Sign-Aware Gated Sparse Autoencoders: Modeling Anticorrelated Features with Bi-Jump-ReLU Activations
Pith reviewed 2026-06-29 14:13 UTC · model grok-4.3
The pith
Half-width sign-aware gated sparse autoencoders match or exceed full-width gated SAEs on reconstruction while cutting dead feature rates by up to 500x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
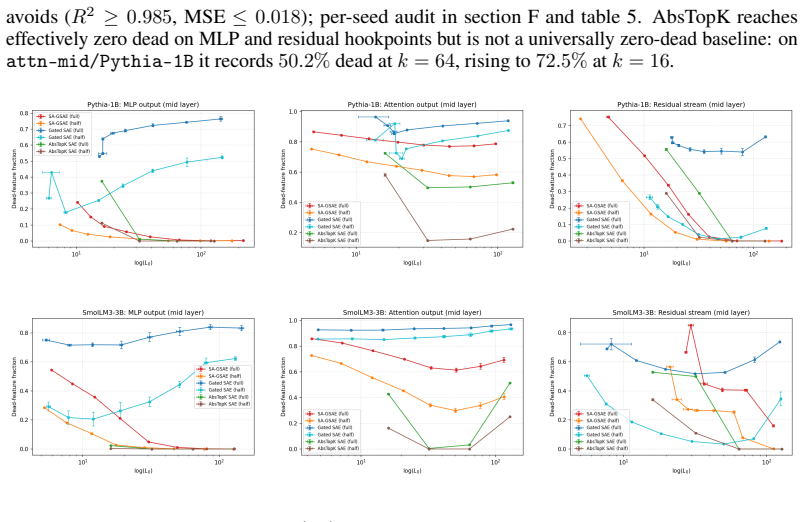
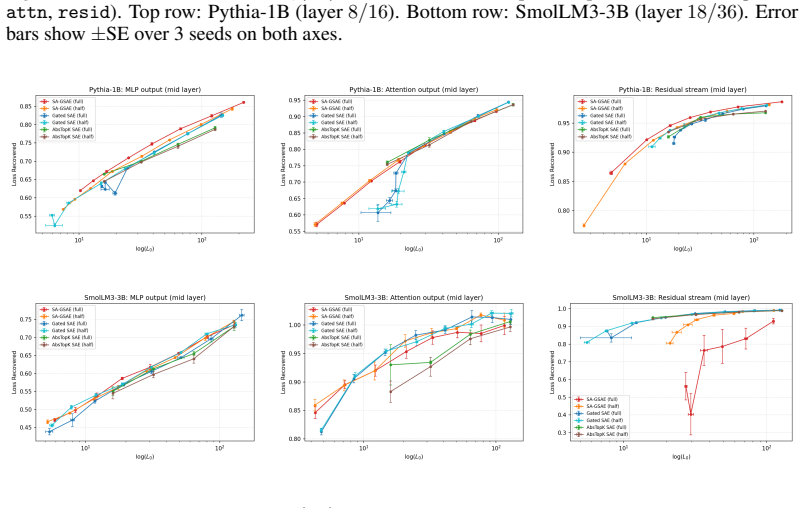
The central claim is that sign-awareness combined with auxiliary supervision realizes bipolar sharing—one latent encoding both signs along a shared direction—while remaining parameter-efficient. On real LLM activations the half-width SA-GSAE at H strictly Pareto-dominates the full-width Gated SAE at 2H over the entire L0 sweep on three of six cells and matches R^2 within 0.025 (max gap -0.008) on the remaining three while cutting dead fraction by 0.35-0.62 absolute; sweep-geomean dead-fraction reductions are 100x-500x on MLP-output and Pythia-1B resid cells. Ablations confirm the two-sided gate and auxiliary loss are load-bearing, tying the radii is sufficient, and full-width SA-GSAE exhibit
What carries the argument
The Bi-Jump-ReLU activation, which uses a polarity-sensitive gate to select support on either sign and a signed-magnitude path to avoid L1 shrinkage while an auxiliary reconstruction term prevents gate collapse.
If this is right
- Most latents in MLP-output hookpoints carry both polarities.
- The auxiliary loss is required; removing it causes collapse.
