Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity
Pith reviewed 2026-06-29 14:01 UTC · model grok-4.3
The pith
Adding exponentially decaying memory to attention improves accuracy of query-aware sparse KV methods on needle retrieval tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
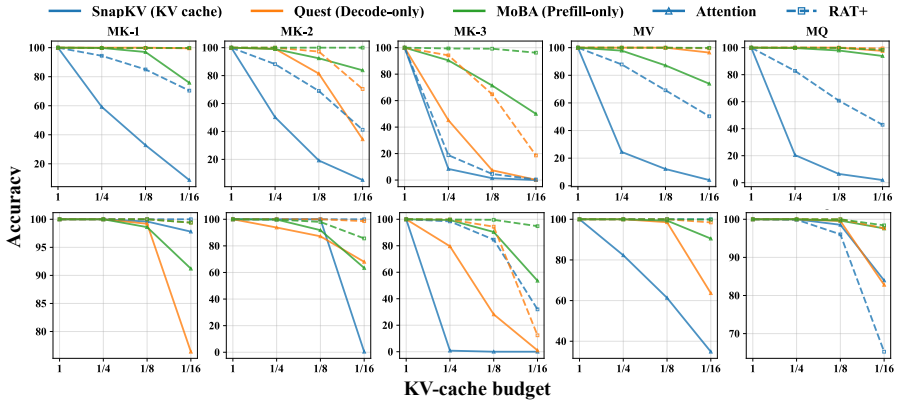
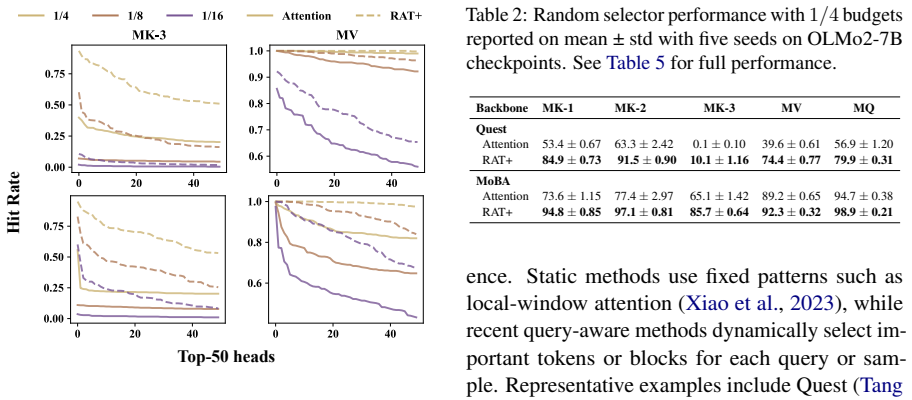
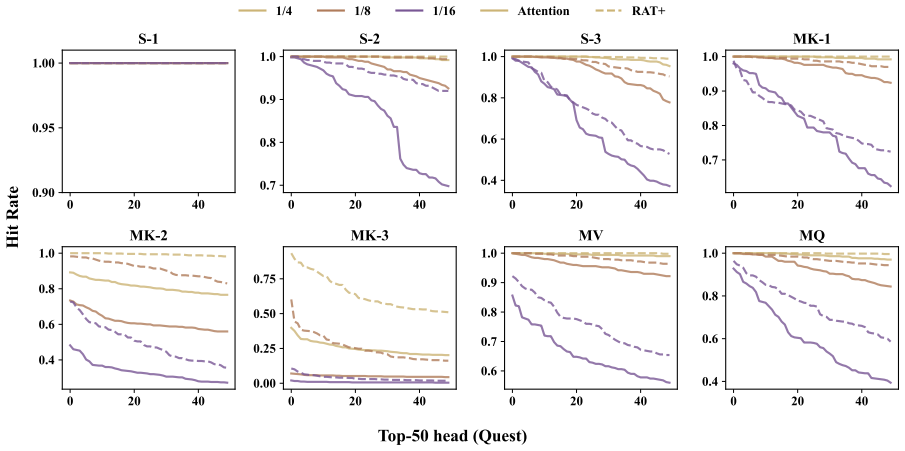
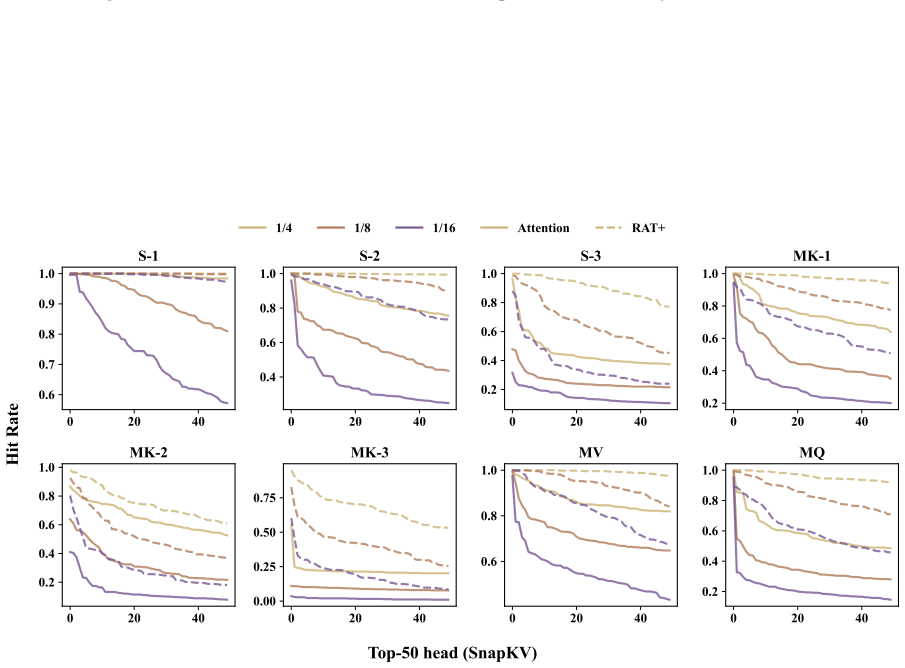
Augmenting attention with the exponentially decaying memory from the RAT+ recurrence-augmented backbone consistently raises accuracy over plain attention when combined with query-aware sparse inference methods including Quest, MoBA, and SnapKV, on eight needle-in-a-haystack tasks and across a range of sparse budgets; the improvement is observed both on released checkpoints and on OLMo2-7B after 10B tokens of continued pretraining with the memory module.
What carries the argument
The exponentially decaying memory module from RAT+, which supplies recurrence-augmented context to the attention computation and can be attached to existing sparse KV selection routines at inference time.
If this is right
- Query-aware sparse methods paired with the memory module outperform the same methods without it on long-context retrieval.
- The benefit appears across representative sparse techniques and multiple sparse budget levels.
- The improvement is reproducible both on published checkpoints and after targeted continued pretraining.
- Two hypotheses are offered and supported by targeted experiments to explain the benefit to query-aware sparsity.
Where Pith is reading between the lines
- The memory module might be attachable to additional sparse selection algorithms not tested in the paper.
- It could allow smaller sparse budgets to reach the same accuracy as larger ones without the memory.
