Refining Multidimensional Video Reward Models via Disentangled Influence Functions
Pith reviewed 2026-06-29 13:43 UTC · model grok-4.3
The pith
Disentangled influence functions estimate per-dimension supervision risk to refine multidimensional video reward models beyond global filtering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
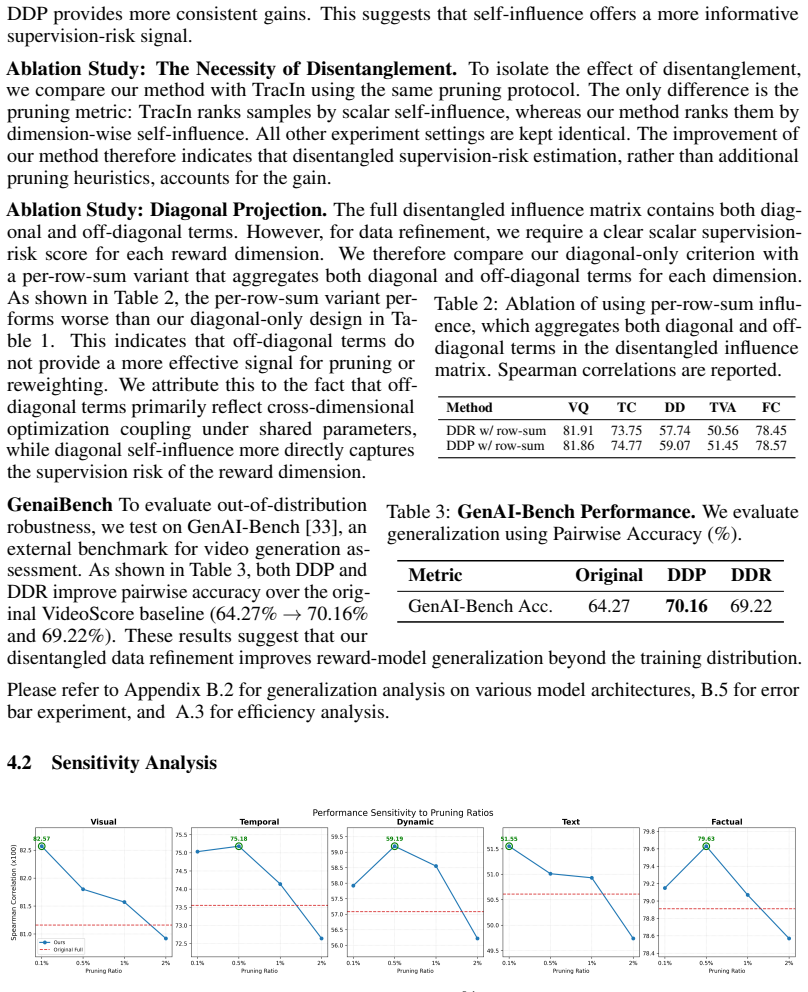
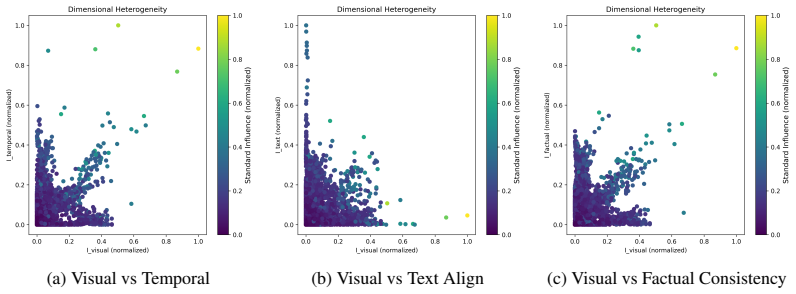
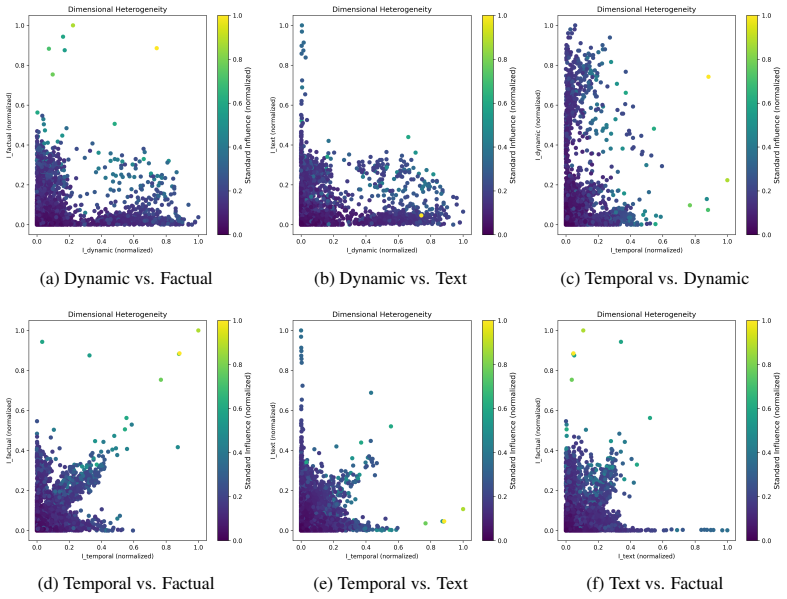
The central claim is that addressing dimensional heterogeneity through a disentangled influence framework enables dimension-specific data refinement strategies, specifically Dimension-Disentangled Pruning and Dimension-Disentangled Reweighting, which outperform global filtering baselines in aligning multidimensional video reward models with ground truth.
What carries the argument
The disentangled influence framework, which efficiently estimates dimension-specific supervision risk for each evaluation dimension.
If this is right
- Dimension-Disentangled Pruning removes samples with extreme high-risk for specific dimensions.
- Dimension-Disentangled Reweighting softly down-weights high-risk supervision per dimension.
- These yield reward models with superior alignment to ground truth compared to global methods.
- The approach handles the complex nature of video data in T2V tasks more effectively than scalar-metric filters.
Where Pith is reading between the lines
- The framework could extend to other multimodal tasks where evaluation dimensions show varying data reliability.
- Influence functions may be adapted more broadly for fine-grained curation when scalar metrics fall short.
- Scalability tests on larger video datasets could expose limits in the risk estimation process.
Load-bearing premise
Dimension-specific supervision risk can be reliably estimated by the disentangled influence framework without the estimation itself introducing new biases or requiring unavailable per-dimension ground-truth labels.
What would settle it
An experiment on a held-out test set where the disentangled pruning and reweighting strategies produce no better or worse alignment metrics than global filtering baselines would falsify the performance claim.