- Tying positive and negative radii yields |Delta R^2| of only 0.0015.
- Bipolar structure concentrates in a small set of top latents on attention cells.
- Full-width SA-GSAE shows reproducible reconstruction collapse on SmolLM3-3B resid that half-width avoids.
Where Pith is reading between the lines
- The efficiency pattern may appear in larger models if the same anticorrelation structure exists.
- Fewer but bipolar latents could simplify downstream interpretability analyses.
- Attention versus MLP differences suggest layer-specific feature polarity statistics worth mapping.
- Testing whether the same auxiliary loss suffices when dictionary size grows by another factor of four would clarify scaling.
Load-bearing premise
The auxiliary reconstruction loss is sufficient to prevent gate collapse in general settings and the observed Pareto dominance will generalize beyond the six specific hookpoint-model combinations tested.
What would settle it
Running the same sweep on a seventh hookpoint or new model and finding either gate collapse to learning rate 0.27 with 98 percent dead latents despite the auxiliary loss, or loss of the half-width Pareto dominance on reconstruction metrics.
Figures


read the original abstract
Sparse Autoencoders (SAEs) extract interpretable features from Large Language Models, but standard variants enforce non-negativity, forcing separate latents for diametrically opposed concepts (e.g., "pressure too high" vs. "pressure too low") and wasting dictionary capacity when features are anticorrelated. We propose the Sign-Aware Gated SAE (SA-GSAE): two-sided gated sparsity with signed magnitude and auxiliary supervision. A polarity-sensitive gate selects support on either sign, a signed-magnitude path avoids L1 shrinkage, and an auxiliary reconstruction prevents gate collapse. Bipolar sharing - one latent encoding both signs along a shared direction - is realised via a new Bi-Jump-ReLU activation; parameter accounting shows sign-awareness stays parameter-efficient even when anticorrelated pairs are rare. On real LLM activations across three mid-depth hookpoints on Pythia-1B and SmolLM3-3B (6 cells, 3 seeds), a half-width SA-GSAE at width H strictly Pareto-dominates a full-width Gated SAE at 2H over the entire swept L0 overlap on 3 of 6 cells (both MLP-output hookpoints and resid-mid/Pythia-1B); on the remaining 3 it matches R^2 within 0.025 (max gap -0.008) while cutting dead fraction by 0.35-0.62 absolute. Sweep-geomean dead-fraction reductions are ~100x-500x on MLP-output cells and Pythia-1B resid, ~2x-4x on attention cells and SmolLM3-3B resid. Ablations show the two-sided gate and auxiliary loss are load-bearing (no auxiliary collapses LR to 0.27, 98% dead); tying r_i^+ = r_i^- is indistinguishable (|Delta R^2| = 0.0015), and we recommend this symmetric variant as default. MLP-output gains come from most latents carrying both polarities; on attention, bipolar structure concentrates in a small set of top latents. Full-width SA-GSAE exhibits a reproducible reconstruction collapse at SmolLM3-3B resid that the half-width entirely avoids.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sign-Aware Gated Sparse Autoencoders (SA-GSAE) that employ a Bi-Jump-ReLU activation to model anticorrelated features via two-sided gated sparsity, signed magnitudes, and an auxiliary reconstruction loss to avoid gate collapse. It claims that a half-width SA-GSAE at dictionary size H strictly Pareto-dominates a full-width Gated SAE at 2H over the full L0 overlap on 3 of 6 tested cells (MLP-output hookpoints and Pythia-1B resid-mid) while matching R² within 0.025 and cutting dead fraction by 0.35-0.62 absolute on the remaining 3 cells; sweep-geomean dead-fraction reductions reach 100x-500x on MLP-output and Pythia-1B resid cells. Ablations confirm the auxiliary loss and two-sided gate are required, with a reproducible collapse noted for full-width SA-GSAE on SmolLM3-3B resid-mid.
