Active Continual Learning with Metaplastic Binary Bayesian Neural Networks
Pith reviewed 2026-06-29 09:01 UTC · model grok-4.3
The pith
A bounded-memory variational update prevents saturation in binary Bayesian neural networks, enabling buffer-free active continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
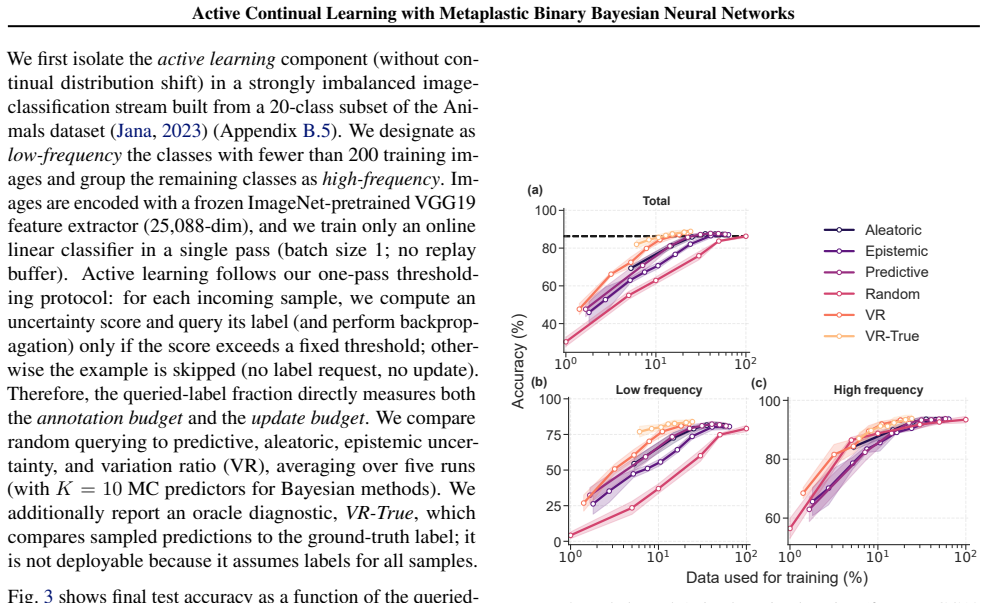
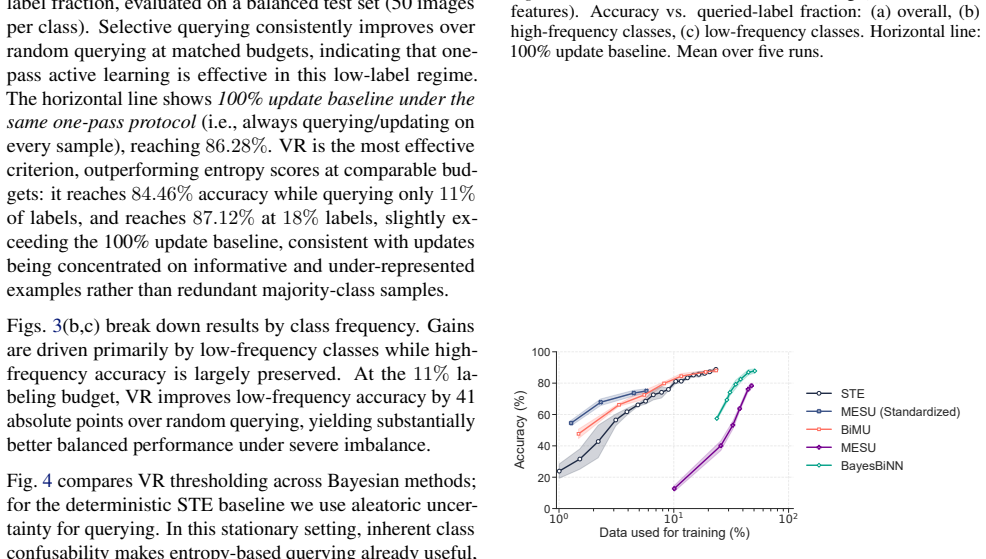
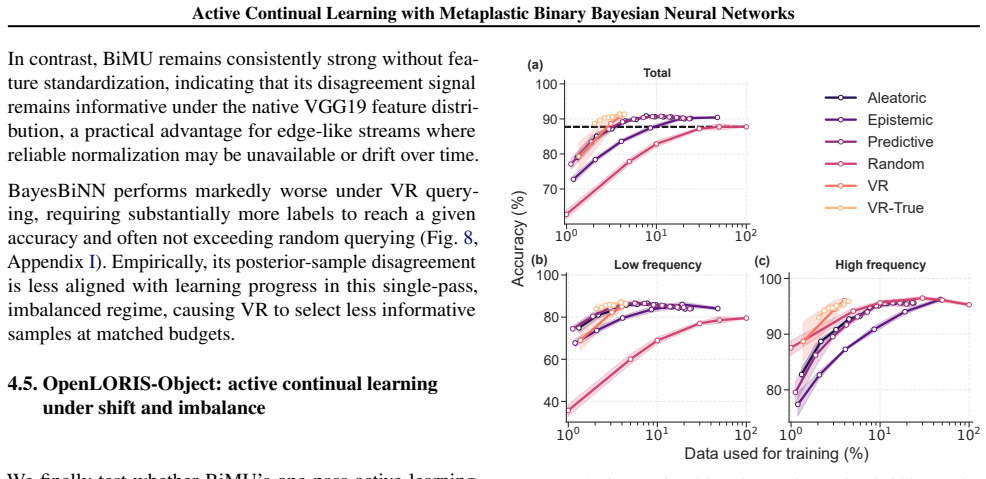
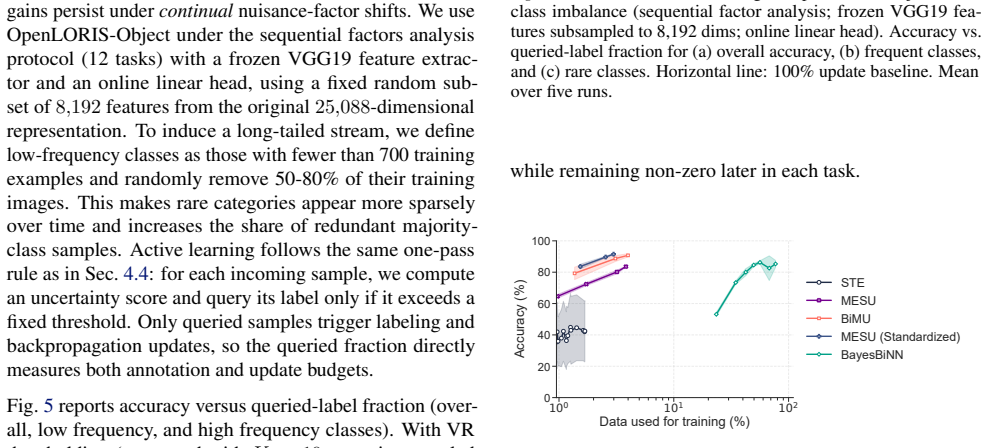
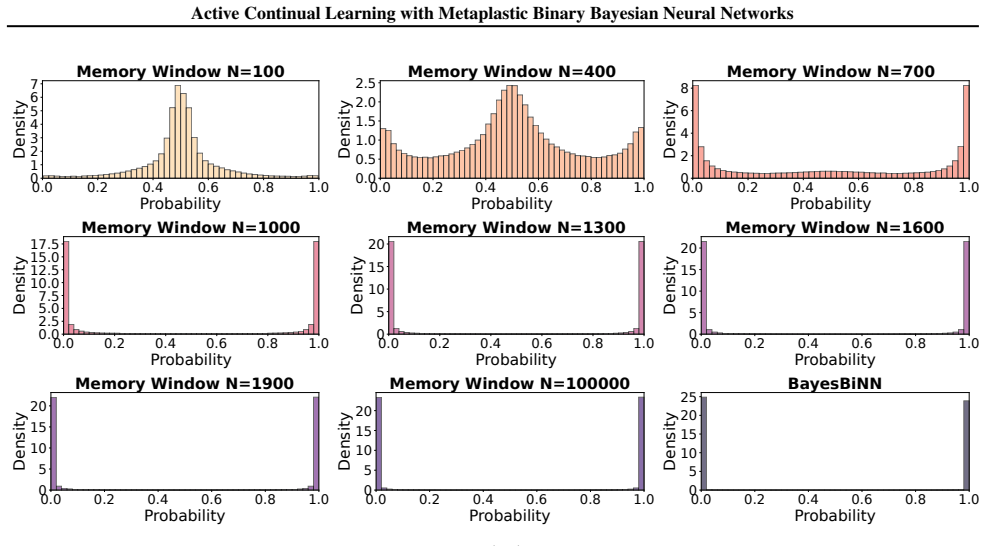
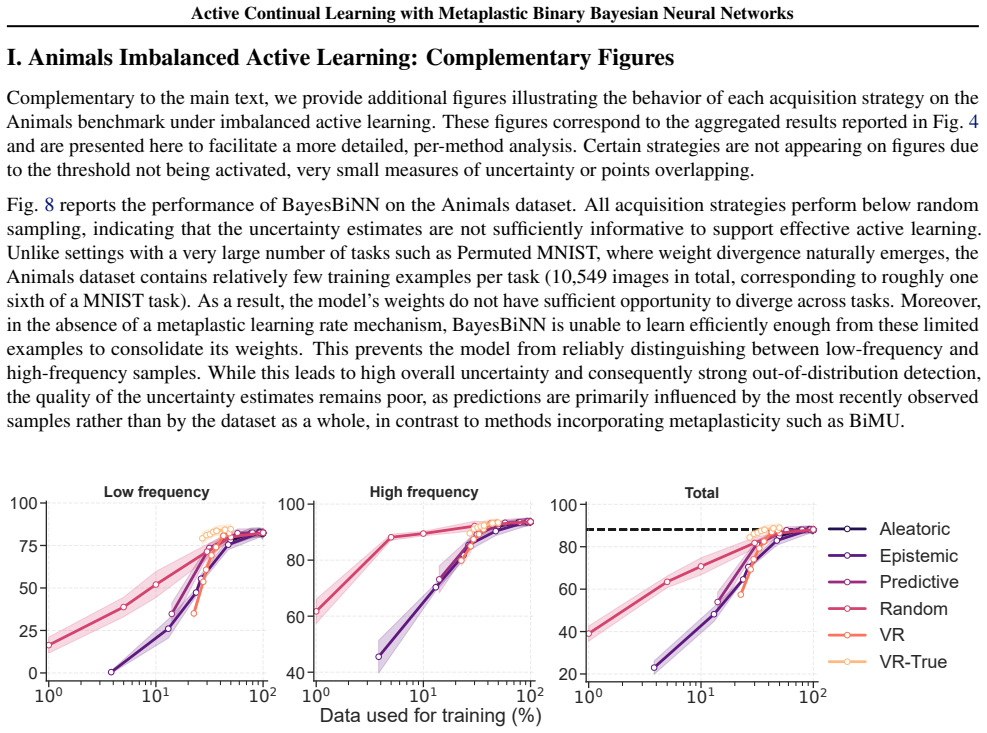
