Quantum Subliminal Learning
Pith reviewed 2026-06-29 07:10 UTC · model grok-4.3
The pith
Quantum neural networks retain most hidden-task signals through public-task interfaces while classical networks transmit little.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
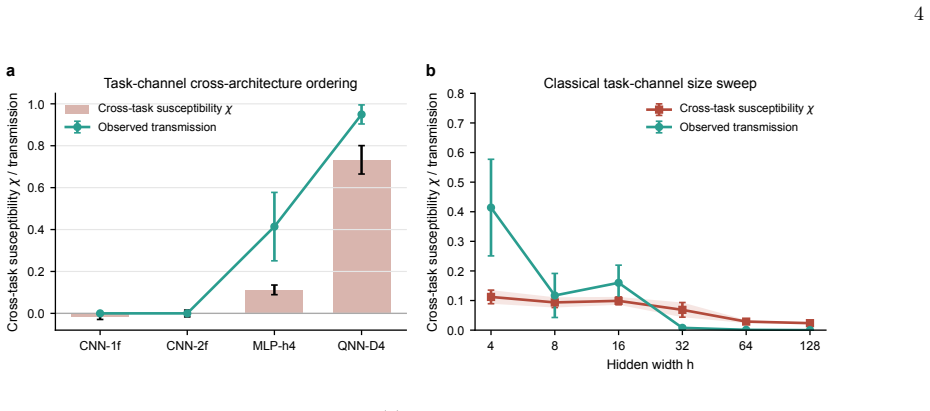
Both classical and quantum neural networks exhibit efficient subliminal learning through an auxiliary channel on random inputs, yet the restricted task channel displays strong architecture dependence: classical networks transmit little hidden-task information through the public-task interface whereas quantum neural networks retain most of the hidden-task signal. Transmission in both regimes is governed by a unified geometric picture in which the amount of hidden information that reaches the student is set by the magnitude of the teacher drift together with the fraction of that drift which remains visible once the public interface is imposed.
What carries the argument
The geometric drift picture, in which hidden-task transmission is set by teacher drift magnitude and the visible fraction of hidden-task-relevant drift through the public interface.
If this is right
- Quantum models can inherit hidden behavioral traits even when the student is trained exclusively on public supervised outputs.
- Classical models largely prevent such inheritance through the same public-task interface.
- The amount of transmitted hidden information scales with teacher drift magnitude and the visible fraction of hidden-relevant drift.
- The architecture dependence creates a concrete security concern for quantum model supply chains.
- The same mechanism offers a potential controlled route for hidden-information transfer in quantum information processing.
Where Pith is reading between the lines
- If the drift picture generalizes, hardware implementations of quantum models may need explicit visibility filters on public interfaces to limit unintended information leakage.
- The contrast between auxiliary and task channels suggests that random-input distillation may be a reliable way to move hidden quantum states even when task-specific training is restricted.
- Testing whether the same architecture split appears in variational quantum algorithms versus tensor-network classical models would clarify whether the effect is tied to quantum superposition or to the specific circuit structure used.
Load-bearing premise
The two distillation pathways studied are representative of realistic model-distillation scenarios and the geometric drift description holds without extra factors such as noise or architecture-specific regularization.
What would settle it
A measurement showing that quantum neural networks trained only on public-task labels lose nearly all hidden-task performance on the disjoint task, comparable to the loss seen in classical networks under identical conditions.
Figures

read the original abstract
Machine learning models can inherit hidden behavioral traits through innocuous public interfaces, a phenomenon known as subliminal learning. Here we extend this framework to quantum models and study two distillation pathways: an auxiliary channel on random inputs and a restricted task channel in which the student matches a public supervised output while the hidden behavior resides on a disjoint task. Both classical and quantum neural networks (QNNs) exhibit efficient auxiliary-channel subliminal learning, but the task channel shows strong architecture dependence. Classical neural networks transmit little hidden-task information through the public-task interface, whereas QNNs retain most of the hidden-task signal. We show that a unified geometric picture explains both regimes: transmission is controlled by the teacher drift magnitude together with the fraction of hidden-task-relevant drift that remains visible through the public interface. These results identify a concrete security concern for quantum model supply chains and suggest a controlled route for hidden-information transfer in quantum information processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends subliminal learning to quantum neural networks via two distillation pathways (auxiliary channel on random inputs; restricted task channel with disjoint hidden behavior). Both classical NNs and QNNs exhibit efficient auxiliary-channel transmission, but the restricted task channel reveals strong architecture dependence: classical networks transmit little hidden-task information while QNNs retain most of the signal. A unified geometric construction—teacher drift magnitude together with the fraction of hidden-task-relevant drift visible through the public interface—is offered to account for both regimes and to identify a security concern for quantum model supply chains.
