An Architecture-Agnostic High-Order Discontinuous Galerkin Framework for Compressible Flows
Pith reviewed 2026-06-29 09:49 UTC · model grok-4.3
The pith
GALÆXI delivers an architecture-agnostic high-order DGSEM framework for compressible flows that runs on both NVIDIA and AMD GPUs from a single Fortran codebase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
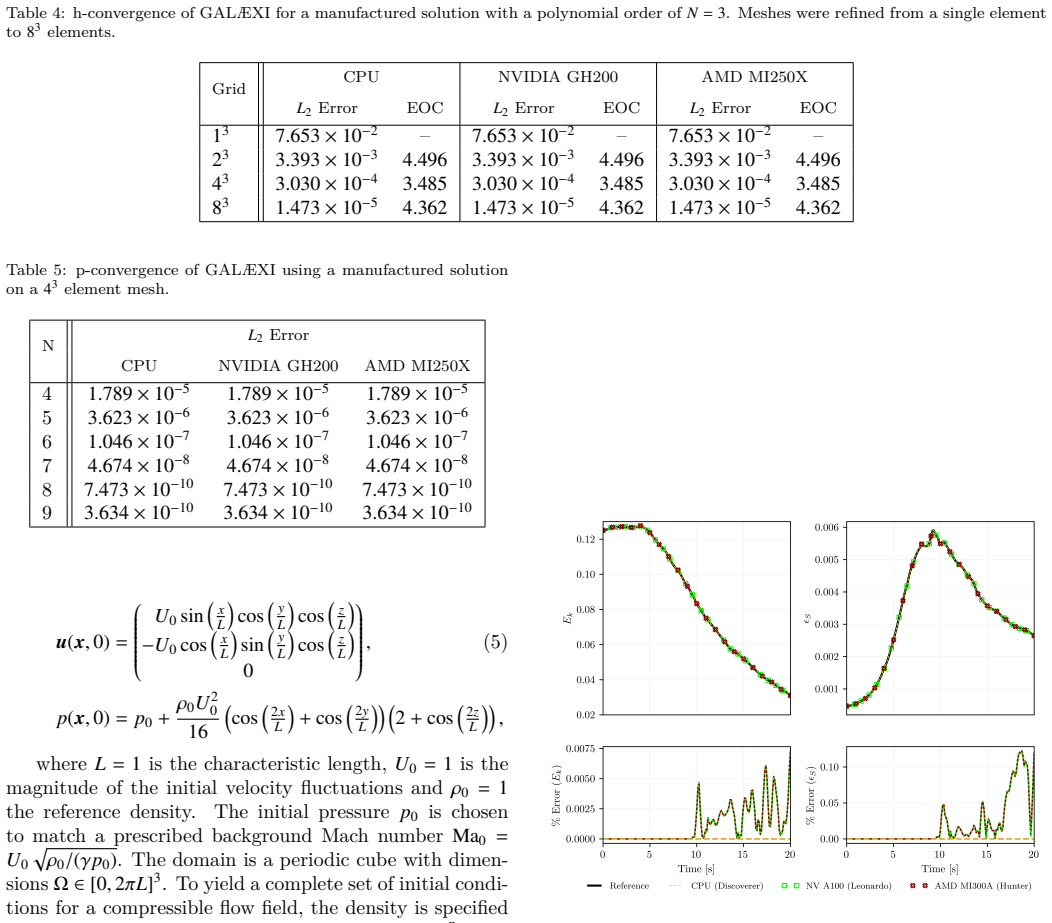
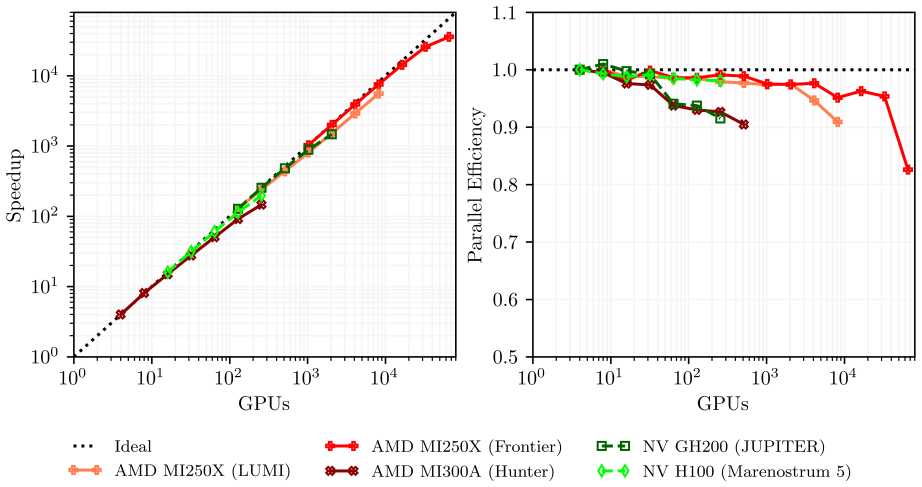
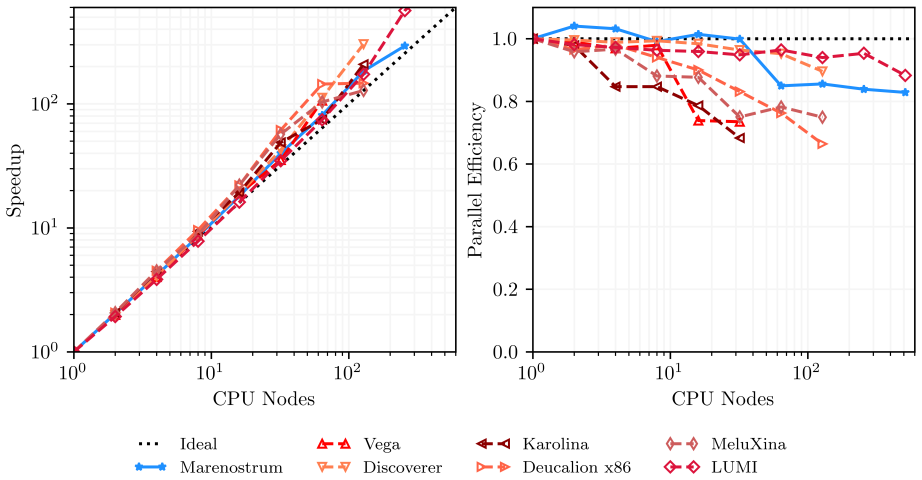
GALÆXI is an open source architecture-agnostic toolchain for high-order DGSEM computations of complex compressible turbulent flows on unstructured hexahedral grids. GPU-accelerated computations are enabled by interfacing Fortran source code to CUDA C++ for NVIDIA and HIP C++ for AMD. The DGSEM implementation is verified to the expected order of convergence via the method of manufactured solutions and shows excellent agreement with reference solutions for the compressible Taylor-Green vortex across all supported architectures. Near-ideal