Transformers Provably Learn to Internalize Chain-of-Thought
Pith reviewed 2026-06-29 14:25 UTC · model grok-4.3
The pith
An L-layer transformer learns k-parity with polynomial samples by internalizing chain-of-thought via a logarithmic curriculum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
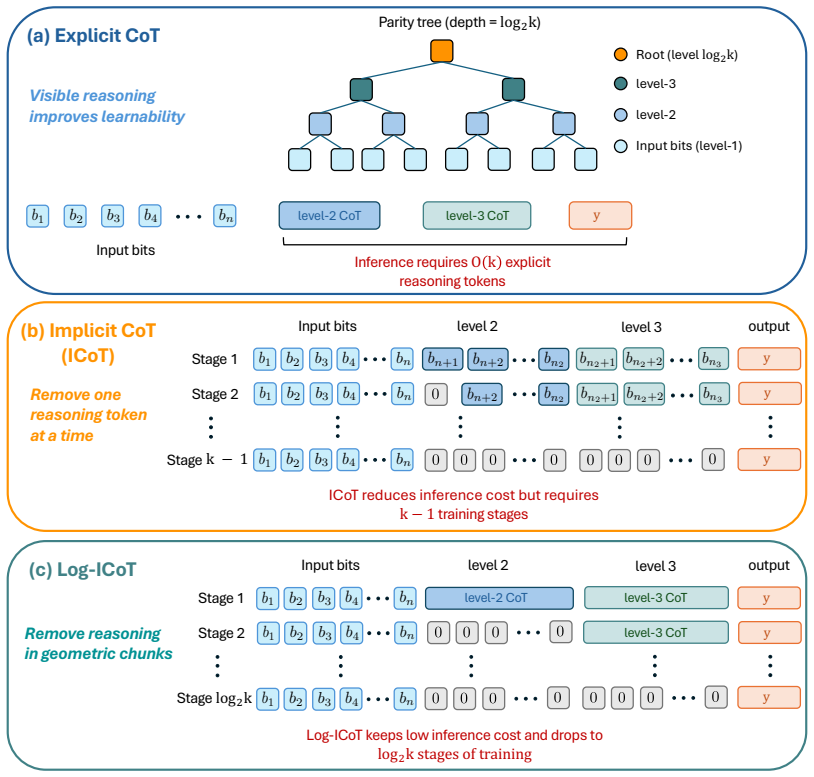
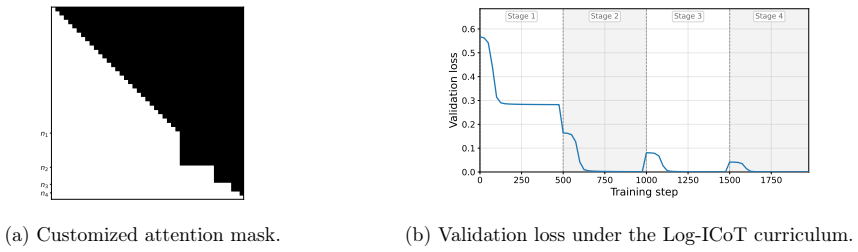
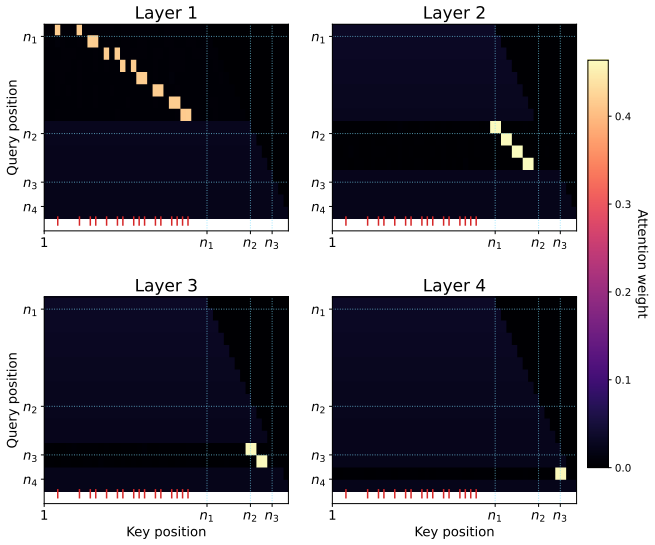
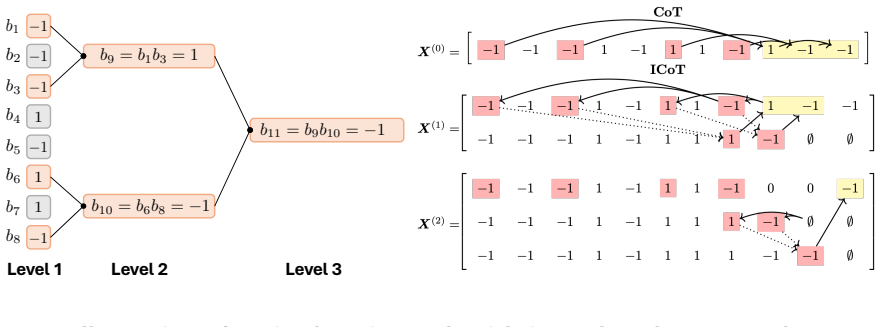
An L-layer transformer trained under the proposed Log-ICoT curriculum learns k-parity with poly(n) samples and L = log_2 k training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in k to logarithmic.