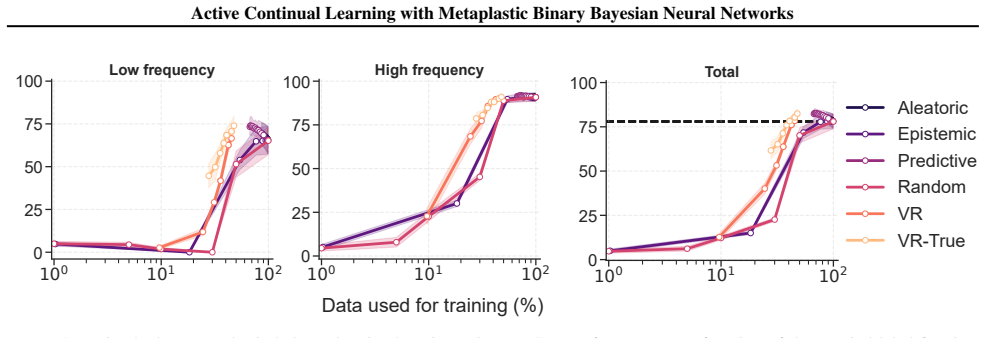
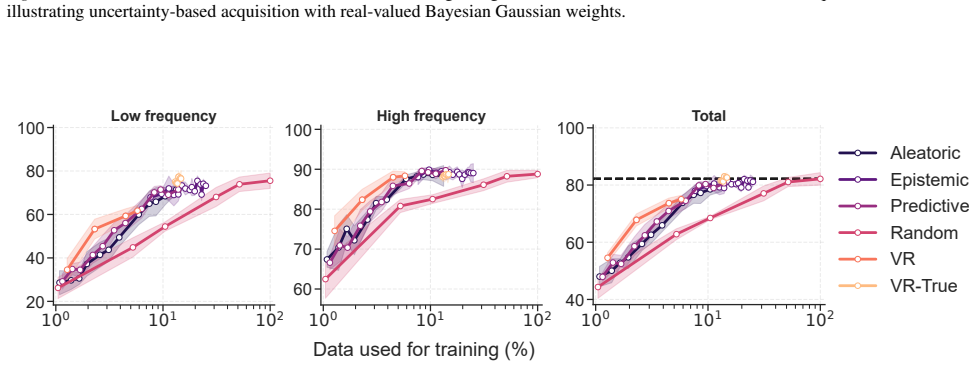
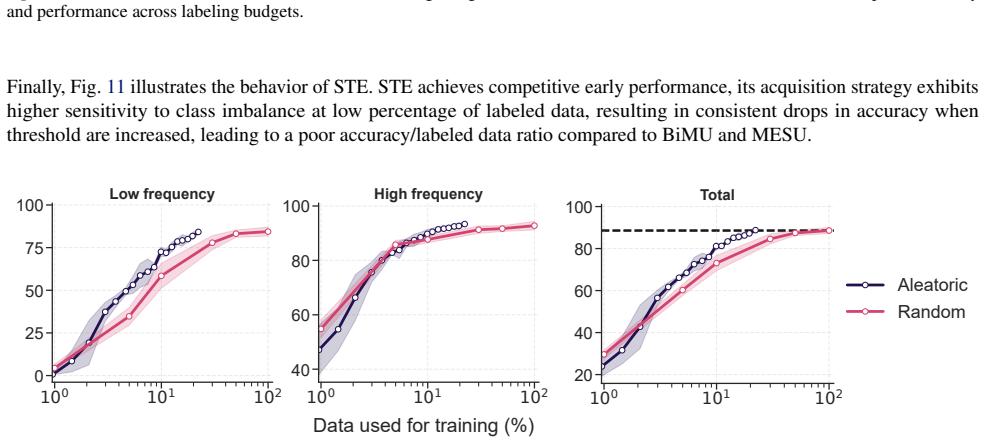
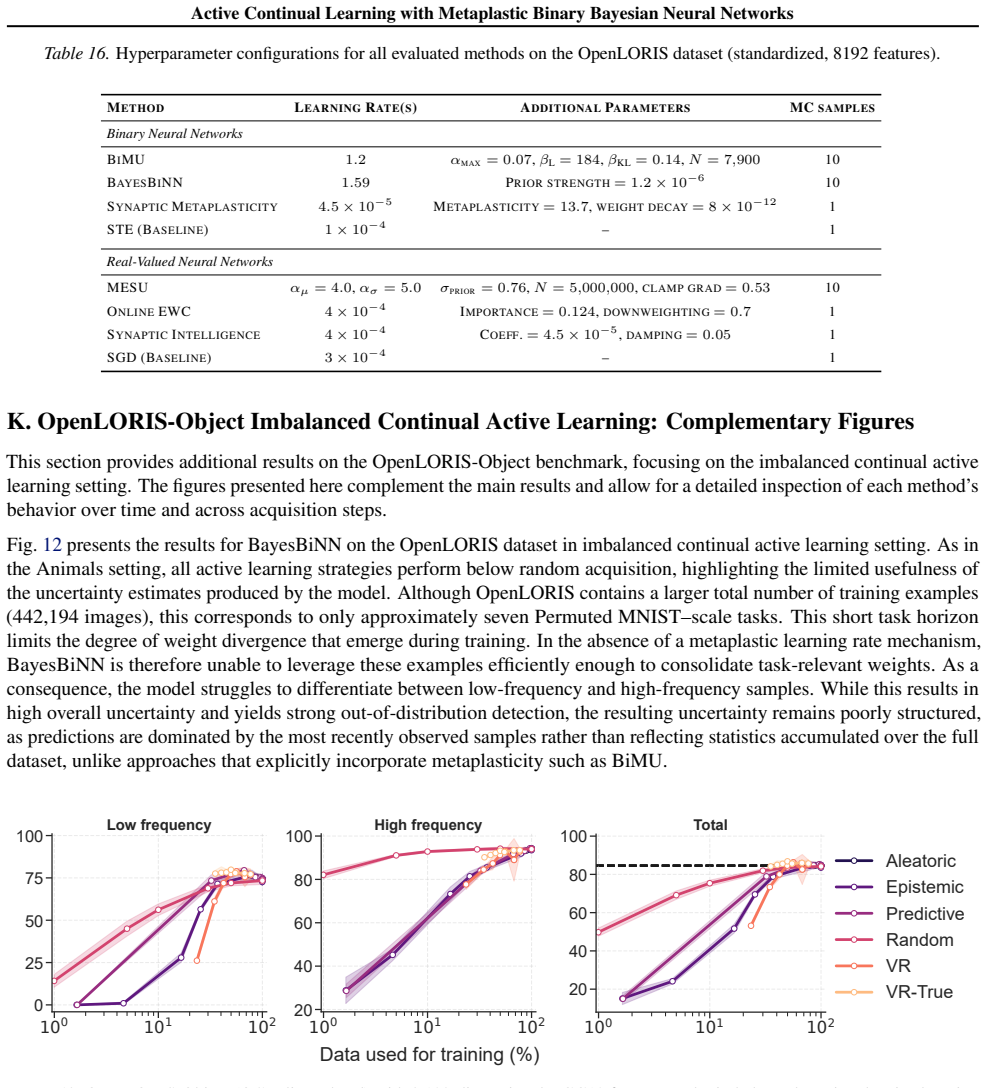
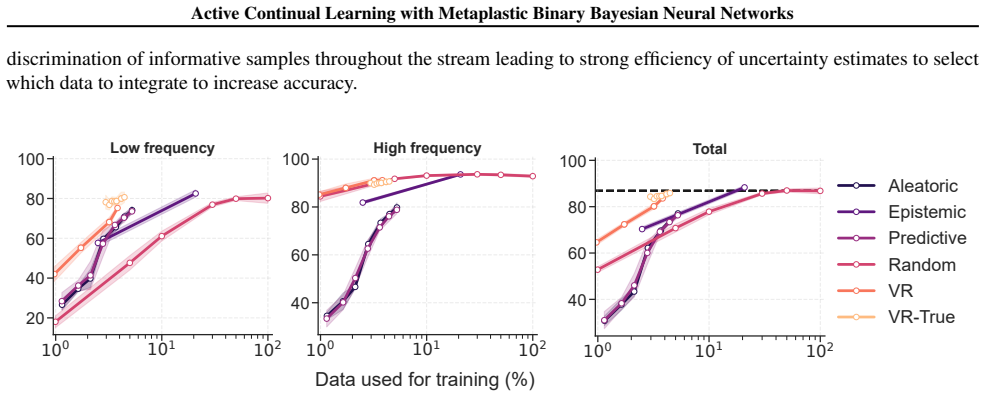
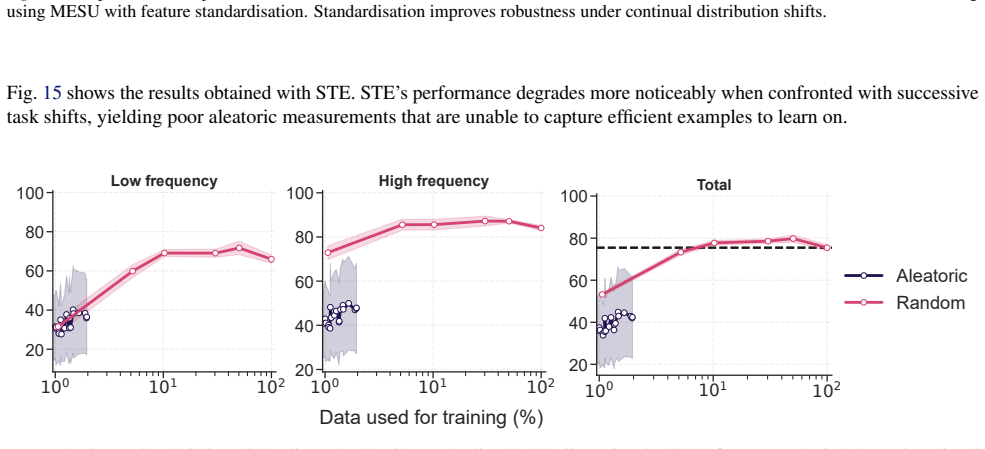
BiMU combines a data term with controlled relaxation toward the prior and an uncertainty-dependent step size that prevents saturation and sustains informative uncertainty. This non-degenerate posterior enables fully online, buffer-free active querying via Monte Carlo disagreement, reducing label queries and backpropagation updates under imbalance. BiMU sustains learning and strong OOD detection on 1000-tasks Permuted-MNIST, and on OpenLORIS-Object achieves up to 32× label/update savings at matched accuracy under class imbalance and feature compression.
