QASM-Eval: A Dataset to Train and Evaluate LLMs on OpenQASM-3 Beyond Quantum Circuits
Pith reviewed 2026-07-01 08:32 UTC · model grok-4.3
The pith
QASM-Eval is the first dataset for training LLMs on OpenQASM-3 hardware features like timing and pulses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
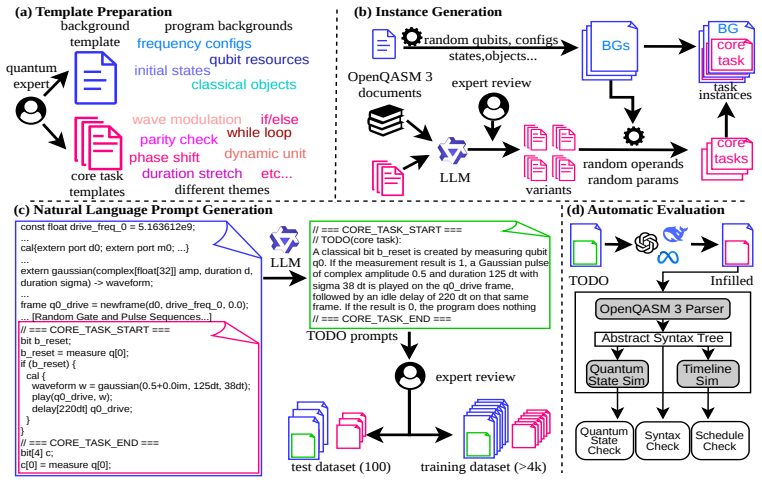
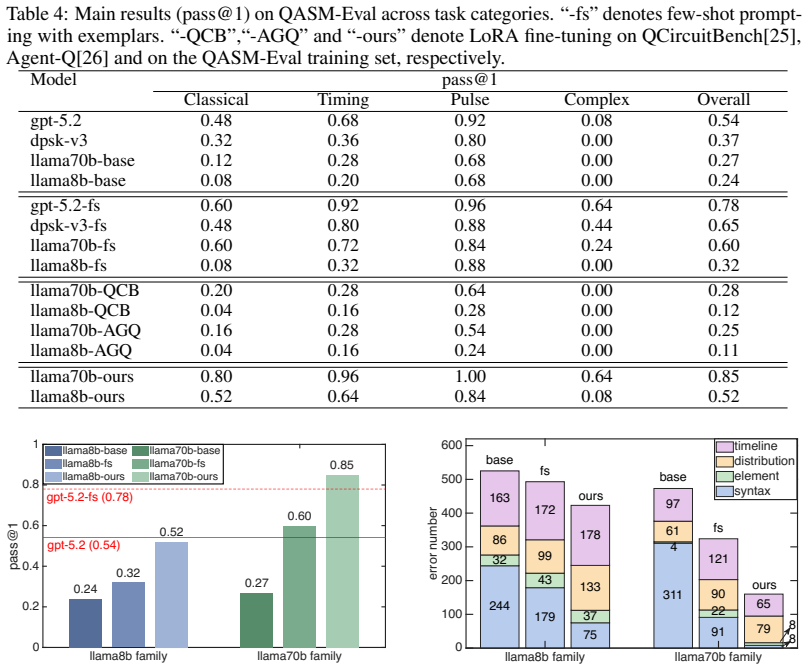
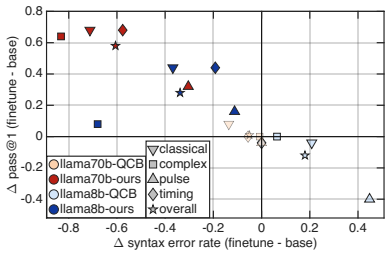
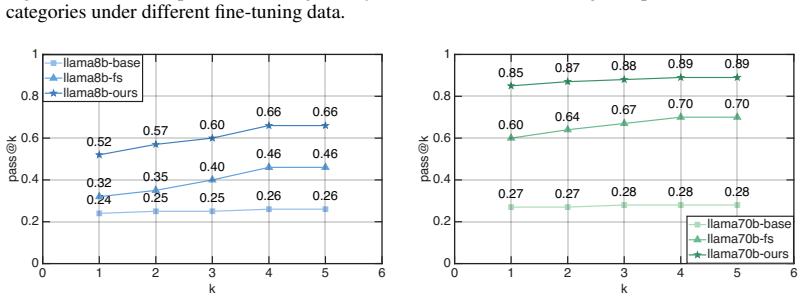
We introduce QASM-Eval, the first comprehensive dataset designed to train and evaluate LLMs on OpenQASM-3 programs involving its advanced hardware-oriented features. QASM-Eval comprises an expert-verified test set of 100 tasks and a training set of 4,000 tasks, systematically covering classical logic, timing scheduling, pulse control, and complex real-world workflows. To automatically validate generated programs, we check syntax, quantum states and program timeline using an extended verifier. Our evaluation reveals that while state-of-the-art LLMs struggle heavily in OpenQASM-3 coding tasks, targeted fine-tuning on QASM-Eval yields significant gains.