What carries the argument
The Log-ICoT curriculum that removes thinking tokens in geometric chunks across log k stages, allowing progressive absorption of reasoning into deeper layers.
If this is right
- Multi-layer transformers achieve the same polynomial sample complexity for k-parity as explicit CoT without incurring inference-time generation cost.
- The number of training stages needed scales as log k rather than linearly with k.
- Reasoning is progressively folded into deeper layers as the curriculum advances.
- The result extends one-layer theoretical guarantees to architectures with multiple layers.
Where Pith is reading between the lines
- The same geometric removal schedule might allow internalization on reasoning tasks other than parity.
- Models trained this way could operate with shorter output sequences at deployment while retaining the benefit of intermediate computation.
- Varying the chunk size schedule could yield further reductions in the number of training stages.
Load-bearing premise
The transformer and its training dynamics must allow reasoning steps to be progressively absorbed into deeper layers when thinking tokens are removed in geometric chunks.
What would settle it
Train an L = log_2 k layer transformer on k-parity under the Log-ICoT schedule and observe whether it achieves poly(n) sample efficiency; failure to do so would falsify the claim.
Figures
read the original abstract
Chain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states, but its theoretical foundations remain poorly understood. We give the first theoretical analysis of ICoT, proving that an $L$-layer transformer trained under our proposed Log-ICoT curriculum learns $k$-parity with $\mathsf{poly}(n)$ samples and $L = \log_2 k$ training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in $k$ to logarithmic. Experiments on multi-layer transformers confirm the theory and visualize how reasoning is progressively absorbed into deeper layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to give the first theoretical analysis of Implicit Chain-of-Thought (ICoT), proving that an L-layer transformer trained under the proposed Log-ICoT curriculum (removing thinking tokens in geometric chunks over log_2 k stages) learns k-parity with poly(n) samples using L = log_2 k training stages. This is asserted to match the sample efficiency of explicit CoT while eliminating inference overhead and to extend prior one-layer parity guarantees to multi-layer architectures. Experiments are said to confirm the result and visualize progressive absorption of reasoning into deeper layers.
Significance. If the central theorem is correct, the work would supply the first rigorous account of how transformers can internalize CoT steps, with the logarithmic-stage curriculum offering a concrete improvement over one-at-a-time removal. The poly(n) sample bound and the explicit link to multi-layer architectures would be notable strengths, as would any reproducible experimental visualization of layer-wise absorption.
major comments (2)
- [Main theorem and its proof (abstract and §3–4)] The central claim that gradient descent on an L-layer transformer under Log-ICoT produces progressive absorption of reasoning chunks into successively deeper layers (thereby closing the inductive step from the one-layer case) is load-bearing yet rests on uncharacterized training dynamics. No architectural assumptions (e.g., on residual connections, attention heads, or the optimizer) or inductive argument are supplied that guarantee absorption occurs once intermediate tokens are removed.
- [Theorem 1 (or equivalent main result statement)] The theorem statement asserts a poly(n) sample bound but supplies neither explicit assumptions, dependence on k, nor error bounds. Without these, it is impossible to verify whether the claimed complexity is robust or whether post-hoc choices in the curriculum or architecture affect the polynomial degree.
minor comments (1)
- The abstract refers to experiments confirming the theory and visualizing absorption, but the summary provides no numbered figures, tables, or specific metrics (e.g., accuracy vs. stage). Ensure all experimental claims are cross-referenced to concrete results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments below.
read point-by-point responses
-
Referee: [Main theorem and its proof (abstract and §3–4)] The central claim that gradient descent on an L-layer transformer under Log-ICoT produces progressive absorption of reasoning chunks into successively deeper layers (thereby closing the inductive step from the one-layer case) is load-bearing yet rests on uncharacterized training dynamics. No architectural assumptions (e.g., on residual connections, attention heads, or the optimizer) or inductive argument are supplied that guarantee absorption occurs once intermediate tokens are removed.