Significance. If the reported Pareto dominance holds, the method improves SAE parameter efficiency for bipolar features without doubling width. The manuscript supplies concrete, multi-seed numbers (3 seeds, 6 cells) on R² and dead fractions, explicit ablation results (LR drops to 0.27 and 98% dead without auxiliary loss), and acknowledgment of a collapse case, enabling direct falsification. These elements strengthen the empirical contribution relative to prior gated SAE baselines.
major comments (2)
- [Ablations] Ablations section: while the auxiliary reconstruction loss is shown to be load-bearing (no-auxiliary LR=0.27, 98% dead), the manuscript also reports a reproducible full-width SA-GSAE reconstruction collapse on the SmolLM3-3B resid-mid cell. This indicates the auxiliary term's robustness may be setting-dependent, which is load-bearing for the claim that SA-GSAE reliably achieves the reported dominance without collapse.
- [Results] Results section (6-cell comparison): the strict Pareto dominance on 3/6 cells and the 'entire swept L0 overlap' claim rest on the intersection of evaluated L0 ranges; the manuscript should explicitly state the pre-specified criteria used to define this overlap and confirm that L0 targets were not selected after inspecting per-cell outcomes.
minor comments (3)
- [Methods] Methods: the Bi-Jump-ReLU activation and the precise parameter count for the sign-aware mechanism should be stated with an explicit equation or table rather than prose description alone.
- [Figures] Figures: the Pareto-front plots would benefit from explicit annotation of the L0 overlap interval used for each cell to allow readers to verify the dominance claim without re-deriving the ranges.
- [Discussion] The manuscript should add a short limitations paragraph addressing generalization beyond the six hookpoint-model combinations tested.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments highlight important points on robustness and experimental transparency, which we address below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [Ablations] Ablations section: while the auxiliary reconstruction loss is shown to be load-bearing (no-auxiliary LR=0.27, 98% dead), the manuscript also reports a reproducible full-width SA-GSAE reconstruction collapse on the SmolLM3-3B resid-mid cell. This indicates the auxiliary term's robustness may be setting-dependent, which is load-bearing for the claim that SA-GSAE reliably achieves the reported dominance without collapse.
Authors: We agree that the observed collapse of the full-width variant on the SmolLM3-3B resid-mid cell indicates that auxiliary-loss robustness can be width- and setting-dependent. The manuscript already reports this collapse explicitly and notes that the half-width SA-GSAE avoids it entirely on that cell. Our primary claims and Pareto-dominance results concern the half-width configuration (the recommended default), where the auxiliary loss remains load-bearing per the reported ablation. We will expand the discussion section to explicitly address this setting dependence, clarify that the half-width variant is the focus of the efficiency claims, and note the full-width collapse as a known limitation of the wider configuration. revision: yes
-
Referee: [Results] Results section (6-cell comparison): the strict Pareto dominance on 3/6 cells and the 'entire swept L0 overlap' claim rest on the intersection of evaluated L0 ranges; the manuscript should explicitly state the pre-specified criteria used to define this overlap and confirm that L0 targets were not selected after inspecting per-cell outcomes.
Authors: The L0 overlap is the intersection of the discrete L0 targets at which both SA-GSAE and Gated SAE models were trained and evaluated across the fixed sweep ranges (L0 targets chosen in advance based on standard SAE literature ranges of approximately 5–200). These targets were not adjusted post-hoc after inspecting per-cell results. We will add an explicit statement in the Results section defining the overlap criterion as this pre-specified intersection and confirming the a-priori selection of L0 targets. revision: yes
Circularity Check
No significant circularity; empirical results stand on direct benchmarks
full rationale
The paper proposes the SA-GSAE architecture (two-sided gated sparsity, Bi-Jump-ReLU, auxiliary reconstruction) and reports its performance via direct experimental comparison against Gated SAE baselines on six specific hookpoint-model cells. No equations or derivations are presented that reduce the reported R^2, dead-fraction, or Pareto-dominance outcomes to quantities defined by the paper's own fitted parameters or self-citations. Ablations confirm the auxiliary loss is required, but this is an independent empirical check rather than a self-referential loop. The central claims remain falsifiable against external models and layers outside the tested set.