What carries the argument
The QASM-Eval dataset with its 100 expert-verified test tasks and extended verifier that checks syntax, quantum states, and program timelines.
If this is right
- Fine-tuned LLMs can generate OpenQASM-3 code for quantum error correction that uses mid-circuit measurements and classical feedback.
- The dataset supports training for dynamical decoupling and pulse-level calibration tasks in NISQ hardware.
- The extended verifier allows automated, scalable checking of syntax, states, and timelines in generated programs.
- Systematic feature coverage enables targeted improvements on specific hardware constraints like timing scheduling.
Where Pith is reading between the lines
- Similar datasets for other low-level quantum languages could help bridge high-level algorithms and hardware control.
- Fine-tuned models might allow non-experts to develop reliable NISQ applications without deep hardware knowledge.
- Extending the verifier to include noise models could enable more realistic evaluation of generated code.
- The dataset approach could be adapted to train models on real hardware interfaces beyond simulation.
Load-bearing premise
The 100 expert-verified test tasks systematically cover the hardware-facing features of OpenQASM-3 and the extended verifier correctly validates syntax, quantum states, and program timelines for those features.
What would settle it
Showing that fine-tuning on the 4,000 tasks produces no improvement on the 100 test tasks, or finding cases where the verifier accepts invalid programs with mid-circuit measurements or timing controls.
Figures
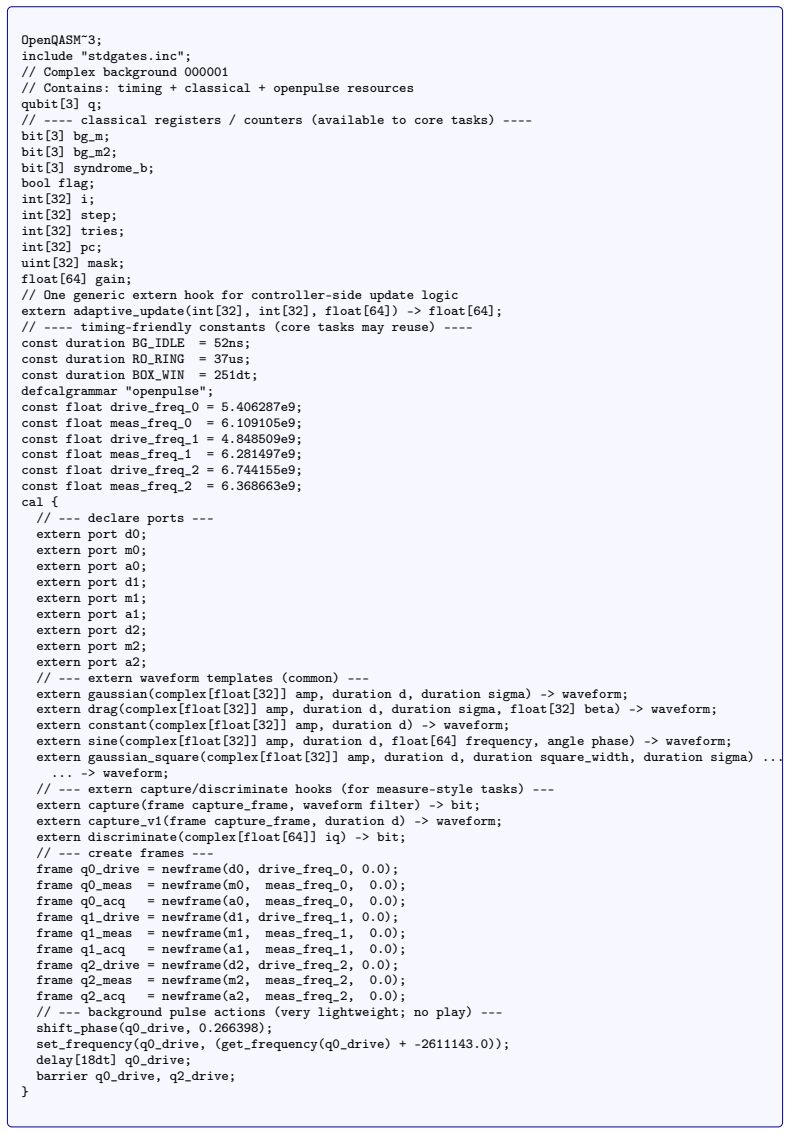







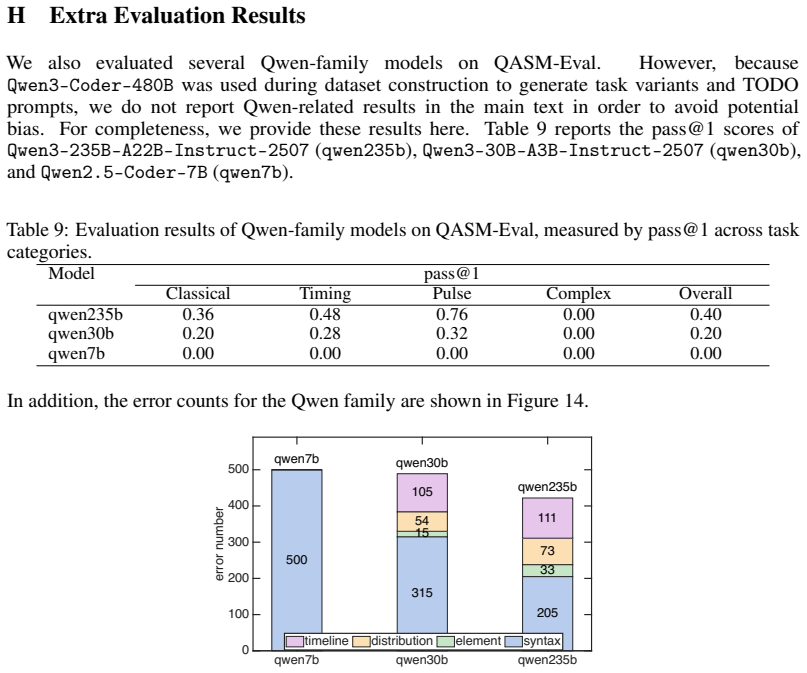
read the original abstract
Quantum computing remains in the Noisy Intermediate-Scale Quantum (NISQ) era, where the performance is highly constrained to noise. Addressing the limitation often requires hardware-facing capabilities beyond gate-sequence circuit specification, including mid-circuit measurement and classical feedback for quantum error correction (QEC), precise timing control for dynamical decoupling (DD), and pulse-level waveform access for calibration. OpenQASM-3 was introduced to expose exactly these capabilities, providing a hardware-level programming interface. However, despite the rapid progress of large language models in code generation, there is still no dataset specifically designed to train and evaluate LLMs on OpenQASM-3 