Authors: Sections 3 and 4 contain an inductive argument that extends the one-layer parity analysis to the multi-layer setting under the Log-ICoT curriculum. The architecture is the standard L-layer transformer with residual connections and multi-head attention as defined in Section 2; the optimizer is gradient descent with the learning rate schedule stated in the proof. The geometric chunk removal is shown to produce the required absorption via a layer-wise analysis of the attention and feed-forward updates. We agree that the assumptions and inductive step can be stated more explicitly and will add a dedicated paragraph listing them together with a highlighted inductive step in the revision. revision: yes
-
Referee: [Theorem 1 (or equivalent main result statement)] The theorem statement asserts a poly(n) sample bound but supplies neither explicit assumptions, dependence on k, nor error bounds. Without these, it is impossible to verify whether the claimed complexity is robust or whether post-hoc choices in the curriculum or architecture affect the polynomial degree.
Authors: Theorem 1 states that under the Log-ICoT curriculum with L = log_2 k stages the sample complexity is poly(n) with degree independent of k and failure probability 1/poly(n). The assumptions are those of the standard transformer architecture and the curriculum defined in Section 2. We will revise the theorem statement to list the assumptions, the explicit logarithmic dependence on k through the number of stages, and the error bound in a single displayed line for clarity. revision: yes
Circularity Check
No circularity; theoretical proof extends prior results without definitional reduction or load-bearing self-citation
full rationale
The provided abstract and description present the central result as a mathematical proof that an L-layer transformer under the Log-ICoT curriculum learns k-parity with poly(n) samples. No equations, fitted parameters, or self-citations are quoted that reduce any prediction or uniqueness claim to its own inputs by construction. The extension of one-layer parity guarantees is stated as an independent theoretical step rather than a renaming or ansatz imported from overlapping prior work. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[3]
Birth of a transformer: A memory viewpoint
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems, 36: 0 1560--1588, 2023
2023
-
[4]
Transformers learn through gradual rank increase
Enric Boix-Adsera, Etai Littwin, Emmanuel Abbe, Samy Bengio, and Joshua Susskind. Transformers learn through gradual rank increase. Advances in Neural Information Processing Systems, 36: 0 24519--24551, 2023
2023
-
[5]
Distributional associations vs in-context reasoning: A study of feed-forward and attention layers
Lei Chen, Joan Bruna, and Alberto Bietti. Distributional associations vs in-context reasoning: A study of feed-forward and attention layers. arXiv preprint arXiv:2406.03068, 2024
-
[6]
Implicit chain of thought reasoning via knowledge distillation
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation. arXiv preprint arXiv:2311.01460, 2023
-
[7]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step. arXiv preprint arXiv:2405.14838, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
2021
-
[9]
Towards revealing the mystery behind chain of thought: a theoretical perspective
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems, 36: 0 70757--70798, 2023
2023
-
[10]
What can a single attention layer learn? a study through the random features lens
Hengyu Fu, Tianyu Guo, Yu Bai, and Song Mei. What can a single attention layer learn? a study through the random features lens. Advances in Neural Information Processing Systems, 36: 0 11912--11951, 2023
2023
-
[11]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023
-
[12]
Continuous chain of thought enables parallel exploration and reasoning
Halil Alperen Gozeten, M Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning. arXiv preprint arXiv:2505.23648, 2025
-
[13]
Active-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms
Tianyu Guo, Druv Pai, Yu Bai, Jiantao Jiao, Michael I Jordan, and Song Mei. Active-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms. arXiv preprint arXiv:2410.13835, 2024
-
[14]
How do llms perform two-hop reasoning in context? arXiv preprint arXiv:2502.13913, 2025
Tianyu Guo, Hanlin Zhu, Ruiqi Zhang, Jiantao Jiao, Song Mei, Michael I Jordan, and Stuart Russell. How do llms perform two-hop reasoning in context? arXiv preprint arXiv:2502.13913, 2025
-
[15]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Transformers learn to implement multi-step gradient descent with chain of thought