Axiom & Free-Parameter Ledger
free parameters (2)
- dictionary width H
- L0 sparsity targets
axioms (2)
- domain assumption LLM activations contain anticorrelated feature pairs that can be usefully represented by a single bipolar latent
- ad hoc to paper The auxiliary reconstruction loss prevents gate collapse without introducing other distortions
invented entities (2)
-
Bi-Jump-ReLU activation
no independent evidence
-
Sign-aware gated sparsity mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mechanistic interpretability, variables, and the importance of interpretable bases
Chris Olah. Mechanistic interpretability, variables, and the importance of interpretable bases. https: //www.transformer-circuits.pub/2022/mech-interp-essay, 2022
2022
-
[2]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020. URLhttps://distill.pub/2020/circuits/zoom-in/
2020
-
[3]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017. URL https://papers.neurips.cc/paper/7181-attention-is-all-you-need. pdf
2017
-
[4]
An interpretability illusion for BERT.arXiv preprint arXiv:2104.07143, 2021
Tolga Bolukbasi, Adam Pearce, Ann Yuan, Andy Coenen, Emily Reif, Fernanda Viégas, and Martin Wattenberg. An interpretability illusion for BERT.arXiv preprint arXiv:2104.07143, 2021
-
[5]
Nelson Elhage et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark
Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860, 2024
-
[8]
Olshausen and David J
Bruno A. Olshausen and David J. Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381(6583):607–609, 1996
1996
-
[9]
Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996
Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996
1996
-
[10]
K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on Signal Processing, 54(11):4311–4322, 2006
Michal Aharon, Michael Elad, and Alfred Bruckstein. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on Signal Processing, 54(11):4311–4322, 2006
2006
-
[11]
Online dictionary learning for sparse coding
Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro. Online dictionary learning for sparse coding. InProceedings of the 26th International Conference on Machine Learning (ICML), pages 689–696, 2009
2009
-
[12]
Lee and H
Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755):788–791, 1999
1999
-
[13]
Learning fast approximations of sparse coding
Karol Gregor and Yann LeCun. Learning fast approximations of sparse coding. InProceedings of the 27th International Conference on Machine Learning (ICML), pages 399–406, 2010
2010
-
[14]
Towards monosemanticity: Decomposing language models with dictionary learning
Trenton Bricken et al. Towards monosemanticity: Decomposing language models with dictionary learning. https://transformer-circuits.pub/2023/monosemantic-features/index.html, 2023
2023
-
[15]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://cdn.openai.com/papers/sparse-autoencoders.pdf
-
[18]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Tom Lieberum et al. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Zhengfu He et al. Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders. arXiv preprint arXiv:2410.20526, 2024
-
[20]
Charles O’Neill, Alim Gumran, and David Klindt. Compute optimal inference and provable amortisation gap in sparse autoencoders.arXiv preprint arXiv:2411.13117, 2024
-
[21]
Jingyi Cui, Qi Zhang, Yifei Wang, and Yisen Wang. On the limits of sparse autoencoders: A theoretical framework and reweighted remedy.arXiv preprint arXiv:2506.15963, 2025
-
[22]
Sparse autoencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878, 2025
Patrick Leask, Bart Bussmann, Michael Pearce, Joseph Bloom, Curt Tigges, Noura Al Moubayed, Lee Sharkey, and Neel Nanda. Sparse autoencoders do not find canonical units of analysis.arXiv preprint arXiv:2502.04878, 2025
-
[23]
Sparse autoencoders trained on the same data learn different features
Gonçalo Paulo and Nora Belrose. Sparse autoencoders trained on the same data learn different features. arXiv preprint arXiv:2501.16615, 2025
-
[24]
Xudong Zhu, Mohammad Mahdi Khalili, and Zhihui Zhu. AbsTopK: Rethinking sparse autoencoders for bidirectional features.arXiv preprint arXiv:2510.00404, 2025
-
[25]
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Krámár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Richard H. R. Hahnloser, H. Sebastian Seung, and Jean-Jacques Slotine. Permitted and forbidden sets in symmetric threshold-linear networks.Neural Computation, 15(3):621–638, 2003. doi: 10.1162/ 089976603321192103
2003
-
[27]
Jianing Han, Ziming Wang, Jiangrong Shen, and Huajin Tang. Symmetric-threshold ReLU for fast and nearly lossless ANN-SNN conversion.Machine Intelligence Research, 20(3):435–446, 2023. doi: 10 10.1007/s11633-022-1388-2
-
[28]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. InProceedings of the 40th International Conferen...