programs that involve its advanced hardware-oriented features. To address this gap, we introduce QASM-Eval, the first comprehensive dataset designed to train and evaluate LLMs on OpenQASM-3. Rather than focusing on quantum algorithm design or reasoning, QASM-Eval explicitly targets the language's hardware-facing features. QASM-Eval comprises an expert-verified test set of 100 tasks and a training set of 4,000 tasks, systematically covering classical logic, timing scheduling, pulse control, and complex real-world workflows. To automatically validate generated programs, we check syntax, quantum states and program timeline using an extended verifier. Our evaluation reveals that while state-of-the-art LLMs struggle heavily in OpenQASM-3 coding tasks, targeted fine-tuning on QASM-Eval yields significant gains. QASM-Eval provides a crucial benchmark and training foundation to accelerate the development of reliable LLM assistants for hardware-facing quantum programming in NISQ era. Data and code: https://github.com/fuzhenxiao/QASM-Eval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QASM-Eval, the first comprehensive dataset for training and evaluating LLMs on OpenQASM-3, focusing on hardware-facing features beyond standard quantum circuits. It includes a training set of 4,000 tasks and an expert-verified test set of 100 tasks covering classical logic, timing scheduling, pulse control, and real-world workflows. The authors use an extended verifier to validate generated programs by checking syntax, quantum states, and program timelines. Their evaluation indicates that state-of-the-art LLMs struggle with these tasks, but targeted fine-tuning on QASM-Eval leads to significant performance improvements.
Significance. Should the dataset and associated verifier prove reliable, this contribution would be significant for the field of LLM-assisted quantum programming. It addresses a clear gap in existing benchmarks, which typically focus on high-level quantum algorithms rather than the low-level hardware controls needed for NISQ devices, such as those for quantum error correction and dynamical decoupling. The release of the dataset and code supports reproducibility and further research.
major comments (2)