Figures



read the original abstract
As Text-to-Video (T2V) generation models continue to evolve, the complexity of video evaluation necessitates a fine-grained assessment across various axes. To address this, recent works have focused on developing Multidimensional Video Reward Models (MVRMs), which decompose the evaluation process to better align with the multifaceted nature of human visual perception. However, training effective MVRMs is fundamentally challenged by the complex nature of video data. In this work, we identify a critical phenomenon termed Dimensional Heterogeneity: the reliability of a training sample can vary substantially across evaluation dimensions, meaning that a sample may provide reliable supervision for one objective while inducing high supervision risk for another. Consequently, prevailing data-centric methods that filter based on global scalar metrics are ill-posed for T2V tasks. To address this, we propose a disentangled influence framework that that efficiently estimates dimension-specific supervision risk. Leveraging this framework, we introduce two dimension-disentangled refinement strategies: Dimension-Disentangled Pruning, which removes extreme high-risk samples, and Dimension-Disentangled Reweighting, which softly down-weights high-risk supervision. Extensive experiments demonstrate that our disentangled strategies significantly outperform global filtering baselines, yielding reward models with superior alignment to ground truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a phenomenon called Dimensional Heterogeneity in training data for Multidimensional Video Reward Models (MVRMs) for Text-to-Video generation, where a sample's reliability can differ substantially across evaluation dimensions. It argues that global scalar filtering is therefore ill-posed and proposes a disentangled influence framework to estimate per-dimension supervision risk. From this it derives two strategies—Dimension-Disentangled Pruning (removing extreme high-risk samples) and Dimension-Disentangled Reweighting (softly down-weighting high-risk supervision)—and reports that both outperform global filtering baselines, producing reward models with superior alignment to ground truth.
