Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
Pith reviewed 2026-06-29 13:54 UTC · model grok-4.3
The pith
Optimal Coefficient Calibration enables joint Multi-Token Prediction and Reinforcement Learning training to match or exceed the detached-gradient baseline on mathematical reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
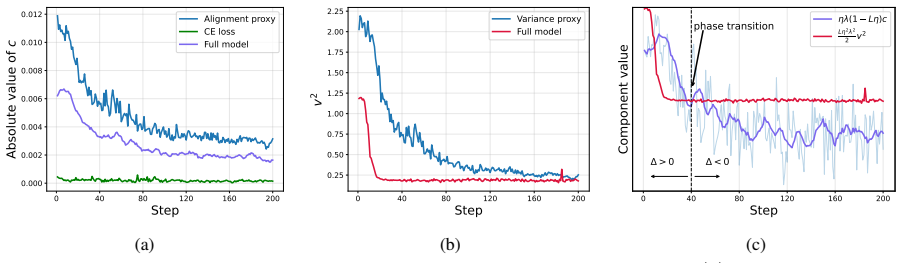
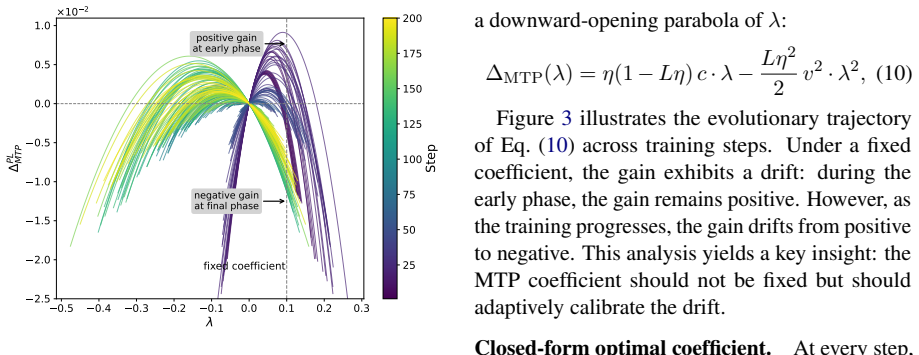
The per-step effect of MTP on the RL objective decomposes into a first-order correlation term and a second-order perturbation penalty term. This decomposition unifies the Detach, Cross-Entropy, and Policy-loss regimes and shows why each succeeds or fails. Under policy loss the correlation term decays while the quadratic penalty persists, causing degradation. Optimal Coefficient Calibration tracks the coefficient that balances the two terms via an online log-probability proxy, restoring joint-training performance.
What carries the argument
Optimal Coefficient Calibration (OCC), an adaptive online scheme that selects the MTP coefficient each step using a log-probability proxy derived from the first-order/second-order decomposition.
If this is right
- Detach, Cross-Entropy loss, and Policy loss become special cases of the same first-order/second-order tradeoff.
- Policy loss degrades because the helpful correlation term shrinks over training while the penalty term remains.
- OCC recovers joint-training performance at negligible extra cost on competition-level math tasks.
- The same decomposition can be used to decide when to apply any auxiliary prediction head inside an RL loop.
Where Pith is reading between the lines
- The same first-order versus second-order accounting could be applied to other auxiliary losses such as auxiliary value heads or contrastive objectives inside RLVR.
- If the log-probability proxy remains stable across model scales, OCC may reduce the need for per-task hyperparameter sweeps when adding MTP to new RLVR runs.
- The analysis suggests that any auxiliary loss whose second-order term grows faster than its first-order benefit will eventually require adaptive re-weighting rather than fixed coefficients.
Load-bearing premise
The per-step effect of MTP on the RL objective decomposes into a first-order correlation term and a second-order perturbation penalty term that can be used to guide coefficient selection.
What would settle it
On the six reported benchmarks, replace OCC with a fixed coefficient or the detach baseline and measure whether average performance falls below the OCC numbers.