- [Abstract] Abstract: The assertion that the 100 expert-verified test tasks systematically cover the hardware-facing features of OpenQASM-3 (including mid-circuit measurement, classical feedback, timing for dynamical decoupling, and pulse control) is not accompanied by any specific examples, coverage breakdown, or mapping to OpenQASM-3 constructs, which is necessary to substantiate the claim that they represent real-world workflows.
- [Abstract] Abstract: The extended verifier is stated to validate syntax, quantum states, and program timelines, but the manuscript provides no description of its implementation, no validation test cases demonstrating correct acceptance/rejection for programs involving mid-circuit feedback or timing schedules, and no comparison to an independent reference. This undermines the interpretability of the reported LLM performance results and fine-tuning gains.
minor comments (1)
- [Abstract] Abstract: The link to the GitHub repository is provided, but the manuscript does not specify the license under which the dataset is released or detail the exact structure of the training and test sets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree that the abstract and manuscript require additional substantiation for the claims made. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the 100 expert-verified test tasks systematically cover the hardware-facing features of OpenQASM-3 (including mid-circuit measurement, classical feedback, timing for dynamical decoupling, and pulse control) is not accompanied by any specific examples, coverage breakdown, or mapping to OpenQASM-3 constructs, which is necessary to substantiate the claim that they represent real-world workflows.
Authors: We agree that the abstract does not include specific examples, a coverage breakdown, or explicit mapping to OpenQASM-3 constructs. The full manuscript (Section 3) provides task examples and a category distribution, but these details are not summarized in the abstract. In revision we will expand the abstract with one concrete example per major feature and a short coverage table, plus add an explicit mapping of tasks to OpenQASM-3 language constructs. revision: yes
-
Referee: [Abstract] Abstract: The extended verifier is stated to validate syntax, quantum states, and program timelines, but the manuscript provides no description of its implementation, no validation test cases demonstrating correct acceptance/rejection for programs involving mid-circuit feedback or timing schedules, and no comparison to an independent reference. This undermines the interpretability of the reported LLM performance results and fine-tuning gains.