- The approach may generalize to other long-context efficiency techniques that rely on selective KV access.
Load-bearing premise
The observed accuracy gains arise from the exponentially decaying memory itself rather than from incidental changes in how the sparse selector is coded or how the continued pretraining is run.
What would settle it
Re-implementing the same sparse methods with and without the memory module while keeping every other detail identical and finding no accuracy difference on the needle tasks would falsify the claim.
Figures
read the original abstract
Efficient inference is critical for long-context language models, where attention computation and KV-cache access dominate the cost. Recent work RAT+, introduces a recurrence-augmented attention backbone that enables flexible dilated attention at inference time. In this paper, we investigate whether this exponentially decaying memory can also improve existing query-aware sparse inference methods. Using representative methods including Quest, MoBA, and SnapKV, we show that RAT+ consistently improves accuracy over standard attention across sparse budgets on eight needle-in-a-haystack tasks. We validate these gains both on the released checkpoints from the RAT+ paper and on OLMo2-7B, which we continue pretraining with the added memory module for 10B tokens. Finally, we propose two hypotheses explaining why this memory module benefits query-aware sparse inference and design targeted experiments to support them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that augmenting standard attention with an exponentially decaying memory module (RAT+) improves accuracy of query-aware KV-sparse methods (Quest, MoBA, SnapKV) on eight needle-in-a-haystack tasks. Gains are shown both on released RAT+ checkpoints and on OLMo2-7B models that receive 10B tokens of continued pretraining with the module added; two hypotheses are proposed and tested to explain the benefit.