Significance. If the geometric picture can be shown to be predictive (i.e., the visible-drift fraction computed independently of the measured transmission rates), the result would constitute a concrete, architecture-specific security finding for quantum ML supply chains and a controlled mechanism for hidden-information transfer. The explicit contrast between classical and quantum behavior under the same public interface is the load-bearing claim.
major comments (2)
- [geometric picture / results] The geometric picture (abstract and results section) asserts that transmission is controlled by teacher drift magnitude plus the visible fraction of hidden-task-relevant drift. If this fraction is extracted from the same output statistics used to quantify transmission rates rather than from an a-priori property of the public-task loss surface or model class, the construction is descriptive rather than predictive and cannot establish that the architecture dependence is explained rather than fitted post hoc.
- [methods / distillation pathways] The two distillation pathways are presented as representative, yet no quantitative justification is given that the restricted task channel (public supervised output, hidden behavior on disjoint task) captures realistic model-distillation scenarios without confounding factors such as regularization, measurement noise, or architecture-specific inductive biases.
minor comments (2)
- [abstract / introduction] Notation for the two drift parameters should be introduced with explicit definitions and units before the geometric picture is invoked.
- [figures] Figure captions should state the precise numerical values of teacher drift magnitude and visible fraction used in each panel.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below, clarifying the independence of the geometric construction and providing additional context on the distillation pathways. Revisions will be made to strengthen the predictive aspects and add discussion of the experimental design.
read point-by-point responses
-
Referee: [geometric picture / results] The geometric picture (abstract and results section) asserts that transmission is controlled by teacher drift magnitude plus the visible fraction of hidden-task-relevant drift. If this fraction is extracted from the same output statistics used to quantify transmission rates rather than from an a-priori property of the public-task loss surface or model class, the construction is descriptive rather than predictive and cannot establish that the architecture dependence is explained rather than fitted post hoc.
Authors: We thank the referee for this important clarification on predictive versus descriptive modeling. The visible fraction in our geometric construction is computed from the a-priori geometry of the public-task loss surface and the model class: specifically, the projection of the hidden-task drift vector onto the subspace spanned by the public-task gradients, which depends only on the architecture and the public interface definition. This quantity is obtained before any hidden-task transmission measurements are performed. The teacher drift magnitude is likewise measured on the public task. Transmission rates on the hidden task are then compared against the prediction from these two quantities. We will revise the results section to include an explicit, independent calculation of the visible fraction for each architecture and demonstrate its use in predicting the observed transmission rates. revision: yes
-
Referee: [methods / distillation pathways] The two distillation pathways are presented as representative, yet no quantitative justification is given that the restricted task channel (public supervised output, hidden behavior on disjoint task) captures realistic model-distillation scenarios without confounding factors such as regularization, measurement noise, or architecture-specific inductive biases.