Authors: We acknowledge that the current manuscript lacks a description of the verifier implementation, validation test cases for mid-circuit feedback and timing, and any comparison to a reference implementation. This is a substantive gap. In the revised version we will insert a dedicated subsection detailing the verifier architecture, include concrete acceptance/rejection test cases for the mentioned features, and discuss any independent checks performed or limitations thereof. revision: yes
Circularity Check
No circularity: dataset creation paper with no derivations or self-referential predictions
full rationale
The paper introduces a new dataset (QASM-Eval) for training/evaluating LLMs on OpenQASM-3 hardware features, along with an external GitHub link for data/code. It contains no mathematical derivations, fitted parameters, predictions of related quantities, or load-bearing self-citations. The central claims rest on the creation of 4000 training + 100 test tasks and use of an extended verifier, which are presented as new contributions rather than reductions to prior inputs by construction. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantum chemistry in the age of quantum computing.Chemical reviews, 119(19):10856–10915, 2019
Yudong Cao, Jonathan Romero, Jonathan P Olson, Matthias Degroote, Peter D Johnson, Mária Kieferová, Ian D Kivlichan, Tim Menke, Borja Peropadre, Nicolas PD Sawaya, et al. Quantum chemistry in the age of quantum computing.Chemical reviews, 119(19):10856–10915, 2019
2019
-
[2]
Evaluating the evidence for exponential quantum advantage in ground-state quantum chemistry.Nature communications, 14(1):1952, 2023
Seunghoon Lee, Joonho Lee, Huanchen Zhai, Yu Tong, Alexander M Dalzell, Ashutosh Kumar, Phillip Helms, Johnnie Gray, Zhi-Hao Cui, Wenyuan Liu, et al. Evaluating the evidence for exponential quantum advantage in ground-state quantum chemistry.Nature communications, 14(1):1952, 2023
1952
-
[3]
Challenges and opportunities in quantum optimization.Nature Reviews Physics, 6(12):718–735, 2024
Amira Abbas, Andris Ambainis, Brandon Augustino, Andreas Bärtschi, Harry Buhrman, Carleton Coffrin, Giorgio Cortiana, Vedran Dunjko, Daniel J Egger, Bruce G Elmegreen, et al. Challenges and opportunities in quantum optimization.Nature Reviews Physics, 6(12):718–735, 2024
2024
-
[4]
Challenges and opportunities in quantum machine learning.Nature computational science, 2 (9):567–576, 2022
Marco Cerezo, Guillaume Verdon, Hsin-Yuan Huang, Lukasz Cincio, and Patrick J Coles. Challenges and opportunities in quantum machine learning.Nature computational science, 2 (9):567–576, 2022
2022
-
[5]
Quantum machine learning.Nature, 549(7671):195–202, 2017
Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning.Nature, 549(7671):195–202, 2017
2017
-
[6]
The complexity of nisq.Nature Communications, 14(1):6001, 2023
Sitan Chen, Jordan Cotler, Hsin-Yuan Huang, and Jerry Li. The complexity of nisq.Nature Communications, 14(1):6001, 2023
2023
-
[7]
Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
John Preskill. Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
2018
-
[8]
An introduction to quantum error correction and fault-tolerant quantum computation
Daniel Gottesman. An introduction to quantum error correction and fault-tolerant quantum computation. InQuantum information science and its contributions to mathematics, Proceedings of Symposia in Applied Mathematics, volume 68, pages 13–58, 2010
2010
-
[9]
Fault-tolerant quantum dynamical decoupling.Physical review letters, 95(18):180501, 2005
Kaveh Khodjasteh and Daniel A Lidar. Fault-tolerant quantum dynamical decoupling.Physical review letters, 95(18):180501, 2005
2005
-
[10]
