SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
Pith reviewed 2026-06-29 18:38 UTC · model grok-4.3
The pith
Batch Normalization induces gradient skew that slows dynamic sparse training, which SparseOpt corrects for faster convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
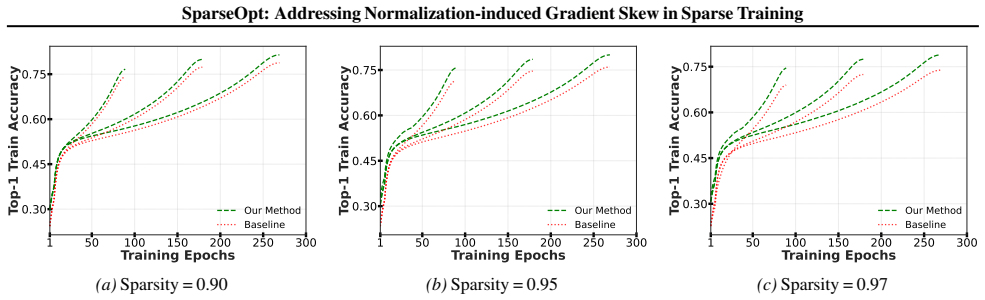
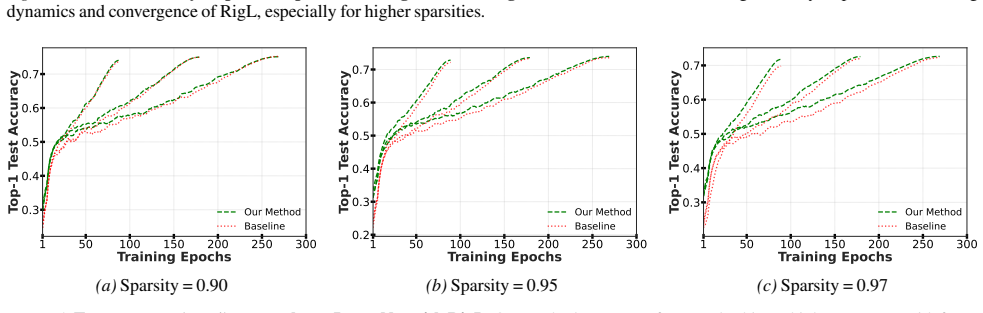
Batch Normalization adversely affects sparse training, and SparseOpt, a sparsity-aware optimizer, addresses this to achieve consistently faster convergence and improved generalization on ResNet models across CIFAR-100 and ImageNet.
What carries the argument
SparseOpt, a sparsity-aware optimizer that corrects normalization-induced gradient skew in sparse layers during dynamic topology adaptation.
If this is right
- Dynamic sparse training reaches target accuracy in fewer epochs when the optimizer accounts for normalization effects.
- Sparse networks trained with the proposed method generalize better than those using standard optimizers.
- Current normalization techniques have inherent limitations when paired with sparse connectivity and dynamic changes.
- The interaction between Batch Normalization and sparse layers is a primary bottleneck limiting practical use of dynamic sparse training.
Where Pith is reading between the lines
- The approach may extend to other normalization methods such as Layer Normalization if similar skew patterns appear in sparse settings.
- Testing on non-vision tasks or alternative sparse training algorithms could show whether the gradient correction generalizes beyond image classification.
- If the correction works broadly, dynamic sparse training might close the performance gap with dense training on larger models without extra compute.
Load-bearing premise
The identified gradient skew from Batch Normalization is the dominant cause of slower convergence in dynamic sparse training.
What would settle it
If applying SparseOpt or removing Batch Normalization produces no measurable improvement in convergence speed or accuracy for the tested ResNet models on CIFAR-100 and ImageNet, the central claim would be falsified.
Figures
























read the original abstract
Dynamic Sparse Training (DST) methods train neural networks by maintaining sparsity while dynamically adapting the network topology. Despite the promise of reduced computation, DST methods converge significantly slower than dense training, often requiring comparable training time to achieve similar accuracy. We demonstrate both analytically and empirically that Batch Normalization (BN) adversely affects sparse training, and propose SparseOpt, a sparsity-aware optimizer, to address this. Experiments on ResNet models across CIFAR-100 and ImageNet demonstrate consistently faster convergence and improved generalization with our proposed method. Our work highlights the limitations of current normalization layers in sparse training and provides the first systematic study of the interaction between Batch Normalization, sparse layers, and DST, taking a significant step toward making DST practically competitive with dense training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Batch Normalization induces gradient skew that slows Dynamic Sparse Training (DST) convergence relative to dense training. It provides both an analytical demonstration of this effect and a sparsity-aware optimizer (SparseOpt) to correct it, with experiments on ResNet models showing faster convergence and better generalization on CIFAR-100 and ImageNet.
Significance. If the central claims hold, the work would be significant for identifying a previously under-studied interaction between normalization layers and sparsity, and for offering a concrete optimizer fix that could help close the convergence gap between DST and dense training. The positioning as the first systematic study of BN-sparse-DST interactions adds to its potential impact if the evidence is made inspectable.
major comments (2)
- [Abstract] Abstract: the claim of an 'analytical demonstration' is unsupported because the abstract (and thus the central claim) contains no equations, no derivation outline, and no description of how the gradient skew is formally shown; without this the analytical part of the contribution cannot be evaluated.
