SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones?
Pith reviewed 2026-06-29 08:11 UTC · model grok-4.3
The pith
Frontier LLMs show optimism bias when judging soundness of machine learning research proposals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
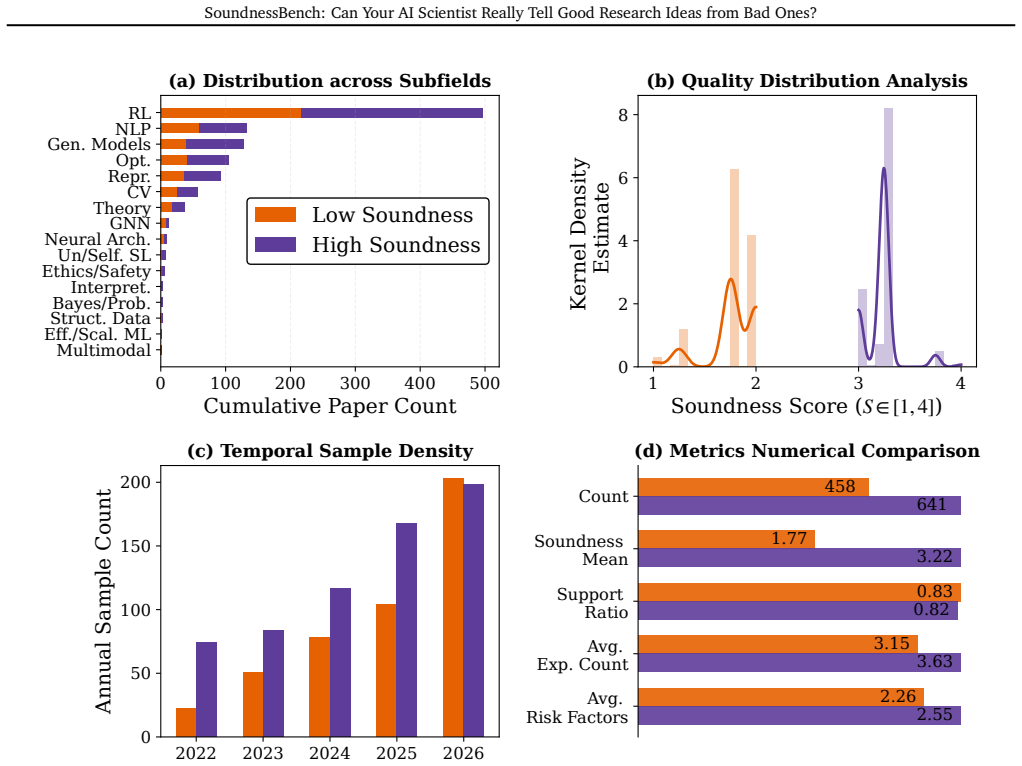
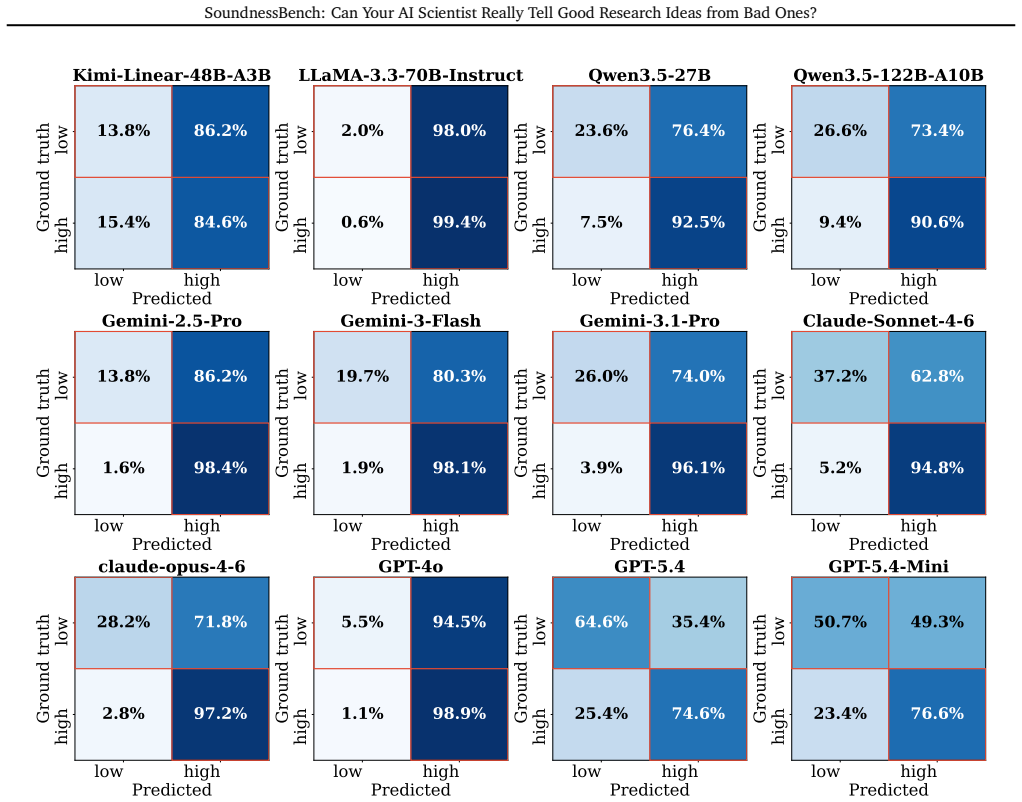
SoundnessBench supplies 1,099 machine-learning proposals reconstructed from ICLR submissions and annotated with reviewer soundness sub-scores. Under standard prompting the 12 tested LLMs frequently assign high soundness ratings to low-soundness proposals; aggressive prompting largely converts those false positives into false negatives. The results indicate that current LLMs cannot yet function as reliable standalone first-gate evaluators of research idea viability.