strong and weak scaling is achieved on both NVIDIA and AMD GPU hardware, including a simulation with 67.1 billion degrees of freedom on 65,536 AMD MI250X dev
What carries the argument
The Fortran-to-CUDA and Fortran-to-HIP interfaces that allow a single DGSEM source code to execute on multiple GPU architectures while preserving the high-order discretization on unstructured hexahedral grids.
If this is right
- High-order accuracy and agreement with reference solutions hold across both NVIDIA and AMD GPU hardware for verification cases.
- Near-ideal strong and weak scaling is maintained up to at least 65,536 AMD MI250X devices for simulations exceeding 67 billion degrees of freedom.
- GPU-based runs deliver 7.75x to 8.08x speedups over CPU computations in time-to-solution while using less than half the energy per node.
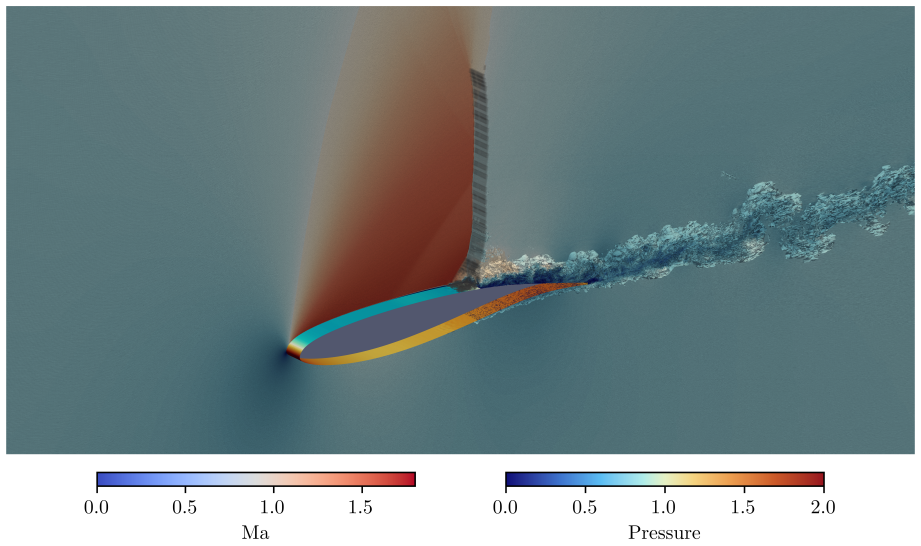
- Wall-resolved large eddy simulations of transonic flows past airfoils with shock buffet are feasible at production scale on the supported architectures.