2023
-
[29]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
SmolLM3: smol, multilingual, long-context reasoner
Elie Bakouch et al. SmolLM3: smol, multilingual, long-context reasoner. https://huggingface.co/ blog/smollm3, 2025
2025
-
[31]
Openwebtext corpus
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus. http:// Skylion007.github.io/OpenWebTextCorpus, 2019
2019
-
[32]
Michaud, Max Tegmark, and Christian Schroeder de Witt
Anish Mudide, Joshua Engels, Eric J. Michaud, Max Tegmark, and Christian Schroeder de Witt. Efficient dictionary learning with switch sparse autoencoders.arXiv preprint arXiv:2410.08201, 2024
-
[33]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547, 2025
-
[34]
A is for absorption: Studying feature splitting and absorption in sparse autoencoders
David Chanin et al. A is for absorption: Studying feature splitting and absorption in sparse autoencoders. arXiv preprint arXiv:2409.14507, 2024
-
[35]
David Chanin et al. Feature hedging: Correlated features break narrow sparse autoencoders.arXiv preprint arXiv:2505.11756, 2025
-
[36]
Ingrid Daubechies, Michel Defrise, and Christine De Mol. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint.Communications on Pure and Applied Mathematics, 57(11): 1413–1457, 2004. doi: 10.1002/cpa.20042
-
[37]
Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems.SIAM Journal on Imaging Sciences, 2(1):183–202, 2009. doi: 10.1137/080716542. URL https://www.tau.ac.il/~becka/FISTA.pdf
-
[38]
Alireza Makhzani and Brendan Frey. k-Sparse autoencoders.arXiv preprint arXiv:1312.5663, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Krámár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with JumpReLU sparse autoencoders.arXiv preprint arXiv:2407.14435, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
BatchTopK sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. BatchTopK sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
-
[41]
Adam Karvonen et al. SAEBench: A comprehensive benchmark for sparse autoencoders in language model interpretability.arXiv preprint arXiv:2503.09532, 2025
