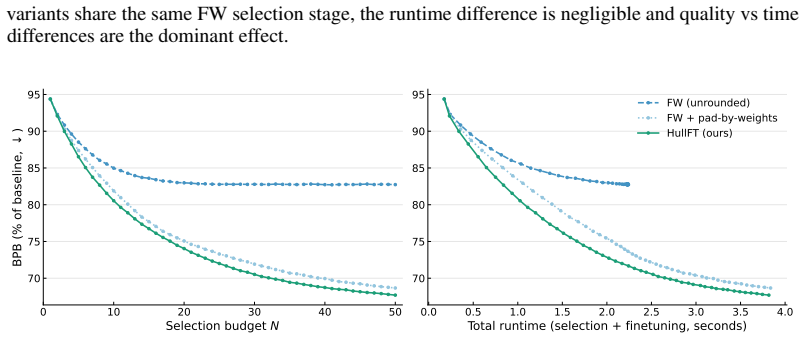
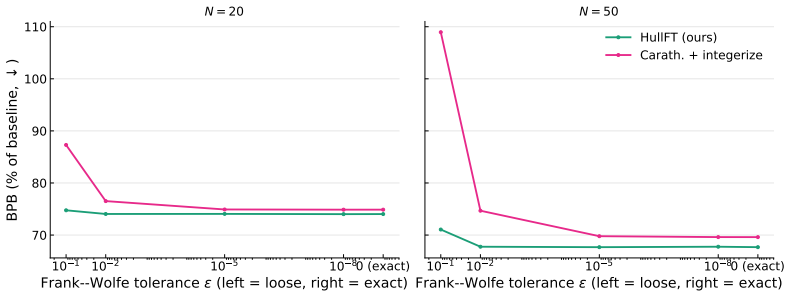
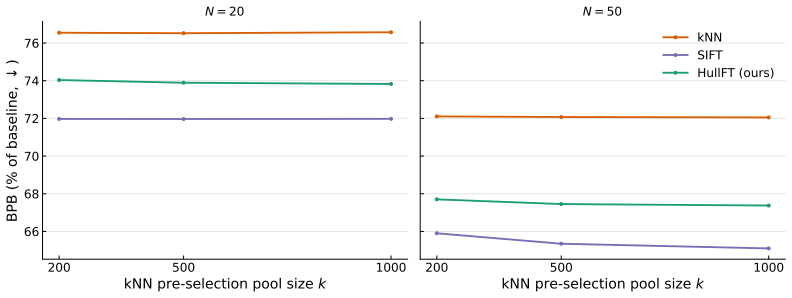
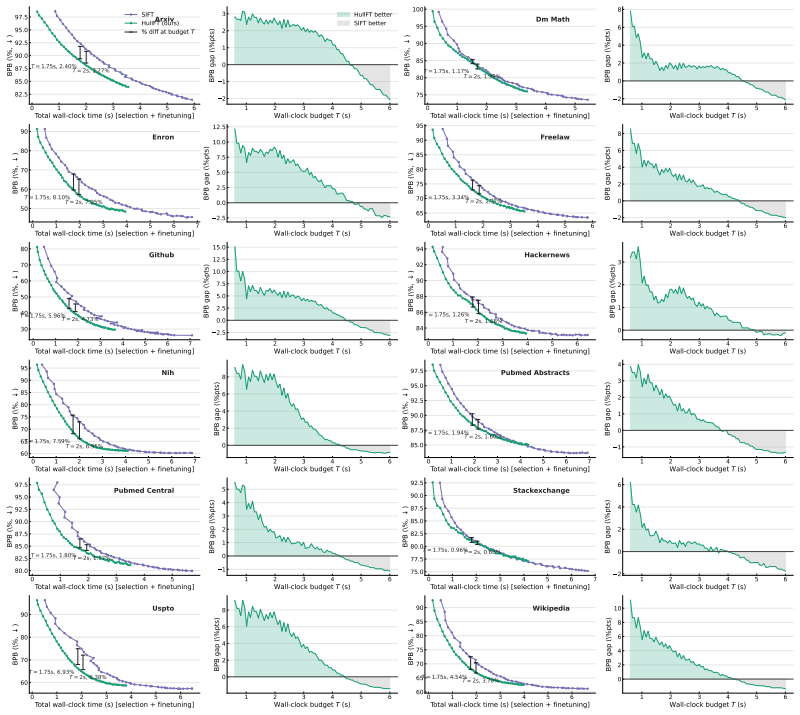
Efficient Test-Time Finetuning of LLMs via Convex Reconstruction and Gradient Caching
Pith reviewed 2026-06-29 08:56 UTC · model grok-4.3
The pith
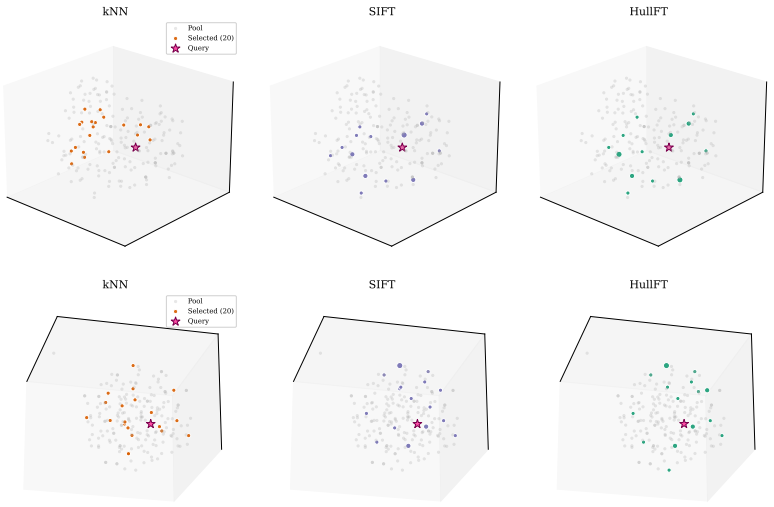
HullFT represents each query embedding as a sparse convex combination of training sequences, converts the weights to integer multiplicities, and reuses gradients on repeats to speed up test-time finetuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
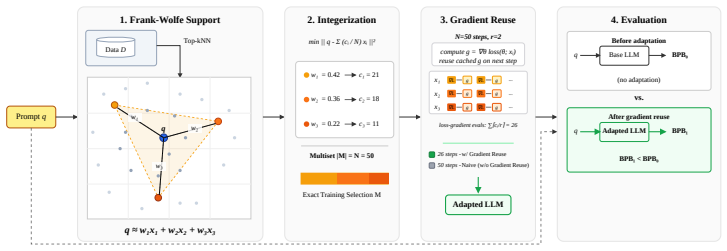
HullFT addresses both selection and update costs in test-time finetuning by first representing the query embedding as a sparse convex combination of training sequences using efficient projection-free Frank-Wolfe optimization, then converting the fractional convex weights into an exact integer multiset for finetuning through a geometric integerization procedure, and finally exploiting the resulting repeated examples with gradient reuse to amortize forward-backward computation across repeated finetuning steps.
What carries the argument
Frank-Wolfe optimization to obtain a sparse convex support set for the query embedding, followed by geometric integerization that turns fractional weights into exact integer multiplicities for gradient caching.
If this is right
- The method achieves lower bits-per-byte than current state-of-the-art TTFT approaches.
- Total runtime per query drops substantially while maintaining or improving adaptation quality.
- The support set obtained from convex reconstruction is inherently relevant and diverse without extra diversity heuristics.
- Gradient reuse on repeated examples amortizes forward-backward cost across multiple finetuning steps.
- The overall pipeline removes the need to trade speed for quality in per-query adaptation.
Where Pith is reading between the lines
- If integerization reliably preserves the convex set properties, similar reconstruction steps could replace heuristic retrieval in other per-example adaptation tasks.
- The approach opens the possibility of running test-time updates on resource-constrained devices where full per-query retrieval and training were previously infeasible.
- Because the support set size is controlled by the Frank-Wolfe sparsity, the method may scale to much larger training corpora without quadratic retrieval costs.
Load-bearing premise
The geometric integerization procedure converts fractional convex weights into an exact integer multiset without materially degrading the relevance or diversity properties that the Frank-Wolfe support set was chosen to provide.
