Revisiting Metafeatures to Explain Model Differences on Tabular Data
Pith reviewed 2026-06-29 14:30 UTC · model grok-4.3
The pith
Meta-features fail to explain performance gaps between model families on tabular data after strict tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
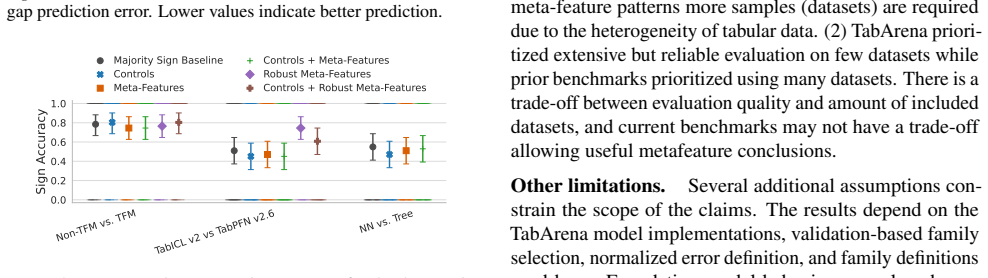
After applying strict statistical tests with false discovery rate control to the TabArena benchmark, no meta-feature survives for explaining neural network versus tree model gaps; one association is robust for non-foundation versus foundation model gaps but does not generalize in leave-one-dataset-out tests; and one robust association for TabICLv2 versus TabPFN-2.6 does improve held-out prediction. Leave-one-dataset-out analysis shows meta-feature predictors do not meaningfully outperform a simple baseline, indicating heterogeneity in tabular datasets and limited robustness of global meta-feature approaches.
What carries the argument
Model-agnostic dataset meta-features linked to performance gaps via statistical tests with FDR control on the TabArena benchmark results.
If this is right
- Global meta-feature approaches are not robust enough to explain model differences on the 51 TabArena datasets.
- Tabular datasets show high heterogeneity that limits universal explanations.
- One specific association between a meta-feature and the TabICLv2 versus TabPFN-2.6 gap improves held-out prediction.
- Meta-feature predictors do not meaningfully beat a simple baseline in leave-one-dataset-out analysis.
Where Pith is reading between the lines
- Dataset-specific or local descriptors may be needed instead of global meta-features for model selection explanations.
- Non-linear or interaction-based relationships among meta-features could be tested in follow-up work.
- Model choice on tabular tasks may hinge on factors outside standard meta-feature sets.
Load-bearing premise
The analysis assumes that the TabArena benchmark performance estimates are stable and representative, and that the selected model-agnostic meta-features plus the chosen statistical tests would detect any genuine explanatory relationships if they existed.
What would settle it
A collection of new tabular datasets where at least one meta-feature consistently predicts performance gaps across model family comparisons, survives FDR control, and improves prediction accuracy in leave-one-dataset-out validation.
Figures


read the original abstract
With the rise of tabular foundation models alongside traditional models still performing well on many tasks, choosing the right model for a tabular dataset remains difficult. We investigate whether dataset meta-features can explain performance gaps between model families on tabular prediction tasks. Using the TabArena benchmark results, we analyze dataset-level performance gaps and relate them to model-agnostic dataset descriptors. After strict statistical tests with false discovery control, we find that (1) for neural network vs. tree gaps, no meta-feature survives false discovery control, (2) for non-foundation vs. foundation model gaps, one association is robust but does not generalize when tested in leave-one-dataset-out prediction, and (3) for TabICLv2 vs. TabPFN-2.6, one robust association also improves held-out prediction. Furthermore, we conduct a leave-one-dataset-out analysis and find that meta-feature predictors fail to improve meaningfully over a simple baseline. Overall, our results show the heterogeneity of tabular datasets and that global meta-feature approaches are not robust enough to offer explanations on the 51 TabArena datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes performance gaps between model families (NN vs. trees, non-foundation vs. foundation models, TabICLv2 vs. TabPFN) on the 51 TabArena tabular datasets using model-agnostic meta-features. It applies FDR-controlled statistical tests to identify associations and conducts leave-one-dataset-out validation to assess whether meta-feature predictors can explain gaps better than a simple baseline. The central claims are that no meta-features survive FDR for NN-tree gaps, one association appears for foundation-model gaps but fails to generalize in LODO, one robust association improves prediction for TabICLv2 vs. TabPFN, and overall meta-feature predictors do not meaningfully outperform the baseline, indicating high dataset heterogeneity and limited robustness of global meta-feature approaches.
