Law of Neural Interaction: Depth-Width Shape, Interaction Efficiency, and Generalization
Pith reviewed 2026-06-29 14:11 UTC · model grok-4.3
The pith
Tuning depth-width ratio places neural networks in an efficient interaction interval that supports better generalization under fixed budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
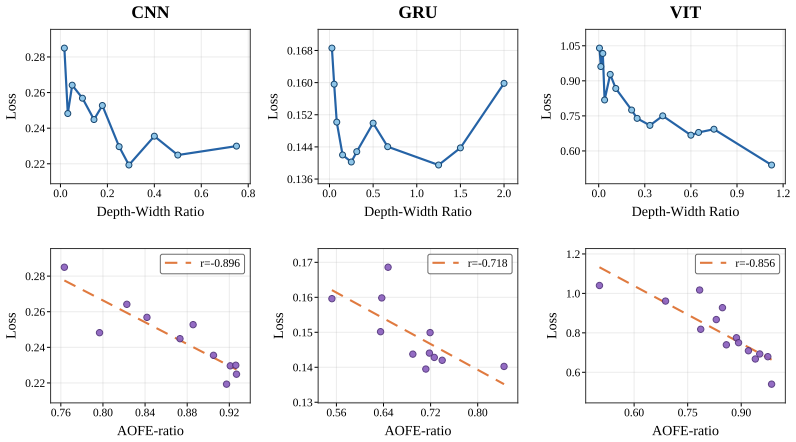
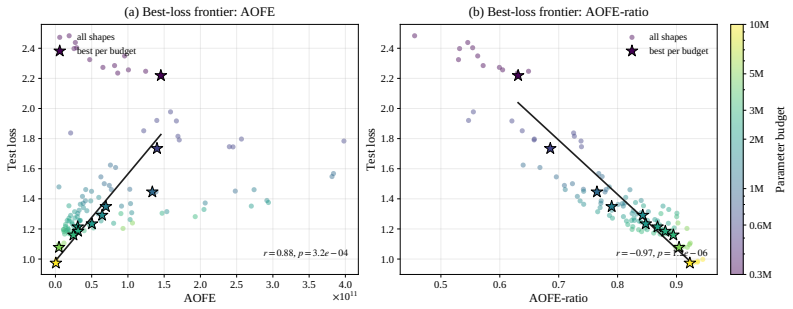
Under a fixed budget, good generalization is accompanied by efficient neural interactions defined in gradient space, and adjusting the depth-width ratio R_D/W can position the model in a stable efficient interaction interval.
What carries the argument
The Neural Feature Ansatz, which defines neural interaction efficiency in gradient space as an extension of superposition.
If this is right
- Adjusting R_D/W can improve generalization by targeting the efficient interaction interval.
- The efficient interaction interval remains stable as compute budget increases.
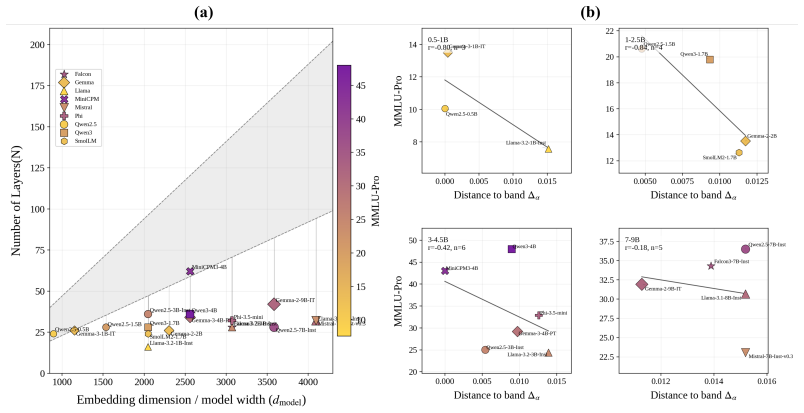
- Models near the efficient interval perform better on MMLU-Pro.
- Resource utilization efficiency depends on the depth-width shape.
Where Pith is reading between the lines
- Architecture design could prioritize depth-width ratios that target this interval for new models.
- The stability of the interval might allow predicting good shapes for larger scales without extensive search.
- Similar principles could extend to other architectures or tasks beyond dense LLMs.
Load-bearing premise
The Neural Feature Ansatz gives a definition of neural interaction whose efficiency directly determines generalization performance.