Where Pith is reading between the lines
- Similar interface layers could allow other high-order CFD codes to support additional GPU vendors without full rewrites.
- Users could run identical simulations on whichever hardware is available or cheaper at a given facility.
- The framework opens the possibility of direct numerical comparisons between results computed on different GPU architectures to check for implementation-specific biases.
Load-bearing premise
The Fortran-to-CUDA and Fortran-to-HIP interfaces maintain numerical correctness and performance portability without hidden vendor-specific optimizations that would break the architecture-agnostic claim.
What would settle it
A side-by-side run of the method of manufactured solutions on NVIDIA and AMD hardware that produces different observed orders of convergence or solution errors for the same problem setup.
Figures



read the original abstract
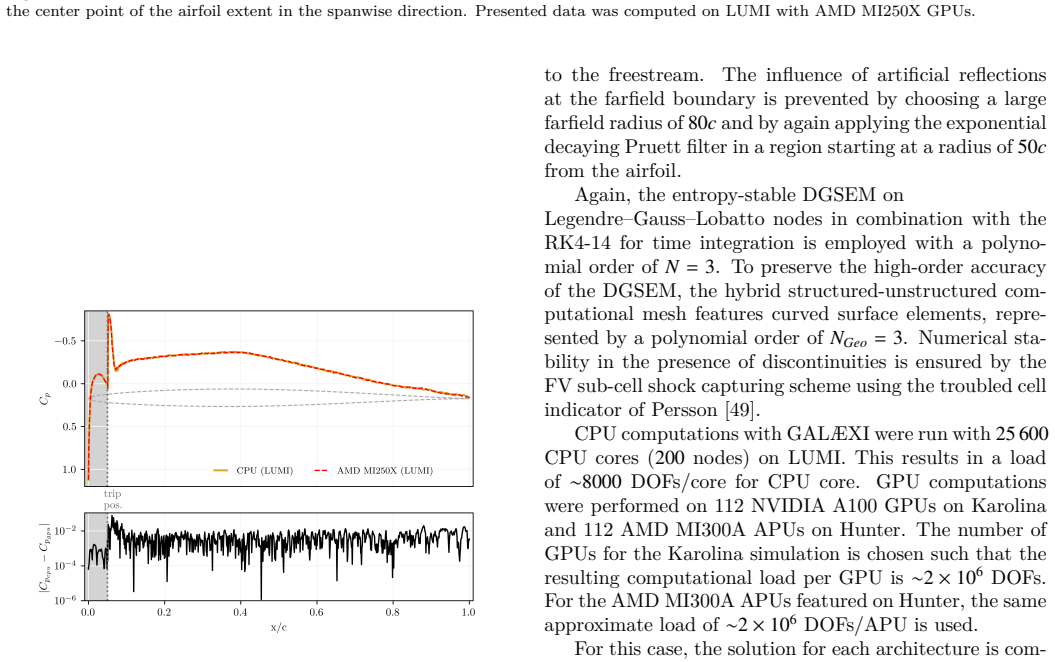
With the recent proliferation of heterogeneous, GPU-accelerated supercomputers, high-order computational fluid dynamics (CFD) simulations of complex, turbulent flows are more accessible than ever. To leverage the computing power of these machines, CFD software must adapt. However, complicating the situation is the emerging need to support hardware from multiple GPU vendors. Addressing this need is the GPU-accelerated, discontinuous Galerkin spectral element method (DGSEM) framework GAL{\AE}XI, a high-order, open source, architecture-agnostic toolchain for the study of complex, compressible, turbulent flows on unstructured, hexahedral grids. GPU-accelerated computations with GAL{\AE}XI are possible on GPU hardware by interfacing Fortran source code to the vendor models CUDA C++ for NVIDIA and HIP C++ for AMD. The DGSEM implementation in GAL{\AE}XI was verified using the method of manufactured solutions to rigorously confirm the expected order of convergence. Simulations of a compressible Taylor-Green-Vortex also demonstrated excellent agreement with reference solutions across all supported architectures. GAL{\AE}XI achieved near ideal strong and weak scaling on GPU hardware from both NVIDIA and AMD. In the largest case, GAL{\AE}XI performed a simulation with 67.1 billion degrees of freedom on 65,536 AMD MI250X graphics compute devices with a parallel efficiency of 82.6%. Comparing node-to-node performance, GPU simulations offered speedups between 7.75x and 8.08x over CPU computations in time-to-solution while consuming less than half the energy. To demonstrate GAL{\AE}XI's effectiveness for production-scale simulations, wall-resolved large eddy simulations of the transonic flow past a NACA 64A-110 airfoil and an ONERA OAT15A airfoil under shock buffet conditions were computed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GALÆXI, an open-source DGSEM framework for compressible flows on unstructured hexahedral grids that achieves architecture-agnostic GPU acceleration by interfacing Fortran source to CUDA C++ (NVIDIA) and HIP C++ (AMD). The DGSEM implementation is verified via the method of manufactured solutions for expected convergence order and tested on the compressible Taylor-Green vortex, showing agreement with reference solutions across architectures. The work reports near-ideal strong and weak scaling, including a 67.1-billion-DOF simulation on 65,536 AMD MI250X devices at 82.6% parallel efficiency, node-to-node GPU speedups of 7.75–8.08× over CPU with less than half the energy consumption, and demonstrates production use via wall-resolved LES of transonic airfoil flows under shock-buffet conditions.
