com/products/motionbuilder, 2025
2025
-
[4]
Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning (ICML), July 2021
Bertasius, G., Wang, H., and Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning (ICML), July 2021
2021
-
[5]
Motion2Motion : Cross-topology motion transfer with sparse correspondence
Chen, L.-H., Zhang, Y., Yin, Z., Dou, Z., Chen, X., Wang, J., Komura, T., and Zhang, L. Motion2Motion : Cross-topology motion transfer with sparse correspondence. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers, SA Conference Papers '25, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400721373
2025
-
[6]
Dog Code : Human to Quadruped Embodiment using Shared Codebooks
Egan, D., Jovane, A., Szkaradek, J., Fletcher, G., Cosker, D., and McDonnell, R. Dog Code : Human to Quadruped Embodiment using Shared Codebooks . In Proceedings of the 17th ACM SIGGRAPH Conference on Motion , Interaction , and Games , MIG '24, pp.\ 1--11, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 979-8-4007-1090-2
2024
-
[7]
CharacterAnimationTools : C haracter animation tools for P ython
Fukahire. CharacterAnimationTools : C haracter animation tools for P ython. https://github.com/KosukeFukazawa/CharacterAnimationTools, 2025. Accessed: 2025-09-19
2025
-
[8]
Gat, I., Raab, S., Tevet, G., Reshef, Y., Bermano, A. H., and Cohen-Or, D. AnyTop : Character animation diffusion with any topology. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, SIGGRAPH Conference Papers '25, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 97...
-
[9]
Generating Diverse and Natural 3D Human Motions From Text
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., and Cheng, L. Generating Diverse and Natural 3D Human Motions From Text . In Proceedings of the IEEE / CVF Conference on Computer Vision and Pattern Recognition , pp.\ 5152--5161, 2022
2022
-
[10]
G., Wang, S., and Cheng, L
Guo, C., Mu, Y., Javed, M. G., Wang, S., and Cheng, L. MoMask : Generative Masked Modeling of 3D Human Motions . In Proceedings of the IEEE / CVF Conference on Computer Vision and Pattern Recognition , pp.\ 1900--1910, 2024
1900
-
[11]
Strategies for pre-training graph neural networks
Hu, W., Liu, B., Gomes, J., Zitnik, M., Liang, P., Pande, V., and Leskovec, J. Strategies for pre-training graph neural networks. In International Conference on Learning Representations, 2020
2020
-
[12]
Kingma, D. P. and Welling, M. Auto- Encoding Variational Bayes . In Proceedings of the 2nd International Conference on Learning Representations , 2014
2014
-
[13]
SAME : Skeleton-Agnostic Motion Embedding for Character Animation
Lee, S., Kang, T., Park, J., Lee, J., and Won, J. SAME : Skeleton-Agnostic Motion Embedding for Character Animation . In SIGGRAPH Asia 2023 Conference Papers , pp.\ 1--11, Sydney NSW Australia, 2023. ACM. ISBN 979-8-4007-0315-7
2023
-
[14]
How to Move Your Dragon : Text-to-Motion Synthesis for Large-Vocabulary Objects
Lee, W., Jeong, J., Moon, T., Kim, H.-J., Kim, J., Kim, G., and Lee, B.-U. How to Move Your Dragon : Text-to-Motion Synthesis for Large-Vocabulary Objects . In Proceedings of the Forty-second International Conference on Machine Learning . OpenReview.net, 2025
2025
-
[15]
WalkTheDog : Cross-Morphology Motion Alignment via Phase Manifolds
Li, P., Starke, S., Ye, Y., and Sorkine-Hornung , O. WalkTheDog : Cross-Morphology Motion Alignment via Phase Manifolds . In Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers '24 , pp.\ 1--10, Denver CO USA, 2024. ACM. ISBN 979-8-4007-0525-0
2024
-
[16]
Lin, J., Chang, J., Liu, L., Li, G., Lin, L., Tian, Q., and Chen, C. W. Being Comes from Not-Being : Open-Vocabulary Text-to-Motion Generation with Wordless Training . In 2023 IEEE / CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , pp.\ 23222--23231, Vancouver, BC, Canada, 2023 a . IEEE. ISBN 979-8-3503-0129-8
2023
-
[17]
