Knowledge Offloading: Decomposing LLMs into Sparse Backbones and Memory Modules
Pith reviewed 2026-06-29 13:44 UTC · model grok-4.3
The pith
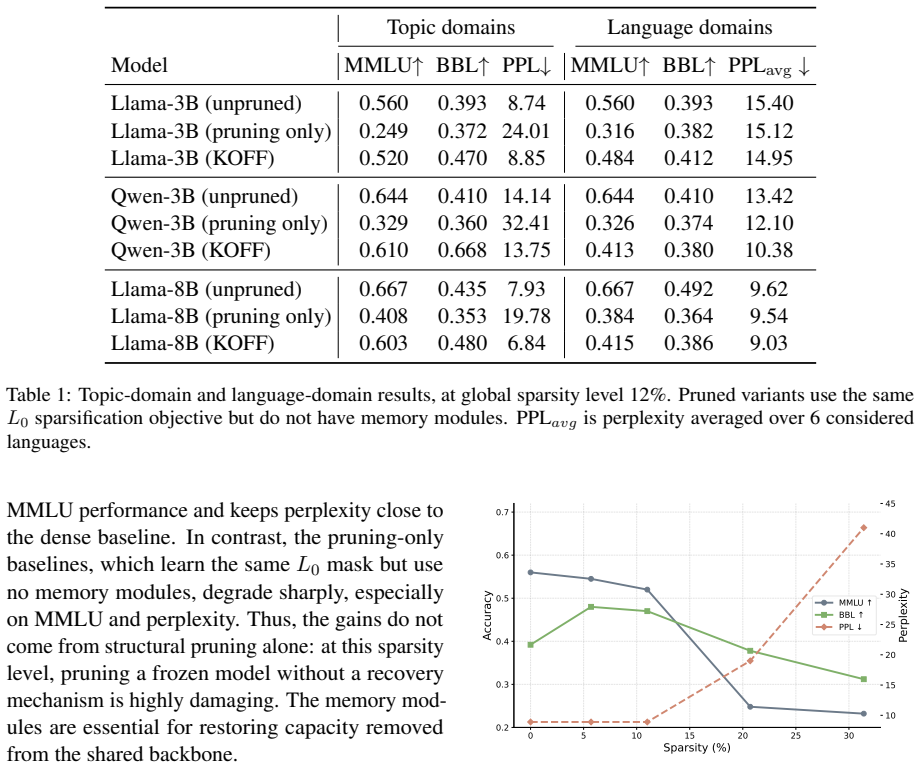
LLMs can be decomposed into a sparse shared backbone and domain-specific memory modules while retaining most performance at 12 percent global sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
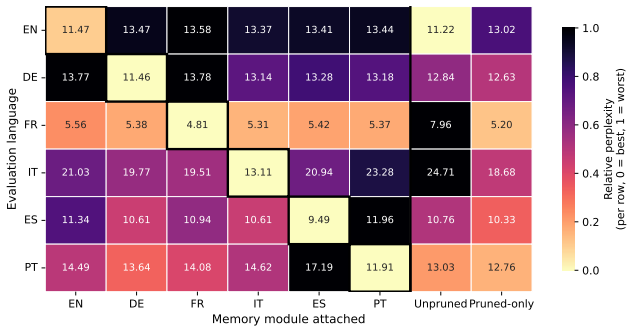
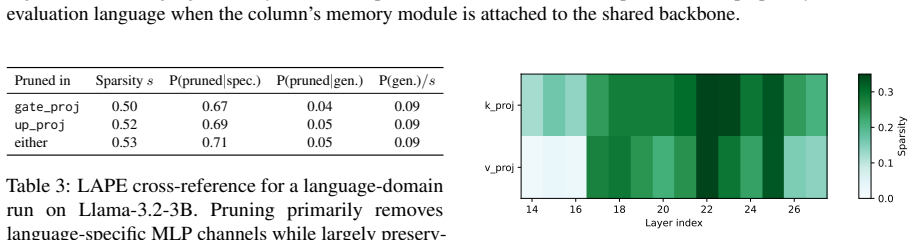
Starting from a frozen base model, jointly learning a structured pruning mask together with LoRA adapters and learned key-value caches moves non-trivial capacity out of the shared backbone without large loss in model ability, while the same pruning without the memory modules degrades performance sharply; the resulting decomposition also shows specialization, with language-specific neurons preferentially removed.