Randomized benchmarking of quantum gates.Physical Review A—Atomic, Molecular, and Optical Physics, 77(1):012307, 2008
Emanuel Knill, Dietrich Leibfried, Rolf Reichle, Joe Britton, R Brad Blakestad, John D Jost, Chris Langer, Roee Ozeri, Signe Seidelin, and David J Wineland. Randomized benchmarking of quantum gates.Physical Review A—Atomic, Molecular, and Optical Physics, 77(1):012307, 2008
2008
-
[12]
Noise spectroscopy through dynamical decoupling with a superconducting flux qubit.Nature Physics, 7(7):565–570, 2011
Jonas Bylander, Simon Gustavsson, Fei Yan, Fumiki Yoshihara, Khalil Harrabi, George Fitch, David G Cory, Yasunobu Nakamura, Jaw-Shen Tsai, and William D Oliver. Noise spectroscopy through dynamical decoupling with a superconducting flux qubit.Nature Physics, 7(7):565–570, 2011
2011
-
[13]
Decoherence benchmarking of superconducting qubits.npj Quantum Information, 5(1):54, 2019
Jonathan J Burnett, Andreas Bengtsson, Marco Scigliuzzo, David Niepce, Marina Kudra, Per Delsing, and Jonas Bylander. Decoherence benchmarking of superconducting qubits.npj Quantum Information, 5(1):54, 2019
2019
-
[14]
Detecting and tracking drift in quantum information processors.Nature communications, 11(1):5396, 2020
Timothy Proctor, Melissa Revelle, Erik Nielsen, Kenneth Rudinger, Daniel Lobser, Peter Maunz, Robin Blume-Kohout, and Kevin Young. Detecting and tracking drift in quantum information processors.Nature communications, 11(1):5396, 2020
2020
-
[15]
Ali Javadi-Abhari, Matthew Treinish, Kevin Krsulich, Christopher J. Wood, Jake Lishman, Julien Gacon, Simon Martiel, Paul D. Nation, Lev S. Bishop, Andrew W. Cross, Blake R. Johnson, and Jay M. Gambetta. Quantum computing with qiskit, 2024. URL https://arxiv. org/abs/2405.08810. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Cirq Developers.Cirq. Zenodo, August 2025. doi: 10.5281/ZENODO.4062499. URL https://zenodo.org/doi/10.5281/zenodo.4062499
-
[17]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, Shahnawaz Ahmed, Vishnu Ajith, M. Sohaib Alam, Guillermo Alonso-Linaje, B. AkashNarayanan, Ali Asadi, Juan Miguel Arrazola, Utkarsh Azad, Sam Banning, Carsten Blank, Thomas R Bromley, Benjamin A. Cordier, Jack Ceroni, Alain Delgado, Olivia Di Matteo, Amintor Dusko, Tanya Garg, Diego Guala, Antho...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Openqasm 3: A broader and deeper quantum assembly language.ACM Transactions on Quantum Computing, 3 (3):1–50, 2022
Andrew Cross, Ali Javadi-Abhari, Thomas Alexander, Niel De Beaudrap, Lev S Bishop, Steven Heidel, Colm A Ryan, Prasahnt Sivarajah, John Smolin, Jay M Gambetta, et al. Openqasm 3: A broader and deeper quantum assembly language.ACM Transactions on Quantum Computing, 3 (3):1–50, 2022
2022
-
[19]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet
Erik Schluntz. Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet. https: //www.anthropic.com/engineering/swe-bench-sonnet, January 2025. Published Jan 06, 2025. Reports 49% on SWE-bench Verified with an agent scaffold. Accessed 2026-02-25
2025
-
[21]
Using an llm to help with code understanding
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[22]
A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Transactions on Software Engineering and Methodology, 2024
Sathvik Joel, Jie Wu, and Fatemeh Fard. A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[23]
Veriqbench: A benchmark for multiple types of quantum circuits, 2022
Kean Chen, Wang Fang, Ji Guan, Xin Hong, Mingyu Huang, Junyi Liu, Qisheng Wang, and Mingsheng Ying. Veriqbench: A benchmark for multiple types of quantum circuits, 2022. URL https://arxiv.org/abs/2206.10880
-
[24]
Ang Li, Samuel Stein, Sriram Krishnamoorthy, and James Ang. Qasmbench: A low-level quantum benchmark suite for nisq evaluation and simulation.ACM Transactions on Quantum Computing, 4(2), February 2023. doi: 10.1145/3550488. URL https://doi.org/10.1145/ 3550488