- [Abstract] Abstract / experimental claims: no baseline comparisons, error bars, or statistical details are mentioned, and no controls are described that isolate BN-induced skew from other DST factors such as topology updates or mask-induced variance; this leaves open whether the reported gains are attributable to the proposed correction or to other unstated differences.
minor comments (1)
- [Abstract] The abstract does not name the specific ResNet variants, sparsity levels, or DST baselines used, which hinders immediate assessment of scope and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The abstract is intended as a concise overview, with full analytical derivations and experimental details provided in the body of the paper. We address each point below and will revise the abstract to better signal the location and nature of the supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of an 'analytical demonstration' is unsupported because the abstract (and thus the central claim) contains no equations, no derivation outline, and no description of how the gradient skew is formally shown; without this the analytical part of the contribution cannot be evaluated.
Authors: We agree the abstract does not contain equations or a derivation outline, as is conventional for abstracts. The analytical demonstration of BN-induced gradient skew appears in Section 3, including the formal derivation of how normalization layers produce skewed gradients under dynamic sparsity. We will revise the abstract to explicitly state that the analytical demonstration is detailed in Section 3, thereby making the claim traceable without lengthening the abstract excessively. revision: yes
-
Referee: [Abstract] Abstract / experimental claims: no baseline comparisons, error bars, or statistical details are mentioned, and no controls are described that isolate BN-induced skew from other DST factors such as topology updates or mask-induced variance; this leaves open whether the reported gains are attributable to the proposed correction or to other unstated differences.
Authors: Abstract length constraints preclude inclusion of error bars, full baseline tables, or control descriptions. The manuscript reports comparisons against standard DST optimizers (Section 4), multiple random seeds with error bars (Section 5), and ablation studies that isolate the BN-skew correction from topology updates and mask variance (Section 5.3). We will revise the abstract to note that experiments include standard baselines and BN-specific controls, directing readers to the relevant sections for details. revision: yes
Circularity Check
No circularity detected; derivation self-contained
full rationale
The provided abstract and claims describe an analytical demonstration plus empirical results on ResNet models for CIFAR-100 and ImageNet, with no equations, fitted parameters, or self-citations shown that reduce any prediction to its own inputs by construction. The central premise (BN-induced gradient skew affecting DST) is presented as independently verified by analysis and experiments rather than defined circularly or imported via author self-citation chains. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Conference on, pp. 248–255. IEEE, 2009. URL https://ieeexplore.ieee.org/abst ract/document/5206848/. Duchi, J., Hazan, E., and Singer, Y . Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research, 12(7), 2011. Evci, U., Elsen, E., Castro, P., and Gale, T. Rigging the lottery: Making all ticket...
-
[2]
URL https://api.semanticscholar. org/CorpusID:17043130. Li, X.-L. Preconditioned stochastic gradient descent.IEEE Transactions on Neural Networks and Learning Systems, 29(5):1454–1466, May 2018. ISSN 2162-2388. doi: 10.1109/tnnls.2017.2672978. URL http://dx.doi .org/10.1109/TNNLS.2017.2672978. Liu, S., Yin, L., Mocanu, D. C., and Pechenizkiy, M. Do we act...
-
[3]
This is summarized by the following observation
Clearly, if we now apply a mask towand rescale this does not affect the invariant. This is summarized by the following observation. ObservationA.2.The scaling and mask only change the gradient flow of wt. Therefore, it does not affect the invariance in Lemma A.1. HAM gradient flowConsider now the HAM gradient flow which is a Riemannian gradient flow with ...
2026
-
[4]
In Figures 6a and 6b we illustrate the invariance for a balanced initialization
making it possible to recover the ground truth (Gadhikar et al., 2025). In Figures 6a and 6b we illustrate the invariance for a balanced initialization. Note that invariant for gradient flow becomes singular ata=0, while HAM’s invariant does not. RemarkA.5.These balance equations can be easily extended to the multi-neuron case. We can see this from the ch...
2025
-
[5]
It is calculated relative to a base batch size of256: ηpeak =η base × B 256 , whereη base =0.1is the base learning rate provided in the arguments
Peak Learning Rate Scaling.The peak learning rate ( ηpeak) is dynamically scaled based on the global batch size (B) to ensure consistent convergence across different hardware configurations. It is calculated relative to a base batch size of256: ηpeak =η base × B 256 , whereη base =0.1is the base learning rate provided in the arguments
-
[6]
Warmup Phase.Training begins with a linear warmup phase lasting for 5 epochs( Twarmup). During this period, the learning rate increases linearly from a small initial value (ηinit) to the peak learning rate: ηt =Linear(η init,ηpeak,t)for0≤t < T warmup, 23 SparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training whereη init =1×10 −5
-
[7]
Cosine Decay Phase.After the warmup phase, the learning rate follows a standard cosine decay schedule for the remainder of the training duration (Ttotal −T warmup). The learning rate decays fromηpeak down to a final minimum value (ηend) by the last epoch: ηt =η end+ 1 2(ηpeak −ηend) 1+cos t−T warmup Ttotal −Twarmup π , whereη end =1×10 −5 andT total is th...
-
[8]
Warmup Phase.Training initiates with a linear warmup phase for the first5 epochs( Twarmup). The learning rate increases linearly from0to the base learning rate (η base): ηt =η base × t Twarmup for0≤t < T warmup, whereη base is the learning rate provided in the arguments (typically 0.1)
-
[9]
gradient clipping
Cosine Decay Phase.Following the warmup, the learning rate follows a standard cosine annealing schedule for the remaining epochs (Ttotal −Twarmup). The learning rate decays fromηbase to a final minimum value (ηend): ηt =η end+ 1 2(ηbase −ηend) 1+cos t−T warmup Ttotal −Twarmup π , whereη end =1×10 −6 andT total is the total number of training epochs (e.g.,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.