Significance. If the dimension-specific influence estimates prove accurate and the reported gains hold under proper controls, the work would offer a practical data-centric improvement for training fine-grained reward models on complex video data, where scalar metrics are known to be insufficient.
major comments (2)
- [Abstract (and § on disentangled influence framework)] The central claim that the disentangled strategies outperform global baselines rests on the accuracy of the per-dimension supervision-risk estimates. The abstract states that per-dimension ground-truth labels are unavailable in practice, yet provides no alternative validation (e.g., synthetic probes, human correlation studies, or ablation on known noisy dimensions) that the influence-derived scores recover true dimension-specific quality rather than shared video-feature artifacts. Without such evidence the reported gains could be artifacts of the estimation procedure itself.
- [Disentangled influence framework description] Influence functions are defined on a scalar loss; the manuscript must specify the exact decomposition (loss splitting, gradient attribution, or auxiliary heads) used to obtain dimension-specific scores. If the decomposition correlates estimates across dimensions or re-introduces the global metric through shared parameters, the “disentangled” claim is undermined. No equation or algorithmic box in the provided description clarifies this step.
minor comments (1)
- [Abstract] Abstract contains a repeated word: “framework that that efficiently”.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and evidence.
read point-by-point responses
-
Referee: [Abstract (and § on disentangled influence framework)] The central claim that the disentangled strategies outperform global baselines rests on the accuracy of the per-dimension supervision-risk estimates. The abstract states that per-dimension ground-truth labels are unavailable in practice, yet provides no alternative validation (e.g., synthetic probes, human correlation studies, or ablation on known noisy dimensions) that the influence-derived scores recover true dimension-specific quality rather than shared video-feature artifacts. Without such evidence the reported gains could be artifacts of the estimation procedure itself.
Authors: We agree that the absence of direct per-dimension ground-truth labels makes validation important. The reported gains in ground-truth alignment provide indirect support that the estimates capture dimension-specific effects rather than artifacts, as global baselines underperform. To strengthen this, we will add synthetic probe experiments with controlled dimension-specific noise injection in the revision. revision: yes
-
Referee: [Disentangled influence framework description] Influence functions are defined on a scalar loss; the manuscript must specify the exact decomposition (loss splitting, gradient attribution, or auxiliary heads) used to obtain dimension-specific scores. If the decomposition correlates estimates across dimensions or re-introduces the global metric through shared parameters, the “disentangled” claim is undermined. No equation or algorithmic box in the provided description clarifies this step.