Jianhao Huang, Zixuan Wang, and Jason D Lee. Transformers learn to implement multi-step gradient descent with chain of thought. arXiv preprint arXiv:2502.21212, 2025 a
-
[17]
Generalization or hallucination? understanding out-of-context reasoning in transformers
Yixiao Huang, Hanlin Zhu, Tianyu Guo, Jiantao Jiao, Somayeh Sojoudi, Michael I Jordan, Stuart Russell, and Song Mei. Generalization or hallucination? understanding out-of-context reasoning in transformers. arXiv preprint arXiv:2506.10887, 2025 b
-
[18]
In-context convergence of transformers
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. In Proceedings of the 41st International Conference on Machine Learning, pages 19660--19722, 2024
2024
-
[19]
Reinforcement Learning via Self-Distillation
Jonas H \"u botter, Frederike L \"u beck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
From self-attention to markov models: Unveiling the dynamics of generative transformers
M Emrullah Ildiz, Yixiao Huang, Yingcong Li, Ankit Singh Rawat, and Samet Oymak. From self-attention to markov models: Unveiling the dynamics of generative transformers. arXiv preprint arXiv:2402.13512, 2024
-
[21]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2704--2713, 2018
2018
-
[22]
Vision transformers provably learn spatial structure
Samy Jelassi, Michael Sander, and Yuanzhi Li. Vision transformers provably learn spatial structure. Advances in Neural Information Processing Systems, 35: 0 37822--37836, 2022
2022
-
[23]
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Transformers provably solve parity efficiently with chain of thought
Juno Kim and Taiji Suzuki. Transformers provably solve parity efficiently with chain of thought. arXiv preprint arXiv:2410.08633, 2024
-
[25]
Juncai Li, Ru Li, Yuxiang Zhou, and Jeff Z. Pan. Dissecting implicit chain of thought: Can transformers learn it spontaneously?, 2026. URL https://openreview.net/forum?id=loP9q6E5kQ
2026
-
[26]
Mechanics of next token prediction with self-attention
Yingcong Li, Yixiao Huang, Muhammed E Ildiz, Ankit Singh Rawat, and Samet Oymak. Mechanics of next token prediction with self-attention. In International Conference on Artificial Intelligence and Statistics, pages 685--693. PMLR, 2024 a
2024
-
[27]
Chain of thought empowers transformers to solve inherently serial problems
Zhiyuan Li, Hong Liu, Denny Zhou, and Tengyu Ma. Chain of thought empowers transformers to solve inherently serial problems. arXiv preprint arXiv:2402.12875, 1, 2024 b
-
[28]
Transformers learn shortcuts to automata
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022
-
[29]
Pause tokens strictly increase the expressivity of constant-depth transformers
Charles London and Varun Kanade. Pause tokens strictly increase the expressivity of constant-depth transformers. arXiv preprint arXiv:2505.21024, 2025
-
[30]
Breaking the Reversal Curse in Autoregressive Language Models via Identity Bridge
Xutao Ma, Yixiao Huang, Hanlin Zhu, and Somayeh Sojoudi. Breaking the reversal curse in autoregressive language models via identity bridge. arXiv preprint arXiv:2602.02470, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Arvind Mahankali, Tatsunori B Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. arXiv preprint arXiv:2307.03576, 2023
-
[32]
Exact expressive power of transformers with padding
Will Merrill and Ashish Sabharwal. Exact expressive power of transformers with padding. Advances in Neural Information Processing Systems, 38: 0 112497--112524, 2026
2026
-
[33]
The expressive power of transformers with chain of thought
William Merrill and Ashish Sabharwal. The expressive power of transformers with chain of thought. arXiv preprint arXiv:2310.07923, 2023
-
[34]
How transformers learn causal structure with gradient descent
Eshaan Nichani, Alex Damian, and Jason D Lee. How transformers learn causal structure with gradient descent. In International Conference on Machine Learning, pages 38018--38070. PMLR, 2024
2024
-
[35]
Stabilizing transformers for reinforcement learning
Emilio Parisotto, Francis Song, Jack Rae, Razvan Pascanu, Caglar Gulcehre, Siddhant Jayakumar, Max Jaderberg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, et al. Stabilizing transformers for reinforcement learning. In International conference on machine learning, pages 7487--7498. PMLR, 2020
2020
-
[36]
Let's think dot by dot: Hidden computation in transformer language models
Jacob Pfau, William Merrill, and Samuel R Bowman. Let's think dot by dot: Hidden computation in transformer language models. arXiv preprint arXiv:2404.15758, 2024
-
[37]
Learning and transferring sparse contextual bigrams with linear transformers
Yunwei Ren, Zixuan Wang, and Jason D Lee. Learning and transferring sparse contextual bigrams with linear transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[38]