-
[25]
Rui Yang, Ziruo Wang, Yuntian Gu, Tianyi Chen, Yitao Liang, and Tongyang Li. Qcircuit- bench: A large-scale dataset for benchmarking quantum algorithm design.arXiv preprint arXiv:2410.07961, 2024
-
[26]
Agent-q: fine-tuning large language models for quantum circuit generation and optimization
Linus Jern, Valter Uotila, Cong Yu, and Bo Zhao. Agent-q: fine-tuning large language models for quantum circuit generation and optimization. In2025 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 1621–1632. IEEE, 2025
2025
-
[27]
Realization of real-time fault-tolerant quantum error correction.Physical Review X, 11(4): 041058, 2021
Ciaran Ryan-Anderson, Justin G Bohnet, Kenny Lee, Daniel Gresh, Aaron Hankin, John P Gaebler, David Francois, Alexander Chernoguzov, Dominic Lucchetti, Natalie C Brown, et al. Realization of real-time fault-tolerant quantum error correction.Physical Review X, 11(4): 041058, 2021
2021
-
[28]
Probing context-dependent errors in quantum processors.Physical Review X, 9 (2):021045, 2019
Kenneth Rudinger, Timothy Proctor, Dylan Langharst, Mohan Sarovar, Kevin Young, and Robin Blume-Kohout. Probing context-dependent errors in quantum processors.Physical Review X, 9 (2):021045, 2019. 11
2019
-
[29]
Quantum circuit engineering for correcting coherent noise.Physical Review A, 105(2):022428, 2022
Muhammad Ahsan, Syed Abbas Zilqurnain Naqvi, and Haider Anwer. Quantum circuit engineering for correcting coherent noise.Physical Review A, 105(2):022428, 2022
2022
-
[30]
A quantum engineer’s guide to superconducting qubits.Applied physics reviews, 6(2), 2019
Philip Krantz, Morten Kjaergaard, Fei Yan, Terry P Orlando, Simon Gustavsson, and William D Oliver. A quantum engineer’s guide to superconducting qubits.Applied physics reviews, 6(2), 2019
2019
-
[31]
Robust quantum error syndrome extraction by classical coding
Alexei Ashikhmin, Ching-Yi Lai, and Todd A Brun. Robust quantum error syndrome extraction by classical coding. In2014 IEEE International Symposium on Information Theory, pages 546–550. IEEE, 2014
2014
-
[32]
Low-depth flag-style syndrome extraction for small quantum error-correction codes
Dhruv Bhatnagar, Matthew Steinberg, David Elkouss, Carmen G Almudever, and Sebastian Feld. Low-depth flag-style syndrome extraction for small quantum error-correction codes. In2023 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 63–69. IEEE, 2023
2023
-
[33]
Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms.Journal of magnetic resonance, 172(2):296–305, 2005
Navin Khaneja, Timo Reiss, Cindie Kehlet, Thomas Schulte-Herbrüggen, and Steffen J Glaser. Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms.Journal of magnetic resonance, 172(2):296–305, 2005
2005
-
[34]
Simple pulses for elimination of leakage in weakly nonlinear qubits.Physical review letters, 103(11):110501, 2009
Felix Motzoi, Jay M Gambetta, Patrick Rebentrost, and Frank K Wilhelm. Simple pulses for elimination of leakage in weakly nonlinear qubits.Physical review letters, 103(11):110501, 2009
2009
-
[35]
Qdataset, quantum datasets for machine learning
Elija Perrier, Akram Youssry, and Chris Ferrie. Qdataset, quantum datasets for machine learning. Scientific data, 9(1):582, 2022
2022
-
[36]
Qiskit humaneval: An evaluation benchmark for quantum code generative models
Sanjay Vishwakarma, Francis Harkins, Siddharth Golecha, Vishal Sharathchandra Bajpe, Nico- las Dupuis, Luca Buratti, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito. Qiskit humaneval: An evaluation benchmark for quantum code generative models. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 116...