Significance. If the results hold, the contribution is significant for enabling high-order CFD on multi-vendor heterogeneous supercomputers. The open-source release, MMS verification, cross-architecture TGV agreement, and the demonstrated 67.1B-DOF run with quantified efficiency and energy metrics provide concrete evidence of correctness and performance portability that directly supports the central architecture-agnostic claim.
minor comments (2)
- The TGV results are described as showing 'excellent agreement' with references; adding quantitative error norms or L2-error tables (e.g., in §4 or a dedicated results subsection) would allow readers to assess the precise level of match across architectures.
- The node-to-node speedup and energy comparisons (7.75–8.08×, <½ energy) would benefit from explicit specification of the CPU baseline hardware and compiler flags to ensure reproducibility of the performance claims.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its significance for multi-vendor GPU CFD, and recommendation to accept. No major comments were raised, so we have no points requiring response or revision.
Circularity Check
No significant circularity
full rationale
This is an implementation and benchmarking paper for the GALÆXI DGSEM framework. It verifies the method via the method of manufactured solutions (standard external check) and reports agreement with independent reference solutions for Taylor-Green-Vortex and airfoil cases. Scaling, performance, and energy results are direct measurements on hardware, not derived predictions. No equations, fitted parameters, or uniqueness claims reduce to self-inputs or self-citations by construction. The architecture-agnostic claim rests on cross-vendor numerical agreement rather than unanchored assertion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-14-01
TOP500 - November 2025, https://www.top500.org/lists/ top500/list/2025/11/, 2025. Accessed: 2026-14-01
2025
-
[2]
Accessed: 2026-14-01
TOP500 - November 2020, https://www.top500.org/lists/ top500/list/2020/11/, 2020. Accessed: 2026-14-01
2020
-
[3]
Gasparino, F
L. Gasparino, F. Spiga, O. Lehmkuhl, SOD2D: A GPU-enabled spectral finite elements method for compressible scale-resolving simulations, Computer Physics Communications 297 (2024) 109067
2024
-
[4]
F. D. Witherden, P. E. Vincent, W. Trojak, Y. Abe, A. Ak- barzadeh, S. Akkurt, M. Alhawwary, L. Caros, T. Dzanic, G. Giangaspero, et al., PyFR v2.0.3: Towards industrial adop- tion of scale-resolving simulations, Computer Physics Commu- nications 311 (2025) 109567
2025
-
[5]
Eleftherakis, G
P.-E. Eleftherakis, G. Anagnostopoulos, A. Kapetanakis, M. Umair, J.-Y. Vet, K. Iliakis, J. Vincent, J. Gong, R. Vin- uesa, S. Xydis, POSTER: Performance Portability in GPU- Accelerated Spectral Finite Element Fluid Simulations: A Cross-layer Exploration Approach, in: Proceedings of the 22nd ACM International Conference on Computing Frontiers, 2025, pp. 228–229
2025
-
[6]
T. Dzanic, F. Witherden, Positivity-preserving entropy-based adaptive filtering for discontinuous spectral element methods, Journal of Computational Physics 468 (2022) 111501. doi: https: //doi.org/10.1016/j.jcp.2022.111501
-
[7]
makotemplates.org/, 2026
Mako, Mako Templates for Python, https://www. makotemplates.org/, 2026. Accessed: 2026-23-04
2026
-
[8]
Industrial LES
K. Fujii, S. Kawai, D. Gaitonde, Scale Resolving Methods for Aeronautical Flows toward the Era of “Industrial LES”, Flow, Turbulence and Combustion 115 (2025) 405–446
2025
-
[9]
A. Ceci, A. Palumbo, S. Pirozzoli, Grid resolution requirements for dns of shock/boundary-layer interactions, Computers & Flu- ids (2025) 106892
2025
-
[10]
J. Zeifang, A. Beck, A data-driven high order sub-cell artifi- cial viscosity for the discontinuous Galerkin spectral element method, Journal of Computational Physics 441 (2021) 110475. doi:10.1016/j.jcp.2021.110475
-
[11]
Herten, Many Cores, Many Models: GPU Programming Model vs