What would settle it
Finding a model with high interaction efficiency but poor generalization performance under the same fixed budget, or a model outside the interval with unexpectedly strong generalization.
Figures

read the original abstract
The guidance of scaling laws has increased the resource demands of modern large language models (LLMs), yet it remains questionable whether these models utilize resources effectively under a fixed budget. Previous research has proved superposition as a key contributor to loss. By leveraging the Neural Feature Ansatz, we extend superposition from parameter space to gradient space and define it as neural interaction. We find that under a fixed budget, good generalization is usually accompanied by efficient neural interactions, and the model can be placed in an efficient interaction interval by adjusting its depth-width ratio ($R_{D/W}$). In addition, as the budget scales up, the efficient interaction interval of the model remains relatively stable. By comparing existing small scale dense LLMs, we observe that models operating near this interval tend to perform better on the MMLU-Pro benchmark. Our findings reveal that the $R_{D/W}$ influences resource utilization efficiency and thereby affects generalization, providing insights into model shape initialization and the understanding of model generalization mechanisms. Code for Neural Interaction Law is available at: https://anonymous.4open.science/r/Neural_Interaction_Law-D788
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under a fixed computational budget, good generalization is accompanied by efficient neural interactions (defined by extending superposition to gradient space via the Neural Feature Ansatz), that the depth-width ratio R_{D/W} can place a model inside a stable 'efficient interaction interval', and that models operating near this interval perform better on MMLU-Pro; these observations are presented as a 'Law of Neural Interaction'.
Significance. If the Neural Feature Ansatz were shown to be a causally relevant and independently validated metric, the work could provide a new lens on depth-width trade-offs and resource utilization. As written, the correlational nature of the results and absence of validation for the core metric limit significance to an exploratory observation rather than a substantiated law.
major comments (4)
- The entire central claim rests on the Neural Feature Ansatz supplying a valid definition of neural interaction whose efficiency governs generalization; the manuscript provides no derivation, independent validation, ablation isolating it from other depth-width effects (e.g., optimization dynamics), or counter-example test (Abstract; § on Neural Feature Ansatz).
- The efficient interaction interval boundaries are identified from the same model runs used to demonstrate the generalization correlation, rendering the reported 'law' at least partly descriptive rather than predictive; no out-of-sample test or pre-defined boundaries are shown (Results on interval stability).
- No quantitative definition of interaction efficiency, error bars, statistical tests, or details on how interval boundaries were determined are reported, so the claims of correlation, adjustability via R_{D/W}, and scale stability cannot be assessed for reliability (Experimental results and benchmark comparison).
- The MMLU-Pro comparison with existing small-scale dense LLMs lacks controls for confounding factors such as training data volume or optimizer settings, weakening the inference that proximity to the interval drives performance (Benchmark comparison section).
minor comments (2)
- Clarify the exact mathematical definition of the Neural Feature Ansatz extension to gradient space and how efficiency is quantified (e.g., a specific equation or algorithm).
- The anonymous code link should be replaced with a permanent repository containing the exact scripts used to compute interactions and intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional rigor and clarity can strengthen the presentation of our exploratory findings on neural interaction efficiency. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: The entire central claim rests on the Neural Feature Ansatz supplying a valid definition of neural interaction whose efficiency governs generalization; the manuscript provides no derivation, independent validation, ablation isolating it from other depth-width effects (e.g., optimization dynamics), or counter-example test (Abstract; § on Neural Feature Ansatz).
Authors: The Neural Feature Ansatz is presented as a direct extension of superposition into gradient space, with the manuscript providing the motivating connection and initial empirical support. We agree that an explicit derivation, independent validation experiments, and ablations isolating the metric from optimization dynamics would improve the work. We will add a dedicated subsection with the mathematical derivation, an ablation study, and discussion of potential counter-examples in the revised manuscript. revision: yes
-
Referee: The efficient interaction interval boundaries are identified from the same model runs used to demonstrate the generalization correlation, rendering the reported 'law' at least partly descriptive rather than predictive; no out-of-sample test or pre-defined boundaries are shown (Results on interval stability).