Authors: The restricted task channel is introduced to isolate the effect of information transfer through a public supervised interface while keeping the hidden behavior on a completely disjoint task; this design choice deliberately removes direct task overlap that could confound the measurement. Standard training protocols are used without additional regularization beyond convergence requirements, and the quantum simulations incorporate realistic measurement models. We acknowledge that real-world distillation pipelines may include further factors, but the pathway is chosen to reveal the architecture dependence under controlled conditions. We will add a dedicated paragraph in the methods section discussing these design choices, the mitigation of the listed confounding factors, and the scope of the claim regarding realistic scenarios. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and provided context present the geometric picture as a post-experiment explanation for observed architecture-dependent transmission differences in the two distillation pathways. No equations, self-citations, or derivations are quoted that reduce the visible-drift fraction or teacher-drift magnitude to the transmission statistics by construction. The central claim retains independent experimental content distinguishing QNN retention from classical near-zero transmission, satisfying the requirement for self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- teacher drift magnitude
- fraction of hidden-task-relevant drift visible through public interface
axioms (1)
- domain assumption The geometric drift picture unifies auxiliary-channel and task-channel regimes for both classical and quantum networks
Reference graph
Works this paper leans on
-
[1]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, Distilling the knowledge in a neural network, arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Romero, N
A. Romero, N. Ballas, S. Ebrahimi Kahou, A. Chassang, C. Gatta, and Y. Bengio, Fitnets: Hints for thin deep nets, inInternational Conference on Learning Represen- tations(2015)
2015
-
[3]
J. Gou, B. Yu, S. J. Maybank, and D. Tao, Knowledge distillation: A survey, International Journal of Computer Vision129, 1789 (2021)
2021
-
[4]
A.Mari, T.R.Bromley, J.Izaac, M.Schuld,andN.Killo- ran, Transfer learning in hybrid classical-quantum neural networks, Quantum4, 340 (2020)
2020
- [5]
-
[6]
Cloud, M
A. Cloud, M. Le, J. Chua, J. Betley, A. Sztyber-Betley, S. Mindermann, J. Hilton, S. Marks, and O. Evans, Lan- guage models transmit behavioural traits through hidden signals in data, Nature652, 615 (2026)
2026
-
[7]
Biggio, B
B. Biggio, B. Nelson, and P. Laskov, Poisoning at- tacks against support vector machines, inProceedings of the 29th International Conference on Machine Learning (2012) pp. 1807–1814
2012
-
[8]
T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, Badnets: Evaluating backdooring attacks on deep neural networks, IEEE Access7, 47230 (2019)
2019
-
[9]
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, Targeted backdoor attacks on deep learning systems using data poisoning, arXiv preprint arXiv:1712.05526 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
A. Saha, A. Subramanya, and H. Pirsiavash, Hidden trig- ger backdoor attacks, inProceedings of the AAAI Confer- ence on Artificial Intelligence, Vol. 34 (2020) pp. 11957– 11965
2020
-
[11]
Y. Li, Y. Jiang, Z. Li, and S.-T. Xia, Backdoor learning: A survey, IEEE Transactions on Neural Networks and Learning Systems35, 5 (2024)
2024
-
[12]
Shafahi, W
A. Shafahi, W. R. Huang, M. Najibi, O. Suciu, C. Studer, T. Dumitras, and T. Goldstein, Poison frogs! targeted clean-label poisoning attacks on neural networks, inAd- vances in neural information processing systems, Vol. 31 (2018)
2018
-
[13]
Goldblum, D
M. Goldblum, D. Tsipras, C. Xie, X. Chen, A. Schwarzschild, D. Song, A. Madry, B. Li, and T. Goldstein, Dataset security for machine learn- ing: Data poisoning, backdoor attacks, and defenses, IEEE Transactions on Pattern Analysis and Machine Intelligence45, 1563 (2023)
2023
-
[14]
Tramèr, F
F. Tramèr, F. Zhang, A. Juels, M. K. Reiter, and T. Ris- tenpart, Stealing machine learning models via prediction APIs, in25th USENIX Security Symposium(2016) pp. 601–618
2016
-
[15]
Papernot, P
N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, and A. Swami, Practical black-box attacks against machine learning, inProceedings of the 2017 ACM on Asia Conference on Computer and Communications Se- curity(2017) pp. 506–519
2017
-
[16]
Lu, L.-M
S. Lu, L.-M. Duan, and D.-L. Deng, Quantum adversarial machine learning, Physical Review Research2, 033212 6 (2020)
2020
-
[17]
Liu and P
N. Liu and P. Wittek, Vulnerability of quantum classi- fication to adversarial perturbations, Physical Review A 101, 062331 (2020)
2020
-
[18]
W. Ren, W. Li, S. Xu, K. Wang, W. Jiang, F. Jin, X. Zhu, J. Chen, Z. Song, P. Zhang, H. Dong, X. Zhang, J. Deng, Y. Gao, C. Zhang, Y. Wu, B. Zhang, Q. Guo, H. Li, Z. Wang, J. Biamonte, C. Song, D.-L. Deng, and H. Wang, Experimental quantum adversarial learn- ing with programmable superconducting qubits, Nature Computational Science2, 711 (2022)