-
[42]
Evaluating SAE interpretability without explanations.arXiv preprint arXiv:2507.08473, 2025
Gonçalo Paulo and Nora Belrose. Evaluating SAE interpretability without explanations.arXiv preprint arXiv:2507.08473, 2025
-
[43]
Adam Karvonen, Benjamin Wright, Can Rager, Rico Angell, Jannik Brinkmann, Logan Smith, Clau- dio Mayrink Verdun, David Bau, and Samuel Marks. Measuring progress in dictionary learning for language model interpretability with board game models.arXiv preprint arXiv:2408.00113, 2024
-
[44]
Aleksandar Makelov, George Lange, and Neel Nanda. Towards principled evaluations of sparse autoen- coders for interpretability and control.arXiv preprint arXiv:2405.08366, 2024
-
[45]
Li, Suraj Srinivas, Usha Bhalla, and Himabindu Lakkaraju
Aaron J. Li, Suraj Srinivas, Usha Bhalla, and Himabindu Lakkaraju. Evaluating adversarial robustness of concept representations in sparse autoencoders.arXiv preprint arXiv:2505.16004, 2025
-
[46]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. URLhttps://arxiv.org/abs/1412.6980. 11 A Background and Related Work A.1 Sparse autoencoders as amortized sparse inference Solving eq. (1) exactly requires an inner optimization to inferz(n) for each sample, often via proximal methods (for exa...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
asymmetric signed-axis calibration,
-
[48]
directional anomaly detection under a strict latent budget,
-
[49]
Polarity Dial
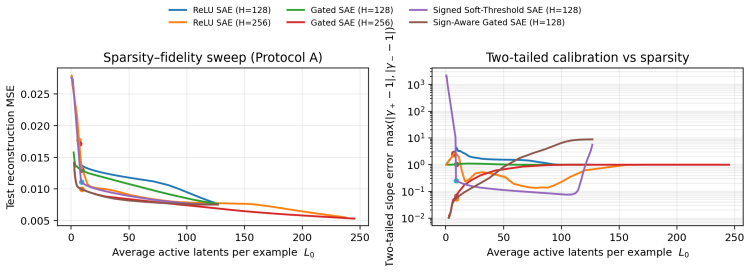
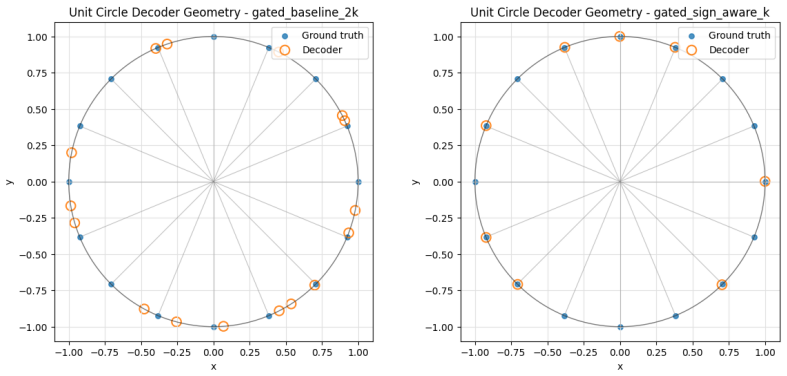
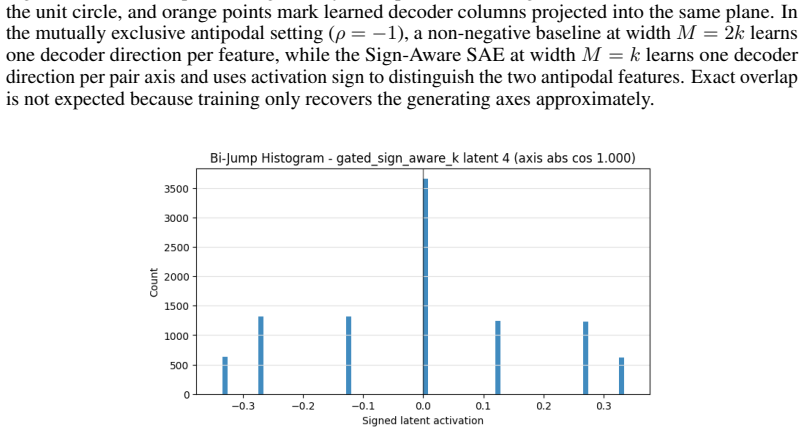
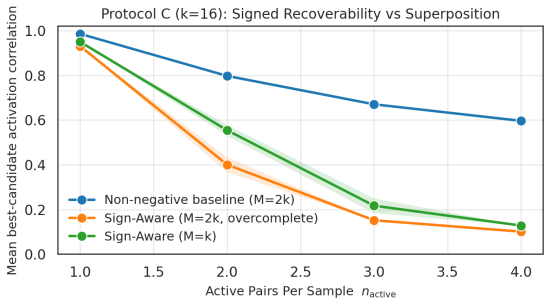
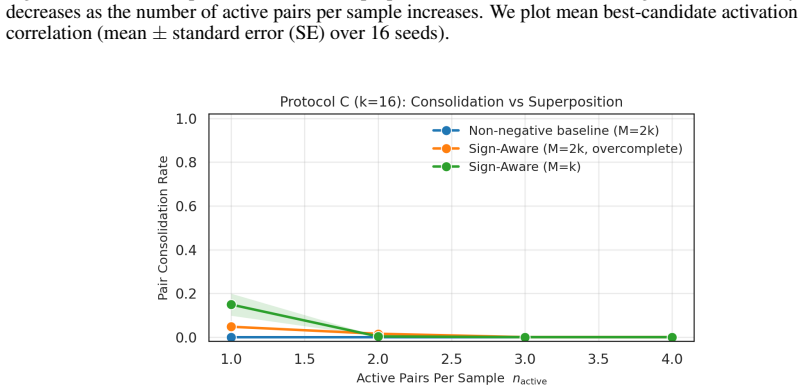
consolidation of anticorrelated pairs in toy geometry. Unless otherwise stated, we report not only a single operating point, but also sparsity-fidelity trade- offs by sweeping the sparsity strength (e.g., λ) and plotting reconstruction MSE versus average L0 (active latents per example). C.1 Protocol A: The "Polarity Dial" (Asymmetry & Calibration) Protoco...
1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.