What carries the argument
SoundnessBench, a set of 1,099 reconstructed research proposals each paired with its original ICLR reviewer soundness sub-score, used to measure LLM ability to detect methodological viability before resources are spent.
If this is right
- Autonomous AI research agents would need additional mechanisms beyond current LLMs to avoid investing in unsound ideas.
- Standard prompting produces too many false positives; aggressive prompting trades them for too many false negatives.
- The optimism bias survives controls for public-corpus overlap, paper-identifying phrases, and surface statistics.
- LLMs cannot yet replace human first-pass review for methodological rigor in ML research.
Where Pith is reading between the lines
- Fully autonomous research loops may remain impractical until judgment reliability improves or human oversight is retained at the idea-filter stage.
- The same bias pattern could appear when LLMs evaluate proposals in other scientific fields.
- The benchmark itself could be reused to test whether fine-tuning or new architectures reduce the optimism error.
- Hybrid human-AI pipelines might remain the practical route for early-stage filtering in the near term.
Load-bearing premise
Reviewer soundness sub-scores on the published papers serve as a valid proxy for the methodological soundness of the same ideas at the proposal stage.
What would settle it
Run the same LLMs on a fresh set of proposals whose soundness has been independently scored by experts given only the proposal text and no access to the later full paper or its reviews.
Figures














read the original abstract
Autonomous AI research agents aim to accelerate scientific discovery by automating the research pipeline, from hypothesis generation to peer review. However, existing benchmarks rarely test a fundamental bottleneck: whether Large Language Models can judge the methodological viability of a research idea before expending time and computational resources. We introduce SoundnessBench, a curated benchmark of 1,099 machine-learning research proposals reconstructed from ICLR submissions, labeled with reviewer soundness sub-scores, and audited against source papers. SoundnessBench should be interpreted as a benchmark for recoverable proposal-stage soundness rather than exact prediction of full-paper review outcomes. Across 12 frontier LLMs, we find a pervasive optimism bias: under standard prompting, models frequently rate low-soundness proposals as sound, while aggressive prompting largely shifts errors from false positives to false negatives. Additional controls for public-corpus contamination, paper-identifying phrases, surface features, and human audit quality suggest that this behavior is not explained by a single confounder. Our results indicate that current LLMs are not yet reliable as standalone first-gate evaluators for scientific rigor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SoundnessBench, a benchmark of 1,099 machine-learning research proposals reconstructed from ICLR submissions and labeled with reviewer soundness sub-scores after auditing against source papers. It evaluates 12 frontier LLMs under standard and aggressive prompting, reporting a pervasive optimism bias (high false-positive rates on low-soundness proposals under standard prompting) that largely shifts to false negatives under aggressive prompting. Multiple controls address public-corpus contamination, paper-identifying phrases, surface features, and human audit quality; the benchmark is explicitly framed as measuring recoverable proposal-stage soundness rather than full-paper outcomes.