Significance. If the negative results hold after addressing power and coverage concerns, the work would usefully demonstrate the limitations of standard meta-features for explaining tabular model differences, reinforcing the value of the TabArena benchmark and strict controls (FDR, LODO) for producing reliable negative findings. This could shift research away from global meta-feature explanations toward more localized or structural descriptors.
major comments (2)
- [Abstract and Results] Abstract and Results: the central negative claim that 'no meta-feature survives false discovery control' for NN-vs-tree gaps (and the broader conclusion on lack of robustness) is load-bearing, yet with n=51 the manuscript does not report achieved statistical power or minimum detectable correlation after FDR correction across the tested meta-features; moderate associations (|r|≈0.35) could plausibly go undetected.
- [Leave-one-dataset-out analysis] Leave-one-dataset-out analysis: the claim that meta-feature predictors 'fail to improve meaningfully over a simple baseline' is central to the overall conclusion, but the manuscript does not specify the exact baseline model, the meta-feature set size, or the quantitative gap in predictive performance (e.g., R² or MAE differences), making it impossible to judge whether the failure is decisive or merely modest.
minor comments (2)
- [Methods] The exact definitions and selection criteria for the model-agnostic meta-features should be stated explicitly (perhaps in a dedicated table) to allow readers to assess coverage of potential confounders such as distributional or structural properties.
- [Data and Experimental Setup] Clarify whether the TabArena performance estimates include variance or confidence intervals, as stability of these estimates is assumed in the LODO evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical transparency. We agree that additional details on power and baseline specification will improve the manuscript and will incorporate them in revision. These changes address the concerns without altering our core negative findings on the limited explanatory power of meta-features.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: the central negative claim that 'no meta-feature survives false discovery control' for NN-vs-tree gaps (and the broader conclusion on lack of robustness) is load-bearing, yet with n=51 the manuscript does not report achieved statistical power or minimum detectable correlation after FDR correction across the tested meta-features; moderate associations (|r|≈0.35) could plausibly go undetected.
Authors: We acknowledge the value of reporting achieved power for interpreting our negative results. While FDR control was our primary safeguard against false positives, we will add a post-hoc power analysis in the revised Results section. This will quantify the minimum detectable correlation (e.g., for |r| = 0.3 and 0.4) given n=51 and the number of meta-features tested under FDR. The addition will clarify the strength of evidence for the absence of robust associations. revision: yes
-
Referee: [Leave-one-dataset-out analysis] Leave-one-dataset-out analysis: the claim that meta-feature predictors 'fail to improve meaningfully over a simple baseline' is central to the overall conclusion, but the manuscript does not specify the exact baseline model, the meta-feature set size, or the quantitative gap in predictive performance (e.g., R² or MAE differences), making it impossible to judge whether the failure is decisive or merely modest.
Authors: We will revise the manuscript to explicitly define the baseline (a constant predictor using the mean gap from training folds), state the exact number of meta-features employed, and report the quantitative performance gaps (including R² and MAE differences) between the meta-feature model and baseline in the LODO experiments. These details will be added to the Methods and Results to allow precise evaluation of the improvement magnitude. revision: yes
Circularity Check
No circularity in empirical analysis of external benchmarks
full rationale
The paper reports statistical associations (or their absence) between precomputed TabArena performance gaps and a fixed set of model-agnostic meta-features on 51 datasets. All load-bearing steps are direct applications of standard tests (FDR-controlled correlations, leave-one-dataset-out regression) to external data; no equation, parameter fit, or claim reduces to a self-definition or to a prior result whose only support is a self-citation. The negative findings on meta-feature explanatory power are therefore falsifiable outcomes of the chosen data and tests rather than artifacts of the analysis construction itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption TabArena benchmark results provide stable, unbiased estimates of model performance on the included datasets.
- domain assumption The selected model-agnostic meta-features capture the dataset properties relevant to model-family performance differences.
Reference graph
Works this paper leans on
-
[1]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
ISBN 978-1-4612-4380-9. doi: 10.1007/ 978-1-4612-4380-9 41. URL https://doi.org/ 10.1007/978-1-4612-4380-9_41. Erickson, N., Mueller, J., Shirkov, A., Zhang, H., Lar- roy, P., Li, M., and Smola, A. AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data, March 2020. URL http://arxiv.org/abs/ 2003.06505. arXiv:2003.06505 [stat]. Erickson, N., Pur...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-1-4612-4380-9_41 2020
-
[2]
doi: 10.1145/2487575.2487579. URL https://dl. acm.org/doi/10.1145/2487575.2487579. Ma, J., Thomas, V ., Hosseinzadeh, R., Labach, A., Kamkari, H., Cresswell, J. C., Golestan, K., Yu, G., Caterini, A. L., and V olkovs, M. TabDPT: Scaling Tabular Foundation Models on Real Data, 2024. URL https://arxiv. org/abs/2410.18164. Version Number: 3. McElfresh, D., K...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.