What would settle it
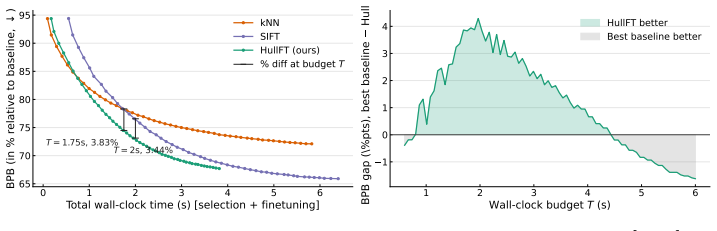
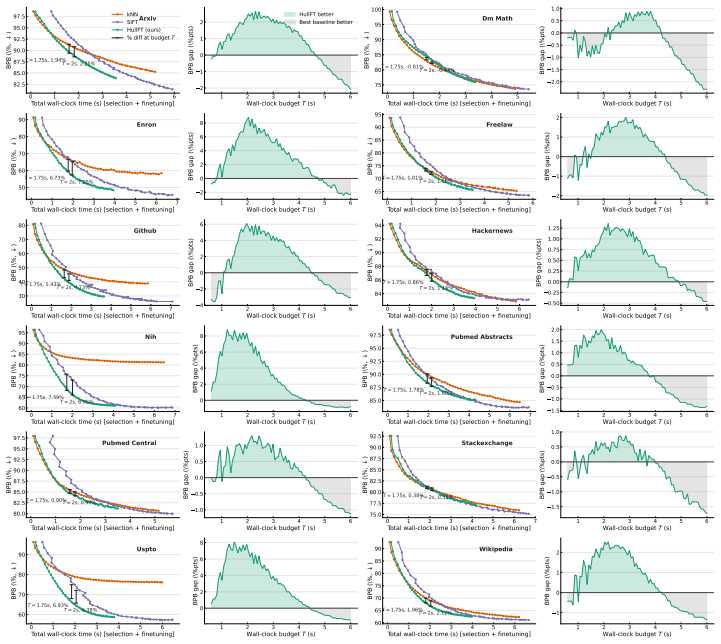
A head-to-head benchmark run showing that HullFT produces higher bits-per-byte or higher total runtime than the strongest prior TTFT baseline on the same model and dataset would falsify the claimed quality-efficiency improvement.
Figures
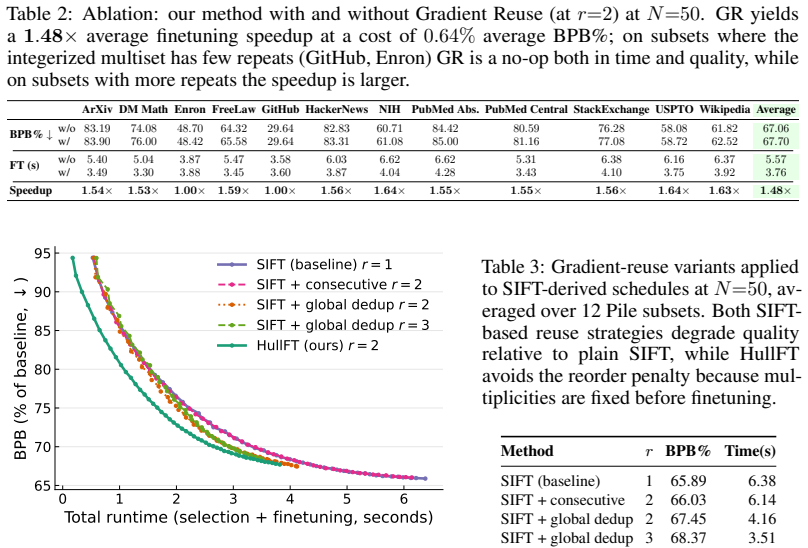
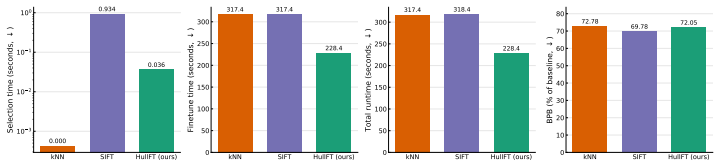
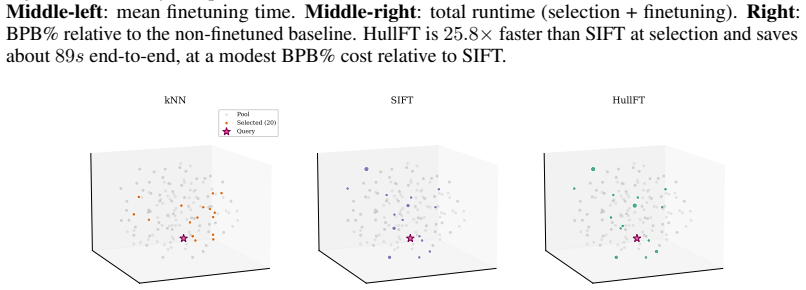
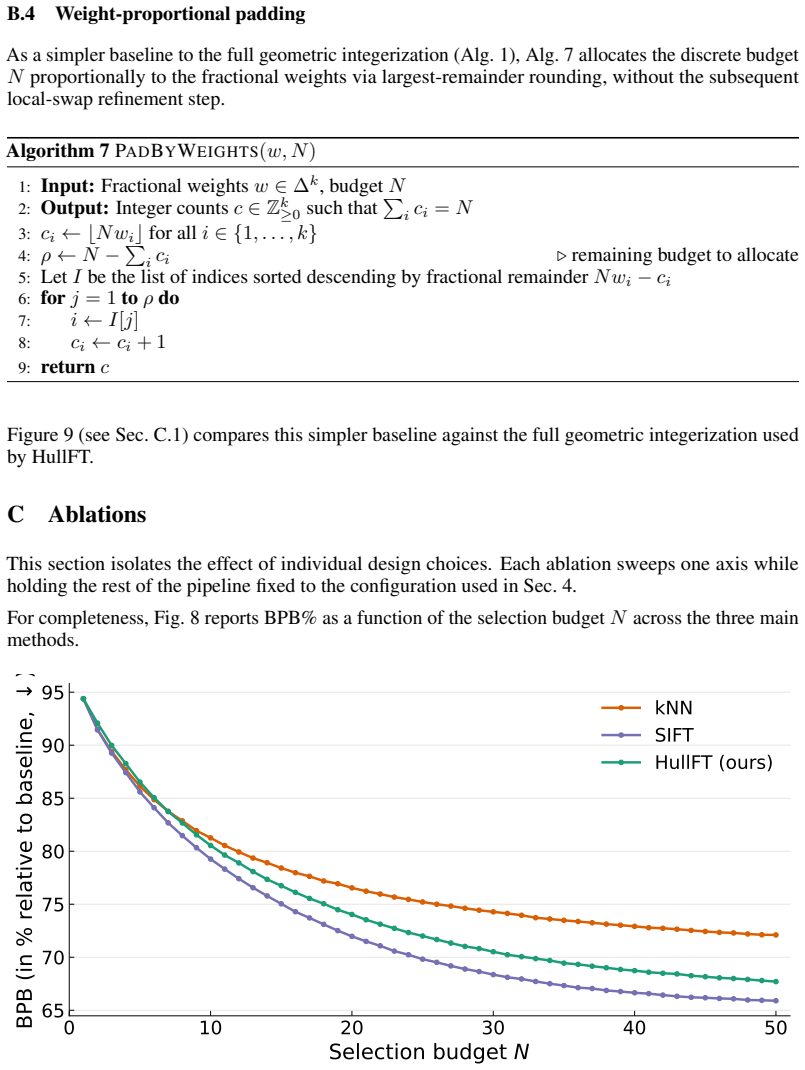



read the original abstract
Test-time finetuning (TTFT) is a rapidly evolving paradigm that adapts a language model to each prompt by retrieving related sequences, updating the model on them, and then evaluating the prompt. However, TTFT is only practical if it is fast: selection and finetuning both happen per query, making each a direct bottleneck. Existing methods trade speed for quality: fast retrieval is often redundant, while stronger diversity-aware selection adds prohibitive per-query cost. We introduce HullFT, a geometric approach to TTFT that addresses both bottlenecks. Given a query, HullFT first represents the query embedding as a sparse convex combination of few training sequences, using efficient projection-free Frank-Wolfe optimization. This yields a support set that is inherently relevant and diverse. We then convert the fractional convex weights into an exact integer multiset for finetuning through a geometric integerization procedure. The resulting multiplicities naturally create repeated examples, which we exploit with Gradient Reuse to amortize forward-backward computation across repeated finetuning steps. Our experiments show that HullFT improves the quality-efficiency tradeoff over current state-of-the-art TTFT methods, achieving lower bits-per-byte at substantially lower total runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HullFT for test-time finetuning (TTFT) of LLMs. It represents each query embedding as a sparse convex combination of training sequences via projection-free Frank-Wolfe optimization to obtain a relevant and diverse support set, converts the resulting fractional weights to an exact integer multiset via a geometric integerization procedure, and exploits the resulting repeated examples with Gradient Reuse to amortize forward-backward passes. The central claim is that this pipeline improves the quality-efficiency tradeoff over prior TTFT methods, yielding lower bits-per-byte at substantially lower total runtime.
Significance. If the empirical claims hold and the integerization step preserves the intended properties of the support set, the geometric framing could supply a more principled and efficient alternative to heuristic retrieval-plus-finetuning pipelines, with potential impact on practical per-query adaptation of large models.
major comments (2)
- [Abstract] Abstract: the claim that experiments demonstrate improved quality-efficiency tradeoffs is presented without any quantitative tables, ablation details, error bars, or baseline numbers, rendering the headline result impossible to evaluate from the provided text.