2024
-
[37]
Xiaoyu Guo, Minggu Wang, and Jianjun Zhao. Quanbench: Benchmarking quantum code generation with large language models.arXiv preprint arXiv:2510.16779, 2025
-
[38]
Mqt bench: Benchmarking software and design automation tools for quantum computing.Quantum, 7:1062, 2023
Nils Quetschlich, Lukas Burgholzer, and Robert Wille. Mqt bench: Benchmarking software and design automation tools for quantum computing.Quantum, 7:1062, 2023
2023
-
[39]
Tianchi Xie, Minzhi Lin, Mengchen Liu, Yilin Ye, Changjian Chen, and Shixia Liu. In- fochartqa: A benchmark for multimodal question answering on infographic charts.arXiv preprint arXiv:2505.19028, 2025
-
[40]
Zimu Lu, Yunqiao Yang, Houxing Ren, Haotian Hou, Han Xiao, Ke Wang, Weikang Shi, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Webgen-bench: Evaluating llms on generating interactive and functional websites from scratch.arXiv preprint arXiv:2505.03733, 2025
-
[41]
Sebastian Antony Joseph, Syed Murtaza Husain, Stella SR Offner, StÊphanie Juneau, Paul Torrey, Adam S Bolton, Juan P Farias, Niall Gaffney, Greg Durrett, and Junyi Jessy Li. Astro- visbench: A code benchmark for scientific computing and visualization in astronomy.arXiv preprint arXiv:2505.20538, 2025
-
[42]
Openqasm 3 feature table, 2026
IBM Quantum. Openqasm 3 feature table, 2026. URL https://quantum.cloud.ibm.com/ docs/en/guides/qasm-feature-table. IBM Quantum Documentation
2026
-
[43]
Qutip 5: The quantum toolbox in python.Physics Reports, 1153:1–62, 2026
Neill Lambert, Eric Giguère, Paul Menczel, Boxi Li, Patrick Hopf, Gerardo Suárez, Marc Gali, Jake Lishman, Rushiraj Gadhvi, Rochisha Agarwal, et al. Qutip 5: The quantum toolbox in python.Physics Reports, 1153:1–62, 2026
2026
-
[44]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz 12 Li...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[45]
Qiskit code assistant: Training llms for generating quantum computing code
Nicolas Dupuis, Luca Buratti, Sanjay Vishwakarma, Aitana Viudes Forrat, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito. Qiskit code assistant: Training llms for generating quantum computing code. In2024 IEEE LLM Aided Design Workshop (LAD), pages 1–4. IEEE, 2024
2024
-
[46]
Enhancing llm-based quantum code generation with multi-agent optimization and quantum error correction
Charlie Campbell, Hao Mark Chen, Wayne Luk, and Hongxiang Fan. Enhancing llm-based quantum code generation with multi-agent optimization and quantum error correction. In2025 62nd ACM/IEEE Design Automation Conference (DAC), pages 1–7. IEEE, 2025
2025
-
[47]
A PennyLane-Centric Dataset to Enhance LLM-based Quantum Code Generation using RAG
Abdul Basit, Nouhaila Innan, Muhammad Haider Asif, Minghao Shao, Muhammad Kashif, Alberto Marchisio, and Muhammad Shafique. Pennylang: Pioneering llm-based quantum code generation with a novel pennylane-centric dataset.arXiv preprint arXiv:2503.02497, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Cong Yu, Valter Uotila, Shilong Deng, Qingyuan Wu, Tuo Shi, Songlin Jiang, Lei You, and Bo Zhao. Quasar: Quantum assembly code generation using tool-augmented llms via agentic rl. arXiv preprint arXiv:2510.00967, 2025. A Ethics Statement The QASM-Eval dataset is composed of synthetically generated code and natural language prompts, meticulously curated th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.