Significance. If the reconstructed proposals and their labels validly capture idea-stage methodological viability, the results would establish a concrete limitation in LLMs' reliability as early-gate evaluators for autonomous AI research agents, directly relevant to claims about automating the research pipeline. The multi-control design and careful scoping of the benchmark strengthen its potential contribution if the proxy assumption holds.
major comments (1)
- [§3 (reconstruction and labeling)] The central empirical claim of pervasive optimism bias (and its shift under aggressive prompting) depends on the ICLR soundness sub-scores serving as valid labels for methodological viability at the proposal stage. Because these scores were originally assigned to complete submissions containing experiments, ablations, and execution details absent from the reconstructions, §3 (reconstruction and labeling procedure) must provide a more explicit argument and quantitative audit evidence that the retained signal reflects idea-stage soundness rather than post-proposal execution quality; without this, the false-positive rates are difficult to interpret as evidence about proposal judgment.
minor comments (2)
- [Methods / Table 1] Table 1 or the methods section should report inter-auditor agreement statistics and the exact criteria used in the human audit of reconstructed proposals to allow readers to assess label reliability.
- [Abstract / Introduction] The abstract states the benchmark 'should be interpreted as' recoverable proposal-stage soundness; this qualification should appear in the introduction and results sections as well to prevent overgeneralization by readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below, agreeing that additional clarification in §3 would strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 (reconstruction and labeling)] The central empirical claim of pervasive optimism bias (and its shift under aggressive prompting) depends on the ICLR soundness sub-scores serving as valid labels for methodological viability at the proposal stage. Because these scores were originally assigned to complete submissions containing experiments, ablations, and execution details absent from the reconstructions, §3 (reconstruction and labeling procedure) must provide a more explicit argument and quantitative audit evidence that the retained signal reflects idea-stage soundness rather than post-proposal execution quality; without this, the false-positive rates are difficult to interpret as evidence about proposal judgment.
Authors: We agree that the link between original ICLR soundness sub-scores and proposal-stage methodological viability requires more explicit support. The manuscript already frames SoundnessBench as measuring recoverable proposal-stage soundness (rather than full-paper outcomes) and describes the reconstruction as stripping execution details while preserving the core idea. The audit against source papers was intended to verify fidelity of the retained proposal. To address the referee's concern directly, we will expand §3 with (1) a clearer argument that soundness sub-scores primarily target methodological viability (which should be evaluable from the proposal text) and (2) additional quantitative audit statistics, including agreement rates between auditors on whether the reconstructed proposal alone would have warranted the original soundness label. revision: yes
Circularity Check
Empirical benchmark measured against external ICLR reviewer labels; no circular reductions
full rationale
The paper constructs SoundnessBench from ICLR submissions and directly measures LLM ratings against the provided reviewer soundness sub-scores as external ground truth. No equations, parameters, or central claims reduce by construction to fitted inputs, self-definitions, or self-citation chains within the paper. The reported optimism bias and prompting effects are statistical observations on independent labels, with explicit caveats that the benchmark targets recoverable proposal-stage soundness rather than exact full-paper outcomes. This is a standard empirical evaluation setup with no load-bearing internal derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ICLR reviewer soundness sub-scores provide a recoverable proxy for proposal-stage methodological soundness
Forward citations
Cited by 3 Pith papers
-
ReproRepo: Scaling Reproducibility Audits with GitHub Repository Issues
ReproRepo uses GitHub issues as natural supervision to benchmark LLM agents on detecting reproducibility blockers across 1,149 ML papers, with the top agent finding related issues for roughly 90% of cases.
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
-
Agon: An Autonomous Large-Scale Omnidisciplinary Research System Built on Prompt Economy
Agon is a new autonomous research system using prompt economy loops across 444 iterations to demonstrate scalable omnidisciplinary research and a taxonomy separating machine-fixable failures from those needing human judgment.