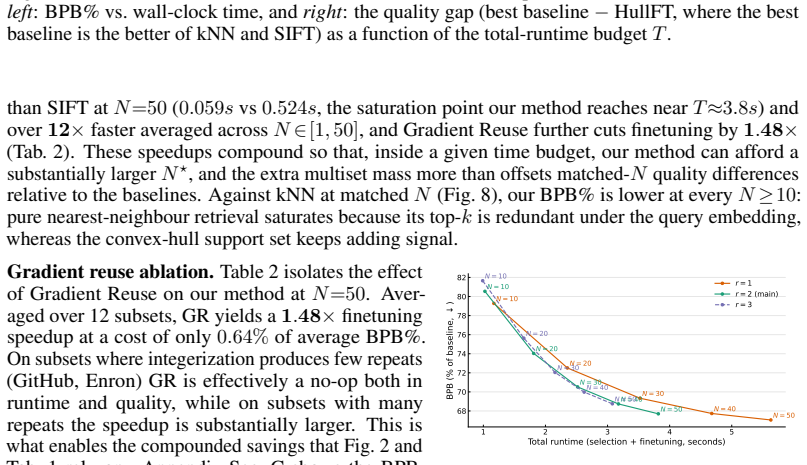
- [Method] Method (geometric integerization step): the pipeline relies on converting Frank-Wolfe fractional weights to integer multiplicities without materially altering the effective training distribution, yet no L1 or total-variation bound, convergence guarantee, or ablation isolating the integerization effect on bits-per-byte (while holding total FLOPs fixed) is supplied; this is load-bearing for the quality claim.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments demonstrate improved quality-efficiency tradeoffs is presented without any quantitative tables, ablation details, error bars, or baseline numbers, rendering the headline result impossible to evaluate from the provided text.
Authors: We agree with the observation that the abstract presents the experimental claims at a high level without specific numbers. To address this, we will revise the abstract to incorporate key quantitative results from our experiments, including comparisons to baselines in terms of bits-per-byte and runtime, while maintaining its concise nature. This will make the headline result more directly evaluable. revision: yes
-
Referee: [Method] Method (geometric integerization step): the pipeline relies on converting Frank-Wolfe fractional weights to integer multiplicities without materially altering the effective training distribution, yet no L1 or total-variation bound, convergence guarantee, or ablation isolating the integerization effect on bits-per-byte (while holding total FLOPs fixed) is supplied; this is load-bearing for the quality claim.
Authors: The referee correctly identifies that the manuscript does not provide an explicit analysis or ablation for the integerization step. We will add to the revised manuscript a bound on the total variation distance between the fractional and integer distributions, along with an ablation that measures the impact of integerization on bits-per-byte under fixed computational budget. This will substantiate the claim that the procedure does not materially alter the effective training distribution. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an algorithmic pipeline: Frank-Wolfe optimization produces a sparse convex combination yielding a support set, a separate geometric integerization converts fractional weights to integer multiplicities, and repeated examples enable gradient reuse. Performance claims (lower bits-per-byte at lower runtime) are presented as empirical outcomes of this procedure rather than tautological re-expressions of input parameters or fitted quantities. No equations reduce by construction to their own inputs, no load-bearing self-citation chains are invoked for uniqueness or ansatz, and no known result is merely renamed. The integerization step's preservation of relevance/diversity is an unproven assumption (a correctness concern), not a definitional or fitted-input circularity. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[2]
The Refined- Web dataset for Falcon LLM: Outperforming curated corpora with web data, and web data only
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Hamza Alobeidli, Alessandro Cappelli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The Refined- Web dataset for Falcon LLM: Outperforming curated corpora with web data, and web data only. InProceedings of the 37th International Conference on Neural Information Processing Sy...