Authors: The full manuscript specifies the decomposition via auxiliary dimension-specific heads combined with a per-dimension loss split in the framework section. We will add an explicit algorithmic box and equations in the revision to clarify the procedure and confirm that shared parameters do not reintroduce global metrics. revision: yes
Circularity Check
No circularity: framework and empirical claims are independent of inputs
full rationale
The provided abstract and description introduce Dimensional Heterogeneity as an observed phenomenon and propose a disentangled influence framework to estimate per-dimension supervision risk, followed by pruning and reweighting strategies. No equations, derivations, or self-citations are present that reduce any prediction or uniqueness claim to a fitted parameter or prior author result by construction. The central claim of outperformance over global baselines is presented as an empirical finding from experiments, not a definitional or self-referential necessity. This is the most common honest outcome when no load-bearing reduction is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[8]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[10]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22139–22149, 2024
2024
-
[11]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[12]
Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video generation
Yuanxin Liu, Lei Li, Shuhuai Ren, Rundong Gao, Shicheng Li, Sishuo Chen, Xu Sun, and Lu Hou. Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video generation. Advances in Neural Information Processing Systems, 36:62352–62387, 2023
2023
-
[13]
Mj-video: Benchmarking and rewarding video generation with fine-grained video preference
Haibo Tong, Zhaoyang Wang, Zhaorun Chen, Haonian Ji, Shi Qiu, Siwei Han, Kexin Geng, Zhongkai Xue, Yiyang Zhou, Peng Xia, et al. Mj-video: Benchmarking and rewarding video generation with fine-grained video preference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[14]
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024
2024
-
[15]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation.arXiv preprint arXiv:2412.21059, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Understanding impact of human feedback via influence functions.arXiv preprint arXiv:2501.05790, 2025
Taywon Min, Haeone Lee, Yongchan Kwon, and Kimin Lee. Understanding impact of human feedback via influence functions.arXiv preprint arXiv:2501.05790, 2025
-
[18]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017
2017
-
[19]
Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems, 33:19920–19930, 2020
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems, 33:19920–19930, 2020
2020
-
[20]
Boosting text-to-video generative model with mllms feedback.Advances in Neural Information Processing Systems, 37:139444–139469, 2024
Xun Wu, Shaohan Huang, Guolong Wang, Jing Xiong, and Furu Wei. Boosting text-to-video generative model with mllms feedback.Advances in Neural Information Processing Systems, 37:139444–139469, 2024
2024
-
[21]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[23]
Mantis: Interleaved multi-image instruction tuning.Transactions on Machine Learning Research
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.Transactions on Machine Learning Research
-
[24]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
2024
-
[25]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491, 2018
2018
-
[26]
Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
2020
-
[27]
Reasonable effectiveness of random weighting: A litmus test for multi-task learning.Transactions on Machine Learning Research
Baijiong Lin, Feiyang Ye, Yu Zhang, and Ivor Tsang. Reasonable effectiveness of random weighting: A litmus test for multi-task learning.Transactions on Machine Learning Research
-
[28]
Data pruning via moving-one-sample-out.Advances in Neural Information Processing Systems, 36, 2024
Haoru Tan, Sitong Wu, Fei Du, Yukang Chen, Zhibin Wang, Fan Wang, and Xiaojuan Qi. Data pruning via moving-one-sample-out.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[29]
Relatif: Identifying explanatory training samples via relative influence
Elnaz Barshan, Marc-Etienne Brunet, and Gintare Karolina Dziugaite. Relatif: Identifying explanatory training samples via relative influence. InInternational Conference on Artificial Intelligence and Statistics, pages 1899–1909. PMLR, 2020
1909
-
[30]
Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
-
[31]
Fast approximate natural gradient descent in a kronecker factored eigenbasis.Advances in neural information processing systems, 31, 2018
Thomas George, César Laurent, Xavier Bouthillier, Nicolas Ballas, and Pascal Vincent. Fast approximate natural gradient descent in a kronecker factored eigenbasis.Advances in neural information processing systems, 31, 2018
2018
-
[32]
Variational bayesian last layers.arXiv preprint arXiv:2404.11599, 2024
James Harrison, John Willes, and Jasper Snoek. Variational bayesian last layers.arXiv preprint arXiv:2404.11599, 2024
-
[33]
Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024. 11 A Proof of Theorem 3.1 In this section, we provide the detailed derivation of the Disentangled Influence Decomposition presented i...
2024
-
[34]
Parameter-Space Reduction:By restricting the influence analysis to the last linear layer, we reduce the problem scale from the vast full-parameter space ( P≈8B ) to the low- dimensional feature space (d≈4096), realizing a complexity reduction ofO(P)→ O(d)
-
[35]
Backward-Free Estimation:Crucially, our closed-form derivation allows us to compute the exact gradient norm using only forward-pass statistics (residuals and embeddings). This completely eliminates the need for the computationally expensive backpropagation process (backward pass), which typically consumes significantly more time and memory than the forwar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.