Motion- X : A Large-scale 3D Expressive Whole-body Human Motion Dataset
Lin, J., Zeng, A., Lu, S., Cai, Y., Zhang, R., Wang, H., and Zhang, L. Motion- X : A Large-scale 3D Expressive Whole-body Human Motion Dataset . In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA, 2023 b . Curran Associates Inc
2023
-
[18]
Loper, M., Mahmood, N., Romero, J., Pons-Moll , G., and Black, M. J. SMPL : A skinned multi-person linear model. ACM Transactions on Graphics, 34 0 (6): 0 248:1--248:16, 2015
2015
-
[19]
F., Pons-Moll , G., and Black, M
Mahmood, N., Ghorbani, N., Troje, N. F., Pons-Moll , G., and Black, M. AMASS : Archive of Motion Capture As Surface Shapes . In 2019 IEEE / CVF International Conference on Computer Vision ( ICCV ) , pp.\ 5441--5450, Seoul, Korea (South), 2019. IEEE. ISBN 978-1-7281-4803-8
2019
-
[20]
FiLM : Visual Reasoning with a General Conditioning Layer
Perez, E., Strub, F., de Vries, H., Dumoulin, V., and Courville, A. FiLM : Visual Reasoning with a General Conditioning Layer . Proceedings of the AAAI Conference on Artificial Intelligence, 32 0 (1), 2018
2018
-
[21]
J., and Varol, G
Petrovich, M., Black, M. J., and Varol, G. Action- Conditioned 3D Human Motion Synthesis with Transformer VAE . In 2021 IEEE / CVF International Conference on Computer Vision ( ICCV ) , pp.\ 10965--10975, Montreal, QC, Canada, 2021. IEEE. ISBN 978-1-6654-2812-5
2021
-
[22]
MMM : Generative Masked Motion Model
Pinyoanuntapong, E., Wang, P., Lee, M., and Chen, C. MMM : Generative Masked Motion Model . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 1546--1555. IEEE, 2024
2024
-
[23]
The KIT Motion-Language Dataset
Plappert, M., Mandery, C., and Asfour, T. The KIT Motion-Language Dataset . Big Data, 4 0 (4): 0 236--252, 2016
2016
-
[24]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer . J. Mach. Learn. Res., 21: 0 140:1--140:67, 2020
2020
-
[25]
P., Luu, A
Ramp\' a s ek, L., Galkin, M., Dwivedi, V. P., Luu, A. T., Wolf, G., and Beaini, D. Recipe for a general, powerful, scalable graph transformer. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[26]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen - Or, D., and Bermano, A. H. Human Motion Diffusion Model . In Proceedings of the The Eleventh International Conference on Learning Representations . OpenReview.net, 2023
2023
-
[27]
Neural Discrete Representation Learning
van den Oord , A., Vinyals, O., and Kavukcuoglu , K. Neural Discrete Representation Learning . In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017
2017
-
[28]
AniMo : Species-Aware Model for Text-Driven Animal Motion Generation
Wang, X., Ruan, K., Zhang, X., and Wang, G. AniMo : Species-Aware Model for Text-Driven Animal Motion Generation . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 1929--1939. Computer Vision Foundation and IEEE, 2025
1929
-
[29]
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Yan, S., Xiong, Y., and Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition . Proceedings of the AAAI Conference on Artificial Intelligence, 32 0 (1), 2018
2018
-
[30]
OmniMotionGPT : Animal Motion Generation with Limited Data
Yang, Z., Zhou, M., Shan, M., Wen, B., Xuan, Z., Hill, M., Bai, J., Qi, G.-J., and Wang, Y. OmniMotionGPT : Animal Motion Generation with Limited Data . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 1249--1259. IEEE, 2024
2024
-
[31]
Skinned motion retargeting with residual perception of motion semantics & geometry
Zhang, J., Weng, J., Kang, D., Zhao, F., Huang, S., Zhe, X., Bao, L., Shan, Y., Wang, J., and Tu, Z. Skinned motion retargeting with residual perception of motion semantics & geometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13864--13872, 2023
2023
-
[32]
Generative motion stylization of cross-structure characters within canonical motion space