Authors: We acknowledge that the interval was initially characterized from the primary experimental runs. To strengthen the predictive claim, we will conduct and report additional out-of-sample experiments on held-out model configurations and scales, using boundaries pre-defined from a subset of the data. This will be added to the Results section on interval stability. revision: yes
-
Referee: No quantitative definition of interaction efficiency, error bars, statistical tests, or details on how interval boundaries were determined are reported, so the claims of correlation, adjustability via R_{D/W}, and scale stability cannot be assessed for reliability (Experimental results and benchmark comparison).
Authors: We agree these quantitative details are essential. The revision will include: (i) a precise mathematical definition of interaction efficiency, (ii) error bars on all relevant figures, (iii) statistical tests for reported correlations, and (iv) explicit methodology for boundary determination (e.g., threshold selection criteria). These additions will appear in the Experimental results and benchmark comparison sections. revision: yes
-
Referee: The MMLU-Pro comparison with existing small-scale dense LLMs lacks controls for confounding factors such as training data volume or optimizer settings, weakening the inference that proximity to the interval drives performance (Benchmark comparison section).
Authors: This is a fair observation; the current comparison is observational. We will revise the Benchmark comparison section to explicitly discuss confounding factors, qualify the correlational nature of the inference, and add any feasible controls or sensitivity analyses using available model metadata. The language will be adjusted to reflect these limitations. revision: partial
Circularity Check
Neural Feature Ansatz supplies the interaction-efficiency metric; efficient interval identified from same runs used to report the correlation
specific steps
-
ansatz smuggled in via citation
[Abstract]
"By leveraging the Neural Feature Ansatz, we extend superposition from parameter space to gradient space and define it as neural interaction."
The paper adopts the Neural Feature Ansatz as the definition of the central quantity (neural interaction) without re-deriving or independently validating it inside this manuscript; the subsequent 'law' is then built on correlations measured with that ansatz-derived metric.
-
fitted input called prediction
[Abstract]
"We find that under a fixed budget, good generalization is usually accompanied by efficient neural interactions, and the model can be placed in an efficient interaction interval by adjusting its depth-width ratio (R_D/W). In addition, as the budget scales up, the efficient interaction interval of the model remains relatively stable."
The efficient interaction interval and its stability are identified by inspecting the same model runs whose generalization performance is being correlated with the interaction-efficiency metric; the reported 'law' is therefore a statistical description of the observed data rather than an independent prediction.
full rationale
The manuscript defines neural interaction by extending superposition via the Neural Feature Ansatz into gradient space, then reports that good generalization occurs inside an 'efficient interaction interval' whose location is stable with scale. Both the metric and the interval boundaries are obtained from the identical set of depth-width experiments; no independent derivation, external validation, or ablation isolating the ansatz quantity from other depth-width effects is supplied. This reduces the claimed 'law' to a post-hoc description of the fitted data rather than a first-principles prediction. The central claim therefore exhibits partial circularity of the fitted-input-called-prediction and ansatz-smuggled-in varieties, warranting a score of 6.
Axiom & Free-Parameter Ledger
free parameters (1)
- efficient interaction interval boundaries
axioms (1)
- domain assumption Neural Feature Ansatz correctly extends superposition to gradient space for measuring interaction efficiency
invented entities (1)
-
neural interaction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Kaplan , J., McCandlish , S., Henighan , T., Brown , T. B., Chess , B., Child , R., Gray , S., Radford , A., Wu , J., & Amodei , D. (2020) Scaling laws for neural language models.arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Hestness , J., Narang , S., Ardalani , N., Diamos , G., Jun , H., Kianinejad , H., Patwary , M. M. A., Yang , Y ., & Zhou , Y . (2017) Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Rosenfeld , J. S., Rosenfeld , A., Belinkov , Y ., & Shavit , N. (2019) A constructive prediction of the generalization error across scales.arXiv preprint arXiv:1909.12673