2023
-
[3]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. InProceedings of the 37th International Conference on Machine Learning, pages 9229–9248, 2020
2020
-
[4]
Test-time training with masked autoencoders
Yossi Gandelsman, Yu Sun, Xinlei Chen, and Alexei A Efros. Test-time training with masked autoencoders. InAdvances in Neural Information Processing Systems, 2022
2022
-
[5]
Test-time training on nearest neighbors for large language models
Moritz Hardt and Yu Sun. Test-time training on nearest neighbors for large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
Learning to (learn at test time): RNNs with expressive hidden states
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): RNNs with expressive hidden states. InForty-second International Conference on Machine Learning, 2025
2025
-
[7]
The surprising effectiveness of test-time training for abstract reasoning
Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyothish Pari, Yoon Kim, and Jacob Andreas. The surprising effectiveness of test-time training for abstract reasoning. arXiv preprint arXiv:2411.07279, 2024
-
[8]
Efficiently learning at test- time: Active fine-tuning of LLMs
Jonas Hübotter, Sascha Bongni, Ido Hakimi, and Andreas Krause. Efficiently learning at test- time: Active fine-tuning of LLMs. InInternational Conference on Learning Representations, 2025
2025
-
[9]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[10]
CCNet: Extracting high quality monolingual datasets from web crawl data
Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. CCNet: Extracting high quality monolingual datasets from web crawl data. InProceedings of the 12th Language Resources and Evaluation Conference, pages 4003–4012, 2020
2020
-
[11]
SemDeDup: Data-efficient learning at web-scale through semantic deduplication
Amro Abbas, Kushal Tirumala, Daniel Simig, Surya Ganguli, and Ari S Morcos. SemD- eDup: Data-efficient learning at web-scale through semantic deduplication.arXiv preprint arXiv:2303.09540, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 335–336, 1998
1998
-
[14]
Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2–3):123–286, 2012
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2–3):123–286, 2012
2012
-
[15]
Active learning for convolutional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Conference on Learning Representations, 2018. 10
2018
-
[16]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InProceedings of the 37th International Conference on Machine Learning, pages 6950–6960, 2020
2020
-
[17]
Approximating Nash equilibria and dense bipartite subgraphs via an approximate version of Carathéodory’s theorem
Siddharth Barman. Approximating Nash equilibria and dense bipartite subgraphs via an approximate version of Carathéodory’s theorem. InProceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, pages 361–369, 2015
2015
-
[18]
Über den Variabilitätsbereich der Koeffizienten von Potenzreihen, die gegebene Werte nicht annehmen.Mathematische Annalen, 64(1):95–115, 1907
Constantin Carathéodory. Über den Variabilitätsbereich der Koeffizienten von Potenzreihen, die gegebene Werte nicht annehmen.Mathematische Annalen, 64(1):95–115, 1907
1907
-
[19]
Combettes and Sebastian Pokutta
Cyrille W. Combettes and Sebastian Pokutta. Revisiting the approximate carathéodory problem via the frank–wolfe algorithm.Mathematical Programming, 197(1):191–214, 2023
2023
-
[20]
Transductive inference for text classification using support vector machines
Thorsten Joachims. Transductive inference for text classification using support vector machines. InProceedings of the Sixteenth International Conference on Machine Learning, pages 200–209, 1999
1999
-
[21]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InPro- ceedings of the 34th International Conference on Neural Information Processing Systems, 2020
2020
-
[22]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, ...
2022
-
[23]
The influence curve and its role in robust estimation.Journal of the American Statistical Association, 69:383–393, 1974
Frank R Hampel. The influence curve and its role in robust estimation.Journal of the American Statistical Association, 69:383–393, 1974
1974
-
[24]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InProceedings of the 34th International Conference on Machine Learning, pages 1885–1894, 2017
2017
-
[25]
Estimating training data influence by tracing gradient descent
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent. InProceedings of the 34th International Conference on Neural Information Processing Systems, volume 33, pages 19920–19930, 2020
2020
-
[26]
DataInf: Efficiently estimating data influence in LoRA-tuned LLMs and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. DataInf: Efficiently estimating data influence in LoRA-tuned LLMs and diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[27]
LESS: Selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. LESS: Selecting influential data for targeted instruction tuning. InInternational Conference on Machine Learning, 2024
2024
-
[28]
Universal language model fine-tuning for text classi- fication
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classi- fication. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 328–339, 2018
2018
-
[29]
Suchin Gururangan, Ana Marasovi´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, 2020
2020
-
[30]
BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020. 11
2020
-
[31]
Publicly available clinical BERT embeddings
Emily Alsentzer, John Murphy, William Boag, Wei-Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. Publicly available clinical BERT embeddings. InProceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78, 2019
2019
-
[32]
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. ClinicalBERT: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[33]
SciBERT: A pretrained language model for sci- entific text
Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for sci- entific text. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, 2019
2019
-
[34]
LEGAL-BERT: The muppets straight out of law school
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion An- droutsopoulos. LEGAL-BERT: The muppets straight out of law school. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2898–2904, 2020
2020
-
[35]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Senevi- ratne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Schärli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Agüera y Arcas, Dale Webster, Greg S. Corrad...