What carries the argument
Knowledge offloading (KOFF) framework that jointly optimizes a structured pruning mask with LoRA adapters and learned key-value caches to separate general computation from domain-specific knowledge.
If this is right
- Non-trivial capacity can be moved out of the shared backbone without a large loss in model ability.
- LoRA adapters and learned KV caches are complementary recovery mechanisms.
- The learned decomposition is meaningful because language-specific neurons are preferentially removed while language-general neurons largely remain.
- Specialized knowledge can be reallocated into swappable external memories attached to a shared core.
Where Pith is reading between the lines
- Different memory modules could be swapped at inference time to adapt the same backbone to new domains without retraining the core weights.
- The approach might reduce the cost of maintaining multiple specialized models by keeping only one sparse backbone and exchanging small memory sets.
- If the separation holds across more tasks, it could support incremental addition of new knowledge without risking interference with the backbone's general abilities.
Load-bearing premise
That jointly learning a structured pruning mask together with lightweight recovery modules can reliably move domain-specific knowledge out of the shared backbone while retaining general capabilities.
What would settle it
A direct comparison in which the frozen model pruned to 12 percent sparsity without any LoRA or KV recovery modules performs as well as the version that includes them would show the offloading components are not necessary.
Figures

read the original abstract
LLMs encode both general capabilities and domain-specific knowledge in a single set of parameters. We ask whether this capacity can be reorganized: keeping broadly useful computation in a shared backbone, while moving specialized knowledge into external memory modules. We propose \emph{knowledge offloading} (KOFF), a framework for decomposing a pretrained LLM into a sparse shared backbone and domain-specific memories. Starting from a frozen base model, we jointly learn a structured pruning mask and lightweight recovery modules, implemented as LoRA adapters and learned key-value caches. Across Llama and Qwen models from 3B to 8B, we find that non-trivial capacity can be moved out of the shared backbone without a large loss in model ability. At around 12\% global sparsity, KOFF preserves much of the unpruned model's performance, while pruning the same frozen model without memories degrades sharply. Ablations show that LoRA and learned KV memories are complementary, and specialization analyses suggest that the learned decomposition is meaningful: language-specific neurons are preferentially removed while language-general neurons largely remain in the backbone. These results suggest that knowledge can be reallocated between a shared core and swappable external memories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Knowledge Offloading (KOFF), a framework that decomposes a frozen pretrained LLM into a sparse shared backbone and domain-specific memory modules by jointly learning a structured pruning mask together with lightweight recovery modules implemented as LoRA adapters and learned key-value caches. Experiments across Llama and Qwen models (3B–8B) report that at approximately 12% global sparsity the approach largely preserves unpruned performance, whereas standard pruning of the frozen model without memories causes sharp degradation. Ablations indicate that LoRA and KV-cache memories are complementary, and neuron-level analyses suggest the learned mask preferentially removes language-specific neurons while retaining language-general ones.
Significance. If the empirical outcomes are robust, the work demonstrates a practical route to reorganizing LLM capacity so that general capabilities remain in a compact shared backbone while domain knowledge is isolated in external modules. The joint mask-plus-recovery training and the post-hoc specialization analysis constitute concrete evidence that non-trivial capacity can be moved without catastrophic loss, which could inform future modular and memory-augmented architectures.
major comments (2)
- [Abstract] Abstract and results: the central claim that the learned memories are 'swappable' and enable true knowledge offloading is not directly tested; the manuscript reports no experiments that take a backbone trained with one set of domain memories and pair it with memory modules trained on a different domain or task.