Figures



read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as the standard paradigm for improving reasoning capability of large language models, while Multi-Token Prediction (MTP) has been a widely adopted module in pretraining. Combining them is a natural approach, yet current RL practices detach MTP gradients because joint training degrades the performance. We revisit this failure from an optimization perspective. We show that the per-step effect of MTP on the RL objective can be decomposed into two terms: a first-order correlation and a second-order perturbation penalty. This decomposition unifies three MTP training regimes: Detach, Cross-Entropy loss, and Policy loss, and explains why each succeeds or fails. Further analysis of policy loss reveals that, although it aligns with intuition, performance still degrades: the correlation term decays while the quadratic penalty persists. Guided by the analysis, we propose Optimal Coefficient Calibration (OCC), an adaptive scheme that tracks the optimal coefficient online via a log-probability proxy at negligible cost. Across six competition-level mathematical reasoning benchmarks, OCC consistently matches or exceeds the detach baseline, delivering improved joint MTP-RL training performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the per-step effect of Multi-Token Prediction (MTP) on the RL objective in RLVR decomposes into a first-order correlation term and a second-order perturbation penalty. This decomposition unifies the Detach, Cross-Entropy, and Policy training regimes, explains the degradation under Policy loss (correlation decays while penalty persists), and motivates Optimal Coefficient Calibration (OCC), an adaptive online scheme using a log-probability proxy to select the MTP coefficient. Empirically, OCC matches or exceeds the detach baseline across six competition-level mathematical reasoning benchmarks.
Significance. If the decomposition is valid and the empirical gains hold under standard controls, the work supplies a principled optimization lens for integrating auxiliary MTP objectives into RL fine-tuning of LLMs. The online proxy for coefficient selection is a low-cost practical contribution that could generalize to other auxiliary losses. The unification of regimes and diagnosis of Policy-loss failure are useful for the community working on joint pretraining-fine-tuning pipelines.
minor comments (2)
- [Abstract] Abstract: the six benchmarks are referred to only generically; naming them (or citing the specific table/figure) would allow immediate assessment of the scope of the claim.
- The log-probability proxy is described as 'negligible cost' but no explicit complexity or memory overhead is stated; a short complexity remark would strengthen the practical claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the core contributions of the decomposition, unification of regimes, diagnosis of policy-loss degradation, and the OCC method.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an optimization-based decomposition of the per-step MTP effect on the RL objective into a first-order correlation term and second-order perturbation penalty. This analytical step is used to unify Detach/CE/Policy regimes and motivate the OCC adaptive calibration scheme via an online log-probability proxy. No step reduces by construction to a fitted parameter renamed as prediction, a self-referential definition, or a load-bearing self-citation chain; the central empirical claim rests on benchmark comparisons rather than internal redefinition. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- MTP coefficient
axioms (1)
- domain assumption The per-step effect of MTP on the RL objective decomposes into first-order correlation and second-order perturbation penalty terms.
Reference graph
Works this paper leans on
-
[1]
The Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, and 1 others. 2022. Solving quan- titative reasoning problems with l...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. 2025. Deepscaler: Surpassing o1- preview with a 1.5b model by scaling rl. Notion Blog. Chiyu Ma, Shuo Yang, Kexin Huang, Jind...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Fipo: Eliciting deep reasoning with future- kl influenced policy optimization.arXiv preprint arXiv:2603.19835. NVIDIA. 2025. Nvidia nemotron 3: Efficient and open intelligence. White Paper. Cursor Research, Aaron Chan, Ahmed Shalaby, Alexan- der Wettig, Aman Sanger, Andrew Zhai, Anurag Ajay, Ashvin Nair, Charlie Snell, Chen Lu, and 1 others. 2026. Compose...
-
[4]
arXiv preprint arXiv:2509.01322 , year=
Blockwise parallel decoding for deep autore- gressive models.Advances in Neural Information Processing Systems, 31. Meituan LongCat Team. 2025a. Longcat-flash technical report.Preprint, arXiv:2509.01322. Qwen Team. 2025b. Qwen3 technical report.Preprint, arXiv:2505.09388. veRL Team. 2026. Multi-token prediction in verl. https://verl.readthedocs.io/en/late...
-
[5]
All reported numbers are averages over 32 decodes; random seeds for data shuffling and sampling follow the veRL defaults
evaluation framework with 32 independent samples per prompt (avg@32), using temperature 1.0 and top-p= 0.7 at validation, matching the rollout configuration. All reported numbers are averages over 32 decodes; random seeds for data shuffling and sampling follow the veRL defaults. E Clipping the Adaptive Coefficient A natural question is whether the online ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.