Significance. If the reported accuracy lifts are caused by the memory module rather than training or implementation differences, the result indicates that recurrence with exponential decay can be productively combined with existing sparse-selection algorithms, providing a practical route to better accuracy-efficiency trade-offs in long-context inference. The dual validation on released checkpoints and new training is a positive feature; the absence of matched continued-pretraining baselines and statistical reporting limits the strength of the causal claim.
major comments (2)
- [Section 4.2] Experiments with OLMo2-7B (Section 4.2): the manuscript states that the RAT+ variant receives 10B tokens of continued pretraining but does not report a control OLMo2-7B run that receives identical continued pretraining (same data, optimizer, steps) without the memory module. This directly affects attribution of the observed gains to the exponentially decaying memory.
- [Section 4.1] Results on released checkpoints (Section 4.1): while the released-checkpoint experiments avoid the continued-pretraining confound, the paper does not state that the sparse-selection implementations (Quest/MoBA/SnapKV) were held exactly constant between the RAT+ and standard-attention variants; any incidental difference in selection logic would undermine the claim that the memory module is responsible for the lift.
minor comments (2)
- [Section 4] No error bars, standard deviations across runs, or statistical significance tests are reported for the accuracy differences on the eight tasks.
- [Section 5] The two hypotheses are introduced in the abstract and conclusion but the targeted experiments that support them are not clearly cross-referenced to specific figures or tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental controls and attribution. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 4.2] Experiments with OLMo2-7B (Section 4.2): the manuscript states that the RAT+ variant receives 10B tokens of continued pretraining but does not report a control OLMo2-7B run that receives identical continued pretraining (same data, optimizer, steps) without the memory module. This directly affects attribution of the observed gains to the exponentially decaying memory.
Authors: We agree that a matched control run without the memory module would strengthen causal attribution of the gains to RAT+. The released-checkpoint experiments in Section 4.1 avoid this confound entirely. We will revise the manuscript to explicitly acknowledge this limitation in the OLMo2-7B results and discuss its implications for interpreting those specific gains. revision: partial
-
Referee: [Section 4.1] Results on released checkpoints (Section 4.1): while the released-checkpoint experiments avoid the continued-pretraining confound, the paper does not state that the sparse-selection implementations (Quest/MoBA/SnapKV) were held exactly constant between the RAT+ and standard-attention variants; any incidental difference in selection logic would undermine the claim that the memory module is responsible for the lift.
Authors: The sparse-selection implementations were held exactly constant: the same code, hyperparameters, and selection logic for Quest, MoBA, and SnapKV were applied to both RAT+ and standard-attention variants. We will add an explicit clarifying statement in Section 4.1 of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical comparisons on external tasks
full rationale
The paper reports accuracy improvements from augmenting existing sparse attention methods (Quest, MoBA, SnapKV) with the RAT+ exponentially decaying memory module, evaluated on eight needle-in-a-haystack tasks using both released checkpoints and continued pretraining on OLMo2-7B. No equations, derivations, or fitted parameters are presented that reduce the reported gains to inputs defined inside the paper; the central claim rests on direct empirical comparisons against external baselines and standard tasks rather than any self-referential construction. Self-citation of the prior RAT+ work is present but not load-bearing for any uniqueness theorem or ansatz that would force the result. Potential confounds such as unmatched continued pretraining are validity issues outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-xl: Attentive language mod- els beyond a fixed-length context. arXiv preprint arXiv:1901.02860. Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. 2024. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference. arXiv preprint arXiv:2407.11550. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shan- ta...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[2]
It partitions the KV cache into blocks and maintains lightweight block-level representatives constructed from the dimension- wise minimum and maximum key values
is a KV-block selection method for decoding- time sparse attention. It partitions the KV cache into blocks and maintains lightweight block-level representatives constructed from the dimension- wise minimum and maximum key values. During decoding, each new query first interacts with these representatives to identify the most relevant top-k blocks, and atte...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.