-
[4]
Brown , T., Mann , B., Ryder , N., Subbiah , M., Kaplan , J. D., Dhariwal , P., Neelakantan , A., Shyam , P., Sastry , G., Askell , A., & others (2020) Language models are few-shot learners.Advances in neural information processing systems33:1877–1901
2020
-
[5]
Training Compute-Optimal Large Language Models
Hoffmann , J., Borgeaud , S., Mensch , A., Buchatskaya , E., Cai , T., Rutherford , E., Casas , D., Hendricks , L. A., Welbl , J., Clark , A., & others (2022) Training compute-optimal large language models.arXiv preprint arXiv:2203.1555610
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Hernandez , D., Kaplan , J., Henighan , T., & McCandlish , S. (2021) Scaling laws for transfer.arXiv preprint arXiv:2102.01293
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
(2021) Scaling laws for neural machine translation.arXiv preprint arXiv:2109.07740
Ghorbani , B., Firat , O., Freitag , M., Bapna , A., Krikun , M., Garcia , X., Chelba , C., & Cherry , C. (2021) Scaling laws for neural machine translation.arXiv preprint arXiv:2109.07740
-
[8]
M., Neyshabur , B., & Zhai , X
Alabdulmohsin , I. M., Neyshabur , B., & Zhai , X. (2022) Revisiting neural scaling laws in language and vision.Advances in Neural Information Processing Systems35:22300–22312
2022
-
[9]
(2024) A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092
Bordelon , B., Atanasov , A., & Pehlevan , C. (2024) A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092
-
[10]
(2024) Explaining neural scaling laws.Proceedings of the National Academy of Sciences121(27):e2311878121
Bahri , Y ., Dyer , E., Kaplan , J., Lee , J., & Sharma , U. (2024) Explaining neural scaling laws.Proceedings of the National Academy of Sciences121(27):e2311878121
2024
-
[11]
(2022) Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems35: 19523–19536
Sorscher , B., Geirhos , R., Shekhar , S., Ganguli , S., & Morcos , A. (2022) Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems35: 19523–19536
2022
-
[12]
Hutter, Learning curve theory, arXiv preprint arXiv:2102.04074 (2021)
Hutter , M. (2021) Learning curve theory.arXiv preprint arXiv:2102.04074
-
[13]
(2025) How feature learning can improve neural scaling laws.Journal of Statistical Mechanics: Theory and Experiment2025(8):084002
Bordelon , B., Atanasov , A., & Pehlevan , C. (2025) How feature learning can improve neural scaling laws.Journal of Statistical Mechanics: Theory and Experiment2025(8):084002
2025
-
[14]
Superposition Yields Robust Neural Scaling
Liu , Y ., Liu , Z., & Gore , J. (2025) Superposition yields robust neural scaling.arXiv preprint arXiv:2505.10465
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Elhage , N., Hume , T., Olsson , C., Schiefer , N., Henighan , T., Kravec , S., Hatfield-Dodds , Z., Lasenby , R., Drain , D., Chen , C., & others (2022) Toy models of superposition.arXiv preprint arXiv:2209.10652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham , H., Ewart , A., Riggs , L., Huben , R., & Sharkey , L. (2023) Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
(2023) Superposition, memorization, and double descent.Transformer Circuits Thread6(24):1725–1744
Henighan , T., Carter , S., Hume , T., Elhage , N., Lasenby , R., Fort , S., Schiefer , N., & Olah , C. (2023) Superposition, memorization, and double descent.Transformer Circuits Thread6(24):1725–1744
2023
-
[18]
(2023) Privileged bases in the transformer residual stream
Elhage , N., Lasenby , R., & Olah , C. (2023) Privileged bases in the transformer residual stream. Transformer Circuits Thread24
2023
-
[19]
(2024) Mechanism for feature learning in neural networks and backpropagation-free machine learning models.Science383(6690):1461–1467
Radhakrishnan , A., Beaglehole , D., Pandit , P., & Belkin , M. (2024) Mechanism for feature learning in neural networks and backpropagation-free machine learning models.Science383(6690):1461–1467
2024
-
[20]
(2025) On the neural feature ansatz for deep neural networks
Tansley , E., Massart , E., & Cartis , C. (2025) On the neural feature ansatz for deep neural networks. arXiv preprint arXiv:2510.15563
-
[21]
(2024) Why do we need weight decay in modern deep learning?Advances in Neural Information Processing Systems37:23191–23223
d’Angelo , F., Andriushchenko , M., Varre , A., & Flammarion , N. (2024) Why do we need weight decay in modern deep learning?Advances in Neural Information Processing Systems37:23191–23223