What carries the argument
BiMU, the metaplastic update derived from a bounded-memory variational objective that uses an uncertainty-dependent step size to maintain non-degenerate posteriors in binary Bayesian neural networks.
If this is right
- Learning continues across 1000 sequential tasks on Permuted-MNIST without performance collapse.
- Active querying reduces the number of required labels and updates by factors up to 32 while matching accuracy.
- The method works under class imbalance and when features are compressed.
- Out-of-distribution detection remains strong without extra mechanisms.
- Training stays fully online and buffer-free.
Where Pith is reading between the lines
- If the same relaxation principle applies to other posterior approximations, it could extend to larger-scale continual learning problems.
- Reducing backpropagation updates this way may lower energy consumption on resource-constrained devices.
- Testing on streams longer than 1000 tasks or with different imbalance levels would further validate the approach.
- The disagreement-based querying could combine with other selection strategies for even greater efficiency.
Load-bearing premise
Mean-field Bernoulli posteriors saturate and lose plasticity on long non-stationary streams unless balanced by controlled relaxation and uncertainty-dependent steps.
What would settle it
An experiment showing that BiMU posteriors still saturate or that active learning performance drops without a replay buffer on the 1000-task Permuted-MNIST benchmark would disprove the central claim.
Figures



read the original abstract
Always-on edge systems must keep learning as conditions change under tight compute budgets and must detect unreliable predictions. Bayesian binary neural networks are attractive in this setting, but mean-field Bernoulli posteriors can saturate on long non-stationary streams, wiping out epistemic uncertainty and freezing plasticity. We propose BiMU, derived from a bounded-memory variational objective that balances stability, plasticity, and forgetting. BiMU combines a data term with controlled relaxation toward the prior and an uncertainty-dependent step size that prevents saturation and sustains informative uncertainty. This non-degenerate posterior enables fully online, buffer-free active querying via Monte Carlo disagreement, reducing label queries and backpropagation updates under imbalance. BiMU sustains learning and strong OOD detection on 1000-tasks Permuted-MNIST, and on OpenLORIS-Object achieves up to 32$\times$ label/update savings at matched accuracy under class imbalance and feature compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BiMU, a method for active continual learning using metaplastic binary Bayesian neural networks. It introduces a bounded-memory variational objective that combines a data term with controlled relaxation toward the prior and an uncertainty-dependent step size to prevent saturation of mean-field Bernoulli posteriors on long non-stationary streams. This sustains informative epistemic uncertainty, enabling fully online, buffer-free active querying via Monte Carlo disagreement. The approach is claimed to reduce label queries and backpropagation updates under class imbalance, with empirical results showing sustained performance and OOD detection on 1000-task Permuted-MNIST and up to 32× savings on OpenLORIS-Object at matched accuracy.
Significance. If the core mechanism holds, the result would be significant for resource-constrained continual learning on edge devices, addressing the challenge of maintaining plasticity and uncertainty without replay buffers or large memory in non-stationary settings. The combination of active querying with binary BNNs could enable efficient adaptation and reliable OOD detection under tight compute budgets.
major comments (2)
- [Abstract] The central claim that the uncertainty-dependent step size in the bounded-memory variational objective prevents saturation (posterior means approaching 0 or 1) over 1000-task streams is not supported by any derivation, analysis, or ablation in the provided text. Without showing that the effective learning rate remains non-degenerate under class imbalance or feature compression, the non-degenerate posterior required for MC-disagreement active querying does not follow.