2023
-
[36]
LIMA: Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. LIMA: Less is more for alignment. InProceedings of the 37th International Conference on Neural Information Processing Systems, 2023
2023
-
[37]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[38]
DataS3: Dataset subset selection for specialization.arXiv preprint arXiv:2504.16277, 2025
Neha Hulkund, Alaa Maalouf, Levi Cai, Daniel Yang, Tsun-Hsuan Wang, Abigail O’Neil, Timm Haucke, Sandeep Mukherjee, Vikram Ramaswamy, Judy Hansen Shen, Gabriel Tseng, Mike Walmsley, Daniela Rus, Ken Goldberg, Hannah Kerner, Irene Chen, Yogesh Girdhar, and Sara Beery. DataS3: Dataset subset selection for specialization.arXiv preprint arXiv:2504.16277, 2025
-
[39]
Compress to impress: Efficient LLM adaptation using a single gradient step on 100 samples
Shiva Sreeram, Alaa Maalouf, Pratyusha Sharma, and Daniela Rus. Compress to impress: Efficient LLM adaptation using a single gradient step on 100 samples. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[40]
Amir Mallak and Alaa Maalouf. Robustness is a function, not a number: A factorized compre- hensive study of OOD robustness in vision-based driving.arXiv preprint arXiv:2602.09018, 2026
-
[41]
Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models
Tsun-Hsuan Wang, Alaa Maalouf, Wei Xiao, Yutong Ban, Alexander Amini, Guy Rosman, Sertac Karaman, and Daniela Rus. Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6687–6694. IEEE, 2024
2024
-
[42]
How to train data-efficient LLMs
Noveen Sachdeva, Benjamin Coleman, Wang-Cheng Kang, Jianmo Ni, Lichan Hong, Ed H Chi, James Caverlee, Julian McAuley, and Derek Zhiyuan Cheng. How to train data-efficient LLMs. arXiv preprint arXiv:2402.09668, 2024
-
[43]
QuRating: Selecting high- quality data for training language models
Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. QuRating: Selecting high- quality data for training language models. InInternational Conference on Machine Learning, 2024
2024
-
[44]
Fast and accurate least-mean-squares solvers
Alaa Maalouf, Ibrahim Jubran, and Dan Feldman. Fast and accurate least-mean-squares solvers. InProceedings of the 33rd International Conference on Neural Information Processing Systems, volume 32, 2019. 12
2019
-
[45]
B. Maurey. Théorèmes de factorisation pour les opérateurs linéaires à valeurs dans un espace lp(ω, µ),0< p≤+∞.Séminaire Maurey-Schwartz, pages 1–8, 1972-1973
1972
-
[46]
Tight bounds for approximate Carathéodory and beyond
Vahab Mirrokni, Renato Paes Leme, Adrian Vladu, and Sam Chiu-wai Wong. Tight bounds for approximate Carathéodory and beyond. InProceedings of the 34th International Conference on Machine Learning, pages 2440–2448, 2017
2017
-
[47]
An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1–2):95–110, 1956
Marguerite Frank and Philip Wolfe. An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1–2):95–110, 1956
1956
-
[48]
Revisiting Frank–Wolfe: Projection-free sparse convex optimization
Martin Jaggi. Revisiting Frank–Wolfe: Projection-free sparse convex optimization. InProceed- ings of the 30th International Conference on Machine Learning, pages 427–435, 2013
2013
-
[49]
Some comments on Wolfe’s ‘away step’.Mathematical Programming, 35:110–119, 1986
Jacques Guélat and Patrice Marcotte. Some comments on Wolfe’s ‘away step’.Mathematical Programming, 35:110–119, 1986
1986
-
[50]
Convergence Rate of Frank-Wolfe for Non-Convex Objectives
Simon Lacoste-Julien. Convergence rate of Frank–Wolfe for non-convex objectives.arXiv preprint arXiv:1607.00345, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[51]
Coresets, sparse greedy approximation, and the Frank–Wolfe algorithm
Kenneth L Clarkson. Coresets, sparse greedy approximation, and the Frank–Wolfe algorithm. ACM Transactions on Algorithms, 6(4):63:1–63:30, 2010
2010
-
[52]
Geometric approximation via coresets
Pankaj K Agarwal, Sariel Har-Peled, and Kasturi R Varadarajan. Geometric approximation via coresets. In Jacob E Goodman, János Pach, and Emo Welzl, editors,Combinatorial and Computational Geometry. Cambridge University Press, 2005
2005
-
[53]
American Mathematical Society, 2011
Sariel Har-Peled.Geometric Approximation Algorithms, volume 173 ofMathematical Surveys and Monographs. American Mathematical Society, 2011
2011
-
[54]
Coresets and sketches
Jeff M Phillips. Coresets and sketches. InHandbook of Discrete and Computational Geometry. CRC Press, 2017
2017
-
[55]
Coresets for the average case error for finite query sets.Sensors, 21(19), 2021
Alaa Maalouf, Ibrahim Jubran, Murad Tukan, and Dan Feldman. Coresets for the average case error for finite query sets.Sensors, 21(19), 2021
2021
-
[56]
Provable data subset selection for efficient neural networks training