Zhang, J., Chen, X., Yu, G., and Tu, Z. Generative motion stylization of cross-structure characters within canonical motion space. In Proceedings of the 32nd ACM International Conference on Multimedia, pp.\ 7018--7026, 2024 a
2024
-
[33]
Tapmo: Shape-aware motion generation of skeleton-free characters
Zhang, J., Huang, S., Tu, Z., Chen, X., Zhan, X., Yu, G., and Shan, Y. Tapmo: Shape-aware motion generation of skeleton-free characters. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 , volume 2024, pp.\ 34575--34589. OpenReview.net, 2024 b
2024
-
[34]
A modular neural motion retargeting system decoupling skeleton and shape perception
Zhang, J., Tu, Z., Weng, J., Yuan, J., and Du, B. A modular neural motion retargeting system decoupling skeleton and shape perception. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 0 (10): 0 6889--6904, 2024 c
2024
-
[35]
Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis
Zhang, X., Li, J., Zhang, J., Dang, Z., Ren, J., Bo, L., and Tu, Z. Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 13761--13771, 2025 a
2025
-
[36]
Echomask: Speech-queried attention-based mask modeling for holistic co-speech motion generation
Zhang, X., Li, J., Zhang, J., Ren, J., Bo, L., and Tu, Z. Echomask: Speech-queried attention-based mask modeling for holistic co-speech motion generation. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 10827--10836, 2025 b
2025
-
[37]
PersonaGesture: Single-Reference Co-Speech Gesture Personalization for Unseen Speakers
Zhang, X., Cai, Y., Li, K., Yang, K., Zhou, Y., Li, Z., Chu, X., Zhang, J., and Liu, H. PersonaGesture : Single-reference co-speech gesture personalization for unseen speakers. arXiv preprint arXiv:2605.06064, 2026 a
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Mitigating error accumulation in co-speech motion generation via global rotation diffusion and multi-level constraints
Zhang, X., Li, J., Ren, J., and Zhang, J. Mitigating error accumulation in co-speech motion generation via global rotation diffusion and multi-level constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 12834--12842, 2026 b
2026
-
[39]
Behave Your Motion : Habit-preserved Cross-category Animal Motion Transfer
Zhang, Z., Du, B., Ma, C., Wang, Z., and Hu, W. Behave Your Motion : Habit-preserved Cross-category Animal Motion Transfer . In Proceedings of the 33rd ACM International Conference on Multimedia , MM '25, pp.\ 9638--9647, New York, NY, USA, 2025 c . Association for Computing Machinery. ISBN 979-8-4007-2035-2
2025
-
[40]
Towards robust and controllable text-to-motion via masked autoregressive diffusion
Zhang, Z., Kong, B., Liu, Q., and Wang, Y. Towards robust and controllable text-to-motion via masked autoregressive diffusion. In Proceedings of the 33rd ACM International Conference on Multimedia, MM '25, pp.\ 9326–9335, New York, NY, USA, 2025 d . Association for Computing Machinery
2025
-
[41]
On the Continuity of Rotation Representations in Neural Networks
Zhou, Y., Barnes, C., Lu, J., Yang, J., and Li, H. On the Continuity of Rotation Representations in Neural Networks . In 2019 IEEE / CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , pp.\ 5738--5746, Long Beach, CA, USA, 2019. IEEE. ISBN 978-1-7281-3293-8
2019
-
[42]
ParCo : Part-Coordinating Text-to-Motion Synthesis
Zou, Q., Yuan, S., Du, S., Wang, Y., Liu, C., Xu, Y., Chen, J., and Ji, X. ParCo : Part-Coordinating Text-to-Motion Synthesis . In Proceedings of the European Conference on Computer Vision (ECCV), volume 15114 of Lecture Notes in Computer Science , pp.\ 126--143. Springer, 2024
2024
-
[43]
W., and Black, M
Zuffi, S., Kanazawa, A., Jacobs, D. W., and Black, M. J. 3D Menagerie : Modeling the 3D Shape and Pose of Animals . In 2017 IEEE Conference on Computer Vision and Pattern Recognition ( CVPR ) , pp.\ 5524--5532, Honolulu, HI, 2017. IEEE. ISBN 978-1-5386-0457-1
2017
-
[44]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.