Reference graph
Works this paper leans on
-
[1]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. Mle-bench: Evaluating machine learning agents on machine learning engineering.arXiv preprint arXiv:2410.07095,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Syntactic framing fragility: An audit of robustness in llm ethical decisions
Katherine Elkins and Jon Chun. Syntactic framing fragility: An audit of robustness in llm ethical decisions. arXiv preprint arXiv:2601.09724,
-
[3]
CausalT5k: Diagnosing Refusal and Failure Modes in Trustworthy Causal Reasoning Across Causal Rungs
Longling Geng, Andy Ouyang, Theodore Wu, Daphne Barretto, Matthew John Hayes, Rachael Cooper, Yuqiao Zeng, Sameer Vijay, Gia Ancone, Ankit Rai, et al. Causalt5k: Diagnosing and informing refusal for trustworthy causal reasoning of skepticism, sycophancy, detection-correction, and rung collapse.arXiv preprint arXiv:2602.08939,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yehua Huang, Penglei Sun, Zebin Chen, Zhenheng Tang, and Xiaowen Chu. Omnireview: A large-scale bench- markandllm-enhancedframeworkforrealisticreviewerrecommendation.arXivpreprintarXiv:2602.08896,
-
[5]
Hindsight: Evaluating research idea generation via future impact.arXiv preprint arXiv:2603.15164,
Bo Jiang. Hindsight: Evaluating research idea generation via future impact.arXiv preprint arXiv:2603.15164,
-
[6]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
GitHub reposi- tory, accessed 2026-03-27. Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Alisia Lupidi, Bhavul Gauri, Thomas Simon Foster, Bassel Al Omari, Despoina Magka, Alberto Pepe, Alexis Audran-Reiss, Muna Aghamelu, Nicolas Baldwin, Lucia Cipolina-Kun, et al. Airs-bench: a suite of tasks for frontier ai research science agents.arXiv preprint arXiv:2602.06855,
-
[8]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proc...
2023
-
[9]
doi: 10.18653/v1/2023.emnlp-main.741
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.741. URLhttps:// aclanthology.org/2023.emnlp-main.741/. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Co...
-
[10]
Is this idea novel? an automated benchmark for judgment of research ideas
Tim Schopf and Michael Färber. Is this idea novel? an automated benchmark for judgment of research ideas. arXiv preprint arXiv:2603.10303,
-
[11]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Chenglei Si, Tatsunori Hashimoto, and Diyi Yang. The ideation-execution gap: Execution outcomes of llm-generated versus human research ideas.arXiv preprint arXiv:2506.20803, 2025a. Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can LLMs generate novel research ideas? a large- scale human study with 100+ NLP researchers. InThe Thirteenth International Co...
-
[13]
URLhttps://openreview.net/forum?id=xF5PuTLPbn. Nitya Thakkar, Mert Yuksekgonul, Jake Silberg, Animesh Garg, Nanyun Peng, Fei Sha, Rose Yu, Carl Vondrick, and James Zou. Can llm feedback enhance review quality? a randomized study of 20k reviews at iclr 2025.arXiv preprint arXiv:2504.09737,
-
[14]
Fever: a large-scale dataset for fact extraction and verification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819,
2018
-
[15]
Jingqi Tong, Mingzhe Li, Hangcheng Li, Yongzhuo Yang, Yurong Mou, Weijie Ma, Zhiheng Xi, Hongji Chen, Xiaoran Liu, Qinyuan Cheng, et al. Ai can learn scientific taste.arXiv preprint arXiv:2603.14473,
-
[16]
14 SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones? Yunze Wu, Dayuan Fu, Weiye Si, Zhen Huang, Mohan Jiang, Keyu Li, Shijie Xia, Jie Sun, Tianze Xu, Xiangkun Hu, et al. Innovatorbench: Evaluating agents’ ability to conduct innovative llm research.arXiv preprint arXiv:2510.27598,
-
[17]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Sungduk Yu, Man Luo, Avinash Madusu, Vasudev Lal, and Phillip Howard. Is your paper being reviewed by an llm? benchmarking ai text detection in peer review.arXiv preprint arXiv:2502.19614,
-
[19]
we show”, “we demonstrate
15 SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones? Supplementary A. Supplementary Material for Data Construction A.1. Prompt to Extract Proposal The prompt is designed to extract proposal-level content from each paper while explicitly excluding results and conclusions. The proposal format follows Yamada et al. (2025). ...
2025
-
[20]
Experiment 1
We compute extraction faithfulness with a retrieval-backed atomic-claim score by decomposing each hypothesis– experiment pair into atomic claims, retrieving supporting passages, and verifying each claim against the source paper, following prior work on atomic factuality and evidence-grounded verification (Min et al., 2023, Thorne et al., 2018). We use GPT...
2023
-
[21]
justification
Scores: •Soundness: 3.25 •Support Ratio: 1.0 •Rigor Bucket: high 20 SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones? Example: Low-Soundness Proposal Paper id: h9ThYkkgSD4 Activation Function: Absolute Function,One Function Behaves more Individualized Year:2023 Short Hypothesis Using the absolute value function, y=|x|, a...