2024
-
[22]
S., Gunasekar , S., & Srebro , N
Soudry , D., Hoffer , E., Nacson , M. S., Gunasekar , S., & Srebro , N. (2018) The implicit bias of gradient descent on separable data.Journal of Machine Learning Research19(70):1–57. 10
2018
-
[23]
Y ., & others (2011) Reading digits in natural images with unsupervised feature learning
Netzer , Y ., Wang , T., Coates , A., Bissacco , A., Wu , B., Ng , A. Y ., & others (2011) Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning 2011, pp. 4. Granada
2011
-
[24]
& Kaplan , J
Sharma , U. & Kaplan , J. (2022) Scaling laws from the data manifold dimension.Journal of Machine Learning Research23(9):1–34
2022
-
[25]
(2024) A resource model for neural scaling law.arXiv preprint arXiv:2402.05164
Song , J., Liu , Z., Tegmark , M., & Gore , J. (2024) A resource model for neural scaling law.arXiv preprint arXiv:2402.05164
-
[26]
E., Bhojanapalli , S., Neyshabur , B., & Srebro , N
Gunasekar , S., Woodworth , B. E., Bhojanapalli , S., Neyshabur , B., & Srebro , N. (2017) Implicit regularization in matrix factorization.Advances in neural information processing systems30
2017
-
[27]
(2018) Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems31
Jacot , A., Gabriel , F., & Hongler , C. (2018) Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems31
2018
-
[28]
Scaling and evaluating sparse autoencoders
Gao , L., Tour , T. D., Tillman , H., Goh , G., Troll , R., Radford , A., Sutskever , I., Leike , J., & Wu , J. (2024) Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
(2024) Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2
Lieberum , T., Rajamanoharan , S., Conmy , A., Smith , L., Sonnerat , N., Varma , V ., Kramár , J., Dragan , A., Shah , R., & Nanda , N. (2024) Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLPpages 278–300
2024
-
[30]
() The price of amortized inference in sparse autoencoders
Sun , W., Wang , D., & Hu , L. () The price of amortized inference in sparse autoencoders. InThe Fourteenth International Conference on Learning Representations
-
[31]
(2024) Residual stream analysis with multi-layer saes.arXiv preprint arXiv:2409.04185
Lawson , T., Farnik , L., Houghton , C., & Aitchison , L. (2024) Residual stream analysis with multi-layer saes.arXiv preprint arXiv:2409.04185
-
[32]
(2024) Mechanistic permutability: Match features across layers.arXiv preprint arXiv:2410.07656
Balagansky , N., Maksimov , I., & Gavrilov , D. (2024) Mechanistic permutability: Match features across layers.arXiv preprint arXiv:2410.07656
-
[33]
(2024) Sparse crosscoders for cross-layer features and model diffing.Transformer Circuits Threadpages 3982–3992
Lindsey , J., Templeton , A., Marcus , J., Conerly , T., Batson , J., & Olah , C. (2024) Sparse crosscoders for cross-layer features and model diffing.Transformer Circuits Threadpages 3982–3992
2024
-
[34]
(2025) Route sparse autoencoder to interpret large language models
Shi , W., Li , S., Liang , T., Wan , M., Ma , G., Wang , X., & He , X. (2025) Route sparse autoencoder to interpret large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processingpages 6812–6826
2025
-
[35]
(2025) Circuit-tracer: A new library for finding feature circuits
Hanna , M., Piotrowski , M., Lindsey , J., & Ameisen , E. (2025) Circuit-tracer: A new library for finding feature circuits. InProceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLPpages 239–249
2025
-
[36]
(2024) Average gradient outer product as a mechanism for deep neural collapse.Advances in Neural Information Processing Systems37:130764– 130796
Beaglehole , D., Súkeník , P., Mondelli , M., & Belkin , M. (2024) Average gradient outer product as a mechanism for deep neural collapse.Advances in Neural Information Processing Systems37:130764– 130796
2024
-
[37]
Radhakrishnan , A., Beaglehole , D., Pandit , P., & Belkin , M. (2022) Mechanism of feature learning in deep fully connected networks and kernel machines that recursively learn features.arXiv preprint arXiv:2212.13881
-
[38]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Frankle , J. & Carbin , M. (2018) The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Mallinar , N., Beaglehole , D., Zhu , L., Radhakrishnan , A., Pandit , P., & Belkin , M. (2024) Emergence in non-neural models: grokking modular arithmetic via average gradient outer product.arXiv preprint arXiv:2407.20199 11 A More Related Work A.1 Superposition Hypothesis The superposition hypothesis was originally introduced to explain the phenomenon o...
-
[40]
Justification: The paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.