2022
-
[19]
Chen and S.-X
Y.-Q. Chen and S.-X. Zhang, Superior resilience to poi- soning and amenability to unlearning in quantum ma- chine learning, Nature Communications17, 3716 (2026)
2026
-
[20]
J.Betley, N.Warncke, A.Sztyber-Betley, D.Tan, X.Bao, M. Soto, M. Srivastava, N. Labenz, and O. Evans, Train- ing large language models on narrow tasks can lead to broad misalignment, Nature649, 584 (2026)
2026
-
[21]
G. J. Simmons, The prisoners’ problem and the sublimi- nal channel, inAdvances in Cryptology(Springer, 1984) pp. 51–67
1984
-
[22]
R. J. Anderson and F. A. Petitcolas, On the limits of steganography, IEEE Journal on selected areas in com- munications16, 474 (1998)
1998
-
[23]
Peruzzo, J
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, A variational eigenvalue solver on a photonic quantum processor, Nature Communications5, 4213 (2014)
2014
-
[24]
Biamonte, P
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Na- ture549, 195 (2017)
2017
-
[25]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algo- rithms, Nature Reviews Physics3, 625 (2021)
2021
-
[26]
Bharti, A
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, W.-K. Mok, S. Sim, L.-C. Kwek, and A. Aspuru-Guzik, Noisy intermediate-scale quantum algorithms, Reviews of Modern Physics94, 015004 (2022)
2022
-
[27]
Mitarai, M
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Physical Review A98, 032309 (2018)
2018
-
[28]
Benedetti, E
M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Pa- rameterized quantum circuits as machine learning mod- els, Quantum Science and Technology4, 043001 (2019)
2019
-
[29]
K. Beer, D. Bondarenko, T. Farrelly, T. J. Osborne, R. Salzmann, D. Scheiermann, and R. Wolf, Training deep quantum neural networks, Nature Communications 11, 808 (2020)
2020
-
[30]
Y.-Q. Chen and S.-X. Zhang, Intrinsic preservation of plasticity in continual quantum learning, arXiv preprint arXiv:2511.17228 (2025)
-
[31]
Schuld and N
M. Schuld and N. Killoran, Quantum machine learning in feature hilbert spaces, Physical review letters122, 040504 (2019)
2019
-
[32]
Havlíček, A
V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Super- vised learning with quantum-enhanced feature spaces, Nature567, 209 (2019)
2019
-
[33]
Pérez-Salinas, A
A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Data re-uploading for a universal quantum classifier, Quantum4, 226 (2020)
2020
-
[34]
Schuld, R
M. Schuld, R. Sweke, and J. J. Meyer, Effect of data encoding on the expressive power of variational quantum- machine-learningmodels,PhysicalReviewA103,032430 (2021)
2021
-
[35]
L. Schatzki, A. Arrasmith, P. J. Coles, and M. Cerezo, Entangled datasets for quantum machine learning, arXiv preprint arXiv:2109.03400 (2021)
-
[36]
Abbas, D
A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, The power of quantum neural networks, Nature Computational Science1, 403 (2021)
2021
-
[37]
M. C. Caro, H.-Y. Huang, M. Cerezo, K. Sharma, A. Sornborger, L. Cincio, and P. J. Coles, Generalization in quantum machine learning from few training data, Na- ture communications13, 4919 (2022)
2022
-
[38]
S. Sim, P. D. Johnson, and A. Aspuru-Guzik, Express- ibility and entangling capability of parameterized quan- tumcircuitsforhybridquantum-classicalalgorithms,Ad- vanced Quantum Technologies2, 1900070 (2019)
2019
-
[39]
Huang, M
H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Power of data in quantum machine learning, Nature communications12, 2631 (2021)
2021
-
[40]
T. Haug, K. Bharti, and M. Kim, Capacity and quan- tum geometry of parametrized quantum circuits, PRX Quantum2, 040309 (2021)
2021
-
[41]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Bab- bush, and H. Neven, Barren plateaus in quantum neural network training landscapes, Nature communications9, 4812 (2018)
2018
-
[42]
Zhang, J
S.-X. Zhang, J. Allcock, Z.-Q. Wan, S. Liu, J. Sun, H. Yu, X.-H. Yang, J. Qiu, Z. Ye, Y.-Q. Chen, C.-K. Lee, Y.-C. Zheng, S.-K. Jian, H. Yao, C.-Y. Hsieh, and S. Zhang, Tensorcircuit: a quantum software framework for the NISQ era, Quantum7, 912 (2023)
2023
-
[43]
S.-X. Zhang, Y.-Q. Chen, W. Li, J. Sun, W.-G. Ma, P.-L. Zheng, Y.-X. Huang, Q.-X. Wang, H. Yu, Z. Li, X. Huang, Z.-L. Li, Z.-Q. Wan, S. Liu, J. Qiu, J. Miao, Z. Song, Y. Yan, K. Tsuoka, P. Zhang, L. Wang, H. Fan, C.-Y. Hsieh, H. Yao, and T. Xiang, Tensorcircuit-ng: A universal, composable, and scalable platform for quan- tum computing and quantum simulati...