2023
-
[22]
finetuning free
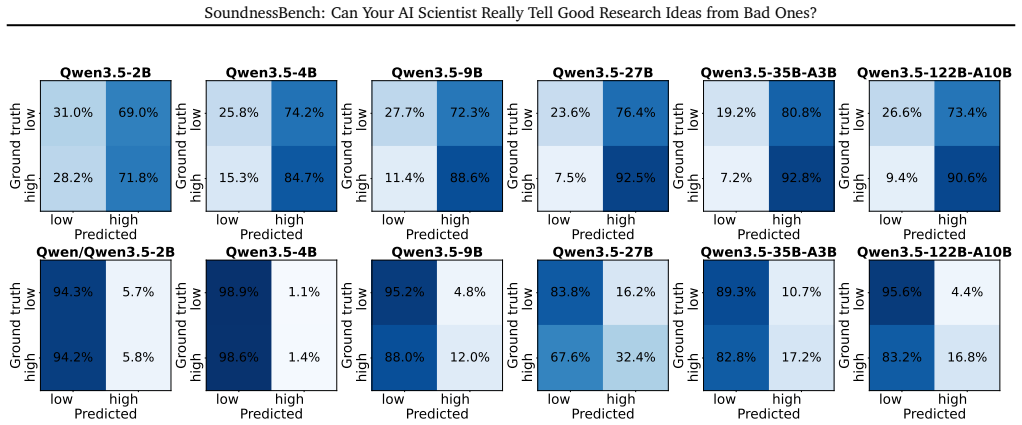
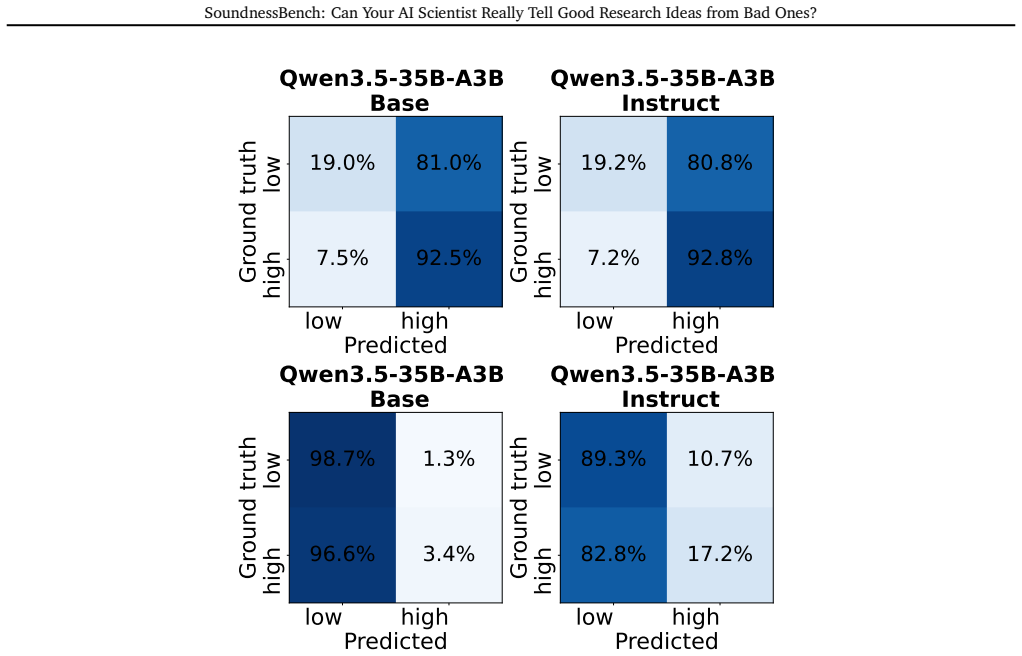
Under standard prompting, the base and instruction-tuned models are nearly indistinguishable. The base model reaches 19.0% low-soundness recall and 92.5% high-soundness recall, while the instruction-tuned model reaches 19.2% and 92.8%, respectively. These similar numbers suggest instruction tuning is unlikely to be the sole driver of the optimism bias. Un...
2026
-
[23]
The design is thoughtful (removing StoryCloze from training data for fair comparison)
Experiment 6 (Qualitative case study): Qualitative evaluation is weaker but provides complementary evidence. The design is thoughtful (removing StoryCloze from training data for fair comparison). Strengths: - Multiple ablation studies - Generalization test on held-out tasks - Comparison against strong baselines including much larger models - Standard benc...
2024
-
[24]
15.The model assigns a high-soundness judgment to the high-soundness proposal
Figure 17: GPT-5.4 Thinking response for the true-positive example in Fig. 15.The model assigns a high-soundness judgment to the high-soundness proposal. Differentially Private Steering for Large Language Model Alignment Let me analyze this hypothesis-experiment pair systematically: Hypothesis Assessment: The hypothesis is clear and meaningful. It propose...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.