Murad Tukan, Samson Zhou, Alaa Maalouf, Daniela Rus, Vladimir Braverman, and Dan Feldman. Provable data subset selection for efficient neural networks training. InProceedings of the 40th International Conference on Machine Learning, pages 34533–34555, 2023
2023
-
[57]
GLISTER: Generalization based data subset selection for efficient and robust learning
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. GLISTER: Generalization based data subset selection for efficient and robust learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8110–8118, 2021
2021
-
[58]
GRAD-MATCH: Gradient matching based data subset selection for efficient deep model training
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. GRAD-MATCH: Gradient matching based data subset selection for efficient deep model training. InProceedings of the 38th International Conference on Machine Learning, pages 5464–5474, 2021
2021
-
[59]
Selection via proxy: Efficient data selection for deep learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data selection for deep learning. InInternational Conference on Learning Representations, 2020
2020
-
[60]
Pruning neural networks via coresets and convex geometry: Towards no assumptions
Murad Tukan, Loay Mualem, and Alaa Maalouf. Pruning neural networks via coresets and convex geometry: Towards no assumptions. InAdvances in Neural Information Processing Systems, 2022
2022
-
[61]
Provable filter pruning for efficient neural networks
Lucas Liebenwein, Cenk Baykal, Harry Lang, Dan Feldman, and Daniela Rus. Provable filter pruning for efficient neural networks. InInternational Conference on Learning Representations, 2020
2020
-
[62]
Data- independent structured pruning of neural networks via coresets.IEEE Transactions on Neural Networks and Learning Systems, 33(12):7829–7841, 2022
Ben Mussay, Dan Feldman, Samson Zhou, Vladimir Braverman, and Margarita Osadchy. Data- independent structured pruning of neural networks via coresets.IEEE Transactions on Neural Networks and Learning Systems, 33(12):7829–7841, 2022. 13
2022
-
[63]
Sensitivity- informed provable pruning of neural networks.SIAM Journal on Mathematics of Data Science, 4(1):26–45, 2022
Cenk Baykal, Lucas Liebenwein, Igor Gilitschenski, Dan Feldman, and Daniela Rus. Sensitivity- informed provable pruning of neural networks.SIAM Journal on Mathematics of Data Science, 4(1):26–45, 2022
2022
-
[64]
AutoCoreset: An au- tomatic practical coreset construction framework
Alaa Maalouf, Murad Tukan, Vladimir Braverman, and Daniela Rus. AutoCoreset: An au- tomatic practical coreset construction framework. InProceedings of the 40th International Conference on Machine Learning, pages 23451–23466, 2023
2023
-
[65]
A unified approach to coreset learning.IEEE Transactions on Neural Networks and Learning Systems, 35 (5):6893–6905, 2024
Alaa Maalouf, Gilad Eini, Ben Mussay, Dan Feldman, and Margarita Osadchy. A unified approach to coreset learning.IEEE Transactions on Neural Networks and Learning Systems, 35 (5):6893–6905, 2024
2024
-
[66]
A unified framework for approximating and clustering data
Dan Feldman and Michael Langberg. A unified framework for approximating and clustering data. InProceedings of the Forty-Third Annual ACM Symposium on Theory of Computing, pages 569–578, 2011
2011
-
[67]
New frameworks for offline and streaming coreset constructions.arXiv preprint arXiv:1612.00889, 2016
Vladimir Braverman, Dan Feldman, Harry Lang, Adiel Statman, and Samson Zhou. New frameworks for offline and streaming coreset constructions.arXiv preprint arXiv:1612.00889, 2016
-
[68]
Practical Coreset Constructions for Machine Learning
Olivier Bachem, Mario Lucic, and Andreas Krause. Practical coreset constructions for machine learning.arXiv preprint arXiv:1703.06476, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[69]
Coresets-methods and history: A theoreticians design pattern for approximation and streaming algorithms.KI - Künstliche Intelligenz, 32(1): 37–53, 2018
Alexander Munteanu and Chris Schwiegelshohn. Coresets-methods and history: A theoreticians design pattern for approximation and streaming algorithms.KI - Künstliche Intelligenz, 32(1): 37–53, 2018
2018
-
[70]
What is the effect of importance weighting in deep learning? InProceedings of the 36th International Conference on Machine Learning, pages 872–881, 2019
Jonathon Byrd and Zachary Lipton. What is the effect of importance weighting in deep learning? InProceedings of the 36th International Conference on Machine Learning, pages 872–881, 2019
2019
-
[71]
/" + b; }; var dbg = Debugger(g); var hits = 0; dbg.onDebuggerStatement = function (frame) { var f = frame.eval(
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Technical Report, 2019. 14 A Experimental protocol details The main experiments use 12 Pile subsets and 150 test queries per subset. This protocol is a compute-conscious version of the evaluation style used by TT...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.