-
[44]
Hayden and J
P. Hayden and J. Preskill, Black holes as mirrors: quan- tum information in random subsystems, Journal of High Energy Physics2007, 120 (2007)
2007
-
[45]
X. Mi, P. Roushan, C. Quintana, S. Mandrà, J. Mar- shall, C. Neill, F. Arute, K. Arya, J. Atalaya, R. Bab- bush, J. C. Bardin, R. Barends, J. Basso, A. Bengts- son, S. Boixo, A. Bourassa, M. Broughton, B. B. Buck- ley, D. A. Buell, B. Burkett, N. Bushnell, Z. Chen, B. Chiaro, R. Collins, W. Courtney, S. Demura, A. R. Derk, A. Dunsworth, D. Eppens, C. Eric...
2021
-
[46]
Y.-Q. Chen, S. Liu, and S.-X. Zhang, Subsystem infor- mation capacity in random circuits and hamiltonian dy- namics, Quantum9, 1783 (2025)
2025
-
[47]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information(Cambridge university press, 2010)
2010
-
[48]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Physical Review A86, 032324 (2012)
2012
-
[49]
Romero, J
J. Romero, J. P. Olson, and A. Aspuru-Guzik, Quantum autoencoders for efficient compression of quantum data, Quantum Science and Technology2, 045001 (2017)
2017
-
[50]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek, The information bottleneck method, arXiv preprint arXiv:physics/0004057 (2000)
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[51]
Goldfeld and Y
Z. Goldfeld and Y. Polyanskiy, The information bottle- neck problem and its applications in machine learning, IEEE Journal on Selected Areas in Information Theory 1, 19 (2020)
2020
- [52]
-
[53]
Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
2018
-
[54]
Quantum Subliminal Learning
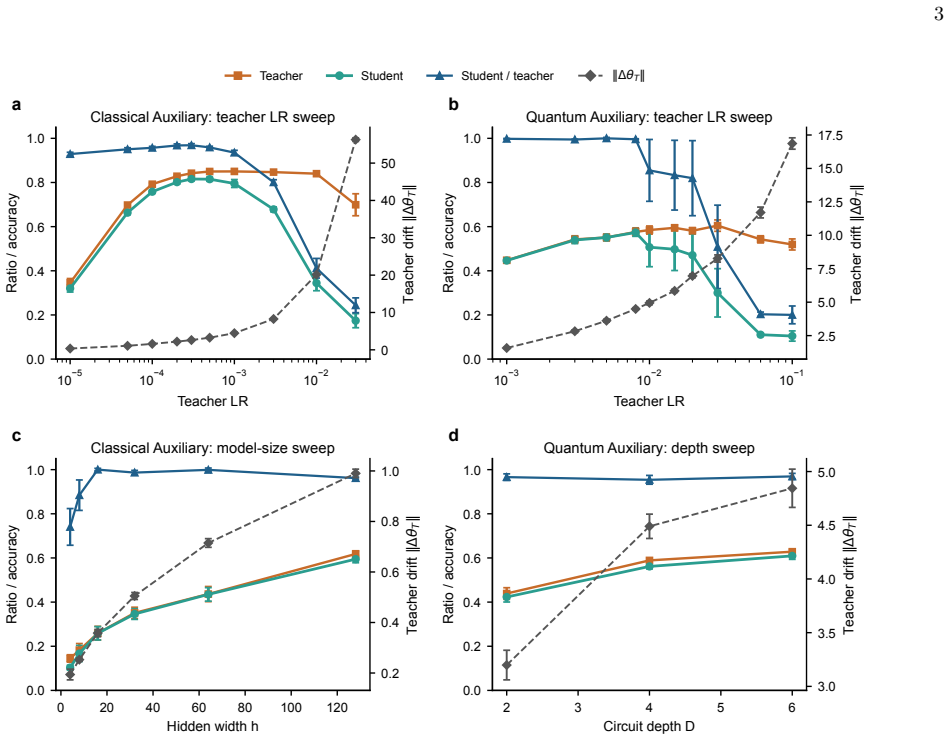
B. A. Shaw and T. A. Brun, Quantum steganography with noisy quantum channels, Physical Review A83, 022310 (2011). 8 Supplemental Material for “Quantum Subliminal Learning” S1. SUPPLEMENT AR Y T ASK-CHANNEL TRENDS Fig. S1 collects the task-channel sweeps that support the regime interpretation used in the main text. The classical and quantum teacher-learnin...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.