A. Herten, Many Cores, Many Models: GPU Programming Model vs. Vendor Compatibility Overview, in: Proceedings of the SC ’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, SC- W ’23, Association for Computing Machinery, 2023, pp. 1019–
2023
-
[12]
doi: 10.1145/3624062.3624178
-
[13]
Fischer, J
P. Fischer, J. Lottes, H. Tufo, Nek5000, Technical Report, Ar- gonne National Lab, Argonne, IL (United States), 2007
2007
-
[14]
De Vanna, F
F. De Vanna, F. A vanzi, M. Cogo, S. Sandrin, M. Bettencourt, F. Picano, E. Benini, URANOS: A GPU accelerated Navier- Stokes solver for compressible wall-bounded flows, Computer Physics Communications 287 (2023) 108717
2023
-
[15]
Jansson, M
N. Jansson, M. Karp, A. Podobas, S. Markidis, P. Schlatter, Neko: A modern, portable, and scalable framework for high- fidelity computational fluid dynamics, Computers & Fluids (2024) 106243
2024
-
[16]
Krais, A
N. Krais, A. Beck, T. Bolemann, H. Frank, D. Flad, G. Gassner, F. Hindenlang, M. Hoffmann, T. Kuhn, M. Sonntag, C.-D. Munz, FLEXI: A high order discontinuous Galerkin frame- work for hyperbolic–parabolic conservation laws, Computers & Mathematics with Applications 81 (2021) 186–219
2021
-
[17]
Rubio, HORSES3D: a high-order discontinuous Galerkin solver for flow simulations and multi-physics applications, arXiv (Cornell University) (2022)
G. Rubio, HORSES3D: a high-order discontinuous Galerkin solver for flow simulations and multi-physics applications, arXiv (Cornell University) (2022)
2022
-
[18]
Fischer, S
P. Fischer, S. Kerkemeier, M. Min, Y.-H. Lan, M. Phillips, T. Rathnayake, E. Merzari, A. Tomboulides, A. Karakus, N. Chalmers, et al., NekRS, a GPU-accelerated spectral element Navier–Stokes solver, Parallel Computing 114 (2022) 102982
2022
-
[19]
Accessed: 2026-11-03
NVIDIA, CUDA Toolkit, https://developer.nvidia.com/ cuda-toolkit, 2026. Accessed: 2026-11-03
2026
-
[20]
Accessed: 2026-11-03
Advanced Micro Devices, HIP, https://rocm.docs.amd.com/ projects/HIP/en/latest/, 2026. Accessed: 2026-11-03
2026
-
[21]
M. Blind, M. Gao, D. Kempf, P. Kopper, M. Kurz, A. Schwarz, A. Beck, Towards Exascale CFD Simulations Using the Discon- tinuous Galerkin Solver FLEXI, Springer Nature Switzerland, 2026, pp. 207–221. doi: 10.1007/978-3-031-91312-9_15
-
[22]
M. Kurz, D. Kempf, M. Blind, P. Kopper, P. Offenhäuser, A. Schwarz, S. Starr, J. Keim, A. Beck, GALÆXI: Solving com- plex compressible flows with high-order discontinuous Galerkin methods on accelerator-based systems, Computer Physics Com- munications 306 (2024). doi: 10.1016/j.cpc.2024.109388
-
[23]
Sonntag, C.-D
M. Sonntag, C.-D. Munz, Shock capturing for discontinuous Galerkin methods using finite volume subcells, in: Finite Vol- umes for Complex Applications VII-Elliptic, Parabolic and Hy- perbolic Problems: FVCA 7, Berlin, June 2014, Springer, 2014, pp. 945–953
2014
-
[24]
A. D. Beck, T. Bolemann, D. Flad, H. Frank, G. J. Gassner, F. Hindenlang, C.-D. Munz, High-order discontinuous Galerkin spectral element methods for transitional and turbulent flow simulations, International Journal for Numerical Methods in Fluids 76 (2014) 522–548
2014
-
[25]
J. Keim, A. Schwarz, P. Kopper, M. Blind, C. Rohde, A. Beck, Entropy Stable High-Order Discontinuous Galerkin Spectral- Element Methods on Curvilinear, Hybrid Meshes, Journal of Computational Physics 557 (2026) 114829. doi: 10.1016/j.jcp. 2026.114829
-
[26]
P. Mossier, P. Oestringer, S. Jöns, J. Keim, C. Mavriplis, A. D. Beck, C.-D. Munz, Tackling Compressible Turbulent Multi- Component Flows with Dynamic Hp-Adaptation 306 (2026) 106928. doi: 10.1016/j.compfluid.2025.106928
-
[27]
Accessed: 2026-26- 02
OpenMP, https://www.openmp.org/, 2026. Accessed: 2026-26- 02
2026
-
[28]
Accessed: 2026- 26-02
OpenACC, https://www.openacc.org/, 2026. Accessed: 2026- 26-02
2026
-
[29]
C. R. Trott, D. Lebrun-Grandié, D. Arndt, J. Ciesko, V. Dang, N. Ellingwood, R. Gayatri, E. Harvey, D. S. Hollman, D. Ibanez, N. Liber, J. Madsen, J. Miles, D. Poliakoff, A. Powell, S. Raja- manickam, M. Simberg, D. Sunderland, B. Turcksin, J. Wilke, Kokkos 3: Programming Model Extensions for the Exascale Era, IEEE Transactions on Parallel and Distributed...