- [Results] Methods and results sections: the performance preservation at ~12% sparsity is stated without error bars, standard deviations across runs, exact training hyperparameters, dataset splits, or full ablation tables, which are required to assess whether the joint-training outcome is statistically reliable and reproducible.
minor comments (1)
- [Abstract] The abstract would benefit from a single quantitative table or figure reference summarizing the main sparsity-versus-performance numbers for both KOFF and the baseline pruning condition.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential significance of reorganizing LLM capacity via knowledge offloading. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the central claim that the learned memories are 'swappable' and enable true knowledge offloading is not directly tested; the manuscript reports no experiments that take a backbone trained with one set of domain memories and pair it with memory modules trained on a different domain or task.
Authors: We agree that the manuscript does not include direct experiments that swap memory modules across different domains or tasks. Our experiments instead demonstrate that joint training of a structured pruning mask with LoRA and KV-cache modules allows a sparse backbone to retain performance on the original distribution while offloading recovery to external modules. The phrasing 'swappable external memories' in the abstract is intended to describe the modular, external nature of the added components rather than to assert empirical results on arbitrary cross-domain pairing. We will revise the abstract and discussion sections to qualify this language and explicitly note the absence of cross-domain swapping experiments as a direction for future work. revision: partial
-
Referee: [Results] Methods and results sections: the performance preservation at ~12% sparsity is stated without error bars, standard deviations across runs, exact training hyperparameters, dataset splits, or full ablation tables, which are required to assess whether the joint-training outcome is statistically reliable and reproducible.
Authors: We acknowledge that the current manuscript lacks these details, which are necessary for evaluating statistical reliability and reproducibility. In the revised version we will add error bars and standard deviations computed over multiple independent runs, report the precise training hyperparameters and dataset splits, and include expanded ablation tables covering all configurations examined. revision: yes
Circularity Check
No circularity; purely empirical results from joint training
full rationale
The paper describes an empirical procedure of jointly training a structured pruning mask together with LoRA adapters and learned KV caches on frozen base models, then reporting performance numbers at ~12% sparsity. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on experimental outcomes rather than any reduction of a result to its own inputs by construction, so the derivation chain is empty and the work is self-contained as an observational study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Tennien, Atri Rudra, James Zou, Azalia Mirhoseini, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cartridges: Lightweight and general-purpose long context representations via self-study.arXiv preprint arXiv:2506.06266. Negar Foroutan, Mohammadreza Banaei, Rémi Lebret, Antoine Bosselut, and Karl Aberer. 2022. Discov- ering language-neutral sub-networks in multilingual language models. InProceedings of the 2022 Con- ference on Empirical Methods in Natur...
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Amr Hendy, Mohamed Abdelghaffar, Mohamed Afify, and Ahmed Y Tawfik. 2022. Domain specific sub- network for multi-domain neural machine translation. InProceedings of the 2nd Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics and the 12th I...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Learning Sparse Neural Networks through $L_0$ Regularization
Learning sparse neural networks through l0 regularization.Preprint, arXiv:1712.01312. Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. Llm-pruner: On the structural pruning of large lan- guage models.Preprint, arXiv:2305.11627. Hadi Pouransari, David Grangier, C Thomas, Michael Kirchhof, and Oncel Tuzel. 2025. Pretraining with hierarchical memories: separ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A random LoRA and KV-cache pair is in- serted into a model
-
[6]
A fresh mini-batch is drawn from a mix- ture of general-domain corpora: C4 (English, streamed), GSM8K (math reasoning), and ARC-Challenge (science reasoning). 11 Languagess ∗ Final Sparsity PPL (en)↓PPL (fr)↓PPL (es)↓PPL (avg)↓ en 0.2 0.150 17.8 – – 17.8 en, fr 0.1 0.071 19.7 9.8 – 14.8 en, fr, es 0.1 0.073 18.5 11.2 20.9 16.8 en, fr, es 0.2 0.146 20.3 11...
-
[7]
A standard language-modeling forward– backward pass is performed; gradients flow to the gate parameters and memory modules. This strategy exposes the gates to data that is distribution-shifted relative to the domain-specific training data, providing a regularizing signal that discourages pruning neurons whose removal would hurt broad language understandin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.