- No equations, variational objective derivation, or step-size rule are supplied, making it impossible to assess whether the claimed balance of stability, plasticity, and forgetting is achieved by construction or requires additional fitted hyperparameters beyond the two free parameters noted in the axiom ledger.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and agree that the manuscript requires revisions to provide the missing derivation, equations, and analysis.
read point-by-point responses
-
Referee: [Abstract] The central claim that the uncertainty-dependent step size in the bounded-memory variational objective prevents saturation (posterior means approaching 0 or 1) over 1000-task streams is not supported by any derivation, analysis, or ablation in the provided text. Without showing that the effective learning rate remains non-degenerate under class imbalance or feature compression, the non-degenerate posterior required for MC-disagreement active querying does not follow.
Authors: We agree that the abstract and current text do not supply the requested derivation, analysis, or ablation. In revision we will add a new subsection deriving the bounded-memory variational objective, explicitly defining the uncertainty-dependent step size, and providing analysis (including effective learning-rate bounds) plus an ablation on class imbalance and feature compression to demonstrate that the posterior remains non-degenerate over long streams. revision: yes
-
Referee: [—] No equations, variational objective derivation, or step-size rule are supplied, making it impossible to assess whether the claimed balance of stability, plasticity, and forgetting is achieved by construction or requires additional fitted hyperparameters beyond the two free parameters noted in the axiom ledger.
Authors: We acknowledge that the manuscript as provided does not include the equations or step-by-step derivation. We will revise by inserting the full variational objective (data term plus controlled prior relaxation), the precise uncertainty-dependent step-size rule, and a short proof that the balance is achieved with only the two stated hyperparameters. Pseudocode and a clarifying paragraph will also be added. revision: yes
Circularity Check
No significant circularity detected; derivation presented as independent variational construction
full rationale
The provided abstract and context introduce BiMU as derived from a bounded-memory variational objective that explicitly combines a data term, controlled prior relaxation, and an uncertainty-dependent step size chosen to prevent saturation. No equations, self-citations, or uniqueness theorems are quoted that would reduce the non-degenerate posterior property or the active-querying performance to a fitted parameter or prior self-referential definition by construction. The claims about sustained uncertainty and label savings are framed as consequences of the proposed objective rather than inputs renamed as outputs. Absent any load-bearing self-citation chain or ansatz smuggled via citation in the given text, the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- relaxation strength toward prior
- uncertainty-dependent step-size scaling
axioms (1)
- domain assumption Mean-field Bernoulli posteriors saturate on long non-stationary streams
Reference graph
Works this paper leans on
-
[1]
Bayesian Active Learning for Classification and Preference Learning
URL https://openreview.net/forum? id=GC5MsCxrU-. Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009. Freeman, L. C. Elementary applied statistics: for students in behavioral science.Open Journal of...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[2]
com/datasets/antoreepjana/ animals-detection-images-dataset
URL https://www.kaggle. com/datasets/antoreepjana/ animals-detection-images-dataset. Jordan, M. I., Ghahramani, Z., Jaakkola, T. S., and Saul, L. K. An introduction to variational methods for graphical models.Machine learning, 37(2):183–233, 1999. Kendall, A. and Gal, Y . What uncertainties do we need in bayesian deep learning for computer vision?Advances...
1999
-
[3]
Very Deep Convolutional Networks for Large-Scale Image Recognition
PMLR, 2020. Ngartera, L., Issaka, M. A., and Nadarajah, S. Application of bayesian neural networks in healthcare: three case studies.Machine Learning and Knowledge Extraction, 6 (4):2639–2658, 2024. Nguyen, C. V ., Li, Y ., Bui, T. D., and Turner, R. E. Variational continual learning. InInternational Confer- ence on Learning Representations, 2018. URL htt...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Performance is measured by ROC-AUC, computed over 1000 decision thresholds to discriminate in-distribution from OOD samples
as OOD data. Performance is measured by ROC-AUC, computed over 1000 decision thresholds to discriminate in-distribution from OOD samples. Hyperparameter optimization. Hyperparameters are computed on 10 tasks of Permuted MNIST with different permutations as the ones presented in the main paper as validation. Hyperparameters are obtained by maximizing the h...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.