-
[30]
Lawrence Livermore National Laboratory, RAJA Portabil- ity Suite: Enabling Performance Portable CPU and GPU HPC Applications, https://computing.llnl.gov/projects/ raja-managing-application-portability-next-generation\ protect\penalty\z@-platforms, 2026
2026
-
[31]
Zenker, B
E. Zenker, B. Worpitz, R. Widera, A. Huebl, G. Juckeland, A. Knüpfer, W. E. Nagel, M. Bussmann, Alpaka – An Ab- straction Library for Parallel Kernel Acceleration, in: 2016 IEEE International Parallel and Distributed Processing Sym- posium Workshops (IPDPSW), 2016, pp. 631–640. doi: 10.1109/ IPDPSW.2016.50
2016
-
[32]
Accessed: 2026-11-03
Khronos Group, SYCL, https://www.khronos.org/sycl/, 2026. Accessed: 2026-11-03
2026
-
[33]
Accessed: 2026-26-02
NVIDIA, CUDA Fortran, https://developer.nvidia.com/ cuda-fortran, 2026. Accessed: 2026-26-02
2026
-
[34]
Accessed: 2026-15-04
Fortran Community, Fortran: High-performance parallel pro- gramming language, https://fortran-lang.org/, 2026. Accessed: 2026-15-04
2026
-
[35]
S. Bak, C. Bertoni, S. Boehm, R. Budiardja, B. M. Chap- man, J. Doerfert, M. Eisenbach, H. Finkel, O. Hernandez, J. Huber, S. Iwasaki, V. Kale, P. R. Kent, J. Kwack, M. Lin, P. Luszczek, Y. Luo, B. Pham, S. Pophale, K. Ravikumar, V. Sarkar, T. Scogland, S. Tian, P. Yeung, OpenMP application experiences: Porting to accelerated nodes, Parallel Computing 18 ...
-
[36]
Bernardini, D
M. Bernardini, D. Modesti, F. Salvadore, S. Pirozzoli, STREAmS: A high-fidelity accelerated solver for direct nu- merical simulation of compressible turbulent flows, Computer Physics Communications 263 (2021) 107906
2021
-
[37]
Salvadore, G
F. Salvadore, G. Rossi, S. Sathyanarayana, M. Bernardini, OpenMP offload toward the exascale using Intel® GPU Max 1550: evaluation of STREAmS compressible solver, The Jour- nal of Supercomputing 80 (2024) 21094–127
2024
-
[38]
De Vanna, G
F. De Vanna, G. Baldan, URANOS-2.0: Improved performance, enhanced portability, and model extension towards exascale computing of high-speed engineering flows, Computer Physics Communications 303 (2024) 109285
2024
-
[39]
Solanki, AdaptiveCpp design and architecture, https://github.com/AdaptiveCpp/AdaptiveCpp/blob/ develop/doc/architecture.md, 2025
M. Solanki, AdaptiveCpp design and architecture, https://github.com/AdaptiveCpp/AdaptiveCpp/blob/ develop/doc/architecture.md, 2025. Accessed: 2026-09-03
2025
- [40]
-
[41]
P. Bauman, B. Messer, J. Glenski, A. Georgiadou, J. Li- etz, K. Gottiparthi, M. Day, J. Chen, J. Rood, L. Esclapez, J. White III, G. R. Jansen, N. Curtis, S. Nichols, J. Kurzak, N. Chalmers, C. Freitag, N. Malaya, A. Fanfarillo, R. D. Bu- diardja, T. Papatheodore, N. Frontiere, D. Mcdougall, M. Nor- man, S. Sreepathi, P. Roth, D. Bykov, N. Wolfe, P. Mullo...