Failures of gradient-based deep learning
Shai Shalev-Shwartz, Ohad Shamir, and Shaked Shammah. Failures of gradient-based deep learning. In International Conference on Machine Learning, pages 3067--3075. PMLR, 2017
2017
-
[39]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Rupesh Kumar Srivastava, Klaus Greff, and J \"u rgen Schmidhuber. Highway networks. arXiv preprint arXiv:1505.00387, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Token assorted: Mixing latent and text tokens for improved language model reasoning
DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, and Qinqing Zheng. Token assorted: Mixing latent and text tokens for improved language model reasoning. arXiv preprint arXiv:2502.03275, 2025
-
[42]
Scan and snap: Understanding training dynamics and token composition in 1-layer transformer
Yuandong Tian, Yiping Wang, Beidi Chen, and Simon S Du. Scan and snap: Understanding training dynamics and token composition in 1-layer transformer. Advances in neural information processing systems, 36: 0 71911--71947, 2023 a
2023
-
[43]
Joma: Demystifying multilayer transformers via joint dynamics of mlp and attention
Yuandong Tian, Yiping Wang, Zhenyu Zhang, Beidi Chen, and Simon Du. Joma: Demystifying multilayer transformers via joint dynamics of mlp and attention. arXiv preprint arXiv:2310.00535, 2023 b
-
[44]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935, 2023 a
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Guiding language model reasoning with planning tokens
Xinyi Wang, Lucas Caccia, Oleksiy Ostapenko, Xingdi Yuan, William Yang Wang, and Alessandro Sordoni. Guiding language model reasoning with planning tokens. arXiv preprint arXiv:2310.05707, 2023 b
-
[46]
Zixuan Wang, Stanley Wei, Daniel Hsu, and Jason D. Lee. Transformers provably learn sparse token selection while fully-connected nets cannot. In ICML, 2024
2024
-
[47]
Learning compositional functions with transformers from easy-to-hard data
Zixuan Wang, Eshaan Nichani, Alberto Bietti, Alex Damian, Daniel Hsu, Jason D Lee, and Denny Wu. Learning compositional functions with transformers from easy-to-hard data. arXiv preprint arXiv:2505.23683, 2025
-
[48]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
2022
-
[49]
Kaiyue Wen, Huaqing Zhang, Hongzhou Lin, and Jingzhao Zhang. From sparse dependence to sparse attention: unveiling how chain-of-thought enhances transformer sample efficiency. arXiv preprint arXiv:2410.05459, 2024
-
[50]
Sub-task decomposition enables learning in sequence to sequence tasks
Noam Wies, Yoav Levine, and Amnon Shashua. Sub-task decomposition enables learning in sequence to sequence tasks. arXiv preprint arXiv:2204.02892, 2022
-
[51]
Integer quantization for deep learning inference: Principles and empirical evaluation
Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev, and Paulius Micikevicius. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv preprint arXiv:2004.09602, 2020
-
[52]
Residual: Transformer with dual residual connections
Shufang Xie, Huishuai Zhang, Junliang Guo, Xu Tan, Jiang Bian, Hany Hassan Awadalla, Arul Menezes, Tao Qin, and Rui Yan. Residual: Transformer with dual residual connections. arXiv preprint arXiv:2304.14802, 2023
-
[53]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Trained transformers learn linear models in-context
Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-context. Journal of Machine Learning Research, 25 0 (49): 0 1--55, 2024
2024
-
[56]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models. arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Sch \"a rli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-connections. arXiv preprint arXiv:2409.19606, 2024 a
-
[59]
Towards a theoretical understanding of the'reversal curse'via training dynamics
Hanlin Zhu, Baihe Huang, Shaolun Zhang, Michael Jordan, Jiantao Jiao, Yuandong Tian, and Stuart J Russell. Towards a theoretical understanding of the'reversal curse'via training dynamics. Advances in Neural Information Processing Systems, 37: 0 90473--90513, 2024 b
2024
-
[60]
Emergence of superposition: Unveiling the training dynamics of chain of continuous thought
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Emergence of superposition: Unveiling the training dynamics of chain of continuous thought. arXiv preprint arXiv:2509.23365, 2025 a
-
[61]
Reasoning by superposition: A theoretical perspective on chain of continuous thought
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought. arXiv preprint arXiv:2505.12514, 2025 b
-
[62]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[63]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[64]
proofsk Proof sketch
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.