-
[42]
G. Nastac, A. Walden, E. J. Nielsen, K. Frendi, Implicit Thermochemical Nonequilibrium Flow Simulations on Unstruc- tured Grids using GPUs, in: AIAA Scitech 2021 Forum, 2021. doi:10.2514/6.2021-0159
-
[43]
Jansson, M
N. Jansson, M. Karp, J. Wahlgren, S. Markidis, P. Schlatter, Design of Neko—A Scalable High-Fidelity Simulation Frame- work With Extensive Accelerator Support, Concurrency and Computation: Practice and Experience 37 (2025)
2025
-
[44]
W. K. Anderson, R. T. Biedron, J.-R. Carlson, J. M. Derlaga, B. Diskin, C. T. Druyor Jr., et al, FUN3D Manual: 14.2, 2025
2025
-
[45]
Nastac, A
G. Nastac, A. Walden, L. Wang, E. J. Nielsen, Y. Liu, M. Opgenorth, J. Orender, M. Zubair, A Multi-Architecture Approach for Implicit Computational Fluid Dynamics on Un- structured Grids, in: AIAA Scitech 2023 Forum, 2023. doi: 10. 2514/6.2023-1226
2023
-
[46]
A. Harten, J. M. Hyman, Self Adjusting Grid Methods for One- Dimensional Hyperbolic Conservation Laws, Journal of Compu- tational Physics 50 (1983) 235–269. doi: 10.1016/0021-9991(83) 90066-9
-
[47]
F. Bassi, S. Rebay, A High-Order Accurate Discontinuous Finite Element Method for the Numerical Solution of the Compressible Navier-Stokes Equations, Journal of Computational Physics 131 (1997) 267–279. doi: 10.1006/jcph.1996.5572
-
[48]
P. Chandrashekar, Kinetic Energy Preserving and Entropy Sta- ble Finite Volume Schemes for Compressible Euler and Navier- Stokes Equations, Communications in Computational Physics 14 (2013) 1252–1286. doi: 10.4208/cicp.170712.010313a
-
[49]
Sonntag, Shape Derivatives and Shock Capturing for the Navier-Stokes Equations in Discontinuous Galerkin Meth- ods, Ph.D
M. Sonntag, Shape Derivatives and Shock Capturing for the Navier-Stokes Equations in Discontinuous Galerkin Meth- ods, Ph.D. thesis, Universität Stuttgart, 2017. doi: 10.18419/ opus-9342
2017
-
[50]
P.-O. Persson, J. Peraire, Sub-Cell Shock Capturing for Discon- tinuous Galerkin Methods, 2006. doi: 10.2514/6.2006-112
-
[51]
M. H. Carpenter, A. Kennedy, Fourth-Order 2N-Storage Runge- Kutta Schemes, Nasa Technical Memorandum 109112 (1994) 1–26
1994
-
[52]
Niegemann, R
J. Niegemann, R. Diehl, K. Busch, Efficient Low-Storage Runge–Kutta Schemes with Optimized Stability Regions, Jour- nal of Computational Physics 231 (2012) 364–372. doi: 10.1016/ j.jcp.2011.09.003
2012
-
[53]
A. Schwarz, D. Kempf, J. Keim, P. Kopper, C. Rohde, A. Beck, Comparison of Entropy Stable Collocation High-Order DG Methods for Compressible Turbulent Flows, Computers & Flu- ids 303 (2025) 106874. doi: 10.1016/j.compfluid.2025.106874
-
[54]
Reid, The new features of Fortran 2003 26 (2007) 10–33
J. Reid, The new features of Fortran 2003 26 (2007) 10–33. doi:10.1145/1243413.1243415
-
[55]
Klöckner, T
A. Klöckner, T. Warburton, J. Bridge, J. Hesthaven, Nodal discontinuous Galerkin methods on graphics processors, Journal of Computational Physics 228 (2009) 7863–7882. doi: j.jcp.2009. 06.041
2009
-
[56]
J. Chan, Z. Wang, A. Modave, J.-F. Remacle, T. Warbur- ton, GPU-accelerated discontinuous Galerkin methods on hy- brid meshes, Journal of Computational Physics 318 (2016) 142–
2016
-
[57]
doi: https://doi.org/10.1016/j.jcp.2016.04.003
-
[58]
A. Karakus, N. Chalmers, K. Świrydowicz, T. Warburton, A GPU accelerated discontinuous Galerkin incompressible flow solver, Journal of Computational Physics 390 (2019) 380–404. doi:https://doi.org/10.1016/j.jcp.2019.04.010
-
[59]
Accessed: 2026-03-03
NVIDIA, Nsight Compute™, https://developer.nvidia.com/ nsight-compute, 2026. Accessed: 2026-03-03
2026
-
[60]
D. A. Kopriva, A conservative staggered-grid chebyshev mul- tidomain method for compressible flows. ii. a semi-structured method, Journal of computational physics 128 (1996) 475–488
1996
-
[61]
P. J. Roache, Code verification by the method of manufactured solutions, J. Fluids Eng. 124 (2002) 4–10
2002
-
[62]
D. J. Lusher, N. D. Sandham, Assessment of low-dissipative shock-capturing schemes for the compressible Taylor–Green vor- tex, AIAA Journal 59 (2021) 533–545
2021
-
[63]
Sarkar, G
S. Sarkar, G. Erlebacher, M. Y. Hussaini, H. O. Kreiss, The analysis and modelling of dilatational terms in compressible tur- bulence, Journal of Fluid Mechanics 227 (1991) 473–493
1991
-
[64]
Sutherland, LII
W. Sutherland, LII. The viscosity of gases and molecular force, The London, Edinburgh, and Dublin Philosophical Mag- azine and Journal of Science 36 (1893) 507–531. doi: 10.1080/ 14786449308620508
-
[65]
bg/index.html, 2026
Discoverer HPC, Discoverer HPC docs, https://docs.discoverer. bg/index.html, 2026. Accessed: 2026-19-02
2026
-
[66]
Accessed: 2026-19-02
Höchstleistungsrechenzentrum Stuttgart (HLRS), Hunter (HPE), https://kb.hlrs.de/platforms/index.php/Hunter_ (HPE), 2026. Accessed: 2026-19-02
2026
-
[67]
Accessed: 2026-19-02
CINECA HPC, Leonardo, https://www.hpc.cineca.it/systems/ hardware/leonardo/, 2026. Accessed: 2026-19-02
2026
-
[68]
Accessed: 2026-19-02
Minho Advanced Computing Center (MACC), Deucalion User Guide, https://docs.macc.fccn.pt/, 2026. Accessed: 2026-19-02
2026
-
[69]
Accessed: 2026-10- 04
Oak Ridge National Laboratory (ORNL) Leadership Comput- ing Facility, Frontier User Guide, https://docs.olcf.ornl.gov/ systems/frontier_user_guide.html, 2026. Accessed: 2026-10- 04
2026
-
[70]
Ac- cessed: 2026-12-03
Jülich Supercomputing Centre (JSC), JUPITER - Exascale for Europe, https://www.fz-juelich.de/en/jsc/jupiter, 2026. Ac- cessed: 2026-12-03
2026
-
[71]
Accessed: 2026-19-02
IT4Innovations, Karolina, https://www.it4i.cz/en/ infrastructure/karolina, 2026. Accessed: 2026-19-02
2026
-
[72]
Accessed: 2026- 19-02
CSC - IT Center for Science, LUMI Documentation, https:// docs.lumi-supercomputer.eu/firststeps/, 2026. Accessed: 2026- 19-02
2026
-
[73]
Accessed: 2026-19-02
Barcelona Supercomputing Center (BSC), MareNostrum 5 Technical information, https://www.bsc.es/marenostrum/ marenostrum-5, 2026. Accessed: 2026-19-02
2026
-
[74]
LuxProvide, MeluXina, https://www.luxprovide.lu/meluxina/,
-
[75]
Accessed: 2026-19-02
2026
-
[76]
Accessed: 2026-19-02
Institute for Information Science, Maribor (IZUM), Vega, https: //izum.si/en/vega-en/, 2026. Accessed: 2026-19-02
2026
-
[77]
Advanced Micro Devices, AMD Instinct ™ MI250X Ac- celerators, https://www.amd.com/en/products/accelerators/ instinct/mi200/mi250x.html, 2026
2026
-
[78]
com/, 2026
SchedMD, Slurm Workload Manager, https://slurm.schedmd. com/, 2026. Accessed: 2026-27-01
2026
-
[79]
Accessed: 2026-27-01
Barcelona Supercomputing Center (BSC), EAR: Energy management framework for HPC, https://www.bsc.es/ 19 research-and-development/software-and-apps/software-list/ ear-energy-management-framework-hpc , 2026. Accessed: 2026-27-01
2026
-
[80]
P. Kopper, M. P. Blind, A. Schwarz, M. Kurz, F. Rodach, S. M. Copplestone, A. D. Beck, PyHOPE: A Python Toolkit for Three-Dimensional Unstructured High-Order Meshes, Jour- nal of Open Source Software 10 (2025) 8769. URL: https: //doi.org/10.21105/joss.08769. doi: 10.21105/joss.08769
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.